From 408c298d3d29604e6c4667f82817fee01f2bff19 Mon Sep 17 00:00:00 2001
From: "Robin.Mueller" <robin.mueller.m@gmail.com>
Date: Wed, 19 Aug 2020 20:42:03 +0200
Subject: [PATCH] added requirements.txt
---
requirements.txt | 31 +-
.../isort-5.4.2.dist-info/INSTALLER | 1 +
.../isort-5.4.2.dist-info/LICENSE | 21 +
.../isort-5.4.2.dist-info/METADATA | 694 ++++++++++
.../isort-5.4.2.dist-info/RECORD | 97 ++
.../isort-5.4.2.dist-info/REQUESTED | 0
.../site-packages/isort-5.4.2.dist-info/WHEEL | 4 +
.../isort-5.4.2.dist-info/entry_points.txt | 9 +
venv/Lib/site-packages/isort/__init__.py | 9 +
venv/Lib/site-packages/isort/__main__.py | 3 +
.../site-packages/isort/_future/__init__.py | 12 +
.../isort/_future/_dataclasses.py | 1206 +++++++++++++++++
.../isort/_vendored/toml/LICENSE | 27 +
.../isort/_vendored/toml/__init__.py | 23 +
.../isort/_vendored/toml/decoder.py | 1053 ++++++++++++++
.../isort/_vendored/toml/encoder.py | 295 ++++
.../isort/_vendored/toml/ordered.py | 13 +
.../site-packages/isort/_vendored/toml/tz.py | 21 +
venv/Lib/site-packages/isort/_version.py | 1 +
venv/Lib/site-packages/isort/api.py | 383 ++++++
venv/Lib/site-packages/isort/comments.py | 32 +
venv/Lib/site-packages/isort/core.py | 386 ++++++
.../isort/deprecated/__init__.py | 0
.../site-packages/isort/deprecated/finders.py | 403 ++++++
venv/Lib/site-packages/isort/exceptions.py | 134 ++
venv/Lib/site-packages/isort/format.py | 121 ++
venv/Lib/site-packages/isort/hooks.py | 80 ++
venv/Lib/site-packages/isort/io.py | 60 +
venv/Lib/site-packages/isort/literal.py | 108 ++
venv/Lib/site-packages/isort/logo.py | 19 +
venv/Lib/site-packages/isort/main.py | 920 +++++++++++++
venv/Lib/site-packages/isort/output.py | 552 ++++++++
venv/Lib/site-packages/isort/parse.py | 463 +++++++
venv/Lib/site-packages/isort/place.py | 95 ++
venv/Lib/site-packages/isort/profiles.py | 62 +
venv/Lib/site-packages/isort/pylama_isort.py | 33 +
venv/Lib/site-packages/isort/sections.py | 9 +
venv/Lib/site-packages/isort/settings.py | 698 ++++++++++
.../isort/setuptools_commands.py | 61 +
venv/Lib/site-packages/isort/sorting.py | 93 ++
.../site-packages/isort/stdlibs/__init__.py | 1 +
venv/Lib/site-packages/isort/stdlibs/all.py | 3 +
venv/Lib/site-packages/isort/stdlibs/py2.py | 3 +
venv/Lib/site-packages/isort/stdlibs/py27.py | 300 ++++
venv/Lib/site-packages/isort/stdlibs/py3.py | 3 +
venv/Lib/site-packages/isort/stdlibs/py35.py | 222 +++
venv/Lib/site-packages/isort/stdlibs/py36.py | 223 +++
venv/Lib/site-packages/isort/stdlibs/py37.py | 224 +++
venv/Lib/site-packages/isort/stdlibs/py38.py | 223 +++
venv/Lib/site-packages/isort/stdlibs/py39.py | 223 +++
venv/Lib/site-packages/isort/utils.py | 29 +
venv/Lib/site-packages/isort/wrap.py | 123 ++
venv/Lib/site-packages/isort/wrap_modes.py | 311 +++++
.../AUTHORS.rst | 10 +
.../INSTALLER | 1 +
.../lazy_object_proxy-1.5.1.dist-info/LICENSE | 21 +
.../METADATA | 176 +++
.../lazy_object_proxy-1.5.1.dist-info/RECORD | 21 +
.../REQUESTED | 0
.../lazy_object_proxy-1.5.1.dist-info/WHEEL | 5 +
.../top_level.txt | 1 +
.../lazy_object_proxy/__init__.py | 23 +
.../lazy_object_proxy/_version.py | 4 +
.../lazy_object_proxy/cext.cp38-win_amd64.pyd | Bin 0 -> 33280 bytes
.../site-packages/lazy_object_proxy/compat.py | 14 +
.../site-packages/lazy_object_proxy/simple.py | 258 ++++
.../site-packages/lazy_object_proxy/slots.py | 426 ++++++
.../site-packages/lazy_object_proxy/utils.py | 13 +
.../six-1.15.0.dist-info/INSTALLER | 1 +
.../six-1.15.0.dist-info/LICENSE | 18 +
.../six-1.15.0.dist-info/METADATA | 49 +
.../site-packages/six-1.15.0.dist-info/RECORD | 9 +
.../six-1.15.0.dist-info/REQUESTED | 0
.../site-packages/six-1.15.0.dist-info/WHEEL | 6 +
.../six-1.15.0.dist-info/top_level.txt | 1 +
venv/Lib/site-packages/six.py | 982 ++++++++++++++
venv/Scripts/isort.exe | Bin 0 -> 106369 bytes
77 files changed, 12156 insertions(+), 3 deletions(-)
create mode 100644 venv/Lib/site-packages/isort-5.4.2.dist-info/INSTALLER
create mode 100644 venv/Lib/site-packages/isort-5.4.2.dist-info/LICENSE
create mode 100644 venv/Lib/site-packages/isort-5.4.2.dist-info/METADATA
create mode 100644 venv/Lib/site-packages/isort-5.4.2.dist-info/RECORD
create mode 100644 venv/Lib/site-packages/isort-5.4.2.dist-info/REQUESTED
create mode 100644 venv/Lib/site-packages/isort-5.4.2.dist-info/WHEEL
create mode 100644 venv/Lib/site-packages/isort-5.4.2.dist-info/entry_points.txt
create mode 100644 venv/Lib/site-packages/isort/__init__.py
create mode 100644 venv/Lib/site-packages/isort/__main__.py
create mode 100644 venv/Lib/site-packages/isort/_future/__init__.py
create mode 100644 venv/Lib/site-packages/isort/_future/_dataclasses.py
create mode 100644 venv/Lib/site-packages/isort/_vendored/toml/LICENSE
create mode 100644 venv/Lib/site-packages/isort/_vendored/toml/__init__.py
create mode 100644 venv/Lib/site-packages/isort/_vendored/toml/decoder.py
create mode 100644 venv/Lib/site-packages/isort/_vendored/toml/encoder.py
create mode 100644 venv/Lib/site-packages/isort/_vendored/toml/ordered.py
create mode 100644 venv/Lib/site-packages/isort/_vendored/toml/tz.py
create mode 100644 venv/Lib/site-packages/isort/_version.py
create mode 100644 venv/Lib/site-packages/isort/api.py
create mode 100644 venv/Lib/site-packages/isort/comments.py
create mode 100644 venv/Lib/site-packages/isort/core.py
create mode 100644 venv/Lib/site-packages/isort/deprecated/__init__.py
create mode 100644 venv/Lib/site-packages/isort/deprecated/finders.py
create mode 100644 venv/Lib/site-packages/isort/exceptions.py
create mode 100644 venv/Lib/site-packages/isort/format.py
create mode 100644 venv/Lib/site-packages/isort/hooks.py
create mode 100644 venv/Lib/site-packages/isort/io.py
create mode 100644 venv/Lib/site-packages/isort/literal.py
create mode 100644 venv/Lib/site-packages/isort/logo.py
create mode 100644 venv/Lib/site-packages/isort/main.py
create mode 100644 venv/Lib/site-packages/isort/output.py
create mode 100644 venv/Lib/site-packages/isort/parse.py
create mode 100644 venv/Lib/site-packages/isort/place.py
create mode 100644 venv/Lib/site-packages/isort/profiles.py
create mode 100644 venv/Lib/site-packages/isort/pylama_isort.py
create mode 100644 venv/Lib/site-packages/isort/sections.py
create mode 100644 venv/Lib/site-packages/isort/settings.py
create mode 100644 venv/Lib/site-packages/isort/setuptools_commands.py
create mode 100644 venv/Lib/site-packages/isort/sorting.py
create mode 100644 venv/Lib/site-packages/isort/stdlibs/__init__.py
create mode 100644 venv/Lib/site-packages/isort/stdlibs/all.py
create mode 100644 venv/Lib/site-packages/isort/stdlibs/py2.py
create mode 100644 venv/Lib/site-packages/isort/stdlibs/py27.py
create mode 100644 venv/Lib/site-packages/isort/stdlibs/py3.py
create mode 100644 venv/Lib/site-packages/isort/stdlibs/py35.py
create mode 100644 venv/Lib/site-packages/isort/stdlibs/py36.py
create mode 100644 venv/Lib/site-packages/isort/stdlibs/py37.py
create mode 100644 venv/Lib/site-packages/isort/stdlibs/py38.py
create mode 100644 venv/Lib/site-packages/isort/stdlibs/py39.py
create mode 100644 venv/Lib/site-packages/isort/utils.py
create mode 100644 venv/Lib/site-packages/isort/wrap.py
create mode 100644 venv/Lib/site-packages/isort/wrap_modes.py
create mode 100644 venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/AUTHORS.rst
create mode 100644 venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/INSTALLER
create mode 100644 venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/LICENSE
create mode 100644 venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/METADATA
create mode 100644 venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/RECORD
create mode 100644 venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/REQUESTED
create mode 100644 venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/WHEEL
create mode 100644 venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/top_level.txt
create mode 100644 venv/Lib/site-packages/lazy_object_proxy/__init__.py
create mode 100644 venv/Lib/site-packages/lazy_object_proxy/_version.py
create mode 100644 venv/Lib/site-packages/lazy_object_proxy/cext.cp38-win_amd64.pyd
create mode 100644 venv/Lib/site-packages/lazy_object_proxy/compat.py
create mode 100644 venv/Lib/site-packages/lazy_object_proxy/simple.py
create mode 100644 venv/Lib/site-packages/lazy_object_proxy/slots.py
create mode 100644 venv/Lib/site-packages/lazy_object_proxy/utils.py
create mode 100644 venv/Lib/site-packages/six-1.15.0.dist-info/INSTALLER
create mode 100644 venv/Lib/site-packages/six-1.15.0.dist-info/LICENSE
create mode 100644 venv/Lib/site-packages/six-1.15.0.dist-info/METADATA
create mode 100644 venv/Lib/site-packages/six-1.15.0.dist-info/RECORD
create mode 100644 venv/Lib/site-packages/six-1.15.0.dist-info/REQUESTED
create mode 100644 venv/Lib/site-packages/six-1.15.0.dist-info/WHEEL
create mode 100644 venv/Lib/site-packages/six-1.15.0.dist-info/top_level.txt
create mode 100644 venv/Lib/site-packages/six.py
create mode 100644 venv/Scripts/isort.exe
diff --git a/requirements.txt b/requirements.txt
index fc5619a..5548b57 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -1,3 +1,28 @@
-crcmod>=1.7
-pyserial>=3.4
-PyQt5>=5.15.0
\ No newline at end of file
+aiohttp==3.6.2
+astroid==2.4.2
+async-timeout==3.0.1
+attrs==19.3.0
+chardet==3.0.4
+colorama==0.4.3
+cpplint==1.5.4
+crc==0.4.1
+crcmod==1.7
+docopt==0.6.2
+future==0.18.2
+idna==2.10
+iso8601==0.1.12
+isort==5.4.2
+lazy-object-proxy==1.5.1
+mccabe==0.6.1
+multidict==4.7.6
+pylint==2.5.3
+PyQt5==5.15.0
+PyQt5-sip==12.8.0
+pyserial==3.4
+PyYAML==5.3.1
+serial==0.0.97
+six==1.15.0
+toml==0.10.1
+typing-extensions==3.7.4.2
+wrapt==1.11.2
+yarl==1.5.0
diff --git a/venv/Lib/site-packages/isort-5.4.2.dist-info/INSTALLER b/venv/Lib/site-packages/isort-5.4.2.dist-info/INSTALLER
new file mode 100644
index 0000000..a1b589e
--- /dev/null
+++ b/venv/Lib/site-packages/isort-5.4.2.dist-info/INSTALLER
@@ -0,0 +1 @@
+pip
diff --git a/venv/Lib/site-packages/isort-5.4.2.dist-info/LICENSE b/venv/Lib/site-packages/isort-5.4.2.dist-info/LICENSE
new file mode 100644
index 0000000..b5083a5
--- /dev/null
+++ b/venv/Lib/site-packages/isort-5.4.2.dist-info/LICENSE
@@ -0,0 +1,21 @@
+The MIT License (MIT)
+
+Copyright (c) 2013 Timothy Edmund Crosley
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in
+all copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
+THE SOFTWARE.
diff --git a/venv/Lib/site-packages/isort-5.4.2.dist-info/METADATA b/venv/Lib/site-packages/isort-5.4.2.dist-info/METADATA
new file mode 100644
index 0000000..4301784
--- /dev/null
+++ b/venv/Lib/site-packages/isort-5.4.2.dist-info/METADATA
@@ -0,0 +1,694 @@
+Metadata-Version: 2.1
+Name: isort
+Version: 5.4.2
+Summary: A Python utility / library to sort Python imports.
+Home-page: https://timothycrosley.github.io/isort/
+License: MIT
+Keywords: Refactor,Lint,Imports,Sort,Clean
+Author: Timothy Crosley
+Author-email: timothy.crosley@gmail.com
+Requires-Python: >=3.6,<4.0
+Classifier: Development Status :: 6 - Mature
+Classifier: Environment :: Console
+Classifier: Intended Audience :: Developers
+Classifier: License :: OSI Approved :: MIT License
+Classifier: Natural Language :: English
+Classifier: Programming Language :: Python
+Classifier: Programming Language :: Python :: 3
+Classifier: Programming Language :: Python :: 3 :: Only
+Classifier: Programming Language :: Python :: 3.6
+Classifier: Programming Language :: Python :: 3.7
+Classifier: Programming Language :: Python :: 3.8
+Classifier: Programming Language :: Python :: 3.9
+Classifier: Programming Language :: Python :: Implementation :: CPython
+Classifier: Programming Language :: Python :: Implementation :: PyPy
+Classifier: Topic :: Software Development :: Libraries
+Classifier: Topic :: Utilities
+Provides-Extra: colors
+Provides-Extra: pipfile_deprecated_finder
+Provides-Extra: requirements_deprecated_finder
+Requires-Dist: colorama (>=0.4.3,<0.5.0); extra == "colors"
+Requires-Dist: pip-api; extra == "requirements_deprecated_finder"
+Requires-Dist: pipreqs; extra == "pipfile_deprecated_finder" or extra == "requirements_deprecated_finder"
+Requires-Dist: requirementslib; extra == "pipfile_deprecated_finder"
+Requires-Dist: tomlkit (>=0.5.3); extra == "pipfile_deprecated_finder"
+Project-URL: Changelog, https://github.com/timothycrosley/isort/blob/master/CHANGELOG.md
+Project-URL: Documentation, https://timothycrosley.github.io/isort/
+Project-URL: Repository, https://github.com/timothycrosley/isort
+Description-Content-Type: text/markdown
+
+[](https://timothycrosley.github.io/isort/)
+
+------------------------------------------------------------------------
+
+[](https://badge.fury.io/py/isort)
+[](https://github.com/timothycrosley/isort/actions?query=workflow%3ATest)
+[](https://github.com/timothycrosley/isort/actions?query=workflow%3ALint)
+[](https://codecov.io/gh/timothycrosley/isort)
+[](https://codeclimate.com/github/timothycrosley/isort/maintainability)
+[](https://pypi.org/project/isort/)
+[](https://gitter.im/timothycrosley/isort?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
+[](https://pepy.tech/project/isort)
+[](https://github.com/psf/black)
+[](https://timothycrosley.github.io/isort/)
+[](https://deepsource.io/gh/timothycrosley/isort/?ref=repository-badge)
+_________________
+
+[Read Latest Documentation](https://timothycrosley.github.io/isort/) - [Browse GitHub Code Repository](https://github.com/timothycrosley/isort/)
+_________________
+
+isort your imports, so you don't have to.
+
+isort is a Python utility / library to sort imports alphabetically, and
+automatically separated into sections and by type. It provides a command line
+utility, Python library and [plugins for various
+editors](https://github.com/timothycrosley/isort/wiki/isort-Plugins) to
+quickly sort all your imports. It requires Python 3.6+ to run but
+supports formatting Python 2 code too.
+
+[Try isort now from your browser!](https://timothycrosley.github.io/isort/docs/quick_start/0.-try/)
+
+
+
+Before isort:
+
+```python
+from my_lib import Object
+
+import os
+
+from my_lib import Object3
+
+from my_lib import Object2
+
+import sys
+
+from third_party import lib15, lib1, lib2, lib3, lib4, lib5, lib6, lib7, lib8, lib9, lib10, lib11, lib12, lib13, lib14
+
+import sys
+
+from __future__ import absolute_import
+
+from third_party import lib3
+
+print("Hey")
+print("yo")
+```
+
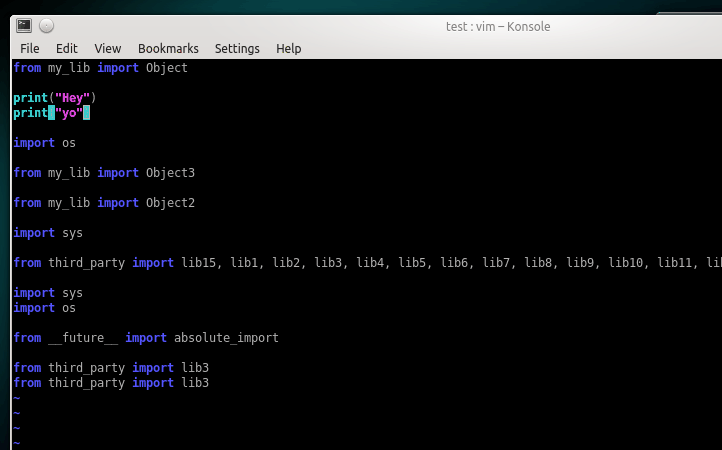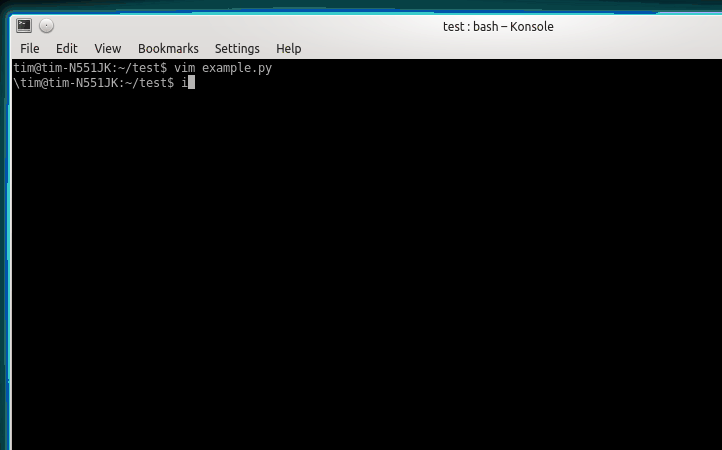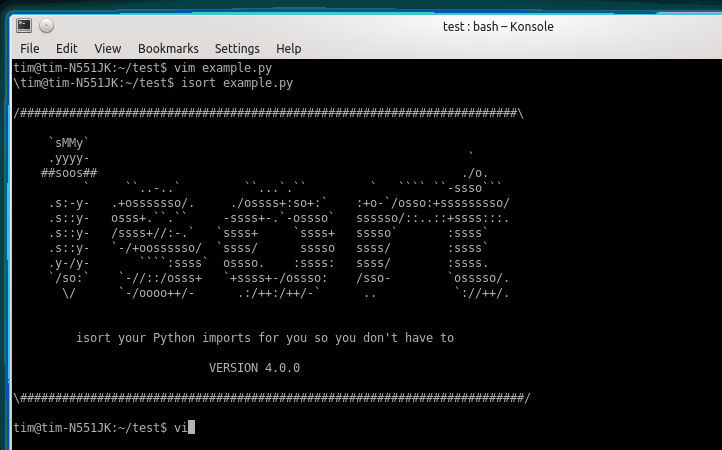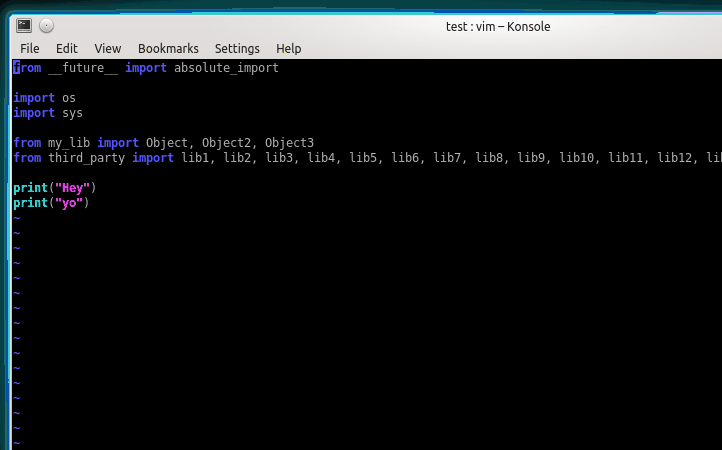
+After isort:
+
+```python
+from __future__ import absolute_import
+
+import os
+import sys
+
+from third_party import (lib1, lib2, lib3, lib4, lib5, lib6, lib7, lib8,
+ lib9, lib10, lib11, lib12, lib13, lib14, lib15)
+
+from my_lib import Object, Object2, Object3
+
+print("Hey")
+print("yo")
+```
+
+## Installing isort
+
+Installing isort is as simple as:
+
+```bash
+pip install isort
+```
+
+Install isort with requirements.txt support:
+
+```bash
+pip install isort[requirements_deprecated_finder]
+```
+
+Install isort with Pipfile support:
+
+```bash
+pip install isort[pipfile_deprecated_finder]
+```
+
+Install isort with both formats support:
+
+```bash
+pip install isort[requirements_deprecated_finder,pipfile_deprecated_finder]
+```
+
+## Using isort
+
+**From the command line**:
+
+```bash
+isort mypythonfile.py mypythonfile2.py
+```
+
+or recursively:
+
+```bash
+isort .
+```
+
+*which is equivalent to:*
+
+```bash
+isort **/*.py
+```
+
+or to see the proposed changes without applying them:
+
+```bash
+isort mypythonfile.py --diff
+```
+
+Finally, to atomically run isort against a project, only applying
+changes if they don't introduce syntax errors do:
+
+```bash
+isort --atomic .
+```
+
+(Note: this is disabled by default as it keeps isort from being able to
+run against code written using a different version of Python)
+
+**From within Python**:
+
+```bash
+import isort
+
+isort.file("pythonfile.py")
+```
+
+or:
+
+```bash
+import isort
+
+sorted_code = isort.code("import b\nimport a\n")
+```
+
+## Installing isort's for your preferred text editor
+
+Several plugins have been written that enable to use isort from within a
+variety of text-editors. You can find a full list of them [on the isort
+wiki](https://github.com/timothycrosley/isort/wiki/isort-Plugins).
+Additionally, I will enthusiastically accept pull requests that include
+plugins for other text editors and add documentation for them as I am
+notified.
+
+## Multi line output modes
+
+You will notice above the \"multi\_line\_output\" setting. This setting
+defines how from imports wrap when they extend past the line\_length
+limit and has 6 possible settings:
+
+**0 - Grid**
+
+```python
+from third_party import (lib1, lib2, lib3,
+ lib4, lib5, ...)
+```
+
+**1 - Vertical**
+
+```python
+from third_party import (lib1,
+ lib2,
+ lib3
+ lib4,
+ lib5,
+ ...)
+```
+
+**2 - Hanging Indent**
+
+```python
+from third_party import \
+ lib1, lib2, lib3, \
+ lib4, lib5, lib6
+```
+
+**3 - Vertical Hanging Indent**
+
+```python
+from third_party import (
+ lib1,
+ lib2,
+ lib3,
+ lib4,
+)
+```
+
+**4 - Hanging Grid**
+
+```python
+from third_party import (
+ lib1, lib2, lib3, lib4,
+ lib5, ...)
+```
+
+**5 - Hanging Grid Grouped**
+
+```python
+from third_party import (
+ lib1, lib2, lib3, lib4,
+ lib5, ...
+)
+```
+
+**6 - Hanging Grid Grouped, No Trailing Comma**
+
+In Mode 5 isort leaves a single extra space to maintain consistency of
+output when a comma is added at the end. Mode 6 is the same - except
+that no extra space is maintained leading to the possibility of lines
+one character longer. You can enforce a trailing comma by using this in
+conjunction with `-tc` or `include_trailing_comma: True`.
+
+```python
+from third_party import (
+ lib1, lib2, lib3, lib4,
+ lib5
+)
+```
+
+**7 - NOQA**
+
+```python
+from third_party import lib1, lib2, lib3, ... # NOQA
+```
+
+Alternatively, you can set `force_single_line` to `True` (`-sl` on the
+command line) and every import will appear on its own line:
+
+```python
+from third_party import lib1
+from third_party import lib2
+from third_party import lib3
+...
+```
+
+**8 - Vertical Hanging Indent Bracket**
+
+Same as Mode 3 - _Vertical Hanging Indent_ but the closing parentheses
+on the last line is indented.
+
+```python
+from third_party import (
+ lib1,
+ lib2,
+ lib3,
+ lib4,
+ )
+```
+
+**9 - Vertical Prefix From Module Import**
+
+Starts a new line with the same `from MODULE import ` prefix when lines are longer than the line length limit.
+
+```python
+from third_party import lib1, lib2, lib3
+from third_party import lib4, lib5, lib6
+```
+
+**10 - Hanging Indent With Parentheses**
+
+Same as Mode 2 - _Hanging Indent_ but uses parentheses instead of backslash
+for wrapping long lines.
+
+```python
+from third_party import (
+ lib1, lib2, lib3,
+ lib4, lib5, lib6)
+```
+
+Note: to change the how constant indents appear - simply change the
+indent property with the following accepted formats:
+
+- Number of spaces you would like. For example: 4 would cause standard
+ 4 space indentation.
+- Tab
+- A verbatim string with quotes around it.
+
+For example:
+
+```python
+" "
+```
+
+is equivalent to 4.
+
+For the import styles that use parentheses, you can control whether or
+not to include a trailing comma after the last import with the
+`include_trailing_comma` option (defaults to `False`).
+
+## Intelligently Balanced Multi-line Imports
+
+As of isort 3.1.0 support for balanced multi-line imports has been
+added. With this enabled isort will dynamically change the import length
+to the one that produces the most balanced grid, while staying below the
+maximum import length defined.
+
+Example:
+
+```python
+from __future__ import (absolute_import, division,
+ print_function, unicode_literals)
+```
+
+Will be produced instead of:
+
+```python
+from __future__ import (absolute_import, division, print_function,
+ unicode_literals)
+```
+
+To enable this set `balanced_wrapping` to `True` in your config or pass
+the `-e` option into the command line utility.
+
+## Custom Sections and Ordering
+
+You can change the section order with `sections` option from the default
+of:
+
+```ini
+FUTURE,STDLIB,THIRDPARTY,FIRSTPARTY,LOCALFOLDER
+```
+
+to your preference:
+
+```ini
+sections=FUTURE,STDLIB,FIRSTPARTY,THIRDPARTY,LOCALFOLDER
+```
+
+You also can define your own sections and their order.
+
+Example:
+
+```ini
+known_django=django
+known_pandas=pandas,numpy
+sections=FUTURE,STDLIB,DJANGO,THIRDPARTY,PANDAS,FIRSTPARTY,LOCALFOLDER
+```
+
+would create two new sections with the specified known modules.
+
+The `no_lines_before` option will prevent the listed sections from being
+split from the previous section by an empty line.
+
+Example:
+
+```ini
+sections=FUTURE,STDLIB,THIRDPARTY,FIRSTPARTY,LOCALFOLDER
+no_lines_before=LOCALFOLDER
+```
+
+would produce a section with both FIRSTPARTY and LOCALFOLDER modules
+combined.
+
+**IMPORTANT NOTE**: It is very important to know when setting `known` sections that the naming
+does not directly map for historical reasons. For custom settings, the only difference is
+capitalization (`known_custom=custom` VS `sections=CUSTOM,...`) for all others reference the
+following mapping:
+
+ - `known_standard_library` : `STANDARD_LIBRARY`
+ - `extra_standard_library` : `STANDARD_LIBRARY` # Like known standard library but appends instead of replacing
+ - `known_future_library` : `FUTURE`
+ - `known_first_party`: `FIRSTPARTY`
+ - `known_third_party`: `THIRDPARTY`
+ - `known_local_folder`: `LOCALFOLDER`
+
+This will likely be changed in isort 6.0.0+ in a backwards compatible way.
+
+## Auto-comment import sections
+
+Some projects prefer to have import sections uniquely titled to aid in
+identifying the sections quickly when visually scanning. isort can
+automate this as well. To do this simply set the
+`import_heading_{section_name}` setting for each section you wish to
+have auto commented - to the desired comment.
+
+For Example:
+
+```ini
+import_heading_stdlib=Standard Library
+import_heading_firstparty=My Stuff
+```
+
+Would lead to output looking like the following:
+
+```python
+# Standard Library
+import os
+import sys
+
+import django.settings
+
+# My Stuff
+import myproject.test
+```
+
+## Ordering by import length
+
+isort also makes it easy to sort your imports by length, simply by
+setting the `length_sort` option to `True`. This will result in the
+following output style:
+
+```python
+from evn.util import (
+ Pool,
+ Dict,
+ Options,
+ Constant,
+ DecayDict,
+ UnexpectedCodePath,
+)
+```
+
+It is also possible to opt-in to sorting imports by length for only
+specific sections by using `length_sort_` followed by the section name
+as a configuration item, e.g.:
+
+ length_sort_stdlib=1
+
+## Controlling how isort sections `from` imports
+
+By default isort places straight (`import y`) imports above from imports (`from x import y`):
+
+```python
+import b
+from a import a # This will always appear below because it is a from import.
+```
+
+However, if you prefer to keep strict alphabetical sorting you can set [force sort within sections](https://timothycrosley.github.io/isort/docs/configuration/options/#force-sort-within-sections) to true. Resulting in:
+
+
+```python
+from a import a # This will now appear at top because a appears in the alphabet before b
+import b
+```
+
+You can even tell isort to always place from imports on top, instead of the default of placing them on bottom, using [from first](https://timothycrosley.github.io/isort/docs/configuration/options/#from-first).
+
+```python
+from b import b # If from first is set to True, all from imports will be placed before non-from imports.
+import a
+```
+
+## Skip processing of imports (outside of configuration)
+
+To make isort ignore a single import simply add a comment at the end of
+the import line containing the text `isort:skip`:
+
+```python
+import module # isort:skip
+```
+
+or:
+
+```python
+from xyz import (abc, # isort:skip
+ yo,
+ hey)
+```
+
+To make isort skip an entire file simply add `isort:skip_file` to the
+module's doc string:
+
+```python
+""" my_module.py
+ Best module ever
+
+ isort:skip_file
+"""
+
+import b
+import a
+```
+
+## Adding an import to multiple files
+
+isort makes it easy to add an import statement across multiple files,
+while being assured it's correctly placed.
+
+To add an import to all files:
+
+```bash
+isort -a "from __future__ import print_function" *.py
+```
+
+To add an import only to files that already have imports:
+
+```bash
+isort -a "from __future__ import print_function" --append-only *.py
+```
+
+
+## Removing an import from multiple files
+
+isort also makes it easy to remove an import from multiple files,
+without having to be concerned with how it was originally formatted.
+
+From the command line:
+
+```bash
+isort --rm "os.system" *.py
+```
+
+## Using isort to verify code
+
+The `--check-only` option
+-------------------------
+
+isort can also be used to used to verify that code is correctly
+formatted by running it with `-c`. Any files that contain incorrectly
+sorted and/or formatted imports will be outputted to `stderr`.
+
+```bash
+isort **/*.py -c -v
+
+SUCCESS: /home/timothy/Projects/Open_Source/isort/isort_kate_plugin.py Everything Looks Good!
+ERROR: /home/timothy/Projects/Open_Source/isort/isort/isort.py Imports are incorrectly sorted.
+```
+
+One great place this can be used is with a pre-commit git hook, such as
+this one by \@acdha:
+
+<https://gist.github.com/acdha/8717683>
+
+This can help to ensure a certain level of code quality throughout a
+project.
+
+Git hook
+--------
+
+isort provides a hook function that can be integrated into your Git
+pre-commit script to check Python code before committing.
+
+To cause the commit to fail if there are isort errors (strict mode),
+include the following in `.git/hooks/pre-commit`:
+
+```python
+#!/usr/bin/env python
+import sys
+from isort.hooks import git_hook
+
+sys.exit(git_hook(strict=True, modify=True, lazy=True))
+```
+
+If you just want to display warnings, but allow the commit to happen
+anyway, call `git_hook` without the strict parameter. If you want to
+display warnings, but not also fix the code, call `git_hook` without the
+modify parameter.
+The `lazy` argument is to support users who are "lazy" to add files
+individually to the index and tend to use `git commit -a` instead.
+Set it to `True` to ensure all tracked files are properly isorted,
+leave it out or set it to `False` to check only files added to your
+index.
+
+## Setuptools integration
+
+Upon installation, isort enables a `setuptools` command that checks
+Python files declared by your project.
+
+Running `python setup.py isort` on the command line will check the files
+listed in your `py_modules` and `packages`. If any warning is found, the
+command will exit with an error code:
+
+```bash
+$ python setup.py isort
+```
+
+Also, to allow users to be able to use the command without having to
+install isort themselves, add isort to the setup\_requires of your
+`setup()` like so:
+
+```python
+setup(
+ name="project",
+ packages=["project"],
+
+ setup_requires=[
+ "isort"
+ ]
+)
+```
+
+## Spread the word
+
+[](https://timothycrosley.github.io/isort/)
+
+Place this badge at the top of your repository to let others know your project uses isort.
+
+For README.md:
+
+```markdown
+[](https://timothycrosley.github.io/isort/)
+```
+
+Or README.rst:
+
+```rst
+.. image:: https://img.shields.io/badge/%20imports-isort-%231674b1?style=flat&labelColor=ef8336
+ :target: https://timothycrosley.github.io/isort/
+```
+
+## Security contact information
+
+To report a security vulnerability, please use the [Tidelift security
+contact](https://tidelift.com/security). Tidelift will coordinate the
+fix and disclosure.
+
+## Why isort?
+
+isort simply stands for import sort. It was originally called
+"sortImports" however I got tired of typing the extra characters and
+came to the realization camelCase is not pythonic.
+
+I wrote isort because in an organization I used to work in the manager
+came in one day and decided all code must have alphabetically sorted
+imports. The code base was huge - and he meant for us to do it by hand.
+However, being a programmer - I\'m too lazy to spend 8 hours mindlessly
+performing a function, but not too lazy to spend 16 hours automating it.
+I was given permission to open source sortImports and here we are :)
+
+------------------------------------------------------------------------
+
+[Get professionally supported isort with the Tidelift
+Subscription](https://tidelift.com/subscription/pkg/pypi-isort?utm_source=pypi-isort&utm_medium=referral&utm_campaign=readme)
+
+Professional support for isort is available as part of the [Tidelift
+Subscription](https://tidelift.com/subscription/pkg/pypi-isort?utm_source=pypi-isort&utm_medium=referral&utm_campaign=readme).
+Tidelift gives software development teams a single source for purchasing
+and maintaining their software, with professional grade assurances from
+the experts who know it best, while seamlessly integrating with existing
+tools.
+
+------------------------------------------------------------------------
+
+Thanks and I hope you find isort useful!
+
+~Timothy Crosley
+
diff --git a/venv/Lib/site-packages/isort-5.4.2.dist-info/RECORD b/venv/Lib/site-packages/isort-5.4.2.dist-info/RECORD
new file mode 100644
index 0000000..c181141
--- /dev/null
+++ b/venv/Lib/site-packages/isort-5.4.2.dist-info/RECORD
@@ -0,0 +1,97 @@
+../../Scripts/isort.exe,sha256=Zpw9tE87YuoOS4aV4XGw1vUS_DjIrOR-3hBSasbB2Do,106369
+isort-5.4.2.dist-info/INSTALLER,sha256=zuuue4knoyJ-UwPPXg8fezS7VCrXJQrAP7zeNuwvFQg,4
+isort-5.4.2.dist-info/LICENSE,sha256=BjKUABw9Uj26y6ud1UrCKZgnVsyvWSylMkCysM3YIGU,1089
+isort-5.4.2.dist-info/METADATA,sha256=DeBAWU6fk135MZXZzo4U9F8Wh3fQZjFm4X6abQDsDxI,19579
+isort-5.4.2.dist-info/RECORD,,
+isort-5.4.2.dist-info/REQUESTED,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+isort-5.4.2.dist-info/WHEEL,sha256=xSvaL1DM8LOHfdyo0cCcwjZu1tC6CnCsRGWUgazvlbM,83
+isort-5.4.2.dist-info/entry_points.txt,sha256=_Iy7m5GNm89oXcjsXzVEFav4wXWsTqKXiZUARWjFI7M,148
+isort/__init__.py,sha256=u8zdFTPFro_l9J7JzdeNSlu6CU6BboY3fRTuloxbl7c,374
+isort/__main__.py,sha256=iK0trzN9CCXpQX-XPZDZ9JVkm2Lc0q0oiAgsa6FkJb4,36
+isort/__pycache__/__init__.cpython-38.pyc,,
+isort/__pycache__/__main__.cpython-38.pyc,,
+isort/__pycache__/_version.cpython-38.pyc,,
+isort/__pycache__/api.cpython-38.pyc,,
+isort/__pycache__/comments.cpython-38.pyc,,
+isort/__pycache__/core.cpython-38.pyc,,
+isort/__pycache__/exceptions.cpython-38.pyc,,
+isort/__pycache__/format.cpython-38.pyc,,
+isort/__pycache__/hooks.cpython-38.pyc,,
+isort/__pycache__/io.cpython-38.pyc,,
+isort/__pycache__/literal.cpython-38.pyc,,
+isort/__pycache__/logo.cpython-38.pyc,,
+isort/__pycache__/main.cpython-38.pyc,,
+isort/__pycache__/output.cpython-38.pyc,,
+isort/__pycache__/parse.cpython-38.pyc,,
+isort/__pycache__/place.cpython-38.pyc,,
+isort/__pycache__/profiles.cpython-38.pyc,,
+isort/__pycache__/pylama_isort.cpython-38.pyc,,
+isort/__pycache__/sections.cpython-38.pyc,,
+isort/__pycache__/settings.cpython-38.pyc,,
+isort/__pycache__/setuptools_commands.cpython-38.pyc,,
+isort/__pycache__/sorting.cpython-38.pyc,,
+isort/__pycache__/utils.cpython-38.pyc,,
+isort/__pycache__/wrap.cpython-38.pyc,,
+isort/__pycache__/wrap_modes.cpython-38.pyc,,
+isort/_future/__init__.py,sha256=wn-Aa4CVe0zZfA_YBTkJqb6LA9HR9NgpAp0uatzNRNs,326
+isort/_future/__pycache__/__init__.cpython-38.pyc,,
+isort/_future/__pycache__/_dataclasses.cpython-38.pyc,,
+isort/_future/_dataclasses.py,sha256=sjuvr80ZnihMsZ5HBTNplgPfhQ-L5xHIh1aOzEtOscQ,44066
+isort/_vendored/toml/LICENSE,sha256=LZKUgj32yJNXyL5JJ_znk2HWVh5e51MtWSbmOTmqpTY,1252
+isort/_vendored/toml/__init__.py,sha256=gKOk-Amczi2juJsOs1D6UEToaPSIIgNh95Yo5N5gneE,703
+isort/_vendored/toml/__pycache__/__init__.cpython-38.pyc,,
+isort/_vendored/toml/__pycache__/decoder.cpython-38.pyc,,
+isort/_vendored/toml/__pycache__/encoder.cpython-38.pyc,,
+isort/_vendored/toml/__pycache__/ordered.cpython-38.pyc,,
+isort/_vendored/toml/__pycache__/tz.cpython-38.pyc,,
+isort/_vendored/toml/decoder.py,sha256=5etBKNvVLFAR0rhLCJ9fnRTlqkebI4ZQeoJi_myFbd4,37713
+isort/_vendored/toml/encoder.py,sha256=gQOXYnAWo27Jc_przA1FqLX5AgwbdgN-qDHQtKRx300,9668
+isort/_vendored/toml/ordered.py,sha256=aW5woa5xOqR4BjIz9t10_lghxyhF54KQ7FqUNVv7WJ0,334
+isort/_vendored/toml/tz.py,sha256=8TAiXrTqU08sE0ruz2TXH_pFY2rlwNKE47MSE4rDo8Y,618
+isort/_version.py,sha256=FeLZIE8encwqUtsr94yKhYavIqQmfviy9Ah69YgUhLU,22
+isort/api.py,sha256=QJegKmNa6fo5FABTDK9j16b3OgmNIT9ziIsApeTjYDQ,15705
+isort/comments.py,sha256=23uMZZbUn8y3glMW6_WftnEhECvc-4LW4ysEghpYUUU,962
+isort/core.py,sha256=rKmnMA7nsW9yNLInT-GE2pLtbPOea8U0MyyT3tUSnaA,16417
+isort/deprecated/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+isort/deprecated/__pycache__/__init__.cpython-38.pyc,,
+isort/deprecated/__pycache__/finders.cpython-38.pyc,,
+isort/deprecated/finders.py,sha256=N-ujofD6auS5ZPjtaeIB5S2lZk-7Dmx17w57DeU0Q_U,14488
+isort/exceptions.py,sha256=Jxk4rfvI4TcaBcmVT2VD5LcEzwCbVQh6BXPfjP_Gmvc,4635
+isort/format.py,sha256=c5jt_mbYBG5uCXRVCTk51YR-BNjtbDVOXJpZQ2XLZR8,4112
+isort/hooks.py,sha256=iO3Pj-rW9GrMTD-znGYUMOr8TA0A8VVhujn6F8d6ILM,2716
+isort/io.py,sha256=30v6ZH7ntl6hAZGAArB5G1uol1FiQ8qb97s1G71Hwt4,1757
+isort/literal.py,sha256=PQRMWSkbbP3pEhj88pFhSjX6Q3IH-_Pn_XdLf4D7a2M,3548
+isort/logo.py,sha256=cL3al79O7O0G2viqRMRfBPp0qtRZmJw2nHSCZw8XWdQ,388
+isort/main.py,sha256=VtJ6tHYe_rfAI0ZGE6RLtfcuqo3DKM2wT3SnAqJVhtY,31757
+isort/output.py,sha256=8x59vLumT2qtgcZ4tGSO3x0Jw7-bTXUjZtQPn2fqocw,22505
+isort/parse.py,sha256=kPr-ekBkrff8FWgUnuQnGMyiwKSV89HuoZWqsgt6-fM,19244
+isort/place.py,sha256=S3eRp3EVsIq7LDgb4QN1jb7-dvtfXXr48EqJsMP54-Y,3289
+isort/profiles.py,sha256=CyCEpF1iOgrfxvC2nnRAjuKxxuojVN5NViyE-OlFciU,1502
+isort/pylama_isort.py,sha256=Qk8XqicFOn7EhVVQl-gmlybh4WVWbKaDYM8koDB8Dg8,897
+isort/sections.py,sha256=xG5bwU4tOIKUmeBBhZ45EIfjP8HgDOx796bPvD5zWCw,297
+isort/settings.py,sha256=foh76t6eWssSJXMIFXm0VCbUas2Oj7wcY2NKrTyRcAU,26573
+isort/setuptools_commands.py,sha256=2EIVYwUYAurcihzYSIDXV6zKHM-DxqxHBW-x7UnI3No,2223
+isort/sorting.py,sha256=DwRFS02vzRv-ZPTwenhYQQ0vV6owTcHQVK6q_nzqtio,2803
+isort/stdlibs/__init__.py,sha256=MgiO4yPeJZ6ieWz5qSw2LuY7pVmRjZUaCqyUaLH5qJQ,64
+isort/stdlibs/__pycache__/__init__.cpython-38.pyc,,
+isort/stdlibs/__pycache__/all.cpython-38.pyc,,
+isort/stdlibs/__pycache__/py2.cpython-38.pyc,,
+isort/stdlibs/__pycache__/py27.cpython-38.pyc,,
+isort/stdlibs/__pycache__/py3.cpython-38.pyc,,
+isort/stdlibs/__pycache__/py35.cpython-38.pyc,,
+isort/stdlibs/__pycache__/py36.cpython-38.pyc,,
+isort/stdlibs/__pycache__/py37.cpython-38.pyc,,
+isort/stdlibs/__pycache__/py38.cpython-38.pyc,,
+isort/stdlibs/__pycache__/py39.cpython-38.pyc,,
+isort/stdlibs/all.py,sha256=n8Es1WK6UlupYyVvf1PDjGbionqix-afC3LkY8nzTcw,57
+isort/stdlibs/py2.py,sha256=dTgWTa7ggz1cwN8fuI9eIs9-5nTmkRxG_uO61CGwfXI,41
+isort/stdlibs/py27.py,sha256=-Id4l2pjAOMXUfwDNnIBR2o8I_mW_Ghmuek2b82Bczk,4492
+isort/stdlibs/py3.py,sha256=4NpsSHXy9mU4pc3nazM6GTB9RD7iqN2JV9n6SUA672w,101
+isort/stdlibs/py35.py,sha256=SVZp9jaCVq4kSjbKcVgF8dJttyFCqcl20ydodsmHrqE,3283
+isort/stdlibs/py36.py,sha256=tCGWDZXWlJJI4_845yOhTpIvnU0-a3TouD_xsMEIZ3s,3298
+isort/stdlibs/py37.py,sha256=nYZmN-s3qMmAHHddegQv6U0j4cnAH0e5SmqTiG6mmhQ,3322
+isort/stdlibs/py38.py,sha256=KE_65iAHg7icOv2xSGScdJWjwBZGuSQYfYcTSIoo_d8,3307
+isort/stdlibs/py39.py,sha256=gHmC2xbsvrqqxybV9G7vrKRv7UmZpgt9NybAhR1LANk,3295
+isort/utils.py,sha256=D_NmQoPoQSTmLzy5HLcZF1hMK9DIj7vzlGDkMWR0c5E,980
+isort/wrap.py,sha256=W73QcVU_4d_LZ19Fh-Oh3eRCcjNeWqHvGSioqqRSsqo,5353
+isort/wrap_modes.py,sha256=EOkrjlWnL_m0SI7f0UtLUwsrWjv6lPaUsTnKevxAQLw,10948
diff --git a/venv/Lib/site-packages/isort-5.4.2.dist-info/REQUESTED b/venv/Lib/site-packages/isort-5.4.2.dist-info/REQUESTED
new file mode 100644
index 0000000..e69de29
diff --git a/venv/Lib/site-packages/isort-5.4.2.dist-info/WHEEL b/venv/Lib/site-packages/isort-5.4.2.dist-info/WHEEL
new file mode 100644
index 0000000..bbb3489
--- /dev/null
+++ b/venv/Lib/site-packages/isort-5.4.2.dist-info/WHEEL
@@ -0,0 +1,4 @@
+Wheel-Version: 1.0
+Generator: poetry 1.0.5
+Root-Is-Purelib: true
+Tag: py3-none-any
diff --git a/venv/Lib/site-packages/isort-5.4.2.dist-info/entry_points.txt b/venv/Lib/site-packages/isort-5.4.2.dist-info/entry_points.txt
new file mode 100644
index 0000000..ff609bb
--- /dev/null
+++ b/venv/Lib/site-packages/isort-5.4.2.dist-info/entry_points.txt
@@ -0,0 +1,9 @@
+[console_scripts]
+isort=isort.main:main
+
+[distutils.commands]
+isort=isort.main:ISortCommand
+
+[pylama.linter]
+isort=isort=isort.pylama_isort:Linter
+
diff --git a/venv/Lib/site-packages/isort/__init__.py b/venv/Lib/site-packages/isort/__init__.py
new file mode 100644
index 0000000..236255d
--- /dev/null
+++ b/venv/Lib/site-packages/isort/__init__.py
@@ -0,0 +1,9 @@
+"""Defines the public isort interface"""
+from . import settings
+from ._version import __version__
+from .api import check_code_string as check_code
+from .api import check_file, check_stream, place_module, place_module_with_reason
+from .api import sort_code_string as code
+from .api import sort_file as file
+from .api import sort_stream as stream
+from .settings import Config
diff --git a/venv/Lib/site-packages/isort/__main__.py b/venv/Lib/site-packages/isort/__main__.py
new file mode 100644
index 0000000..94b1d05
--- /dev/null
+++ b/venv/Lib/site-packages/isort/__main__.py
@@ -0,0 +1,3 @@
+from isort.main import main
+
+main()
diff --git a/venv/Lib/site-packages/isort/_future/__init__.py b/venv/Lib/site-packages/isort/_future/__init__.py
new file mode 100644
index 0000000..4d9ef4b
--- /dev/null
+++ b/venv/Lib/site-packages/isort/_future/__init__.py
@@ -0,0 +1,12 @@
+import sys
+
+if sys.version_info.major <= 3 and sys.version_info.minor <= 6:
+ from . import _dataclasses as dataclasses # type: ignore
+
+else:
+ import dataclasses # type: ignore
+
+dataclass = dataclasses.dataclass # type: ignore
+field = dataclasses.field # type: ignore
+
+__all__ = ["dataclasses", "dataclass", "field"]
diff --git a/venv/Lib/site-packages/isort/_future/_dataclasses.py b/venv/Lib/site-packages/isort/_future/_dataclasses.py
new file mode 100644
index 0000000..a7b113f
--- /dev/null
+++ b/venv/Lib/site-packages/isort/_future/_dataclasses.py
@@ -0,0 +1,1206 @@
+# type: ignore
+# flake8: noqa
+# flake8: noqa
+"""Backport of Python3.7 dataclasses Library
+
+Taken directly from here: https://github.com/ericvsmith/dataclasses
+Licensed under the Apache License: https://github.com/ericvsmith/dataclasses/blob/master/LICENSE.txt
+
+Needed due to isorts strict no non-optional requirements stance.
+
+TODO: Remove once isort only supports 3.7+
+"""
+import copy
+import inspect
+import keyword
+import re
+import sys
+import types
+
+__all__ = [
+ "dataclass",
+ "field",
+ "Field",
+ "FrozenInstanceError",
+ "InitVar",
+ "MISSING",
+ # Helper functions.
+ "fields",
+ "asdict",
+ "astuple",
+ "make_dataclass",
+ "replace",
+ "is_dataclass",
+]
+
+# Conditions for adding methods. The boxes indicate what action the
+# dataclass decorator takes. For all of these tables, when I talk
+# about init=, repr=, eq=, order=, unsafe_hash=, or frozen=, I'm
+# referring to the arguments to the @dataclass decorator. When
+# checking if a dunder method already exists, I mean check for an
+# entry in the class's __dict__. I never check to see if an attribute
+# is defined in a base class.
+
+# Key:
+# +=========+=========================================+
+# + Value | Meaning |
+# +=========+=========================================+
+# | <blank> | No action: no method is added. |
+# +---------+-----------------------------------------+
+# | add | Generated method is added. |
+# +---------+-----------------------------------------+
+# | raise | TypeError is raised. |
+# +---------+-----------------------------------------+
+# | None | Attribute is set to None. |
+# +=========+=========================================+
+
+# __init__
+#
+# +--- init= parameter
+# |
+# v | | |
+# | no | yes | <--- class has __init__ in __dict__?
+# +=======+=======+=======+
+# | False | | |
+# +-------+-------+-------+
+# | True | add | | <- the default
+# +=======+=======+=======+
+
+# __repr__
+#
+# +--- repr= parameter
+# |
+# v | | |
+# | no | yes | <--- class has __repr__ in __dict__?
+# +=======+=======+=======+
+# | False | | |
+# +-------+-------+-------+
+# | True | add | | <- the default
+# +=======+=======+=======+
+
+
+# __setattr__
+# __delattr__
+#
+# +--- frozen= parameter
+# |
+# v | | |
+# | no | yes | <--- class has __setattr__ or __delattr__ in __dict__?
+# +=======+=======+=======+
+# | False | | | <- the default
+# +-------+-------+-------+
+# | True | add | raise |
+# +=======+=======+=======+
+# Raise because not adding these methods would break the "frozen-ness"
+# of the class.
+
+# __eq__
+#
+# +--- eq= parameter
+# |
+# v | | |
+# | no | yes | <--- class has __eq__ in __dict__?
+# +=======+=======+=======+
+# | False | | |
+# +-------+-------+-------+
+# | True | add | | <- the default
+# +=======+=======+=======+
+
+# __lt__
+# __le__
+# __gt__
+# __ge__
+#
+# +--- order= parameter
+# |
+# v | | |
+# | no | yes | <--- class has any comparison method in __dict__?
+# +=======+=======+=======+
+# | False | | | <- the default
+# +-------+-------+-------+
+# | True | add | raise |
+# +=======+=======+=======+
+# Raise because to allow this case would interfere with using
+# functools.total_ordering.
+
+# __hash__
+
+# +------------------- unsafe_hash= parameter
+# | +----------- eq= parameter
+# | | +--- frozen= parameter
+# | | |
+# v v v | | |
+# | no | yes | <--- class has explicitly defined __hash__
+# +=======+=======+=======+========+========+
+# | False | False | False | | | No __eq__, use the base class __hash__
+# +-------+-------+-------+--------+--------+
+# | False | False | True | | | No __eq__, use the base class __hash__
+# +-------+-------+-------+--------+--------+
+# | False | True | False | None | | <-- the default, not hashable
+# +-------+-------+-------+--------+--------+
+# | False | True | True | add | | Frozen, so hashable, allows override
+# +-------+-------+-------+--------+--------+
+# | True | False | False | add | raise | Has no __eq__, but hashable
+# +-------+-------+-------+--------+--------+
+# | True | False | True | add | raise | Has no __eq__, but hashable
+# +-------+-------+-------+--------+--------+
+# | True | True | False | add | raise | Not frozen, but hashable
+# +-------+-------+-------+--------+--------+
+# | True | True | True | add | raise | Frozen, so hashable
+# +=======+=======+=======+========+========+
+# For boxes that are blank, __hash__ is untouched and therefore
+# inherited from the base class. If the base is object, then
+# id-based hashing is used.
+#
+# Note that a class may already have __hash__=None if it specified an
+# __eq__ method in the class body (not one that was created by
+# @dataclass).
+#
+# See _hash_action (below) for a coded version of this table.
+
+
+# Raised when an attempt is made to modify a frozen class.
+class FrozenInstanceError(AttributeError):
+ pass
+
+
+# A sentinel object for default values to signal that a default
+# factory will be used. This is given a nice repr() which will appear
+# in the function signature of dataclasses' constructors.
+class _HAS_DEFAULT_FACTORY_CLASS:
+ def __repr__(self):
+ return "<factory>"
+
+
+_HAS_DEFAULT_FACTORY = _HAS_DEFAULT_FACTORY_CLASS()
+
+# A sentinel object to detect if a parameter is supplied or not. Use
+# a class to give it a better repr.
+class _MISSING_TYPE:
+ pass
+
+
+MISSING = _MISSING_TYPE()
+
+# Since most per-field metadata will be unused, create an empty
+# read-only proxy that can be shared among all fields.
+_EMPTY_METADATA = types.MappingProxyType({})
+
+# Markers for the various kinds of fields and pseudo-fields.
+class _FIELD_BASE:
+ def __init__(self, name):
+ self.name = name
+
+ def __repr__(self):
+ return self.name
+
+
+_FIELD = _FIELD_BASE("_FIELD")
+_FIELD_CLASSVAR = _FIELD_BASE("_FIELD_CLASSVAR")
+_FIELD_INITVAR = _FIELD_BASE("_FIELD_INITVAR")
+
+# The name of an attribute on the class where we store the Field
+# objects. Also used to check if a class is a Data Class.
+_FIELDS = "__dataclass_fields__"
+
+# The name of an attribute on the class that stores the parameters to
+# @dataclass.
+_PARAMS = "__dataclass_params__"
+
+# The name of the function, that if it exists, is called at the end of
+# __init__.
+_POST_INIT_NAME = "__post_init__"
+
+# String regex that string annotations for ClassVar or InitVar must match.
+# Allows "identifier.identifier[" or "identifier[".
+# https://bugs.python.org/issue33453 for details.
+_MODULE_IDENTIFIER_RE = re.compile(r"^(?:\s*(\w+)\s*\.)?\s*(\w+)")
+
+
+class _InitVarMeta(type):
+ def __getitem__(self, params):
+ return self
+
+
+class InitVar(metaclass=_InitVarMeta):
+ pass
+
+
+# Instances of Field are only ever created from within this module,
+# and only from the field() function, although Field instances are
+# exposed externally as (conceptually) read-only objects.
+#
+# name and type are filled in after the fact, not in __init__.
+# They're not known at the time this class is instantiated, but it's
+# convenient if they're available later.
+#
+# When cls._FIELDS is filled in with a list of Field objects, the name
+# and type fields will have been populated.
+class Field:
+ __slots__ = (
+ "name",
+ "type",
+ "default",
+ "default_factory",
+ "repr",
+ "hash",
+ "init",
+ "compare",
+ "metadata",
+ "_field_type", # Private: not to be used by user code.
+ )
+
+ def __init__(self, default, default_factory, init, repr, hash, compare, metadata):
+ self.name = None
+ self.type = None
+ self.default = default
+ self.default_factory = default_factory
+ self.init = init
+ self.repr = repr
+ self.hash = hash
+ self.compare = compare
+ self.metadata = (
+ _EMPTY_METADATA
+ if metadata is None or len(metadata) == 0
+ else types.MappingProxyType(metadata)
+ )
+ self._field_type = None
+
+ def __repr__(self):
+ return (
+ "Field("
+ f"name={self.name!r},"
+ f"type={self.type!r},"
+ f"default={self.default!r},"
+ f"default_factory={self.default_factory!r},"
+ f"init={self.init!r},"
+ f"repr={self.repr!r},"
+ f"hash={self.hash!r},"
+ f"compare={self.compare!r},"
+ f"metadata={self.metadata!r},"
+ f"_field_type={self._field_type}"
+ ")"
+ )
+
+ # This is used to support the PEP 487 __set_name__ protocol in the
+ # case where we're using a field that contains a descriptor as a
+ # defaul value. For details on __set_name__, see
+ # https://www.python.org/dev/peps/pep-0487/#implementation-details.
+ #
+ # Note that in _process_class, this Field object is overwritten
+ # with the default value, so the end result is a descriptor that
+ # had __set_name__ called on it at the right time.
+ def __set_name__(self, owner, name):
+ func = getattr(type(self.default), "__set_name__", None)
+ if func:
+ # There is a __set_name__ method on the descriptor, call
+ # it.
+ func(self.default, owner, name)
+
+
+class _DataclassParams:
+ __slots__ = ("init", "repr", "eq", "order", "unsafe_hash", "frozen")
+
+ def __init__(self, init, repr, eq, order, unsafe_hash, frozen):
+ self.init = init
+ self.repr = repr
+ self.eq = eq
+ self.order = order
+ self.unsafe_hash = unsafe_hash
+ self.frozen = frozen
+
+ def __repr__(self):
+ return (
+ "_DataclassParams("
+ f"init={self.init!r},"
+ f"repr={self.repr!r},"
+ f"eq={self.eq!r},"
+ f"order={self.order!r},"
+ f"unsafe_hash={self.unsafe_hash!r},"
+ f"frozen={self.frozen!r}"
+ ")"
+ )
+
+
+# This function is used instead of exposing Field creation directly,
+# so that a type checker can be told (via overloads) that this is a
+# function whose type depends on its parameters.
+def field(
+ *,
+ default=MISSING,
+ default_factory=MISSING,
+ init=True,
+ repr=True,
+ hash=None,
+ compare=True,
+ metadata=None,
+):
+ """Return an object to identify dataclass fields.
+ default is the default value of the field. default_factory is a
+ 0-argument function called to initialize a field's value. If init
+ is True, the field will be a parameter to the class's __init__()
+ function. If repr is True, the field will be included in the
+ object's repr(). If hash is True, the field will be included in
+ the object's hash(). If compare is True, the field will be used
+ in comparison functions. metadata, if specified, must be a
+ mapping which is stored but not otherwise examined by dataclass.
+ It is an error to specify both default and default_factory.
+ """
+
+ if default is not MISSING and default_factory is not MISSING:
+ raise ValueError("cannot specify both default and default_factory")
+ return Field(default, default_factory, init, repr, hash, compare, metadata)
+
+
+def _tuple_str(obj_name, fields):
+ # Return a string representing each field of obj_name as a tuple
+ # member. So, if fields is ['x', 'y'] and obj_name is "self",
+ # return "(self.x,self.y)".
+
+ # Special case for the 0-tuple.
+ if not fields:
+ return "()"
+ # Note the trailing comma, needed if this turns out to be a 1-tuple.
+ return f'({",".join(f"{obj_name}.{f.name}" for f in fields)},)'
+
+
+def _create_fn(name, args, body, *, globals=None, locals=None, return_type=MISSING):
+ # Note that we mutate locals when exec() is called. Caller
+ # beware! The only callers are internal to this module, so no
+ # worries about external callers.
+ if locals is None:
+ locals = {}
+ return_annotation = ""
+ if return_type is not MISSING:
+ locals["_return_type"] = return_type
+ return_annotation = "->_return_type"
+ args = ",".join(args)
+ body = "\n".join(f" {b}" for b in body)
+
+ # Compute the text of the entire function.
+ txt = f"def {name}({args}){return_annotation}:\n{body}"
+
+ exec(txt, globals, locals) # nosec
+ return locals[name]
+
+
+def _field_assign(frozen, name, value, self_name):
+ # If we're a frozen class, then assign to our fields in __init__
+ # via object.__setattr__. Otherwise, just use a simple
+ # assignment.
+ #
+ # self_name is what "self" is called in this function: don't
+ # hard-code "self", since that might be a field name.
+ if frozen:
+ return f"object.__setattr__({self_name},{name!r},{value})"
+ return f"{self_name}.{name}={value}"
+
+
+def _field_init(f, frozen, globals, self_name):
+ # Return the text of the line in the body of __init__ that will
+ # initialize this field.
+
+ default_name = f"_dflt_{f.name}"
+ if f.default_factory is not MISSING:
+ if f.init:
+ # This field has a default factory. If a parameter is
+ # given, use it. If not, call the factory.
+ globals[default_name] = f.default_factory
+ value = f"{default_name}() " f"if {f.name} is _HAS_DEFAULT_FACTORY " f"else {f.name}"
+ else:
+ # This is a field that's not in the __init__ params, but
+ # has a default factory function. It needs to be
+ # initialized here by calling the factory function,
+ # because there's no other way to initialize it.
+
+ # For a field initialized with a default=defaultvalue, the
+ # class dict just has the default value
+ # (cls.fieldname=defaultvalue). But that won't work for a
+ # default factory, the factory must be called in __init__
+ # and we must assign that to self.fieldname. We can't
+ # fall back to the class dict's value, both because it's
+ # not set, and because it might be different per-class
+ # (which, after all, is why we have a factory function!).
+
+ globals[default_name] = f.default_factory
+ value = f"{default_name}()"
+ else:
+ # No default factory.
+ if f.init:
+ if f.default is MISSING:
+ # There's no default, just do an assignment.
+ value = f.name
+ elif f.default is not MISSING:
+ globals[default_name] = f.default
+ value = f.name
+ else:
+ # This field does not need initialization. Signify that
+ # to the caller by returning None.
+ return None
+
+ # Only test this now, so that we can create variables for the
+ # default. However, return None to signify that we're not going
+ # to actually do the assignment statement for InitVars.
+ if f._field_type == _FIELD_INITVAR:
+ return None
+
+ # Now, actually generate the field assignment.
+ return _field_assign(frozen, f.name, value, self_name)
+
+
+def _init_param(f):
+ # Return the __init__ parameter string for this field. For
+ # example, the equivalent of 'x:int=3' (except instead of 'int',
+ # reference a variable set to int, and instead of '3', reference a
+ # variable set to 3).
+ if f.default is MISSING and f.default_factory is MISSING:
+ # There's no default, and no default_factory, just output the
+ # variable name and type.
+ default = ""
+ elif f.default is not MISSING:
+ # There's a default, this will be the name that's used to look
+ # it up.
+ default = f"=_dflt_{f.name}"
+ elif f.default_factory is not MISSING:
+ # There's a factory function. Set a marker.
+ default = "=_HAS_DEFAULT_FACTORY"
+ return f"{f.name}:_type_{f.name}{default}"
+
+
+def _init_fn(fields, frozen, has_post_init, self_name):
+ # fields contains both real fields and InitVar pseudo-fields.
+
+ # Make sure we don't have fields without defaults following fields
+ # with defaults. This actually would be caught when exec-ing the
+ # function source code, but catching it here gives a better error
+ # message, and future-proofs us in case we build up the function
+ # using ast.
+ seen_default = False
+ for f in fields:
+ # Only consider fields in the __init__ call.
+ if f.init:
+ if not (f.default is MISSING and f.default_factory is MISSING):
+ seen_default = True
+ elif seen_default:
+ raise TypeError(f"non-default argument {f.name!r} " "follows default argument")
+
+ globals = {"MISSING": MISSING, "_HAS_DEFAULT_FACTORY": _HAS_DEFAULT_FACTORY}
+
+ body_lines = []
+ for f in fields:
+ line = _field_init(f, frozen, globals, self_name)
+ # line is None means that this field doesn't require
+ # initialization (it's a pseudo-field). Just skip it.
+ if line:
+ body_lines.append(line)
+
+ # Does this class have a post-init function?
+ if has_post_init:
+ params_str = ",".join(f.name for f in fields if f._field_type is _FIELD_INITVAR)
+ body_lines.append(f"{self_name}.{_POST_INIT_NAME}({params_str})")
+
+ # If no body lines, use 'pass'.
+ if not body_lines:
+ body_lines = ["pass"]
+
+ locals = {f"_type_{f.name}": f.type for f in fields}
+ return _create_fn(
+ "__init__",
+ [self_name] + [_init_param(f) for f in fields if f.init],
+ body_lines,
+ locals=locals,
+ globals=globals,
+ return_type=None,
+ )
+
+
+def _repr_fn(fields):
+ return _create_fn(
+ "__repr__",
+ ("self",),
+ [
+ 'return self.__class__.__qualname__ + f"('
+ + ", ".join(f"{f.name}={{self.{f.name}!r}}" for f in fields)
+ + ')"'
+ ],
+ )
+
+
+def _frozen_get_del_attr(cls, fields):
+ # XXX: globals is modified on the first call to _create_fn, then
+ # the modified version is used in the second call. Is this okay?
+ globals = {"cls": cls, "FrozenInstanceError": FrozenInstanceError}
+ if fields:
+ fields_str = "(" + ",".join(repr(f.name) for f in fields) + ",)"
+ else:
+ # Special case for the zero-length tuple.
+ fields_str = "()"
+ return (
+ _create_fn(
+ "__setattr__",
+ ("self", "name", "value"),
+ (
+ f"if type(self) is cls or name in {fields_str}:",
+ ' raise FrozenInstanceError(f"cannot assign to field {name!r}")',
+ f"super(cls, self).__setattr__(name, value)",
+ ),
+ globals=globals,
+ ),
+ _create_fn(
+ "__delattr__",
+ ("self", "name"),
+ (
+ f"if type(self) is cls or name in {fields_str}:",
+ ' raise FrozenInstanceError(f"cannot delete field {name!r}")',
+ f"super(cls, self).__delattr__(name)",
+ ),
+ globals=globals,
+ ),
+ )
+
+
+def _cmp_fn(name, op, self_tuple, other_tuple):
+ # Create a comparison function. If the fields in the object are
+ # named 'x' and 'y', then self_tuple is the string
+ # '(self.x,self.y)' and other_tuple is the string
+ # '(other.x,other.y)'.
+
+ return _create_fn(
+ name,
+ ("self", "other"),
+ [
+ "if other.__class__ is self.__class__:",
+ f" return {self_tuple}{op}{other_tuple}",
+ "return NotImplemented",
+ ],
+ )
+
+
+def _hash_fn(fields):
+ self_tuple = _tuple_str("self", fields)
+ return _create_fn("__hash__", ("self",), [f"return hash({self_tuple})"])
+
+
+def _is_classvar(a_type, typing):
+ # This test uses a typing internal class, but it's the best way to
+ # test if this is a ClassVar.
+ return type(a_type) is typing._ClassVar
+
+
+def _is_initvar(a_type, dataclasses):
+ # The module we're checking against is the module we're
+ # currently in (dataclasses.py).
+ return a_type is dataclasses.InitVar
+
+
+def _is_type(annotation, cls, a_module, a_type, is_type_predicate):
+ # Given a type annotation string, does it refer to a_type in
+ # a_module? For example, when checking that annotation denotes a
+ # ClassVar, then a_module is typing, and a_type is
+ # typing.ClassVar.
+
+ # It's possible to look up a_module given a_type, but it involves
+ # looking in sys.modules (again!), and seems like a waste since
+ # the caller already knows a_module.
+
+ # - annotation is a string type annotation
+ # - cls is the class that this annotation was found in
+ # - a_module is the module we want to match
+ # - a_type is the type in that module we want to match
+ # - is_type_predicate is a function called with (obj, a_module)
+ # that determines if obj is of the desired type.
+
+ # Since this test does not do a local namespace lookup (and
+ # instead only a module (global) lookup), there are some things it
+ # gets wrong.
+
+ # With string annotations, cv0 will be detected as a ClassVar:
+ # CV = ClassVar
+ # @dataclass
+ # class C0:
+ # cv0: CV
+
+ # But in this example cv1 will not be detected as a ClassVar:
+ # @dataclass
+ # class C1:
+ # CV = ClassVar
+ # cv1: CV
+
+ # In C1, the code in this function (_is_type) will look up "CV" in
+ # the module and not find it, so it will not consider cv1 as a
+ # ClassVar. This is a fairly obscure corner case, and the best
+ # way to fix it would be to eval() the string "CV" with the
+ # correct global and local namespaces. However that would involve
+ # a eval() penalty for every single field of every dataclass
+ # that's defined. It was judged not worth it.
+
+ match = _MODULE_IDENTIFIER_RE.match(annotation)
+ if match:
+ ns = None
+ module_name = match.group(1)
+ if not module_name:
+ # No module name, assume the class's module did
+ # "from dataclasses import InitVar".
+ ns = sys.modules.get(cls.__module__).__dict__
+ else:
+ # Look up module_name in the class's module.
+ module = sys.modules.get(cls.__module__)
+ if module and module.__dict__.get(module_name) is a_module:
+ ns = sys.modules.get(a_type.__module__).__dict__
+ if ns and is_type_predicate(ns.get(match.group(2)), a_module):
+ return True
+ return False
+
+
+def _get_field(cls, a_name, a_type):
+ # Return a Field object for this field name and type. ClassVars
+ # and InitVars are also returned, but marked as such (see
+ # f._field_type).
+
+ # If the default value isn't derived from Field, then it's only a
+ # normal default value. Convert it to a Field().
+ default = getattr(cls, a_name, MISSING)
+ if isinstance(default, Field):
+ f = default
+ else:
+ if isinstance(default, types.MemberDescriptorType):
+ # This is a field in __slots__, so it has no default value.
+ default = MISSING
+ f = field(default=default)
+
+ # Only at this point do we know the name and the type. Set them.
+ f.name = a_name
+ f.type = a_type
+
+ # Assume it's a normal field until proven otherwise. We're next
+ # going to decide if it's a ClassVar or InitVar, everything else
+ # is just a normal field.
+ f._field_type = _FIELD
+
+ # In addition to checking for actual types here, also check for
+ # string annotations. get_type_hints() won't always work for us
+ # (see https://github.com/python/typing/issues/508 for example),
+ # plus it's expensive and would require an eval for every stirng
+ # annotation. So, make a best effort to see if this is a ClassVar
+ # or InitVar using regex's and checking that the thing referenced
+ # is actually of the correct type.
+
+ # For the complete discussion, see https://bugs.python.org/issue33453
+
+ # If typing has not been imported, then it's impossible for any
+ # annotation to be a ClassVar. So, only look for ClassVar if
+ # typing has been imported by any module (not necessarily cls's
+ # module).
+ typing = sys.modules.get("typing")
+ if typing:
+ if _is_classvar(a_type, typing) or (
+ isinstance(f.type, str) and _is_type(f.type, cls, typing, typing.ClassVar, _is_classvar)
+ ):
+ f._field_type = _FIELD_CLASSVAR
+
+ # If the type is InitVar, or if it's a matching string annotation,
+ # then it's an InitVar.
+ if f._field_type is _FIELD:
+ # The module we're checking against is the module we're
+ # currently in (dataclasses.py).
+ dataclasses = sys.modules[__name__]
+ if _is_initvar(a_type, dataclasses) or (
+ isinstance(f.type, str)
+ and _is_type(f.type, cls, dataclasses, dataclasses.InitVar, _is_initvar)
+ ):
+ f._field_type = _FIELD_INITVAR
+
+ # Validations for individual fields. This is delayed until now,
+ # instead of in the Field() constructor, since only here do we
+ # know the field name, which allows for better error reporting.
+
+ # Special restrictions for ClassVar and InitVar.
+ if f._field_type in (_FIELD_CLASSVAR, _FIELD_INITVAR):
+ if f.default_factory is not MISSING:
+ raise TypeError(f"field {f.name} cannot have a " "default factory")
+ # Should I check for other field settings? default_factory
+ # seems the most serious to check for. Maybe add others. For
+ # example, how about init=False (or really,
+ # init=<not-the-default-init-value>)? It makes no sense for
+ # ClassVar and InitVar to specify init=<anything>.
+
+ # For real fields, disallow mutable defaults for known types.
+ if f._field_type is _FIELD and isinstance(f.default, (list, dict, set)):
+ raise ValueError(
+ f"mutable default {type(f.default)} for field "
+ f"{f.name} is not allowed: use default_factory"
+ )
+
+ return f
+
+
+def _set_new_attribute(cls, name, value):
+ # Never overwrites an existing attribute. Returns True if the
+ # attribute already exists.
+ if name in cls.__dict__:
+ return True
+ setattr(cls, name, value)
+ return False
+
+
+# Decide if/how we're going to create a hash function. Key is
+# (unsafe_hash, eq, frozen, does-hash-exist). Value is the action to
+# take. The common case is to do nothing, so instead of providing a
+# function that is a no-op, use None to signify that.
+
+
+def _hash_set_none(cls, fields):
+ return None
+
+
+def _hash_add(cls, fields):
+ flds = [f for f in fields if (f.compare if f.hash is None else f.hash)]
+ return _hash_fn(flds)
+
+
+def _hash_exception(cls, fields):
+ # Raise an exception.
+ raise TypeError(f"Cannot overwrite attribute __hash__ " f"in class {cls.__name__}")
+
+
+#
+# +-------------------------------------- unsafe_hash?
+# | +------------------------------- eq?
+# | | +------------------------ frozen?
+# | | | +---------------- has-explicit-hash?
+# | | | |
+# | | | | +------- action
+# | | | | |
+# v v v v v
+_hash_action = {
+ (False, False, False, False): None,
+ (False, False, False, True): None,
+ (False, False, True, False): None,
+ (False, False, True, True): None,
+ (False, True, False, False): _hash_set_none,
+ (False, True, False, True): None,
+ (False, True, True, False): _hash_add,
+ (False, True, True, True): None,
+ (True, False, False, False): _hash_add,
+ (True, False, False, True): _hash_exception,
+ (True, False, True, False): _hash_add,
+ (True, False, True, True): _hash_exception,
+ (True, True, False, False): _hash_add,
+ (True, True, False, True): _hash_exception,
+ (True, True, True, False): _hash_add,
+ (True, True, True, True): _hash_exception,
+}
+# See https://bugs.python.org/issue32929#msg312829 for an if-statement
+# version of this table.
+
+
+def _process_class(cls, init, repr, eq, order, unsafe_hash, frozen):
+ # Now that dicts retain insertion order, there's no reason to use
+ # an ordered dict. I am leveraging that ordering here, because
+ # derived class fields overwrite base class fields, but the order
+ # is defined by the base class, which is found first.
+ fields = {}
+
+ setattr(cls, _PARAMS, _DataclassParams(init, repr, eq, order, unsafe_hash, frozen))
+
+ # Find our base classes in reverse MRO order, and exclude
+ # ourselves. In reversed order so that more derived classes
+ # override earlier field definitions in base classes. As long as
+ # we're iterating over them, see if any are frozen.
+ any_frozen_base = False
+ has_dataclass_bases = False
+ for b in cls.__mro__[-1:0:-1]:
+ # Only process classes that have been processed by our
+ # decorator. That is, they have a _FIELDS attribute.
+ base_fields = getattr(b, _FIELDS, None)
+ if base_fields:
+ has_dataclass_bases = True
+ for f in base_fields.values():
+ fields[f.name] = f
+ if getattr(b, _PARAMS).frozen:
+ any_frozen_base = True
+
+ # Annotations that are defined in this class (not in base
+ # classes). If __annotations__ isn't present, then this class
+ # adds no new annotations. We use this to compute fields that are
+ # added by this class.
+ #
+ # Fields are found from cls_annotations, which is guaranteed to be
+ # ordered. Default values are from class attributes, if a field
+ # has a default. If the default value is a Field(), then it
+ # contains additional info beyond (and possibly including) the
+ # actual default value. Pseudo-fields ClassVars and InitVars are
+ # included, despite the fact that they're not real fields. That's
+ # dealt with later.
+ cls_annotations = cls.__dict__.get("__annotations__", {})
+
+ # Now find fields in our class. While doing so, validate some
+ # things, and set the default values (as class attributes) where
+ # we can.
+ cls_fields = [_get_field(cls, name, type) for name, type in cls_annotations.items()]
+ for f in cls_fields:
+ fields[f.name] = f
+
+ # If the class attribute (which is the default value for this
+ # field) exists and is of type 'Field', replace it with the
+ # real default. This is so that normal class introspection
+ # sees a real default value, not a Field.
+ if isinstance(getattr(cls, f.name, None), Field):
+ if f.default is MISSING:
+ # If there's no default, delete the class attribute.
+ # This happens if we specify field(repr=False), for
+ # example (that is, we specified a field object, but
+ # no default value). Also if we're using a default
+ # factory. The class attribute should not be set at
+ # all in the post-processed class.
+ delattr(cls, f.name)
+ else:
+ setattr(cls, f.name, f.default)
+
+ # Do we have any Field members that don't also have annotations?
+ for name, value in cls.__dict__.items():
+ if isinstance(value, Field) and not name in cls_annotations:
+ raise TypeError(f"{name!r} is a field but has no type annotation")
+
+ # Check rules that apply if we are derived from any dataclasses.
+ if has_dataclass_bases:
+ # Raise an exception if any of our bases are frozen, but we're not.
+ if any_frozen_base and not frozen:
+ raise TypeError("cannot inherit non-frozen dataclass from a " "frozen one")
+
+ # Raise an exception if we're frozen, but none of our bases are.
+ if not any_frozen_base and frozen:
+ raise TypeError("cannot inherit frozen dataclass from a " "non-frozen one")
+
+ # Remember all of the fields on our class (including bases). This
+ # also marks this class as being a dataclass.
+ setattr(cls, _FIELDS, fields)
+
+ # Was this class defined with an explicit __hash__? Note that if
+ # __eq__ is defined in this class, then python will automatically
+ # set __hash__ to None. This is a heuristic, as it's possible
+ # that such a __hash__ == None was not auto-generated, but it
+ # close enough.
+ class_hash = cls.__dict__.get("__hash__", MISSING)
+ has_explicit_hash = not (
+ class_hash is MISSING or (class_hash is None and "__eq__" in cls.__dict__)
+ )
+
+ # If we're generating ordering methods, we must be generating the
+ # eq methods.
+ if order and not eq:
+ raise ValueError("eq must be true if order is true")
+
+ if init:
+ # Does this class have a post-init function?
+ has_post_init = hasattr(cls, _POST_INIT_NAME)
+
+ # Include InitVars and regular fields (so, not ClassVars).
+ flds = [f for f in fields.values() if f._field_type in (_FIELD, _FIELD_INITVAR)]
+ _set_new_attribute(
+ cls,
+ "__init__",
+ _init_fn(
+ flds,
+ frozen,
+ has_post_init,
+ # The name to use for the "self"
+ # param in __init__. Use "self"
+ # if possible.
+ "__dataclass_self__" if "self" in fields else "self",
+ ),
+ )
+
+ # Get the fields as a list, and include only real fields. This is
+ # used in all of the following methods.
+ field_list = [f for f in fields.values() if f._field_type is _FIELD]
+
+ if repr:
+ flds = [f for f in field_list if f.repr]
+ _set_new_attribute(cls, "__repr__", _repr_fn(flds))
+
+ if eq:
+ # Create _eq__ method. There's no need for a __ne__ method,
+ # since python will call __eq__ and negate it.
+ flds = [f for f in field_list if f.compare]
+ self_tuple = _tuple_str("self", flds)
+ other_tuple = _tuple_str("other", flds)
+ _set_new_attribute(cls, "__eq__", _cmp_fn("__eq__", "==", self_tuple, other_tuple))
+
+ if order:
+ # Create and set the ordering methods.
+ flds = [f for f in field_list if f.compare]
+ self_tuple = _tuple_str("self", flds)
+ other_tuple = _tuple_str("other", flds)
+ for name, op in [("__lt__", "<"), ("__le__", "<="), ("__gt__", ">"), ("__ge__", ">=")]:
+ if _set_new_attribute(cls, name, _cmp_fn(name, op, self_tuple, other_tuple)):
+ raise TypeError(
+ f"Cannot overwrite attribute {name} "
+ f"in class {cls.__name__}. Consider using "
+ "functools.total_ordering"
+ )
+
+ if frozen:
+ for fn in _frozen_get_del_attr(cls, field_list):
+ if _set_new_attribute(cls, fn.__name__, fn):
+ raise TypeError(
+ f"Cannot overwrite attribute {fn.__name__} " f"in class {cls.__name__}"
+ )
+
+ # Decide if/how we're going to create a hash function.
+ hash_action = _hash_action[bool(unsafe_hash), bool(eq), bool(frozen), has_explicit_hash]
+ if hash_action:
+ # No need to call _set_new_attribute here, since by the time
+ # we're here the overwriting is unconditional.
+ cls.__hash__ = hash_action(cls, field_list)
+
+ if not getattr(cls, "__doc__"):
+ # Create a class doc-string.
+ cls.__doc__ = cls.__name__ + str(inspect.signature(cls)).replace(" -> None", "")
+
+ return cls
+
+
+# _cls should never be specified by keyword, so start it with an
+# underscore. The presence of _cls is used to detect if this
+# decorator is being called with parameters or not.
+def dataclass(
+ _cls=None, *, init=True, repr=True, eq=True, order=False, unsafe_hash=False, frozen=False
+):
+ """Returns the same class as was passed in, with dunder methods
+ added based on the fields defined in the class.
+ Examines PEP 526 __annotations__ to determine fields.
+ If init is true, an __init__() method is added to the class. If
+ repr is true, a __repr__() method is added. If order is true, rich
+ comparison dunder methods are added. If unsafe_hash is true, a
+ __hash__() method function is added. If frozen is true, fields may
+ not be assigned to after instance creation.
+ """
+
+ def wrap(cls):
+ return _process_class(cls, init, repr, eq, order, unsafe_hash, frozen)
+
+ # See if we're being called as @dataclass or @dataclass().
+ if _cls is None:
+ # We're called with parens.
+ return wrap
+
+ # We're called as @dataclass without parens.
+ return wrap(_cls)
+
+
+def fields(class_or_instance):
+ """Return a tuple describing the fields of this dataclass.
+ Accepts a dataclass or an instance of one. Tuple elements are of
+ type Field.
+ """
+
+ # Might it be worth caching this, per class?
+ try:
+ fields = getattr(class_or_instance, _FIELDS)
+ except AttributeError:
+ raise TypeError("must be called with a dataclass type or instance")
+
+ # Exclude pseudo-fields. Note that fields is sorted by insertion
+ # order, so the order of the tuple is as the fields were defined.
+ return tuple(f for f in fields.values() if f._field_type is _FIELD)
+
+
+def _is_dataclass_instance(obj):
+ """Returns True if obj is an instance of a dataclass."""
+ return not isinstance(obj, type) and hasattr(obj, _FIELDS)
+
+
+def is_dataclass(obj):
+ """Returns True if obj is a dataclass or an instance of a
+ dataclass."""
+ return hasattr(obj, _FIELDS)
+
+
+def asdict(obj, *, dict_factory=dict):
+ """Return the fields of a dataclass instance as a new dictionary mapping
+ field names to field values.
+ Example usage:
+ @dataclass
+ class C:
+ x: int
+ y: int
+ c = C(1, 2)
+ assert asdict(c) == {'x': 1, 'y': 2}
+ If given, 'dict_factory' will be used instead of built-in dict.
+ The function applies recursively to field values that are
+ dataclass instances. This will also look into built-in containers:
+ tuples, lists, and dicts.
+ """
+ if not _is_dataclass_instance(obj):
+ raise TypeError("asdict() should be called on dataclass instances")
+ return _asdict_inner(obj, dict_factory)
+
+
+def _asdict_inner(obj, dict_factory):
+ if _is_dataclass_instance(obj):
+ result = []
+ for f in fields(obj):
+ value = _asdict_inner(getattr(obj, f.name), dict_factory)
+ result.append((f.name, value))
+ return dict_factory(result)
+ elif isinstance(obj, (list, tuple)):
+ return type(obj)(_asdict_inner(v, dict_factory) for v in obj)
+ elif isinstance(obj, dict):
+ return type(obj)(
+ (_asdict_inner(k, dict_factory), _asdict_inner(v, dict_factory)) for k, v in obj.items()
+ )
+ else:
+ return copy.deepcopy(obj)
+
+
+def astuple(obj, *, tuple_factory=tuple):
+ """Return the fields of a dataclass instance as a new tuple of field values.
+ Example usage::
+ @dataclass
+ class C:
+ x: int
+ y: int
+ c = C(1, 2)
+ assert astuple(c) == (1, 2)
+ If given, 'tuple_factory' will be used instead of built-in tuple.
+ The function applies recursively to field values that are
+ dataclass instances. This will also look into built-in containers:
+ tuples, lists, and dicts.
+ """
+
+ if not _is_dataclass_instance(obj):
+ raise TypeError("astuple() should be called on dataclass instances")
+ return _astuple_inner(obj, tuple_factory)
+
+
+def _astuple_inner(obj, tuple_factory):
+ if _is_dataclass_instance(obj):
+ result = []
+ for f in fields(obj):
+ value = _astuple_inner(getattr(obj, f.name), tuple_factory)
+ result.append(value)
+ return tuple_factory(result)
+ elif isinstance(obj, (list, tuple)):
+ return type(obj)(_astuple_inner(v, tuple_factory) for v in obj)
+ elif isinstance(obj, dict):
+ return type(obj)(
+ (_astuple_inner(k, tuple_factory), _astuple_inner(v, tuple_factory))
+ for k, v in obj.items()
+ )
+ else:
+ return copy.deepcopy(obj)
+
+
+def make_dataclass(
+ cls_name,
+ fields,
+ *,
+ bases=(),
+ namespace=None,
+ init=True,
+ repr=True,
+ eq=True,
+ order=False,
+ unsafe_hash=False,
+ frozen=False,
+):
+ """Return a new dynamically created dataclass.
+ The dataclass name will be 'cls_name'. 'fields' is an iterable
+ of either (name), (name, type) or (name, type, Field) objects. If type is
+ omitted, use the string 'typing.Any'. Field objects are created by
+ the equivalent of calling 'field(name, type [, Field-info])'.
+ C = make_dataclass('C', ['x', ('y', int), ('z', int, field(init=False))], bases=(Base,))
+ is equivalent to:
+ @dataclass
+ class C(Base):
+ x: 'typing.Any'
+ y: int
+ z: int = field(init=False)
+ For the bases and namespace parameters, see the builtin type() function.
+ The parameters init, repr, eq, order, unsafe_hash, and frozen are passed to
+ dataclass().
+ """
+
+ if namespace is None:
+ namespace = {}
+ else:
+ # Copy namespace since we're going to mutate it.
+ namespace = namespace.copy()
+
+ # While we're looking through the field names, validate that they
+ # are identifiers, are not keywords, and not duplicates.
+ seen = set()
+ anns = {}
+ for item in fields:
+ if isinstance(item, str):
+ name = item
+ tp = "typing.Any"
+ elif len(item) == 2:
+ name, tp, = item
+ elif len(item) == 3:
+ name, tp, spec = item
+ namespace[name] = spec
+ else:
+ raise TypeError(f"Invalid field: {item!r}")
+
+ if not isinstance(name, str) or not name.isidentifier():
+ raise TypeError(f"Field names must be valid identifers: {name!r}")
+ if keyword.iskeyword(name):
+ raise TypeError(f"Field names must not be keywords: {name!r}")
+ if name in seen:
+ raise TypeError(f"Field name duplicated: {name!r}")
+
+ seen.add(name)
+ anns[name] = tp
+
+ namespace["__annotations__"] = anns
+ # We use `types.new_class()` instead of simply `type()` to allow dynamic creation
+ # of generic dataclassses.
+ cls = types.new_class(cls_name, bases, {}, lambda ns: ns.update(namespace))
+ return dataclass(
+ cls, init=init, repr=repr, eq=eq, order=order, unsafe_hash=unsafe_hash, frozen=frozen
+ )
+
+
+def replace(obj, **changes):
+ """Return a new object replacing specified fields with new values.
+ This is especially useful for frozen classes. Example usage:
+ @dataclass(frozen=True)
+ class C:
+ x: int
+ y: int
+ c = C(1, 2)
+ c1 = replace(c, x=3)
+ assert c1.x == 3 and c1.y == 2
+ """
+
+ # We're going to mutate 'changes', but that's okay because it's a
+ # new dict, even if called with 'replace(obj, **my_changes)'.
+
+ if not _is_dataclass_instance(obj):
+ raise TypeError("replace() should be called on dataclass instances")
+
+ # It's an error to have init=False fields in 'changes'.
+ # If a field is not in 'changes', read its value from the provided obj.
+
+ for f in getattr(obj, _FIELDS).values():
+ if not f.init:
+ # Error if this field is specified in changes.
+ if f.name in changes:
+ raise ValueError(
+ f"field {f.name} is declared with "
+ "init=False, it cannot be specified with "
+ "replace()"
+ )
+ continue
+
+ if f.name not in changes:
+ changes[f.name] = getattr(obj, f.name)
+
+ # Create the new object, which calls __init__() and
+ # __post_init__() (if defined), using all of the init fields we've
+ # added and/or left in 'changes'. If there are values supplied in
+ # changes that aren't fields, this will correctly raise a
+ # TypeError.
+ return obj.__class__(**changes)
diff --git a/venv/Lib/site-packages/isort/_vendored/toml/LICENSE b/venv/Lib/site-packages/isort/_vendored/toml/LICENSE
new file mode 100644
index 0000000..5010e30
--- /dev/null
+++ b/venv/Lib/site-packages/isort/_vendored/toml/LICENSE
@@ -0,0 +1,27 @@
+The MIT License
+
+Copyright 2013-2019 William Pearson
+Copyright 2015-2016 Julien Enselme
+Copyright 2016 Google Inc.
+Copyright 2017 Samuel Vasko
+Copyright 2017 Nate Prewitt
+Copyright 2017 Jack Evans
+Copyright 2019 Filippo Broggini
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in
+all copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
+THE SOFTWARE.
\ No newline at end of file
diff --git a/venv/Lib/site-packages/isort/_vendored/toml/__init__.py b/venv/Lib/site-packages/isort/_vendored/toml/__init__.py
new file mode 100644
index 0000000..8cefeff
--- /dev/null
+++ b/venv/Lib/site-packages/isort/_vendored/toml/__init__.py
@@ -0,0 +1,23 @@
+"""Python module which parses and emits TOML.
+
+Released under the MIT license.
+"""
+from . import decoder, encoder
+
+__version__ = "0.10.1"
+_spec_ = "0.5.0"
+
+load = decoder.load
+loads = decoder.loads
+TomlDecoder = decoder.TomlDecoder
+TomlDecodeError = decoder.TomlDecodeError
+TomlPreserveCommentDecoder = decoder.TomlPreserveCommentDecoder
+
+dump = encoder.dump
+dumps = encoder.dumps
+TomlEncoder = encoder.TomlEncoder
+TomlArraySeparatorEncoder = encoder.TomlArraySeparatorEncoder
+TomlPreserveInlineDictEncoder = encoder.TomlPreserveInlineDictEncoder
+TomlNumpyEncoder = encoder.TomlNumpyEncoder
+TomlPreserveCommentEncoder = encoder.TomlPreserveCommentEncoder
+TomlPathlibEncoder = encoder.TomlPathlibEncoder
diff --git a/venv/Lib/site-packages/isort/_vendored/toml/decoder.py b/venv/Lib/site-packages/isort/_vendored/toml/decoder.py
new file mode 100644
index 0000000..b90b693
--- /dev/null
+++ b/venv/Lib/site-packages/isort/_vendored/toml/decoder.py
@@ -0,0 +1,1053 @@
+import datetime
+import io
+import re
+import sys
+from os import linesep
+
+from .tz import TomlTz
+
+if sys.version_info < (3,):
+ _range = xrange # noqa: F821
+else:
+ unicode = str
+ _range = range
+ basestring = str
+ unichr = chr
+
+
+def _detect_pathlib_path(p):
+ if (3, 4) <= sys.version_info:
+ import pathlib
+
+ if isinstance(p, pathlib.PurePath):
+ return True
+ return False
+
+
+def _ispath(p):
+ if isinstance(p, (bytes, basestring)):
+ return True
+ return _detect_pathlib_path(p)
+
+
+def _getpath(p):
+ if (3, 6) <= sys.version_info:
+ import os
+
+ return os.fspath(p)
+ if _detect_pathlib_path(p):
+ return str(p)
+ return p
+
+
+try:
+ FNFError = FileNotFoundError
+except NameError:
+ FNFError = IOError
+
+
+TIME_RE = re.compile(r"([0-9]{2}):([0-9]{2}):([0-9]{2})(\.([0-9]{3,6}))?")
+
+
+class TomlDecodeError(ValueError):
+ """Base toml Exception / Error."""
+
+ def __init__(self, msg, doc, pos):
+ lineno = doc.count("\n", 0, pos) + 1
+ colno = pos - doc.rfind("\n", 0, pos)
+ emsg = "{} (line {} column {} char {})".format(msg, lineno, colno, pos)
+ ValueError.__init__(self, emsg)
+ self.msg = msg
+ self.doc = doc
+ self.pos = pos
+ self.lineno = lineno
+ self.colno = colno
+
+
+# Matches a TOML number, which allows underscores for readability
+_number_with_underscores = re.compile("([0-9])(_([0-9]))*")
+
+
+class CommentValue(object):
+ def __init__(self, val, comment, beginline, _dict):
+ self.val = val
+ separator = "\n" if beginline else " "
+ self.comment = separator + comment
+ self._dict = _dict
+
+ def __getitem__(self, key):
+ return self.val[key]
+
+ def __setitem__(self, key, value):
+ self.val[key] = value
+
+ def dump(self, dump_value_func):
+ retstr = dump_value_func(self.val)
+ if isinstance(self.val, self._dict):
+ return self.comment + "\n" + unicode(retstr)
+ else:
+ return unicode(retstr) + self.comment
+
+
+def _strictly_valid_num(n):
+ n = n.strip()
+ if not n:
+ return False
+ if n[0] == "_":
+ return False
+ if n[-1] == "_":
+ return False
+ if "_." in n or "._" in n:
+ return False
+ if len(n) == 1:
+ return True
+ if n[0] == "0" and n[1] not in [".", "o", "b", "x"]:
+ return False
+ if n[0] == "+" or n[0] == "-":
+ n = n[1:]
+ if len(n) > 1 and n[0] == "0" and n[1] != ".":
+ return False
+ if "__" in n:
+ return False
+ return True
+
+
+def load(f, _dict=dict, decoder=None):
+ """Parses named file or files as toml and returns a dictionary
+
+ Args:
+ f: Path to the file to open, array of files to read into single dict
+ or a file descriptor
+ _dict: (optional) Specifies the class of the returned toml dictionary
+ decoder: The decoder to use
+
+ Returns:
+ Parsed toml file represented as a dictionary
+
+ Raises:
+ TypeError -- When f is invalid type
+ TomlDecodeError: Error while decoding toml
+ IOError / FileNotFoundError -- When an array with no valid (existing)
+ (Python 2 / Python 3) file paths is passed
+ """
+
+ if _ispath(f):
+ with io.open(_getpath(f), encoding="utf-8") as ffile:
+ return loads(ffile.read(), _dict, decoder)
+ elif isinstance(f, list):
+ from os import path as op
+ from warnings import warn
+
+ if not [path for path in f if op.exists(path)]:
+ error_msg = "Load expects a list to contain filenames only."
+ error_msg += linesep
+ error_msg += "The list needs to contain the path of at least one " "existing file."
+ raise FNFError(error_msg)
+ if decoder is None:
+ decoder = TomlDecoder(_dict)
+ d = decoder.get_empty_table()
+ for l in f: # noqa: E741
+ if op.exists(l):
+ d.update(load(l, _dict, decoder))
+ else:
+ warn("Non-existent filename in list with at least one valid " "filename")
+ return d
+ else:
+ try:
+ return loads(f.read(), _dict, decoder)
+ except AttributeError:
+ raise TypeError("You can only load a file descriptor, filename or " "list")
+
+
+_groupname_re = re.compile(r"^[A-Za-z0-9_-]+$")
+
+
+def loads(s, _dict=dict, decoder=None):
+ """Parses string as toml
+
+ Args:
+ s: String to be parsed
+ _dict: (optional) Specifies the class of the returned toml dictionary
+
+ Returns:
+ Parsed toml file represented as a dictionary
+
+ Raises:
+ TypeError: When a non-string is passed
+ TomlDecodeError: Error while decoding toml
+ """
+
+ implicitgroups = []
+ if decoder is None:
+ decoder = TomlDecoder(_dict)
+ retval = decoder.get_empty_table()
+ currentlevel = retval
+ if not isinstance(s, basestring):
+ raise TypeError("Expecting something like a string")
+
+ if not isinstance(s, unicode):
+ s = s.decode("utf8")
+
+ original = s
+ sl = list(s)
+ openarr = 0
+ openstring = False
+ openstrchar = ""
+ multilinestr = False
+ arrayoftables = False
+ beginline = True
+ keygroup = False
+ dottedkey = False
+ keyname = 0
+ key = ""
+ prev_key = ""
+ line_no = 1
+
+ for i, item in enumerate(sl):
+ if item == "\r" and sl[i + 1] == "\n":
+ sl[i] = " "
+ continue
+ if keyname:
+ key += item
+ if item == "\n":
+ raise TomlDecodeError(
+ "Key name found without value." " Reached end of line.", original, i
+ )
+ if openstring:
+ if item == openstrchar:
+ oddbackslash = False
+ k = 1
+ while i >= k and sl[i - k] == "\\":
+ oddbackslash = not oddbackslash
+ k += 1
+ if not oddbackslash:
+ keyname = 2
+ openstring = False
+ openstrchar = ""
+ continue
+ elif keyname == 1:
+ if item.isspace():
+ keyname = 2
+ continue
+ elif item == ".":
+ dottedkey = True
+ continue
+ elif item.isalnum() or item == "_" or item == "-":
+ continue
+ elif dottedkey and sl[i - 1] == "." and (item == '"' or item == "'"):
+ openstring = True
+ openstrchar = item
+ continue
+ elif keyname == 2:
+ if item.isspace():
+ if dottedkey:
+ nextitem = sl[i + 1]
+ if not nextitem.isspace() and nextitem != ".":
+ keyname = 1
+ continue
+ if item == ".":
+ dottedkey = True
+ nextitem = sl[i + 1]
+ if not nextitem.isspace() and nextitem != ".":
+ keyname = 1
+ continue
+ if item == "=":
+ keyname = 0
+ prev_key = key[:-1].rstrip()
+ key = ""
+ dottedkey = False
+ else:
+ raise TomlDecodeError(
+ "Found invalid character in key name: '"
+ + item
+ + "'. Try quoting the key name.",
+ original,
+ i,
+ )
+ if item == "'" and openstrchar != '"':
+ k = 1
+ try:
+ while sl[i - k] == "'":
+ k += 1
+ if k == 3:
+ break
+ except IndexError:
+ pass
+ if k == 3:
+ multilinestr = not multilinestr
+ openstring = multilinestr
+ else:
+ openstring = not openstring
+ if openstring:
+ openstrchar = "'"
+ else:
+ openstrchar = ""
+ if item == '"' and openstrchar != "'":
+ oddbackslash = False
+ k = 1
+ tripquote = False
+ try:
+ while sl[i - k] == '"':
+ k += 1
+ if k == 3:
+ tripquote = True
+ break
+ if k == 1 or (k == 3 and tripquote):
+ while sl[i - k] == "\\":
+ oddbackslash = not oddbackslash
+ k += 1
+ except IndexError:
+ pass
+ if not oddbackslash:
+ if tripquote:
+ multilinestr = not multilinestr
+ openstring = multilinestr
+ else:
+ openstring = not openstring
+ if openstring:
+ openstrchar = '"'
+ else:
+ openstrchar = ""
+ if item == "#" and (not openstring and not keygroup and not arrayoftables):
+ j = i
+ comment = ""
+ try:
+ while sl[j] != "\n":
+ comment += s[j]
+ sl[j] = " "
+ j += 1
+ except IndexError:
+ break
+ if not openarr:
+ decoder.preserve_comment(line_no, prev_key, comment, beginline)
+ if item == "[" and (not openstring and not keygroup and not arrayoftables):
+ if beginline:
+ if len(sl) > i + 1 and sl[i + 1] == "[":
+ arrayoftables = True
+ else:
+ keygroup = True
+ else:
+ openarr += 1
+ if item == "]" and not openstring:
+ if keygroup:
+ keygroup = False
+ elif arrayoftables:
+ if sl[i - 1] == "]":
+ arrayoftables = False
+ else:
+ openarr -= 1
+ if item == "\n":
+ if openstring or multilinestr:
+ if not multilinestr:
+ raise TomlDecodeError("Unbalanced quotes", original, i)
+ if (sl[i - 1] == "'" or sl[i - 1] == '"') and (sl[i - 2] == sl[i - 1]):
+ sl[i] = sl[i - 1]
+ if sl[i - 3] == sl[i - 1]:
+ sl[i - 3] = " "
+ elif openarr:
+ sl[i] = " "
+ else:
+ beginline = True
+ line_no += 1
+ elif beginline and sl[i] != " " and sl[i] != "\t":
+ beginline = False
+ if not keygroup and not arrayoftables:
+ if sl[i] == "=":
+ raise TomlDecodeError("Found empty keyname. ", original, i)
+ keyname = 1
+ key += item
+ if keyname:
+ raise TomlDecodeError(
+ "Key name found without value." " Reached end of file.", original, len(s)
+ )
+ if openstring: # reached EOF and have an unterminated string
+ raise TomlDecodeError(
+ "Unterminated string found." " Reached end of file.", original, len(s)
+ )
+ s = "".join(sl)
+ s = s.split("\n")
+ multikey = None
+ multilinestr = ""
+ multibackslash = False
+ pos = 0
+ for idx, line in enumerate(s):
+ if idx > 0:
+ pos += len(s[idx - 1]) + 1
+
+ decoder.embed_comments(idx, currentlevel)
+
+ if not multilinestr or multibackslash or "\n" not in multilinestr:
+ line = line.strip()
+ if line == "" and (not multikey or multibackslash):
+ continue
+ if multikey:
+ if multibackslash:
+ multilinestr += line
+ else:
+ multilinestr += line
+ multibackslash = False
+ closed = False
+ if multilinestr[0] == "[":
+ closed = line[-1] == "]"
+ elif len(line) > 2:
+ closed = (
+ line[-1] == multilinestr[0]
+ and line[-2] == multilinestr[0]
+ and line[-3] == multilinestr[0]
+ )
+ if closed:
+ try:
+ value, vtype = decoder.load_value(multilinestr)
+ except ValueError as err:
+ raise TomlDecodeError(str(err), original, pos)
+ currentlevel[multikey] = value
+ multikey = None
+ multilinestr = ""
+ else:
+ k = len(multilinestr) - 1
+ while k > -1 and multilinestr[k] == "\\":
+ multibackslash = not multibackslash
+ k -= 1
+ if multibackslash:
+ multilinestr = multilinestr[:-1]
+ else:
+ multilinestr += "\n"
+ continue
+ if line[0] == "[":
+ arrayoftables = False
+ if len(line) == 1:
+ raise TomlDecodeError(
+ "Opening key group bracket on line by " "itself.", original, pos
+ )
+ if line[1] == "[":
+ arrayoftables = True
+ line = line[2:]
+ splitstr = "]]"
+ else:
+ line = line[1:]
+ splitstr = "]"
+ i = 1
+ quotesplits = decoder._get_split_on_quotes(line)
+ quoted = False
+ for quotesplit in quotesplits:
+ if not quoted and splitstr in quotesplit:
+ break
+ i += quotesplit.count(splitstr)
+ quoted = not quoted
+ line = line.split(splitstr, i)
+ if len(line) < i + 1 or line[-1].strip() != "":
+ raise TomlDecodeError("Key group not on a line by itself.", original, pos)
+ groups = splitstr.join(line[:-1]).split(".")
+ i = 0
+ while i < len(groups):
+ groups[i] = groups[i].strip()
+ if len(groups[i]) > 0 and (groups[i][0] == '"' or groups[i][0] == "'"):
+ groupstr = groups[i]
+ j = i + 1
+ while not groupstr[0] == groupstr[-1]:
+ j += 1
+ if j > len(groups) + 2:
+ raise TomlDecodeError(
+ "Invalid group name '" + groupstr + "' Something " + "went wrong.",
+ original,
+ pos,
+ )
+ groupstr = ".".join(groups[i:j]).strip()
+ groups[i] = groupstr[1:-1]
+ groups[i + 1 : j] = []
+ else:
+ if not _groupname_re.match(groups[i]):
+ raise TomlDecodeError(
+ "Invalid group name '" + groups[i] + "'. Try quoting it.", original, pos
+ )
+ i += 1
+ currentlevel = retval
+ for i in _range(len(groups)):
+ group = groups[i]
+ if group == "":
+ raise TomlDecodeError(
+ "Can't have a keygroup with an empty " "name", original, pos
+ )
+ try:
+ currentlevel[group]
+ if i == len(groups) - 1:
+ if group in implicitgroups:
+ implicitgroups.remove(group)
+ if arrayoftables:
+ raise TomlDecodeError(
+ "An implicitly defined " "table can't be an array",
+ original,
+ pos,
+ )
+ elif arrayoftables:
+ currentlevel[group].append(decoder.get_empty_table())
+ else:
+ raise TomlDecodeError(
+ "What? " + group + " already exists?" + str(currentlevel),
+ original,
+ pos,
+ )
+ except TypeError:
+ currentlevel = currentlevel[-1]
+ if group not in currentlevel:
+ currentlevel[group] = decoder.get_empty_table()
+ if i == len(groups) - 1 and arrayoftables:
+ currentlevel[group] = [decoder.get_empty_table()]
+ except KeyError:
+ if i != len(groups) - 1:
+ implicitgroups.append(group)
+ currentlevel[group] = decoder.get_empty_table()
+ if i == len(groups) - 1 and arrayoftables:
+ currentlevel[group] = [decoder.get_empty_table()]
+ currentlevel = currentlevel[group]
+ if arrayoftables:
+ try:
+ currentlevel = currentlevel[-1]
+ except KeyError:
+ pass
+ elif line[0] == "{":
+ if line[-1] != "}":
+ raise TomlDecodeError(
+ "Line breaks are not allowed in inline" "objects", original, pos
+ )
+ try:
+ decoder.load_inline_object(line, currentlevel, multikey, multibackslash)
+ except ValueError as err:
+ raise TomlDecodeError(str(err), original, pos)
+ elif "=" in line:
+ try:
+ ret = decoder.load_line(line, currentlevel, multikey, multibackslash)
+ except ValueError as err:
+ raise TomlDecodeError(str(err), original, pos)
+ if ret is not None:
+ multikey, multilinestr, multibackslash = ret
+ return retval
+
+
+def _load_date(val):
+ microsecond = 0
+ tz = None
+ try:
+ if len(val) > 19:
+ if val[19] == ".":
+ if val[-1].upper() == "Z":
+ subsecondval = val[20:-1]
+ tzval = "Z"
+ else:
+ subsecondvalandtz = val[20:]
+ if "+" in subsecondvalandtz:
+ splitpoint = subsecondvalandtz.index("+")
+ subsecondval = subsecondvalandtz[:splitpoint]
+ tzval = subsecondvalandtz[splitpoint:]
+ elif "-" in subsecondvalandtz:
+ splitpoint = subsecondvalandtz.index("-")
+ subsecondval = subsecondvalandtz[:splitpoint]
+ tzval = subsecondvalandtz[splitpoint:]
+ else:
+ tzval = None
+ subsecondval = subsecondvalandtz
+ if tzval is not None:
+ tz = TomlTz(tzval)
+ microsecond = int(int(subsecondval) * (10 ** (6 - len(subsecondval))))
+ else:
+ tz = TomlTz(val[19:])
+ except ValueError:
+ tz = None
+ if "-" not in val[1:]:
+ return None
+ try:
+ if len(val) == 10:
+ d = datetime.date(int(val[:4]), int(val[5:7]), int(val[8:10]))
+ else:
+ d = datetime.datetime(
+ int(val[:4]),
+ int(val[5:7]),
+ int(val[8:10]),
+ int(val[11:13]),
+ int(val[14:16]),
+ int(val[17:19]),
+ microsecond,
+ tz,
+ )
+ except ValueError:
+ return None
+ return d
+
+
+def _load_unicode_escapes(v, hexbytes, prefix):
+ skip = False
+ i = len(v) - 1
+ while i > -1 and v[i] == "\\":
+ skip = not skip
+ i -= 1
+ for hx in hexbytes:
+ if skip:
+ skip = False
+ i = len(hx) - 1
+ while i > -1 and hx[i] == "\\":
+ skip = not skip
+ i -= 1
+ v += prefix
+ v += hx
+ continue
+ hxb = ""
+ i = 0
+ hxblen = 4
+ if prefix == "\\U":
+ hxblen = 8
+ hxb = "".join(hx[i : i + hxblen]).lower()
+ if hxb.strip("0123456789abcdef"):
+ raise ValueError("Invalid escape sequence: " + hxb)
+ if hxb[0] == "d" and hxb[1].strip("01234567"):
+ raise ValueError(
+ "Invalid escape sequence: " + hxb + ". Only scalar unicode points are allowed."
+ )
+ v += unichr(int(hxb, 16))
+ v += unicode(hx[len(hxb) :])
+ return v
+
+
+# Unescape TOML string values.
+
+# content after the \
+_escapes = ["0", "b", "f", "n", "r", "t", '"']
+# What it should be replaced by
+_escapedchars = ["\0", "\b", "\f", "\n", "\r", "\t", '"']
+# Used for substitution
+_escape_to_escapedchars = dict(zip(_escapes, _escapedchars))
+
+
+def _unescape(v):
+ """Unescape characters in a TOML string."""
+ i = 0
+ backslash = False
+ while i < len(v):
+ if backslash:
+ backslash = False
+ if v[i] in _escapes:
+ v = v[: i - 1] + _escape_to_escapedchars[v[i]] + v[i + 1 :]
+ elif v[i] == "\\":
+ v = v[: i - 1] + v[i:]
+ elif v[i] == "u" or v[i] == "U":
+ i += 1
+ else:
+ raise ValueError("Reserved escape sequence used")
+ continue
+ elif v[i] == "\\":
+ backslash = True
+ i += 1
+ return v
+
+
+class InlineTableDict(object):
+ """Sentinel subclass of dict for inline tables."""
+
+
+class TomlDecoder(object):
+ def __init__(self, _dict=dict):
+ self._dict = _dict
+
+ def get_empty_table(self):
+ return self._dict()
+
+ def get_empty_inline_table(self):
+ class DynamicInlineTableDict(self._dict, InlineTableDict):
+ """Concrete sentinel subclass for inline tables.
+ It is a subclass of _dict which is passed in dynamically at load
+ time
+
+ It is also a subclass of InlineTableDict
+ """
+
+ return DynamicInlineTableDict()
+
+ def load_inline_object(self, line, currentlevel, multikey=False, multibackslash=False):
+ candidate_groups = line[1:-1].split(",")
+ groups = []
+ if len(candidate_groups) == 1 and not candidate_groups[0].strip():
+ candidate_groups.pop()
+ while len(candidate_groups) > 0:
+ candidate_group = candidate_groups.pop(0)
+ try:
+ _, value = candidate_group.split("=", 1)
+ except ValueError:
+ raise ValueError("Invalid inline table encountered")
+ value = value.strip()
+ if (value[0] == value[-1] and value[0] in ('"', "'")) or (
+ value[0] in "-0123456789"
+ or value in ("true", "false")
+ or (value[0] == "[" and value[-1] == "]")
+ or (value[0] == "{" and value[-1] == "}")
+ ):
+ groups.append(candidate_group)
+ elif len(candidate_groups) > 0:
+ candidate_groups[0] = candidate_group + "," + candidate_groups[0]
+ else:
+ raise ValueError("Invalid inline table value encountered")
+ for group in groups:
+ status = self.load_line(group, currentlevel, multikey, multibackslash)
+ if status is not None:
+ break
+
+ def _get_split_on_quotes(self, line):
+ doublequotesplits = line.split('"')
+ quoted = False
+ quotesplits = []
+ if len(doublequotesplits) > 1 and "'" in doublequotesplits[0]:
+ singlequotesplits = doublequotesplits[0].split("'")
+ doublequotesplits = doublequotesplits[1:]
+ while len(singlequotesplits) % 2 == 0 and len(doublequotesplits):
+ singlequotesplits[-1] += '"' + doublequotesplits[0]
+ doublequotesplits = doublequotesplits[1:]
+ if "'" in singlequotesplits[-1]:
+ singlequotesplits = singlequotesplits[:-1] + singlequotesplits[-1].split("'")
+ quotesplits += singlequotesplits
+ for doublequotesplit in doublequotesplits:
+ if quoted:
+ quotesplits.append(doublequotesplit)
+ else:
+ quotesplits += doublequotesplit.split("'")
+ quoted = not quoted
+ return quotesplits
+
+ def load_line(self, line, currentlevel, multikey, multibackslash):
+ i = 1
+ quotesplits = self._get_split_on_quotes(line)
+ quoted = False
+ for quotesplit in quotesplits:
+ if not quoted and "=" in quotesplit:
+ break
+ i += quotesplit.count("=")
+ quoted = not quoted
+ pair = line.split("=", i)
+ strictly_valid = _strictly_valid_num(pair[-1])
+ if _number_with_underscores.match(pair[-1]):
+ pair[-1] = pair[-1].replace("_", "")
+ while len(pair[-1]) and (
+ pair[-1][0] != " "
+ and pair[-1][0] != "\t"
+ and pair[-1][0] != "'"
+ and pair[-1][0] != '"'
+ and pair[-1][0] != "["
+ and pair[-1][0] != "{"
+ and pair[-1].strip() != "true"
+ and pair[-1].strip() != "false"
+ ):
+ try:
+ float(pair[-1])
+ break
+ except ValueError:
+ pass
+ if _load_date(pair[-1]) is not None:
+ break
+ if TIME_RE.match(pair[-1]):
+ break
+ i += 1
+ prev_val = pair[-1]
+ pair = line.split("=", i)
+ if prev_val == pair[-1]:
+ raise ValueError("Invalid date or number")
+ if strictly_valid:
+ strictly_valid = _strictly_valid_num(pair[-1])
+ pair = ["=".join(pair[:-1]).strip(), pair[-1].strip()]
+ if "." in pair[0]:
+ if '"' in pair[0] or "'" in pair[0]:
+ quotesplits = self._get_split_on_quotes(pair[0])
+ quoted = False
+ levels = []
+ for quotesplit in quotesplits:
+ if quoted:
+ levels.append(quotesplit)
+ else:
+ levels += [level.strip() for level in quotesplit.split(".")]
+ quoted = not quoted
+ else:
+ levels = pair[0].split(".")
+ while levels[-1] == "":
+ levels = levels[:-1]
+ for level in levels[:-1]:
+ if level == "":
+ continue
+ if level not in currentlevel:
+ currentlevel[level] = self.get_empty_table()
+ currentlevel = currentlevel[level]
+ pair[0] = levels[-1].strip()
+ elif (pair[0][0] == '"' or pair[0][0] == "'") and (pair[0][-1] == pair[0][0]):
+ pair[0] = _unescape(pair[0][1:-1])
+ k, koffset = self._load_line_multiline_str(pair[1])
+ if k > -1:
+ while k > -1 and pair[1][k + koffset] == "\\":
+ multibackslash = not multibackslash
+ k -= 1
+ if multibackslash:
+ multilinestr = pair[1][:-1]
+ else:
+ multilinestr = pair[1] + "\n"
+ multikey = pair[0]
+ else:
+ value, vtype = self.load_value(pair[1], strictly_valid)
+ try:
+ currentlevel[pair[0]]
+ raise ValueError("Duplicate keys!")
+ except TypeError:
+ raise ValueError("Duplicate keys!")
+ except KeyError:
+ if multikey:
+ return multikey, multilinestr, multibackslash
+ else:
+ currentlevel[pair[0]] = value
+
+ def _load_line_multiline_str(self, p):
+ poffset = 0
+ if len(p) < 3:
+ return -1, poffset
+ if p[0] == "[" and (p.strip()[-1] != "]" and self._load_array_isstrarray(p)):
+ newp = p[1:].strip().split(",")
+ while len(newp) > 1 and newp[-1][0] != '"' and newp[-1][0] != "'":
+ newp = newp[:-2] + [newp[-2] + "," + newp[-1]]
+ newp = newp[-1]
+ poffset = len(p) - len(newp)
+ p = newp
+ if p[0] != '"' and p[0] != "'":
+ return -1, poffset
+ if p[1] != p[0] or p[2] != p[0]:
+ return -1, poffset
+ if len(p) > 5 and p[-1] == p[0] and p[-2] == p[0] and p[-3] == p[0]:
+ return -1, poffset
+ return len(p) - 1, poffset
+
+ def load_value(self, v, strictly_valid=True):
+ if not v:
+ raise ValueError("Empty value is invalid")
+ if v == "true":
+ return (True, "bool")
+ elif v == "false":
+ return (False, "bool")
+ elif v[0] == '"' or v[0] == "'":
+ quotechar = v[0]
+ testv = v[1:].split(quotechar)
+ triplequote = False
+ triplequotecount = 0
+ if len(testv) > 1 and testv[0] == "" and testv[1] == "":
+ testv = testv[2:]
+ triplequote = True
+ closed = False
+ for tv in testv:
+ if tv == "":
+ if triplequote:
+ triplequotecount += 1
+ else:
+ closed = True
+ else:
+ oddbackslash = False
+ try:
+ i = -1
+ j = tv[i]
+ while j == "\\":
+ oddbackslash = not oddbackslash
+ i -= 1
+ j = tv[i]
+ except IndexError:
+ pass
+ if not oddbackslash:
+ if closed:
+ raise ValueError(
+ "Found tokens after a closed " + "string. Invalid TOML."
+ )
+ else:
+ if not triplequote or triplequotecount > 1:
+ closed = True
+ else:
+ triplequotecount = 0
+ if quotechar == '"':
+ escapeseqs = v.split("\\")[1:]
+ backslash = False
+ for i in escapeseqs:
+ if i == "":
+ backslash = not backslash
+ else:
+ if i[0] not in _escapes and (i[0] != "u" and i[0] != "U" and not backslash):
+ raise ValueError("Reserved escape sequence used")
+ if backslash:
+ backslash = False
+ for prefix in ["\\u", "\\U"]:
+ if prefix in v:
+ hexbytes = v.split(prefix)
+ v = _load_unicode_escapes(hexbytes[0], hexbytes[1:], prefix)
+ v = _unescape(v)
+ if len(v) > 1 and v[1] == quotechar and (len(v) < 3 or v[1] == v[2]):
+ v = v[2:-2]
+ return (v[1:-1], "str")
+ elif v[0] == "[":
+ return (self.load_array(v), "array")
+ elif v[0] == "{":
+ inline_object = self.get_empty_inline_table()
+ self.load_inline_object(v, inline_object)
+ return (inline_object, "inline_object")
+ elif TIME_RE.match(v):
+ h, m, s, _, ms = TIME_RE.match(v).groups()
+ time = datetime.time(int(h), int(m), int(s), int(ms) if ms else 0)
+ return (time, "time")
+ else:
+ parsed_date = _load_date(v)
+ if parsed_date is not None:
+ return (parsed_date, "date")
+ if not strictly_valid:
+ raise ValueError("Weirdness with leading zeroes or " "underscores in your number.")
+ itype = "int"
+ neg = False
+ if v[0] == "-":
+ neg = True
+ v = v[1:]
+ elif v[0] == "+":
+ v = v[1:]
+ v = v.replace("_", "")
+ lowerv = v.lower()
+ if "." in v or ("x" not in v and ("e" in v or "E" in v)):
+ if "." in v and v.split(".", 1)[1] == "":
+ raise ValueError("This float is missing digits after " "the point")
+ if v[0] not in "0123456789":
+ raise ValueError("This float doesn't have a leading " "digit")
+ v = float(v)
+ itype = "float"
+ elif len(lowerv) == 3 and (lowerv == "inf" or lowerv == "nan"):
+ v = float(v)
+ itype = "float"
+ if itype == "int":
+ v = int(v, 0)
+ if neg:
+ return (0 - v, itype)
+ return (v, itype)
+
+ def bounded_string(self, s):
+ if len(s) == 0:
+ return True
+ if s[-1] != s[0]:
+ return False
+ i = -2
+ backslash = False
+ while len(s) + i > 0:
+ if s[i] == "\\":
+ backslash = not backslash
+ i -= 1
+ else:
+ break
+ return not backslash
+
+ def _load_array_isstrarray(self, a):
+ a = a[1:-1].strip()
+ if a != "" and (a[0] == '"' or a[0] == "'"):
+ return True
+ return False
+
+ def load_array(self, a):
+ atype = None
+ retval = []
+ a = a.strip()
+ if "[" not in a[1:-1] or "" != a[1:-1].split("[")[0].strip():
+ strarray = self._load_array_isstrarray(a)
+ if not a[1:-1].strip().startswith("{"):
+ a = a[1:-1].split(",")
+ else:
+ # a is an inline object, we must find the matching parenthesis
+ # to define groups
+ new_a = []
+ start_group_index = 1
+ end_group_index = 2
+ open_bracket_count = 1 if a[start_group_index] == "{" else 0
+ in_str = False
+ while end_group_index < len(a[1:]):
+ if a[end_group_index] == '"' or a[end_group_index] == "'":
+ if in_str:
+ backslash_index = end_group_index - 1
+ while backslash_index > -1 and a[backslash_index] == "\\":
+ in_str = not in_str
+ backslash_index -= 1
+ in_str = not in_str
+ if not in_str and a[end_group_index] == "{":
+ open_bracket_count += 1
+ if in_str or a[end_group_index] != "}":
+ end_group_index += 1
+ continue
+ elif a[end_group_index] == "}" and open_bracket_count > 1:
+ open_bracket_count -= 1
+ end_group_index += 1
+ continue
+
+ # Increase end_group_index by 1 to get the closing bracket
+ end_group_index += 1
+
+ new_a.append(a[start_group_index:end_group_index])
+
+ # The next start index is at least after the closing
+ # bracket, a closing bracket can be followed by a comma
+ # since we are in an array.
+ start_group_index = end_group_index + 1
+ while start_group_index < len(a[1:]) and a[start_group_index] != "{":
+ start_group_index += 1
+ end_group_index = start_group_index + 1
+ a = new_a
+ b = 0
+ if strarray:
+ while b < len(a) - 1:
+ ab = a[b].strip()
+ while not self.bounded_string(ab) or (
+ len(ab) > 2
+ and ab[0] == ab[1] == ab[2]
+ and ab[-2] != ab[0]
+ and ab[-3] != ab[0]
+ ):
+ a[b] = a[b] + "," + a[b + 1]
+ ab = a[b].strip()
+ if b < len(a) - 2:
+ a = a[: b + 1] + a[b + 2 :]
+ else:
+ a = a[: b + 1]
+ b += 1
+ else:
+ al = list(a[1:-1])
+ a = []
+ openarr = 0
+ j = 0
+ for i in _range(len(al)):
+ if al[i] == "[":
+ openarr += 1
+ elif al[i] == "]":
+ openarr -= 1
+ elif al[i] == "," and not openarr:
+ a.append("".join(al[j:i]))
+ j = i + 1
+ a.append("".join(al[j:]))
+ for i in _range(len(a)):
+ a[i] = a[i].strip()
+ if a[i] != "":
+ nval, ntype = self.load_value(a[i])
+ if atype:
+ if ntype != atype:
+ raise ValueError("Not a homogeneous array")
+ else:
+ atype = ntype
+ retval.append(nval)
+ return retval
+
+ def preserve_comment(self, line_no, key, comment, beginline):
+ pass
+
+ def embed_comments(self, idx, currentlevel):
+ pass
+
+
+class TomlPreserveCommentDecoder(TomlDecoder):
+ def __init__(self, _dict=dict):
+ self.saved_comments = {}
+ super(TomlPreserveCommentDecoder, self).__init__(_dict)
+
+ def preserve_comment(self, line_no, key, comment, beginline):
+ self.saved_comments[line_no] = (key, comment, beginline)
+
+ def embed_comments(self, idx, currentlevel):
+ if idx not in self.saved_comments:
+ return
+
+ key, comment, beginline = self.saved_comments[idx]
+ currentlevel[key] = CommentValue(currentlevel[key], comment, beginline, self._dict)
diff --git a/venv/Lib/site-packages/isort/_vendored/toml/encoder.py b/venv/Lib/site-packages/isort/_vendored/toml/encoder.py
new file mode 100644
index 0000000..68ec60f
--- /dev/null
+++ b/venv/Lib/site-packages/isort/_vendored/toml/encoder.py
@@ -0,0 +1,295 @@
+import datetime
+import re
+import sys
+from decimal import Decimal
+
+from .decoder import InlineTableDict
+
+if sys.version_info >= (3,):
+ unicode = str
+
+
+def dump(o, f, encoder=None):
+ """Writes out dict as toml to a file
+
+ Args:
+ o: Object to dump into toml
+ f: File descriptor where the toml should be stored
+ encoder: The ``TomlEncoder`` to use for constructing the output string
+
+ Returns:
+ String containing the toml corresponding to dictionary
+
+ Raises:
+ TypeError: When anything other than file descriptor is passed
+ """
+
+ if not f.write:
+ raise TypeError("You can only dump an object to a file descriptor")
+ d = dumps(o, encoder=encoder)
+ f.write(d)
+ return d
+
+
+def dumps(o, encoder=None):
+ """Stringifies input dict as toml
+
+ Args:
+ o: Object to dump into toml
+ encoder: The ``TomlEncoder`` to use for constructing the output string
+
+ Returns:
+ String containing the toml corresponding to dict
+
+ Examples:
+ ```python
+ >>> import toml
+ >>> output = {
+ ... 'a': "I'm a string",
+ ... 'b': ["I'm", "a", "list"],
+ ... 'c': 2400
+ ... }
+ >>> toml.dumps(output)
+ 'a = "I\'m a string"\nb = [ "I\'m", "a", "list",]\nc = 2400\n'
+ ```
+ """
+
+ retval = ""
+ if encoder is None:
+ encoder = TomlEncoder(o.__class__)
+ addtoretval, sections = encoder.dump_sections(o, "")
+ retval += addtoretval
+ outer_objs = [id(o)]
+ while sections:
+ section_ids = [id(section) for section in sections]
+ for outer_obj in outer_objs:
+ if outer_obj in section_ids:
+ raise ValueError("Circular reference detected")
+ outer_objs += section_ids
+ newsections = encoder.get_empty_table()
+ for section in sections:
+ addtoretval, addtosections = encoder.dump_sections(sections[section], section)
+
+ if addtoretval or (not addtoretval and not addtosections):
+ if retval and retval[-2:] != "\n\n":
+ retval += "\n"
+ retval += "[" + section + "]\n"
+ if addtoretval:
+ retval += addtoretval
+ for s in addtosections:
+ newsections[section + "." + s] = addtosections[s]
+ sections = newsections
+ return retval
+
+
+def _dump_str(v):
+ if sys.version_info < (3,) and hasattr(v, "decode") and isinstance(v, str):
+ v = v.decode("utf-8")
+ v = "%r" % v
+ if v[0] == "u":
+ v = v[1:]
+ singlequote = v.startswith("'")
+ if singlequote or v.startswith('"'):
+ v = v[1:-1]
+ if singlequote:
+ v = v.replace("\\'", "'")
+ v = v.replace('"', '\\"')
+ v = v.split("\\x")
+ while len(v) > 1:
+ i = -1
+ if not v[0]:
+ v = v[1:]
+ v[0] = v[0].replace("\\\\", "\\")
+ # No, I don't know why != works and == breaks
+ joinx = v[0][i] != "\\"
+ while v[0][:i] and v[0][i] == "\\":
+ joinx = not joinx
+ i -= 1
+ if joinx:
+ joiner = "x"
+ else:
+ joiner = "u00"
+ v = [v[0] + joiner + v[1]] + v[2:]
+ return unicode('"' + v[0] + '"')
+
+
+def _dump_float(v):
+ return "{}".format(v).replace("e+0", "e+").replace("e-0", "e-")
+
+
+def _dump_time(v):
+ utcoffset = v.utcoffset()
+ if utcoffset is None:
+ return v.isoformat()
+ # The TOML norm specifies that it's local time thus we drop the offset
+ return v.isoformat()[:-6]
+
+
+class TomlEncoder(object):
+ def __init__(self, _dict=dict, preserve=False):
+ self._dict = _dict
+ self.preserve = preserve
+ self.dump_funcs = {
+ str: _dump_str,
+ unicode: _dump_str,
+ list: self.dump_list,
+ bool: lambda v: unicode(v).lower(),
+ int: lambda v: v,
+ float: _dump_float,
+ Decimal: _dump_float,
+ datetime.datetime: lambda v: v.isoformat().replace("+00:00", "Z"),
+ datetime.time: _dump_time,
+ datetime.date: lambda v: v.isoformat(),
+ }
+
+ def get_empty_table(self):
+ return self._dict()
+
+ def dump_list(self, v):
+ retval = "["
+ for u in v:
+ retval += " " + unicode(self.dump_value(u)) + ","
+ retval += "]"
+ return retval
+
+ def dump_inline_table(self, section):
+ """Preserve inline table in its compact syntax instead of expanding
+ into subsection.
+
+ https://github.com/toml-lang/toml#user-content-inline-table
+ """
+ retval = ""
+ if isinstance(section, dict):
+ val_list = []
+ for k, v in section.items():
+ val = self.dump_inline_table(v)
+ val_list.append(k + " = " + val)
+ retval += "{ " + ", ".join(val_list) + " }\n"
+ return retval
+ else:
+ return unicode(self.dump_value(section))
+
+ def dump_value(self, v):
+ # Lookup function corresponding to v's type
+ dump_fn = self.dump_funcs.get(type(v))
+ if dump_fn is None and hasattr(v, "__iter__"):
+ dump_fn = self.dump_funcs[list]
+ # Evaluate function (if it exists) else return v
+ return dump_fn(v) if dump_fn is not None else self.dump_funcs[str](v)
+
+ def dump_sections(self, o, sup):
+ retstr = ""
+ if sup != "" and sup[-1] != ".":
+ sup += "."
+ retdict = self._dict()
+ arraystr = ""
+ for section in o:
+ section = unicode(section)
+ qsection = section
+ if not re.match(r"^[A-Za-z0-9_-]+$", section):
+ qsection = _dump_str(section)
+ if not isinstance(o[section], dict):
+ arrayoftables = False
+ if isinstance(o[section], list):
+ for a in o[section]:
+ if isinstance(a, dict):
+ arrayoftables = True
+ if arrayoftables:
+ for a in o[section]:
+ arraytabstr = "\n"
+ arraystr += "[[" + sup + qsection + "]]\n"
+ s, d = self.dump_sections(a, sup + qsection)
+ if s:
+ if s[0] == "[":
+ arraytabstr += s
+ else:
+ arraystr += s
+ while d:
+ newd = self._dict()
+ for dsec in d:
+ s1, d1 = self.dump_sections(d[dsec], sup + qsection + "." + dsec)
+ if s1:
+ arraytabstr += "[" + sup + qsection + "." + dsec + "]\n"
+ arraytabstr += s1
+ for s1 in d1:
+ newd[dsec + "." + s1] = d1[s1]
+ d = newd
+ arraystr += arraytabstr
+ else:
+ if o[section] is not None:
+ retstr += qsection + " = " + unicode(self.dump_value(o[section])) + "\n"
+ elif self.preserve and isinstance(o[section], InlineTableDict):
+ retstr += qsection + " = " + self.dump_inline_table(o[section])
+ else:
+ retdict[qsection] = o[section]
+ retstr += arraystr
+ return (retstr, retdict)
+
+
+class TomlPreserveInlineDictEncoder(TomlEncoder):
+ def __init__(self, _dict=dict):
+ super(TomlPreserveInlineDictEncoder, self).__init__(_dict, True)
+
+
+class TomlArraySeparatorEncoder(TomlEncoder):
+ def __init__(self, _dict=dict, preserve=False, separator=","):
+ super(TomlArraySeparatorEncoder, self).__init__(_dict, preserve)
+ if separator.strip() == "":
+ separator = "," + separator
+ elif separator.strip(" \t\n\r,"):
+ raise ValueError("Invalid separator for arrays")
+ self.separator = separator
+
+ def dump_list(self, v):
+ t = []
+ retval = "["
+ for u in v:
+ t.append(self.dump_value(u))
+ while t != []:
+ s = []
+ for u in t:
+ if isinstance(u, list):
+ for r in u:
+ s.append(r)
+ else:
+ retval += " " + unicode(u) + self.separator
+ t = s
+ retval += "]"
+ return retval
+
+
+class TomlNumpyEncoder(TomlEncoder):
+ def __init__(self, _dict=dict, preserve=False):
+ import numpy as np
+
+ super(TomlNumpyEncoder, self).__init__(_dict, preserve)
+ self.dump_funcs[np.float16] = _dump_float
+ self.dump_funcs[np.float32] = _dump_float
+ self.dump_funcs[np.float64] = _dump_float
+ self.dump_funcs[np.int16] = self._dump_int
+ self.dump_funcs[np.int32] = self._dump_int
+ self.dump_funcs[np.int64] = self._dump_int
+
+ def _dump_int(self, v):
+ return "{}".format(int(v))
+
+
+class TomlPreserveCommentEncoder(TomlEncoder):
+ def __init__(self, _dict=dict, preserve=False):
+ from toml.decoder import CommentValue
+
+ super(TomlPreserveCommentEncoder, self).__init__(_dict, preserve)
+ self.dump_funcs[CommentValue] = lambda v: v.dump(self.dump_value)
+
+
+class TomlPathlibEncoder(TomlEncoder):
+ def _dump_pathlib_path(self, v):
+ return _dump_str(str(v))
+
+ def dump_value(self, v):
+ if (3, 4) <= sys.version_info:
+ import pathlib
+
+ if isinstance(v, pathlib.PurePath):
+ v = str(v)
+ return super(TomlPathlibEncoder, self).dump_value(v)
diff --git a/venv/Lib/site-packages/isort/_vendored/toml/ordered.py b/venv/Lib/site-packages/isort/_vendored/toml/ordered.py
new file mode 100644
index 0000000..013b31e
--- /dev/null
+++ b/venv/Lib/site-packages/isort/_vendored/toml/ordered.py
@@ -0,0 +1,13 @@
+from collections import OrderedDict
+
+from . import TomlDecoder, TomlEncoder
+
+
+class TomlOrderedDecoder(TomlDecoder):
+ def __init__(self):
+ super(self.__class__, self).__init__(_dict=OrderedDict)
+
+
+class TomlOrderedEncoder(TomlEncoder):
+ def __init__(self):
+ super(self.__class__, self).__init__(_dict=OrderedDict)
diff --git a/venv/Lib/site-packages/isort/_vendored/toml/tz.py b/venv/Lib/site-packages/isort/_vendored/toml/tz.py
new file mode 100644
index 0000000..46214bd
--- /dev/null
+++ b/venv/Lib/site-packages/isort/_vendored/toml/tz.py
@@ -0,0 +1,21 @@
+from datetime import timedelta, tzinfo
+
+
+class TomlTz(tzinfo):
+ def __init__(self, toml_offset):
+ if toml_offset == "Z":
+ self._raw_offset = "+00:00"
+ else:
+ self._raw_offset = toml_offset
+ self._sign = -1 if self._raw_offset[0] == "-" else 1
+ self._hours = int(self._raw_offset[1:3])
+ self._minutes = int(self._raw_offset[4:6])
+
+ def tzname(self, dt):
+ return "UTC" + self._raw_offset
+
+ def utcoffset(self, dt):
+ return self._sign * timedelta(hours=self._hours, minutes=self._minutes)
+
+ def dst(self, dt):
+ return timedelta(0)
diff --git a/venv/Lib/site-packages/isort/_version.py b/venv/Lib/site-packages/isort/_version.py
new file mode 100644
index 0000000..cfda0f8
--- /dev/null
+++ b/venv/Lib/site-packages/isort/_version.py
@@ -0,0 +1 @@
+__version__ = "5.4.2"
diff --git a/venv/Lib/site-packages/isort/api.py b/venv/Lib/site-packages/isort/api.py
new file mode 100644
index 0000000..059bbf9
--- /dev/null
+++ b/venv/Lib/site-packages/isort/api.py
@@ -0,0 +1,383 @@
+import shutil
+import sys
+from io import StringIO
+from pathlib import Path
+from typing import Optional, TextIO, Union, cast
+from warnings import warn
+
+from isort import core
+
+from . import io
+from .exceptions import (
+ ExistingSyntaxErrors,
+ FileSkipComment,
+ FileSkipSetting,
+ IntroducedSyntaxErrors,
+)
+from .format import ask_whether_to_apply_changes_to_file, create_terminal_printer, show_unified_diff
+from .io import Empty
+from .place import module as place_module # noqa: F401
+from .place import module_with_reason as place_module_with_reason # noqa: F401
+from .settings import DEFAULT_CONFIG, Config
+
+
+def sort_code_string(
+ code: str,
+ extension: Optional[str] = None,
+ config: Config = DEFAULT_CONFIG,
+ file_path: Optional[Path] = None,
+ disregard_skip: bool = False,
+ show_diff: Union[bool, TextIO] = False,
+ **config_kwargs,
+):
+ """Sorts any imports within the provided code string, returning a new string with them sorted.
+
+ - **code**: The string of code with imports that need to be sorted.
+ - **extension**: The file extension that contains imports. Defaults to filename extension or py.
+ - **config**: The config object to use when sorting imports.
+ - **file_path**: The disk location where the code string was pulled from.
+ - **disregard_skip**: set to `True` if you want to ignore a skip set in config for this file.
+ - **show_diff**: If `True` the changes that need to be done will be printed to stdout, if a
+ TextIO stream is provided results will be written to it, otherwise no diff will be computed.
+ - ****config_kwargs**: Any config modifications.
+ """
+ input_stream = StringIO(code)
+ output_stream = StringIO()
+ config = _config(path=file_path, config=config, **config_kwargs)
+ sort_stream(
+ input_stream,
+ output_stream,
+ extension=extension,
+ config=config,
+ file_path=file_path,
+ disregard_skip=disregard_skip,
+ show_diff=show_diff,
+ )
+ output_stream.seek(0)
+ return output_stream.read()
+
+
+def check_code_string(
+ code: str,
+ show_diff: Union[bool, TextIO] = False,
+ extension: Optional[str] = None,
+ config: Config = DEFAULT_CONFIG,
+ file_path: Optional[Path] = None,
+ disregard_skip: bool = False,
+ **config_kwargs,
+) -> bool:
+ """Checks the order, format, and categorization of imports within the provided code string.
+ Returns `True` if everything is correct, otherwise `False`.
+
+ - **code**: The string of code with imports that need to be sorted.
+ - **show_diff**: If `True` the changes that need to be done will be printed to stdout, if a
+ TextIO stream is provided results will be written to it, otherwise no diff will be computed.
+ - **extension**: The file extension that contains imports. Defaults to filename extension or py.
+ - **config**: The config object to use when sorting imports.
+ - **file_path**: The disk location where the code string was pulled from.
+ - **disregard_skip**: set to `True` if you want to ignore a skip set in config for this file.
+ - ****config_kwargs**: Any config modifications.
+ """
+ config = _config(path=file_path, config=config, **config_kwargs)
+ return check_stream(
+ StringIO(code),
+ show_diff=show_diff,
+ extension=extension,
+ config=config,
+ file_path=file_path,
+ disregard_skip=disregard_skip,
+ )
+
+
+def sort_stream(
+ input_stream: TextIO,
+ output_stream: TextIO,
+ extension: Optional[str] = None,
+ config: Config = DEFAULT_CONFIG,
+ file_path: Optional[Path] = None,
+ disregard_skip: bool = False,
+ show_diff: Union[bool, TextIO] = False,
+ **config_kwargs,
+) -> bool:
+ """Sorts any imports within the provided code stream, outputs to the provided output stream.
+ Returns `True` if anything is modified from the original input stream, otherwise `False`.
+
+ - **input_stream**: The stream of code with imports that need to be sorted.
+ - **output_stream**: The stream where sorted imports should be written to.
+ - **extension**: The file extension that contains imports. Defaults to filename extension or py.
+ - **config**: The config object to use when sorting imports.
+ - **file_path**: The disk location where the code string was pulled from.
+ - **disregard_skip**: set to `True` if you want to ignore a skip set in config for this file.
+ - **show_diff**: If `True` the changes that need to be done will be printed to stdout, if a
+ TextIO stream is provided results will be written to it, otherwise no diff will be computed.
+ - ****config_kwargs**: Any config modifications.
+ """
+ if show_diff:
+ _output_stream = StringIO()
+ _input_stream = StringIO(input_stream.read())
+ changed = sort_stream(
+ input_stream=_input_stream,
+ output_stream=_output_stream,
+ extension=extension,
+ config=config,
+ file_path=file_path,
+ disregard_skip=disregard_skip,
+ **config_kwargs,
+ )
+ _output_stream.seek(0)
+ _input_stream.seek(0)
+ show_unified_diff(
+ file_input=_input_stream.read(),
+ file_output=_output_stream.read(),
+ file_path=file_path,
+ output=output_stream if show_diff is True else cast(TextIO, show_diff),
+ )
+ return changed
+
+ config = _config(path=file_path, config=config, **config_kwargs)
+ content_source = str(file_path or "Passed in content")
+ if not disregard_skip:
+ if file_path and config.is_skipped(file_path):
+ raise FileSkipSetting(content_source)
+
+ _internal_output = output_stream
+
+ if config.atomic:
+ try:
+ file_content = input_stream.read()
+ compile(file_content, content_source, "exec", 0, 1)
+ input_stream = StringIO(file_content)
+ except SyntaxError:
+ raise ExistingSyntaxErrors(content_source)
+
+ if not output_stream.readable():
+ _internal_output = StringIO()
+
+ try:
+ changed = core.process(
+ input_stream,
+ _internal_output,
+ extension=extension or (file_path and file_path.suffix.lstrip(".")) or "py",
+ config=config,
+ )
+ except FileSkipComment:
+ raise FileSkipComment(content_source)
+
+ if config.atomic:
+ _internal_output.seek(0)
+ try:
+ compile(_internal_output.read(), content_source, "exec", 0, 1)
+ _internal_output.seek(0)
+ if _internal_output != output_stream:
+ output_stream.write(_internal_output.read())
+ except SyntaxError: # pragma: no cover
+ raise IntroducedSyntaxErrors(content_source)
+
+ return changed
+
+
+def check_stream(
+ input_stream: TextIO,
+ show_diff: Union[bool, TextIO] = False,
+ extension: Optional[str] = None,
+ config: Config = DEFAULT_CONFIG,
+ file_path: Optional[Path] = None,
+ disregard_skip: bool = False,
+ **config_kwargs,
+) -> bool:
+ """Checks any imports within the provided code stream, returning `False` if any unsorted or
+ incorrectly imports are found or `True` if no problems are identified.
+
+ - **input_stream**: The stream of code with imports that need to be sorted.
+ - **show_diff**: If `True` the changes that need to be done will be printed to stdout, if a
+ TextIO stream is provided results will be written to it, otherwise no diff will be computed.
+ - **extension**: The file extension that contains imports. Defaults to filename extension or py.
+ - **config**: The config object to use when sorting imports.
+ - **file_path**: The disk location where the code string was pulled from.
+ - **disregard_skip**: set to `True` if you want to ignore a skip set in config for this file.
+ - ****config_kwargs**: Any config modifications.
+ """
+ config = _config(path=file_path, config=config, **config_kwargs)
+
+ changed: bool = sort_stream(
+ input_stream=input_stream,
+ output_stream=Empty,
+ extension=extension,
+ config=config,
+ file_path=file_path,
+ disregard_skip=disregard_skip,
+ )
+ printer = create_terminal_printer(color=config.color_output)
+ if not changed:
+ if config.verbose:
+ printer.success(f"{file_path or ''} Everything Looks Good!")
+ return True
+ else:
+ printer.error(f"{file_path or ''} Imports are incorrectly sorted and/or formatted.")
+ if show_diff:
+ output_stream = StringIO()
+ input_stream.seek(0)
+ file_contents = input_stream.read()
+ sort_stream(
+ input_stream=StringIO(file_contents),
+ output_stream=output_stream,
+ extension=extension,
+ config=config,
+ file_path=file_path,
+ disregard_skip=disregard_skip,
+ )
+ output_stream.seek(0)
+
+ show_unified_diff(
+ file_input=file_contents,
+ file_output=output_stream.read(),
+ file_path=file_path,
+ output=None if show_diff is True else cast(TextIO, show_diff),
+ )
+ return False
+
+
+def check_file(
+ filename: Union[str, Path],
+ show_diff: Union[bool, TextIO] = False,
+ config: Config = DEFAULT_CONFIG,
+ file_path: Optional[Path] = None,
+ disregard_skip: bool = True,
+ extension: Optional[str] = None,
+ **config_kwargs,
+) -> bool:
+ """Checks any imports within the provided file, returning `False` if any unsorted or
+ incorrectly imports are found or `True` if no problems are identified.
+
+ - **filename**: The name or Path of the file to check.
+ - **show_diff**: If `True` the changes that need to be done will be printed to stdout, if a
+ TextIO stream is provided results will be written to it, otherwise no diff will be computed.
+ - **config**: The config object to use when sorting imports.
+ - **file_path**: The disk location where the code string was pulled from.
+ - **disregard_skip**: set to `True` if you want to ignore a skip set in config for this file.
+ - **extension**: The file extension that contains imports. Defaults to filename extension or py.
+ - ****config_kwargs**: Any config modifications.
+ """
+ with io.File.read(filename) as source_file:
+ return check_stream(
+ source_file.stream,
+ show_diff=show_diff,
+ extension=extension,
+ config=config,
+ file_path=file_path or source_file.path,
+ disregard_skip=disregard_skip,
+ **config_kwargs,
+ )
+
+
+def sort_file(
+ filename: Union[str, Path],
+ extension: Optional[str] = None,
+ config: Config = DEFAULT_CONFIG,
+ file_path: Optional[Path] = None,
+ disregard_skip: bool = True,
+ ask_to_apply: bool = False,
+ show_diff: Union[bool, TextIO] = False,
+ write_to_stdout: bool = False,
+ **config_kwargs,
+) -> bool:
+ """Sorts and formats any groups of imports imports within the provided file or Path.
+ Returns `True` if the file has been changed, otherwise `False`.
+
+ - **filename**: The name or Path of the file to format.
+ - **extension**: The file extension that contains imports. Defaults to filename extension or py.
+ - **config**: The config object to use when sorting imports.
+ - **file_path**: The disk location where the code string was pulled from.
+ - **disregard_skip**: set to `True` if you want to ignore a skip set in config for this file.
+ - **ask_to_apply**: If `True`, prompt before applying any changes.
+ - **show_diff**: If `True` the changes that need to be done will be printed to stdout, if a
+ TextIO stream is provided results will be written to it, otherwise no diff will be computed.
+ - **write_to_stdout**: If `True`, write to stdout instead of the input file.
+ - ****config_kwargs**: Any config modifications.
+ """
+ with io.File.read(filename) as source_file:
+ changed: bool = False
+ try:
+ if write_to_stdout:
+ changed = sort_stream(
+ input_stream=source_file.stream,
+ output_stream=sys.stdout,
+ config=config,
+ file_path=file_path or source_file.path,
+ disregard_skip=disregard_skip,
+ extension=extension,
+ **config_kwargs,
+ )
+ else:
+ tmp_file = source_file.path.with_suffix(source_file.path.suffix + ".isorted")
+ try:
+ with tmp_file.open(
+ "w", encoding=source_file.encoding, newline=""
+ ) as output_stream:
+ shutil.copymode(filename, tmp_file)
+ changed = sort_stream(
+ input_stream=source_file.stream,
+ output_stream=output_stream,
+ config=config,
+ file_path=file_path or source_file.path,
+ disregard_skip=disregard_skip,
+ extension=extension,
+ **config_kwargs,
+ )
+ if changed:
+ if show_diff or ask_to_apply:
+ source_file.stream.seek(0)
+ with tmp_file.open(
+ encoding=source_file.encoding, newline=""
+ ) as tmp_out:
+ show_unified_diff(
+ file_input=source_file.stream.read(),
+ file_output=tmp_out.read(),
+ file_path=file_path or source_file.path,
+ output=None if show_diff is True else cast(TextIO, show_diff),
+ )
+ if show_diff or (
+ ask_to_apply
+ and not ask_whether_to_apply_changes_to_file(
+ str(source_file.path)
+ )
+ ):
+ return False
+ source_file.stream.close()
+ tmp_file.replace(source_file.path)
+ if not config.quiet:
+ print(f"Fixing {source_file.path}")
+ finally:
+ try: # Python 3.8+: use `missing_ok=True` instead of try except.
+ tmp_file.unlink()
+ except FileNotFoundError:
+ pass
+ except ExistingSyntaxErrors:
+ warn(f"{file_path} unable to sort due to existing syntax errors")
+ except IntroducedSyntaxErrors: # pragma: no cover
+ warn(f"{file_path} unable to sort as isort introduces new syntax errors")
+
+ return changed
+
+
+def _config(
+ path: Optional[Path] = None, config: Config = DEFAULT_CONFIG, **config_kwargs
+) -> Config:
+ if path:
+ if (
+ config is DEFAULT_CONFIG
+ and "settings_path" not in config_kwargs
+ and "settings_file" not in config_kwargs
+ ):
+ config_kwargs["settings_path"] = path
+
+ if config_kwargs:
+ if config is not DEFAULT_CONFIG:
+ raise ValueError(
+ "You can either specify custom configuration options using kwargs or "
+ "passing in a Config object. Not Both!"
+ )
+
+ config = Config(**config_kwargs)
+
+ return config
diff --git a/venv/Lib/site-packages/isort/comments.py b/venv/Lib/site-packages/isort/comments.py
new file mode 100644
index 0000000..b865b32
--- /dev/null
+++ b/venv/Lib/site-packages/isort/comments.py
@@ -0,0 +1,32 @@
+from typing import List, Optional, Tuple
+
+
+def parse(line: str) -> Tuple[str, str]:
+ """Parses import lines for comments and returns back the
+ import statement and the associated comment.
+ """
+ comment_start = line.find("#")
+ if comment_start != -1:
+ return (line[:comment_start], line[comment_start + 1 :].strip())
+
+ return (line, "")
+
+
+def add_to_line(
+ comments: Optional[List[str]],
+ original_string: str = "",
+ removed: bool = False,
+ comment_prefix: str = "",
+) -> str:
+ """Returns a string with comments added if removed is not set."""
+ if removed:
+ return parse(original_string)[0]
+
+ if not comments:
+ return original_string
+ else:
+ unique_comments: List[str] = []
+ for comment in comments:
+ if comment not in unique_comments:
+ unique_comments.append(comment)
+ return f"{parse(original_string)[0]}{comment_prefix} {'; '.join(unique_comments)}"
diff --git a/venv/Lib/site-packages/isort/core.py b/venv/Lib/site-packages/isort/core.py
new file mode 100644
index 0000000..010aa7f
--- /dev/null
+++ b/venv/Lib/site-packages/isort/core.py
@@ -0,0 +1,386 @@
+import textwrap
+from io import StringIO
+from itertools import chain
+from typing import List, TextIO, Union
+
+import isort.literal
+from isort.settings import DEFAULT_CONFIG, Config
+
+from . import output, parse
+from .exceptions import FileSkipComment
+from .format import format_natural, remove_whitespace
+from .settings import FILE_SKIP_COMMENTS
+
+CIMPORT_IDENTIFIERS = ("cimport ", "cimport*", "from.cimport")
+IMPORT_START_IDENTIFIERS = ("from ", "from.import", "import ", "import*") + CIMPORT_IDENTIFIERS
+COMMENT_INDICATORS = ('"""', "'''", "'", '"', "#")
+CODE_SORT_COMMENTS = (
+ "# isort: list",
+ "# isort: dict",
+ "# isort: set",
+ "# isort: unique-list",
+ "# isort: tuple",
+ "# isort: unique-tuple",
+ "# isort: assignments",
+)
+
+
+def process(
+ input_stream: TextIO,
+ output_stream: TextIO,
+ extension: str = "py",
+ config: Config = DEFAULT_CONFIG,
+) -> bool:
+ """Parses stream identifying sections of contiguous imports and sorting them
+
+ Code with unsorted imports is read from the provided `input_stream`, sorted and then
+ outputted to the specified `output_stream`.
+
+ - `input_stream`: Text stream with unsorted import sections.
+ - `output_stream`: Text stream to output sorted inputs into.
+ - `config`: Config settings to use when sorting imports. Defaults settings.
+ - *Default*: `isort.settings.DEFAULT_CONFIG`.
+ - `extension`: The file extension or file extension rules that should be used.
+ - *Default*: `"py"`.
+ - *Choices*: `["py", "pyi", "pyx"]`.
+
+ Returns `True` if there were changes that needed to be made (errors present) from what
+ was provided in the input_stream, otherwise `False`.
+ """
+ line_separator: str = config.line_ending
+ add_imports: List[str] = [format_natural(addition) for addition in config.add_imports]
+ import_section: str = ""
+ next_import_section: str = ""
+ next_cimports: bool = False
+ in_quote: str = ""
+ first_comment_index_start: int = -1
+ first_comment_index_end: int = -1
+ contains_imports: bool = False
+ in_top_comment: bool = False
+ first_import_section: bool = True
+ section_comments = [f"# {heading}" for heading in config.import_headings.values()]
+ indent: str = ""
+ isort_off: bool = False
+ code_sorting: Union[bool, str] = False
+ code_sorting_section: str = ""
+ code_sorting_indent: str = ""
+ cimports: bool = False
+ made_changes: bool = False
+
+ if config.float_to_top:
+ new_input = ""
+ current = ""
+ isort_off = False
+ for line in chain(input_stream, (None,)):
+ if isort_off and line is not None:
+ if line == "# isort: on\n":
+ isort_off = False
+ new_input += line
+ elif line in ("# isort: split\n", "# isort: off\n", None) or str(line).endswith(
+ "# isort: split\n"
+ ):
+ if line == "# isort: off\n":
+ isort_off = True
+ if current:
+ parsed = parse.file_contents(current, config=config)
+ extra_space = ""
+ while current[-1] == "\n":
+ extra_space += "\n"
+ current = current[:-1]
+ extra_space = extra_space.replace("\n", "", 1)
+ sorted_output = output.sorted_imports(
+ parsed, config, extension, import_type="import"
+ )
+ made_changes = made_changes or _has_changed(
+ before=current,
+ after=sorted_output,
+ line_separator=parsed.line_separator,
+ ignore_whitespace=config.ignore_whitespace,
+ )
+ new_input += sorted_output
+ new_input += extra_space
+ current = ""
+ new_input += line or ""
+ else:
+ current += line or ""
+
+ input_stream = StringIO(new_input)
+
+ for index, line in enumerate(chain(input_stream, (None,))):
+ if line is None:
+ if index == 0 and not config.force_adds:
+ return False
+
+ not_imports = True
+ line = ""
+ if not line_separator:
+ line_separator = "\n"
+
+ if code_sorting and code_sorting_section:
+ output_stream.write(
+ textwrap.indent(
+ isort.literal.assignment(
+ code_sorting_section,
+ str(code_sorting),
+ extension,
+ config=_indented_config(config, indent),
+ ),
+ code_sorting_indent,
+ )
+ )
+ else:
+ stripped_line = line.strip()
+ if stripped_line and not line_separator:
+ line_separator = line[len(line.rstrip()) :].replace(" ", "").replace("\t", "")
+
+ for file_skip_comment in FILE_SKIP_COMMENTS:
+ if file_skip_comment in line:
+ raise FileSkipComment("Passed in content")
+
+ if (
+ (index == 0 or (index in (1, 2) and not contains_imports))
+ and stripped_line.startswith("#")
+ and stripped_line not in section_comments
+ ):
+ in_top_comment = True
+ elif in_top_comment:
+ if not line.startswith("#") or stripped_line in section_comments:
+ in_top_comment = False
+ first_comment_index_end = index - 1
+
+ if (not stripped_line.startswith("#") or in_quote) and '"' in line or "'" in line:
+ char_index = 0
+ if first_comment_index_start == -1 and (
+ line.startswith('"') or line.startswith("'")
+ ):
+ first_comment_index_start = index
+ while char_index < len(line):
+ if line[char_index] == "\\":
+ char_index += 1
+ elif in_quote:
+ if line[char_index : char_index + len(in_quote)] == in_quote:
+ in_quote = ""
+ if first_comment_index_end < first_comment_index_start:
+ first_comment_index_end = index
+ elif line[char_index] in ("'", '"'):
+ long_quote = line[char_index : char_index + 3]
+ if long_quote in ('"""', "'''"):
+ in_quote = long_quote
+ char_index += 2
+ else:
+ in_quote = line[char_index]
+ elif line[char_index] == "#":
+ break
+ char_index += 1
+
+ not_imports = bool(in_quote) or in_top_comment or isort_off
+ if not (in_quote or in_top_comment):
+ stripped_line = line.strip()
+ if isort_off:
+ if stripped_line == "# isort: on":
+ isort_off = False
+ elif stripped_line == "# isort: off":
+ not_imports = True
+ isort_off = True
+ elif stripped_line.endswith("# isort: split"):
+ not_imports = True
+ elif stripped_line in CODE_SORT_COMMENTS:
+ code_sorting = stripped_line.split("isort: ")[1].strip()
+ code_sorting_indent = line[: -len(line.lstrip())]
+ not_imports = True
+ elif code_sorting:
+ if not stripped_line:
+ output_stream.write(
+ textwrap.indent(
+ isort.literal.assignment(
+ code_sorting_section,
+ str(code_sorting),
+ extension,
+ config=_indented_config(config, indent),
+ ),
+ code_sorting_indent,
+ )
+ )
+ not_imports = True
+ code_sorting = False
+ code_sorting_section = ""
+ code_sorting_indent = ""
+ else:
+ code_sorting_section += line
+ line = ""
+ elif stripped_line in config.section_comments and not import_section:
+ import_section += line
+ indent = line[: -len(line.lstrip())]
+ elif not (stripped_line or contains_imports):
+ if add_imports and not indent and not config.append_only:
+ if not import_section:
+ output_stream.write(line)
+ line = ""
+ import_section += line_separator.join(add_imports) + line_separator
+ contains_imports = True
+ add_imports = []
+ else:
+ not_imports = True
+ elif (
+ not stripped_line
+ or stripped_line.startswith("#")
+ and (not indent or indent + line.lstrip() == line)
+ and not config.treat_all_comments_as_code
+ and stripped_line not in config.treat_comments_as_code
+ ):
+ import_section += line
+ elif stripped_line.startswith(IMPORT_START_IDENTIFIERS):
+ contains_imports = True
+
+ new_indent = line[: -len(line.lstrip())]
+ import_statement = line
+ stripped_line = line.strip().split("#")[0]
+ while stripped_line.endswith("\\") or (
+ "(" in stripped_line and ")" not in stripped_line
+ ):
+ if stripped_line.endswith("\\"):
+ while stripped_line and stripped_line.endswith("\\"):
+ line = input_stream.readline()
+ stripped_line = line.strip().split("#")[0]
+ import_statement += line
+ else:
+ while ")" not in stripped_line:
+ line = input_stream.readline()
+ stripped_line = line.strip().split("#")[0]
+ import_statement += line
+
+ cimport_statement: bool = False
+ if (
+ import_statement.lstrip().startswith(CIMPORT_IDENTIFIERS)
+ or " cimport " in import_statement
+ or " cimport*" in import_statement
+ or " cimport(" in import_statement
+ or ".cimport" in import_statement
+ ):
+ cimport_statement = True
+
+ if cimport_statement != cimports or (new_indent != indent and import_section):
+ if import_section:
+ next_cimports = cimport_statement
+ next_import_section = import_statement
+ import_statement = ""
+ not_imports = True
+ line = ""
+ else:
+ cimports = cimport_statement
+
+ indent = new_indent
+ import_section += import_statement
+ else:
+ not_imports = True
+
+ if not_imports:
+ raw_import_section: str = import_section
+ if (
+ add_imports
+ and not config.append_only
+ and not in_top_comment
+ and not in_quote
+ and not import_section
+ and not line.lstrip().startswith(COMMENT_INDICATORS)
+ ):
+ import_section = line_separator.join(add_imports) + line_separator
+ contains_imports = True
+ add_imports = []
+
+ if next_import_section and not import_section: # pragma: no cover
+ raw_import_section = import_section = next_import_section
+ next_import_section = ""
+
+ if import_section:
+ if add_imports and not indent:
+ import_section = (
+ line_separator.join(add_imports) + line_separator + import_section
+ )
+ contains_imports = True
+ add_imports = []
+
+ if not indent:
+ import_section += line
+ raw_import_section += line
+ if not contains_imports:
+ output_stream.write(import_section)
+ else:
+ leading_whitespace = import_section[: -len(import_section.lstrip())]
+ trailing_whitespace = import_section[len(import_section.rstrip()) :]
+ if first_import_section and not import_section.lstrip(
+ line_separator
+ ).startswith(COMMENT_INDICATORS):
+ import_section = import_section.lstrip(line_separator)
+ raw_import_section = raw_import_section.lstrip(line_separator)
+ first_import_section = False
+
+ if indent:
+ import_section = "".join(
+ line[len(indent) :] for line in import_section.splitlines(keepends=True)
+ )
+
+ sorted_import_section = output.sorted_imports(
+ parse.file_contents(import_section, config=config),
+ _indented_config(config, indent),
+ extension,
+ import_type="cimport" if cimports else "import",
+ )
+ if not (import_section.strip() and not sorted_import_section):
+ if indent:
+ sorted_import_section = (
+ leading_whitespace
+ + textwrap.indent(sorted_import_section, indent).strip()
+ + trailing_whitespace
+ )
+
+ made_changes = made_changes or _has_changed(
+ before=raw_import_section,
+ after=sorted_import_section,
+ line_separator=line_separator,
+ ignore_whitespace=config.ignore_whitespace,
+ )
+
+ output_stream.write(sorted_import_section)
+ if not line and not indent and next_import_section:
+ output_stream.write(line_separator)
+
+ if indent:
+ output_stream.write(line)
+ if not next_import_section:
+ indent = ""
+
+ if next_import_section:
+ cimports = next_cimports
+ contains_imports = True
+ else:
+ contains_imports = False
+ import_section = next_import_section
+ next_import_section = ""
+ else:
+ output_stream.write(line)
+ not_imports = False
+
+ return made_changes
+
+
+def _indented_config(config: Config, indent: str):
+ if not indent:
+ return config
+
+ return Config(
+ config=config,
+ line_length=max(config.line_length - len(indent), 0),
+ wrap_length=max(config.wrap_length - len(indent), 0),
+ lines_after_imports=1,
+ )
+
+
+def _has_changed(before: str, after: str, line_separator: str, ignore_whitespace: bool) -> bool:
+ if ignore_whitespace:
+ return (
+ remove_whitespace(before, line_separator=line_separator).strip()
+ != remove_whitespace(after, line_separator=line_separator).strip()
+ )
+ else:
+ return before.strip() != after.strip()
diff --git a/venv/Lib/site-packages/isort/deprecated/__init__.py b/venv/Lib/site-packages/isort/deprecated/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/venv/Lib/site-packages/isort/deprecated/finders.py b/venv/Lib/site-packages/isort/deprecated/finders.py
new file mode 100644
index 0000000..77eb23f
--- /dev/null
+++ b/venv/Lib/site-packages/isort/deprecated/finders.py
@@ -0,0 +1,403 @@
+"""Finders try to find right section for passed module name"""
+import importlib.machinery
+import inspect
+import os
+import os.path
+import re
+import sys
+import sysconfig
+from abc import ABCMeta, abstractmethod
+from fnmatch import fnmatch
+from functools import lru_cache
+from glob import glob
+from pathlib import Path
+from typing import Dict, Iterable, Iterator, List, Optional, Pattern, Sequence, Tuple, Type
+
+from isort import sections
+from isort.settings import KNOWN_SECTION_MAPPING, Config
+from isort.utils import chdir, exists_case_sensitive
+
+try:
+ from pipreqs import pipreqs
+
+except ImportError:
+ pipreqs = None
+
+try:
+ from pip_api import parse_requirements
+
+except ImportError:
+ parse_requirements = None
+
+try:
+ from requirementslib import Pipfile
+
+except ImportError:
+ Pipfile = None
+
+
+class BaseFinder(metaclass=ABCMeta):
+ def __init__(self, config: Config) -> None:
+ self.config = config
+
+ @abstractmethod
+ def find(self, module_name: str) -> Optional[str]:
+ raise NotImplementedError
+
+
+class ForcedSeparateFinder(BaseFinder):
+ def find(self, module_name: str) -> Optional[str]:
+ for forced_separate in self.config.forced_separate:
+ # Ensure all forced_separate patterns will match to end of string
+ path_glob = forced_separate
+ if not forced_separate.endswith("*"):
+ path_glob = "%s*" % forced_separate
+
+ if fnmatch(module_name, path_glob) or fnmatch(module_name, "." + path_glob):
+ return forced_separate
+ return None
+
+
+class LocalFinder(BaseFinder):
+ def find(self, module_name: str) -> Optional[str]:
+ if module_name.startswith("."):
+ return "LOCALFOLDER"
+ return None
+
+
+class KnownPatternFinder(BaseFinder):
+ def __init__(self, config: Config) -> None:
+ super().__init__(config)
+
+ self.known_patterns: List[Tuple[Pattern[str], str]] = []
+ for placement in reversed(config.sections):
+ known_placement = KNOWN_SECTION_MAPPING.get(placement, placement).lower()
+ config_key = f"known_{known_placement}"
+ known_patterns = list(
+ getattr(self.config, config_key, self.config.known_other.get(known_placement, []))
+ )
+ known_patterns = [
+ pattern
+ for known_pattern in known_patterns
+ for pattern in self._parse_known_pattern(known_pattern)
+ ]
+ for known_pattern in known_patterns:
+ regexp = "^" + known_pattern.replace("*", ".*").replace("?", ".?") + "$"
+ self.known_patterns.append((re.compile(regexp), placement))
+
+ def _parse_known_pattern(self, pattern: str) -> List[str]:
+ """Expand pattern if identified as a directory and return found sub packages"""
+ if pattern.endswith(os.path.sep):
+ patterns = [
+ filename
+ for filename in os.listdir(os.path.join(self.config.directory, pattern))
+ if os.path.isdir(os.path.join(self.config.directory, pattern, filename))
+ ]
+ else:
+ patterns = [pattern]
+
+ return patterns
+
+ def find(self, module_name: str) -> Optional[str]:
+ # Try to find most specific placement instruction match (if any)
+ parts = module_name.split(".")
+ module_names_to_check = (".".join(parts[:first_k]) for first_k in range(len(parts), 0, -1))
+ for module_name_to_check in module_names_to_check:
+ for pattern, placement in self.known_patterns:
+ if pattern.match(module_name_to_check):
+ return placement
+ return None
+
+
+class PathFinder(BaseFinder):
+ def __init__(self, config: Config, path: str = ".") -> None:
+ super().__init__(config)
+
+ # restore the original import path (i.e. not the path to bin/isort)
+ root_dir = os.path.abspath(path)
+ src_dir = f"{root_dir}/src"
+ self.paths = [root_dir, src_dir]
+
+ # virtual env
+ self.virtual_env = self.config.virtual_env or os.environ.get("VIRTUAL_ENV")
+ if self.virtual_env:
+ self.virtual_env = os.path.realpath(self.virtual_env)
+ self.virtual_env_src = ""
+ if self.virtual_env:
+ self.virtual_env_src = f"{self.virtual_env}/src/"
+ for venv_path in glob(f"{self.virtual_env}/lib/python*/site-packages"):
+ if venv_path not in self.paths:
+ self.paths.append(venv_path)
+ for nested_venv_path in glob(f"{self.virtual_env}/lib/python*/*/site-packages"):
+ if nested_venv_path not in self.paths:
+ self.paths.append(nested_venv_path)
+ for venv_src_path in glob(f"{self.virtual_env}/src/*"):
+ if os.path.isdir(venv_src_path):
+ self.paths.append(venv_src_path)
+
+ # conda
+ self.conda_env = self.config.conda_env or os.environ.get("CONDA_PREFIX") or ""
+ if self.conda_env:
+ self.conda_env = os.path.realpath(self.conda_env)
+ for conda_path in glob(f"{self.conda_env}/lib/python*/site-packages"):
+ if conda_path not in self.paths:
+ self.paths.append(conda_path)
+ for nested_conda_path in glob(f"{self.conda_env}/lib/python*/*/site-packages"):
+ if nested_conda_path not in self.paths:
+ self.paths.append(nested_conda_path)
+
+ # handle case-insensitive paths on windows
+ self.stdlib_lib_prefix = os.path.normcase(sysconfig.get_paths()["stdlib"])
+ if self.stdlib_lib_prefix not in self.paths:
+ self.paths.append(self.stdlib_lib_prefix)
+
+ # add system paths
+ for system_path in sys.path[1:]:
+ if system_path not in self.paths:
+ self.paths.append(system_path)
+
+ def find(self, module_name: str) -> Optional[str]:
+ for prefix in self.paths:
+ package_path = "/".join((prefix, module_name.split(".")[0]))
+ path_obj = Path(package_path).resolve()
+ is_module = (
+ exists_case_sensitive(package_path + ".py")
+ or any(
+ exists_case_sensitive(package_path + ext_suffix)
+ for ext_suffix in importlib.machinery.EXTENSION_SUFFIXES
+ )
+ or exists_case_sensitive(package_path + "/__init__.py")
+ )
+ is_package = exists_case_sensitive(package_path) and os.path.isdir(package_path)
+ if is_module or is_package:
+ if (
+ "site-packages" in prefix
+ or "dist-packages" in prefix
+ or (self.virtual_env and self.virtual_env_src in prefix)
+ ):
+ return sections.THIRDPARTY
+ elif os.path.normcase(prefix) == self.stdlib_lib_prefix:
+ return sections.STDLIB
+ elif self.conda_env and self.conda_env in prefix:
+ return sections.THIRDPARTY
+ for src_path in self.config.src_paths:
+ if src_path in path_obj.parents and not self.config.is_skipped(path_obj):
+ return sections.FIRSTPARTY
+
+ if os.path.normcase(prefix).startswith(self.stdlib_lib_prefix):
+ return sections.STDLIB # pragma: no cover - edge case for one OS. Hard to test.
+
+ return self.config.default_section
+ return None
+
+
+class ReqsBaseFinder(BaseFinder):
+ enabled = False
+
+ def __init__(self, config: Config, path: str = ".") -> None:
+ super().__init__(config)
+ self.path = path
+ if self.enabled:
+ self.mapping = self._load_mapping()
+ self.names = self._load_names()
+
+ @abstractmethod
+ def _get_names(self, path: str) -> Iterator[str]:
+ raise NotImplementedError
+
+ @abstractmethod
+ def _get_files_from_dir(self, path: str) -> Iterator[str]:
+ raise NotImplementedError
+
+ @staticmethod
+ def _load_mapping() -> Optional[Dict[str, str]]:
+ """Return list of mappings `package_name -> module_name`
+
+ Example:
+ django-haystack -> haystack
+ """
+ if not pipreqs:
+ return None
+ path = os.path.dirname(inspect.getfile(pipreqs))
+ path = os.path.join(path, "mapping")
+ with open(path) as f:
+ mappings: Dict[str, str] = {} # pypi_name: import_name
+ for line in f:
+ import_name, _, pypi_name = line.strip().partition(":")
+ mappings[pypi_name] = import_name
+ return mappings
+ # return dict(tuple(line.strip().split(":")[::-1]) for line in f)
+
+ def _load_names(self) -> List[str]:
+ """Return list of thirdparty modules from requirements"""
+ names = []
+ for path in self._get_files():
+ for name in self._get_names(path):
+ names.append(self._normalize_name(name))
+ return names
+
+ @staticmethod
+ def _get_parents(path: str) -> Iterator[str]:
+ prev = ""
+ while path != prev:
+ prev = path
+ yield path
+ path = os.path.dirname(path)
+
+ def _get_files(self) -> Iterator[str]:
+ """Return paths to all requirements files"""
+ path = os.path.abspath(self.path)
+ if os.path.isfile(path):
+ path = os.path.dirname(path)
+
+ for path in self._get_parents(path):
+ yield from self._get_files_from_dir(path)
+
+ def _normalize_name(self, name: str) -> str:
+ """Convert package name to module name
+
+ Examples:
+ Django -> django
+ django-haystack -> django_haystack
+ Flask-RESTFul -> flask_restful
+ """
+ if self.mapping:
+ name = self.mapping.get(name.replace("-", "_"), name)
+ return name.lower().replace("-", "_")
+
+ def find(self, module_name: str) -> Optional[str]:
+ # required lib not installed yet
+ if not self.enabled:
+ return None
+
+ module_name, _sep, _submodules = module_name.partition(".")
+ module_name = module_name.lower()
+ if not module_name:
+ return None
+
+ for name in self.names:
+ if module_name == name:
+ return sections.THIRDPARTY
+ return None
+
+
+class RequirementsFinder(ReqsBaseFinder):
+ exts = (".txt", ".in")
+ enabled = bool(parse_requirements)
+
+ def _get_files_from_dir(self, path: str) -> Iterator[str]:
+ """Return paths to requirements files from passed dir."""
+ yield from self._get_files_from_dir_cached(path)
+
+ @classmethod
+ @lru_cache(maxsize=16)
+ def _get_files_from_dir_cached(cls, path: str) -> List[str]:
+ results = []
+
+ for fname in os.listdir(path):
+ if "requirements" not in fname:
+ continue
+ full_path = os.path.join(path, fname)
+
+ # *requirements*/*.{txt,in}
+ if os.path.isdir(full_path):
+ for subfile_name in os.listdir(full_path):
+ for ext in cls.exts:
+ if subfile_name.endswith(ext):
+ results.append(os.path.join(full_path, subfile_name))
+ continue
+
+ # *requirements*.{txt,in}
+ if os.path.isfile(full_path):
+ for ext in cls.exts:
+ if fname.endswith(ext):
+ results.append(full_path)
+ break
+
+ return results
+
+ def _get_names(self, path: str) -> Iterator[str]:
+ """Load required packages from path to requirements file"""
+ yield from self._get_names_cached(path)
+
+ @classmethod
+ @lru_cache(maxsize=16)
+ def _get_names_cached(cls, path: str) -> List[str]:
+ result = []
+
+ with chdir(os.path.dirname(path)):
+ requirements = parse_requirements(path)
+ for req in requirements.values():
+ if req.name:
+ result.append(req.name)
+
+ return result
+
+
+class PipfileFinder(ReqsBaseFinder):
+ enabled = bool(Pipfile)
+
+ def _get_names(self, path: str) -> Iterator[str]:
+ with chdir(path):
+ project = Pipfile.load(path)
+ for req in project.packages:
+ yield req.name
+
+ def _get_files_from_dir(self, path: str) -> Iterator[str]:
+ if "Pipfile" in os.listdir(path):
+ yield path
+
+
+class DefaultFinder(BaseFinder):
+ def find(self, module_name: str) -> Optional[str]:
+ return self.config.default_section
+
+
+class FindersManager:
+ _default_finders_classes: Sequence[Type[BaseFinder]] = (
+ ForcedSeparateFinder,
+ LocalFinder,
+ KnownPatternFinder,
+ PathFinder,
+ PipfileFinder,
+ RequirementsFinder,
+ DefaultFinder,
+ )
+
+ def __init__(
+ self, config: Config, finder_classes: Optional[Iterable[Type[BaseFinder]]] = None
+ ) -> None:
+ self.verbose: bool = config.verbose
+
+ if finder_classes is None:
+ finder_classes = self._default_finders_classes
+ finders: List[BaseFinder] = []
+ for finder_cls in finder_classes:
+ try:
+ finders.append(finder_cls(config))
+ except Exception as exception:
+ # if one finder fails to instantiate isort can continue using the rest
+ if self.verbose:
+ print(
+ (
+ f"{finder_cls.__name__} encountered an error ({exception}) during "
+ "instantiation and cannot be used"
+ )
+ )
+ self.finders: Tuple[BaseFinder, ...] = tuple(finders)
+
+ def find(self, module_name: str) -> Optional[str]:
+ for finder in self.finders:
+ try:
+ section = finder.find(module_name)
+ if section is not None:
+ return section
+ except Exception as exception:
+ # isort has to be able to keep trying to identify the correct
+ # import section even if one approach fails
+ if self.verbose:
+ print(
+ f"{finder.__class__.__name__} encountered an error ({exception}) while "
+ f"trying to identify the {module_name} module"
+ )
+ return None
diff --git a/venv/Lib/site-packages/isort/exceptions.py b/venv/Lib/site-packages/isort/exceptions.py
new file mode 100644
index 0000000..9f45744
--- /dev/null
+++ b/venv/Lib/site-packages/isort/exceptions.py
@@ -0,0 +1,134 @@
+"""All isort specific exception classes should be defined here"""
+from .profiles import profiles
+
+
+class ISortError(Exception):
+ """Base isort exception object from which all isort sourced exceptions should inherit"""
+
+
+class InvalidSettingsPath(ISortError):
+ """Raised when a settings path is provided that is neither a valid file or directory"""
+
+ def __init__(self, settings_path: str):
+ super().__init__(
+ f"isort was told to use the settings_path: {settings_path} as the base directory or "
+ "file that represents the starting point of config file discovery, but it does not "
+ "exist."
+ )
+ self.settings_path = settings_path
+
+
+class ExistingSyntaxErrors(ISortError):
+ """Raised when isort is told to sort imports within code that has existing syntax errors"""
+
+ def __init__(self, file_path: str):
+ super().__init__(
+ f"isort was told to sort imports within code that contains syntax errors: "
+ f"{file_path}."
+ )
+ self.file_path = file_path
+
+
+class IntroducedSyntaxErrors(ISortError):
+ """Raised when isort has introduced a syntax error in the process of sorting imports"""
+
+ def __init__(self, file_path: str):
+ super().__init__(
+ f"isort introduced syntax errors when attempting to sort the imports contained within "
+ f"{file_path}."
+ )
+ self.file_path = file_path
+
+
+class FileSkipped(ISortError):
+ """Should be raised when a file is skipped for any reason"""
+
+ def __init__(self, message: str, file_path: str):
+ super().__init__(message)
+ self.file_path = file_path
+
+
+class FileSkipComment(FileSkipped):
+ """Raised when an entire file is skipped due to a isort skip file comment"""
+
+ def __init__(self, file_path: str):
+ super().__init__(
+ f"{file_path} contains an file skip comment and was skipped.", file_path=file_path
+ )
+
+
+class FileSkipSetting(FileSkipped):
+ """Raised when an entire file is skipped due to provided isort settings"""
+
+ def __init__(self, file_path: str):
+ super().__init__(
+ f"{file_path} was skipped as it's listed in 'skip' setting"
+ " or matches a glob in 'skip_glob' setting",
+ file_path=file_path,
+ )
+
+
+class ProfileDoesNotExist(ISortError):
+ """Raised when a profile is set by the user that doesn't exist"""
+
+ def __init__(self, profile: str):
+ super().__init__(
+ f"Specified profile of {profile} does not exist. "
+ f"Available profiles: {','.join(profiles)}."
+ )
+ self.profile = profile
+
+
+class FormattingPluginDoesNotExist(ISortError):
+ """Raised when a formatting plugin is set by the user that doesn't exist"""
+
+ def __init__(self, formatter: str):
+ super().__init__(f"Specified formatting plugin of {formatter} does not exist. ")
+ self.formatter = formatter
+
+
+class LiteralParsingFailure(ISortError):
+ """Raised when one of isorts literal sorting comments is used but isort can't parse the
+ the given data structure.
+ """
+
+ def __init__(self, code: str, original_error: Exception):
+ super().__init__(
+ f"isort failed to parse the given literal {code}. It's important to note "
+ "that isort literal sorting only supports simple literals parsable by "
+ f"ast.literal_eval which gave the exception of {original_error}."
+ )
+ self.code = code
+ self.original_error = original_error
+
+
+class LiteralSortTypeMismatch(ISortError):
+ """Raised when an isort literal sorting comment is used, with a type that doesn't match the
+ supplied data structure's type.
+ """
+
+ def __init__(self, kind: type, expected_kind: type):
+ super().__init__(
+ f"isort was told to sort a literal of type {expected_kind} but was given "
+ f"a literal of type {kind}."
+ )
+ self.kind = kind
+ self.expected_kind = expected_kind
+
+
+class AssignmentsFormatMismatch(ISortError):
+ """Raised when isort is told to sort assignments but the format of the assignment section
+ doesn't match isort's expectation.
+ """
+
+ def __init__(self, code: str):
+ super().__init__(
+ "isort was told to sort a section of assignments, however the given code:\n\n"
+ f"{code}\n\n"
+ "Does not match isort's strict single line formatting requirement for assignment "
+ "sorting:\n\n"
+ "{variable_name} = {value}\n"
+ "{variable_name2} = {value2}\n"
+ "...\n\n"
+ )
+ self.code = code
diff --git a/venv/Lib/site-packages/isort/format.py b/venv/Lib/site-packages/isort/format.py
new file mode 100644
index 0000000..3dbb195
--- /dev/null
+++ b/venv/Lib/site-packages/isort/format.py
@@ -0,0 +1,121 @@
+import sys
+from datetime import datetime
+from difflib import unified_diff
+from pathlib import Path
+from typing import Optional, TextIO
+
+try:
+ import colorama
+except ImportError:
+ colorama_unavailable = True
+else:
+ colorama_unavailable = False
+ colorama.init()
+
+
+def format_simplified(import_line: str) -> str:
+ import_line = import_line.strip()
+ if import_line.startswith("from "):
+ import_line = import_line.replace("from ", "")
+ import_line = import_line.replace(" import ", ".")
+ elif import_line.startswith("import "):
+ import_line = import_line.replace("import ", "")
+
+ return import_line
+
+
+def format_natural(import_line: str) -> str:
+ import_line = import_line.strip()
+ if not import_line.startswith("from ") and not import_line.startswith("import "):
+ if "." not in import_line:
+ return f"import {import_line}"
+ parts = import_line.split(".")
+ end = parts.pop(-1)
+ return f"from {'.'.join(parts)} import {end}"
+
+ return import_line
+
+
+def show_unified_diff(
+ *, file_input: str, file_output: str, file_path: Optional[Path], output: Optional[TextIO] = None
+):
+ """Shows a unified_diff for the provided input and output against the provided file path.
+
+ - **file_input**: A string that represents the contents of a file before changes.
+ - **file_output**: A string that represents the contents of a file after changes.
+ - **file_path**: A Path object that represents the file path of the file being changed.
+ - **output**: A stream to output the diff to. If non is provided uses sys.stdout.
+ """
+ output = sys.stdout if output is None else output
+ file_name = "" if file_path is None else str(file_path)
+ file_mtime = str(
+ datetime.now() if file_path is None else datetime.fromtimestamp(file_path.stat().st_mtime)
+ )
+ unified_diff_lines = unified_diff(
+ file_input.splitlines(keepends=True),
+ file_output.splitlines(keepends=True),
+ fromfile=file_name + ":before",
+ tofile=file_name + ":after",
+ fromfiledate=file_mtime,
+ tofiledate=str(datetime.now()),
+ )
+ for line in unified_diff_lines:
+ output.write(line)
+
+
+def ask_whether_to_apply_changes_to_file(file_path: str) -> bool:
+ answer = None
+ while answer not in ("yes", "y", "no", "n", "quit", "q"):
+ answer = input(f"Apply suggested changes to '{file_path}' [y/n/q]? ") # nosec
+ answer = answer.lower()
+ if answer in ("no", "n"):
+ return False
+ if answer in ("quit", "q"):
+ sys.exit(1)
+ return True
+
+
+def remove_whitespace(content: str, line_separator: str = "\n") -> str:
+ content = content.replace(line_separator, "").replace(" ", "").replace("\x0c", "")
+ return content
+
+
+class BasicPrinter:
+ ERROR = "ERROR"
+ SUCCESS = "SUCCESS"
+
+ def success(self, message: str) -> None:
+ print(f"{self.SUCCESS}: {message}")
+
+ def error(self, message: str) -> None:
+ print(
+ f"{self.ERROR}: {message}",
+ # TODO this should print to stderr, but don't want to make it backward incompatible now
+ # file=sys.stderr
+ )
+
+
+class ColoramaPrinter(BasicPrinter):
+ def __init__(self):
+ self.ERROR = self.style_text("ERROR", colorama.Fore.RED)
+ self.SUCCESS = self.style_text("SUCCESS", colorama.Fore.GREEN)
+
+ @staticmethod
+ def style_text(text: str, style: str) -> str:
+ return style + text + colorama.Style.RESET_ALL
+
+
+def create_terminal_printer(color: bool):
+ if color and colorama_unavailable:
+ no_colorama_message = (
+ "\n"
+ "Sorry, but to use --color (color_output) the colorama python package is required.\n\n"
+ "Reference: https://pypi.org/project/colorama/\n\n"
+ "You can either install it separately on your system or as the colors extra "
+ "for isort. Ex: \n\n"
+ "$ pip install isort[colors]\n"
+ )
+ print(no_colorama_message, file=sys.stderr)
+ sys.exit(1)
+
+ return ColoramaPrinter() if color else BasicPrinter()
diff --git a/venv/Lib/site-packages/isort/hooks.py b/venv/Lib/site-packages/isort/hooks.py
new file mode 100644
index 0000000..3198a1d
--- /dev/null
+++ b/venv/Lib/site-packages/isort/hooks.py
@@ -0,0 +1,80 @@
+"""Defines a git hook to allow pre-commit warnings and errors about import order.
+
+usage:
+ exit_code = git_hook(strict=True|False, modify=True|False)
+"""
+import os
+import subprocess # nosec - Needed for hook
+from pathlib import Path
+from typing import List
+
+from isort import Config, api, exceptions
+
+
+def get_output(command: List[str]) -> str:
+ """
+ Run a command and return raw output
+
+ :param str command: the command to run
+ :returns: the stdout output of the command
+ """
+ result = subprocess.run(command, stdout=subprocess.PIPE, check=True) # nosec - trusted input
+ return result.stdout.decode()
+
+
+def get_lines(command: List[str]) -> List[str]:
+ """
+ Run a command and return lines of output
+
+ :param str command: the command to run
+ :returns: list of whitespace-stripped lines output by command
+ """
+ stdout = get_output(command)
+ return [line.strip() for line in stdout.splitlines()]
+
+
+def git_hook(strict: bool = False, modify: bool = False, lazy: bool = False) -> int:
+ """
+ Git pre-commit hook to check staged files for isort errors
+
+ :param bool strict - if True, return number of errors on exit,
+ causing the hook to fail. If False, return zero so it will
+ just act as a warning.
+ :param bool modify - if True, fix the sources if they are not
+ sorted properly. If False, only report result without
+ modifying anything.
+ :param bool lazy - if True, also check/fix unstaged files.
+ This is useful if you frequently use ``git commit -a`` for example.
+ If False, ony check/fix the staged files for isort errors.
+
+ :return number of errors if in strict mode, 0 otherwise.
+ """
+
+ # Get list of files modified and staged
+ diff_cmd = ["git", "diff-index", "--cached", "--name-only", "--diff-filter=ACMRTUXB", "HEAD"]
+ if lazy:
+ diff_cmd.remove("--cached")
+
+ files_modified = get_lines(diff_cmd)
+ if not files_modified:
+ return 0
+
+ errors = 0
+ config = Config(settings_path=os.path.dirname(os.path.abspath(files_modified[0])))
+ for filename in files_modified:
+ if filename.endswith(".py"):
+ # Get the staged contents of the file
+ staged_cmd = ["git", "show", f":{filename}"]
+ staged_contents = get_output(staged_cmd)
+
+ try:
+ if not api.check_code_string(
+ staged_contents, file_path=Path(filename), config=config
+ ):
+ errors += 1
+ if modify:
+ api.sort_file(filename, config=config)
+ except exceptions.FileSkipped: # pragma: no cover
+ pass
+
+ return errors if strict else 0
diff --git a/venv/Lib/site-packages/isort/io.py b/venv/Lib/site-packages/isort/io.py
new file mode 100644
index 0000000..a035734
--- /dev/null
+++ b/venv/Lib/site-packages/isort/io.py
@@ -0,0 +1,60 @@
+"""Defines any IO utilities used by isort"""
+import re
+import tokenize
+from contextlib import contextmanager
+from io import BytesIO, StringIO, TextIOWrapper
+from pathlib import Path
+from typing import Iterator, NamedTuple, TextIO, Union
+
+_ENCODING_PATTERN = re.compile(br"^[ \t\f]*#.*?coding[:=][ \t]*([-_.a-zA-Z0-9]+)")
+
+
+class File(NamedTuple):
+ stream: TextIO
+ path: Path
+ encoding: str
+
+ @staticmethod
+ def from_contents(contents: str, filename: str) -> "File":
+ encoding, _ = tokenize.detect_encoding(BytesIO(contents.encode("utf-8")).readline)
+ return File(StringIO(contents), path=Path(filename).resolve(), encoding=encoding)
+
+ @property
+ def extension(self):
+ return self.path.suffix.lstrip(".")
+
+ @staticmethod
+ def _open(filename):
+ """Open a file in read only mode using the encoding detected by
+ detect_encoding().
+ """
+ buffer = open(filename, "rb")
+ try:
+ encoding, _ = tokenize.detect_encoding(buffer.readline)
+ buffer.seek(0)
+ text = TextIOWrapper(buffer, encoding, line_buffering=True, newline="")
+ text.mode = "r" # type: ignore
+ return text
+ except Exception:
+ buffer.close()
+ raise
+
+ @staticmethod
+ @contextmanager
+ def read(filename: Union[str, Path]) -> Iterator["File"]:
+ file_path = Path(filename).resolve()
+ stream = None
+ try:
+ stream = File._open(file_path)
+ yield File(stream=stream, path=file_path, encoding=stream.encoding)
+ finally:
+ if stream is not None:
+ stream.close()
+
+
+class _EmptyIO(StringIO):
+ def write(self, *args, **kwargs):
+ pass
+
+
+Empty = _EmptyIO()
diff --git a/venv/Lib/site-packages/isort/literal.py b/venv/Lib/site-packages/isort/literal.py
new file mode 100644
index 0000000..28e0855
--- /dev/null
+++ b/venv/Lib/site-packages/isort/literal.py
@@ -0,0 +1,108 @@
+import ast
+from pprint import PrettyPrinter
+from typing import Any, Callable, Dict, List, Set, Tuple
+
+from isort.exceptions import (
+ AssignmentsFormatMismatch,
+ LiteralParsingFailure,
+ LiteralSortTypeMismatch,
+)
+from isort.settings import DEFAULT_CONFIG, Config
+
+
+class ISortPrettyPrinter(PrettyPrinter):
+ """an isort customized pretty printer for sorted literals"""
+
+ def __init__(self, config: Config):
+ super().__init__(width=config.line_length, compact=True)
+
+
+type_mapping: Dict[str, Tuple[type, Callable[[Any, ISortPrettyPrinter], str]]] = {}
+
+
+def assignments(code: str) -> str:
+ sort_assignments = {}
+ for line in code.splitlines(keepends=True):
+ if line:
+ if " = " not in line:
+ raise AssignmentsFormatMismatch(code)
+ else:
+ variable_name, value = line.split(" = ", 1)
+ sort_assignments[variable_name] = value
+
+ sorted_assignments = dict(sorted(sort_assignments.items(), key=lambda item: item[1]))
+ return "".join(f"{key} = {value}" for key, value in sorted_assignments.items())
+
+
+def assignment(code: str, sort_type: str, extension: str, config: Config = DEFAULT_CONFIG) -> str:
+ """Sorts the literal present within the provided code against the provided sort type,
+ returning the sorted representation of the source code.
+ """
+ if sort_type == "assignments":
+ return assignments(code)
+ elif sort_type not in type_mapping:
+ raise ValueError(
+ "Trying to sort using an undefined sort_type. "
+ f"Defined sort types are {', '.join(type_mapping.keys())}."
+ )
+
+ variable_name, literal = code.split(" = ")
+ variable_name = variable_name.lstrip()
+ try:
+ value = ast.literal_eval(literal)
+ except Exception as error:
+ raise LiteralParsingFailure(code, error)
+
+ expected_type, sort_function = type_mapping[sort_type]
+ if type(value) != expected_type:
+ raise LiteralSortTypeMismatch(type(value), expected_type)
+
+ printer = ISortPrettyPrinter(config)
+ sorted_value_code = f"{variable_name} = {sort_function(value, printer)}"
+ if config.formatting_function:
+ sorted_value_code = config.formatting_function(
+ sorted_value_code, extension, config
+ ).rstrip()
+
+ sorted_value_code += code[len(code.rstrip()) :]
+ return sorted_value_code
+
+
+def register_type(name: str, kind: type):
+ """Registers a new literal sort type."""
+
+ def wrap(function):
+ type_mapping[name] = (kind, function)
+ return function
+
+ return wrap
+
+
+@register_type("dict", dict)
+def _dict(value: Dict[Any, Any], printer: ISortPrettyPrinter) -> str:
+ return printer.pformat(dict(sorted(value.items(), key=lambda item: item[1])))
+
+
+@register_type("list", list)
+def _list(value: List[Any], printer: ISortPrettyPrinter) -> str:
+ return printer.pformat(sorted(value))
+
+
+@register_type("unique-list", list)
+def _unique_list(value: List[Any], printer: ISortPrettyPrinter) -> str:
+ return printer.pformat(list(sorted(set(value))))
+
+
+@register_type("set", set)
+def _set(value: Set[Any], printer: ISortPrettyPrinter) -> str:
+ return "{" + printer.pformat(tuple(sorted(value)))[1:-1] + "}"
+
+
+@register_type("tuple", tuple)
+def _tuple(value: Tuple[Any, ...], printer: ISortPrettyPrinter) -> str:
+ return printer.pformat(tuple(sorted(value)))
+
+
+@register_type("unique-tuple", tuple)
+def _unique_tuple(value: Tuple[Any, ...], printer: ISortPrettyPrinter) -> str:
+ return printer.pformat(tuple(sorted(set(value))))
diff --git a/venv/Lib/site-packages/isort/logo.py b/venv/Lib/site-packages/isort/logo.py
new file mode 100644
index 0000000..6377d86
--- /dev/null
+++ b/venv/Lib/site-packages/isort/logo.py
@@ -0,0 +1,19 @@
+from ._version import __version__
+
+ASCII_ART = rf"""
+ _ _
+ (_) ___ ___ _ __| |_
+ | |/ _/ / _ \/ '__ _/
+ | |\__ \/\_\/| | | |_
+ |_|\___/\___/\_/ \_/
+
+ isort your imports, so you don't have to.
+
+ VERSION {__version__}
+"""
+
+__doc__ = f"""
+```python
+{ASCII_ART}
+```
+"""
diff --git a/venv/Lib/site-packages/isort/main.py b/venv/Lib/site-packages/isort/main.py
new file mode 100644
index 0000000..58c4e10
--- /dev/null
+++ b/venv/Lib/site-packages/isort/main.py
@@ -0,0 +1,920 @@
+"""Tool for sorting imports alphabetically, and automatically separated into sections."""
+import argparse
+import functools
+import json
+import os
+import sys
+from io import TextIOWrapper
+from pathlib import Path
+from typing import Any, Dict, Iterable, Iterator, List, Optional, Sequence, Set
+from warnings import warn
+
+from . import __version__, api, sections
+from .exceptions import FileSkipped
+from .logo import ASCII_ART
+from .profiles import profiles
+from .settings import VALID_PY_TARGETS, Config, WrapModes
+
+try:
+ from .setuptools_commands import ISortCommand # noqa: F401
+except ImportError:
+ pass
+
+DEPRECATED_SINGLE_DASH_ARGS = {
+ "-ac",
+ "-af",
+ "-ca",
+ "-cs",
+ "-df",
+ "-ds",
+ "-dt",
+ "-fas",
+ "-fass",
+ "-ff",
+ "-fgw",
+ "-fss",
+ "-lai",
+ "-lbt",
+ "-le",
+ "-ls",
+ "-nis",
+ "-nlb",
+ "-ot",
+ "-rr",
+ "-sd",
+ "-sg",
+ "-sl",
+ "-sp",
+ "-tc",
+ "-wl",
+ "-ws",
+}
+QUICK_GUIDE = f"""
+{ASCII_ART}
+
+Nothing to do: no files or paths have have been passed in!
+
+Try one of the following:
+
+ `isort .` - sort all Python files, starting from the current directory, recursively.
+ `isort . --interactive` - Do the same, but ask before making any changes.
+ `isort . --check --diff` - Check to see if imports are correctly sorted within this project.
+ `isort --help` - In-depth information about isort's available command-line options.
+
+Visit https://timothycrosley.github.io/isort/ for complete information about how to use isort.
+"""
+
+
+class SortAttempt:
+ def __init__(self, incorrectly_sorted: bool, skipped: bool) -> None:
+ self.incorrectly_sorted = incorrectly_sorted
+ self.skipped = skipped
+
+
+def sort_imports(
+ file_name: str,
+ config: Config,
+ check: bool = False,
+ ask_to_apply: bool = False,
+ write_to_stdout: bool = False,
+ **kwargs: Any,
+) -> Optional[SortAttempt]:
+ try:
+ incorrectly_sorted: bool = False
+ skipped: bool = False
+ if check:
+ try:
+ incorrectly_sorted = not api.check_file(file_name, config=config, **kwargs)
+ except FileSkipped:
+ skipped = True
+ return SortAttempt(incorrectly_sorted, skipped)
+ else:
+ try:
+ incorrectly_sorted = not api.sort_file(
+ file_name,
+ config=config,
+ ask_to_apply=ask_to_apply,
+ write_to_stdout=write_to_stdout,
+ **kwargs,
+ )
+ except FileSkipped:
+ skipped = True
+ return SortAttempt(incorrectly_sorted, skipped)
+ except (OSError, ValueError) as error:
+ warn(f"Unable to parse file {file_name} due to {error}")
+ return None
+
+
+def iter_source_code(paths: Iterable[str], config: Config, skipped: List[str]) -> Iterator[str]:
+ """Iterate over all Python source files defined in paths."""
+ visited_dirs: Set[Path] = set()
+
+ for path in paths:
+ if os.path.isdir(path):
+ for dirpath, dirnames, filenames in os.walk(path, topdown=True, followlinks=True):
+ base_path = Path(dirpath)
+ for dirname in list(dirnames):
+ full_path = base_path / dirname
+ if config.is_skipped(full_path):
+ skipped.append(dirname)
+ dirnames.remove(dirname)
+
+ resolved_path = full_path.resolve()
+ if resolved_path in visited_dirs: # pragma: no cover
+ if not config.quiet:
+ warn(f"Likely recursive symlink detected to {resolved_path}")
+ dirnames.remove(dirname)
+ else:
+ visited_dirs.add(resolved_path)
+
+ for filename in filenames:
+ filepath = os.path.join(dirpath, filename)
+ if config.is_supported_filetype(filepath):
+ if config.is_skipped(Path(filepath)):
+ skipped.append(filename)
+ else:
+ yield filepath
+ else:
+ yield path
+
+
+def _build_arg_parser() -> argparse.ArgumentParser:
+ parser = argparse.ArgumentParser(
+ description="Sort Python import definitions alphabetically "
+ "within logical sections. Run with no arguments to see a quick "
+ "start guide, otherwise, one or more files/directories/stdin must be provided. "
+ "Use `-` as the first argument to represent stdin. Use --interactive to use the pre 5.0.0 "
+ "interactive behavior."
+ ""
+ "If you've used isort 4 but are new to isort 5, see the upgrading guide:"
+ "https://timothycrosley.github.io/isort/docs/upgrade_guides/5.0.0/."
+ )
+ inline_args_group = parser.add_mutually_exclusive_group()
+ parser.add_argument(
+ "--src",
+ "--src-path",
+ dest="src_paths",
+ action="append",
+ help="Add an explicitly defined source path "
+ "(modules within src paths have their imports automatically catorgorized as first_party).",
+ )
+ parser.add_argument(
+ "-a",
+ "--add-import",
+ dest="add_imports",
+ action="append",
+ help="Adds the specified import line to all files, "
+ "automatically determining correct placement.",
+ )
+ parser.add_argument(
+ "--append",
+ "--append-only",
+ dest="append_only",
+ action="store_true",
+ help="Only adds the imports specified in --add-imports if the file"
+ " contains existing imports.",
+ )
+ parser.add_argument(
+ "--ac",
+ "--atomic",
+ dest="atomic",
+ action="store_true",
+ help="Ensures the output doesn't save if the resulting file contains syntax errors.",
+ )
+ parser.add_argument(
+ "--af",
+ "--force-adds",
+ dest="force_adds",
+ action="store_true",
+ help="Forces import adds even if the original file is empty.",
+ )
+ parser.add_argument(
+ "-b",
+ "--builtin",
+ dest="known_standard_library",
+ action="append",
+ help="Force isort to recognize a module as part of Python's standard library.",
+ )
+ parser.add_argument(
+ "--extra-builtin",
+ dest="extra_standard_library",
+ action="append",
+ help="Extra modules to be included in the list of ones in Python's standard library.",
+ )
+ parser.add_argument(
+ "-c",
+ "--check-only",
+ "--check",
+ action="store_true",
+ dest="check",
+ help="Checks the file for unsorted / unformatted imports and prints them to the "
+ "command line without modifying the file.",
+ )
+ parser.add_argument(
+ "--ca",
+ "--combine-as",
+ dest="combine_as_imports",
+ action="store_true",
+ help="Combines as imports on the same line.",
+ )
+ parser.add_argument(
+ "--cs",
+ "--combine-star",
+ dest="combine_star",
+ action="store_true",
+ help="Ensures that if a star import is present, "
+ "nothing else is imported from that namespace.",
+ )
+ parser.add_argument(
+ "-d",
+ "--stdout",
+ help="Force resulting output to stdout, instead of in-place.",
+ dest="write_to_stdout",
+ action="store_true",
+ )
+ parser.add_argument(
+ "--df",
+ "--diff",
+ dest="show_diff",
+ action="store_true",
+ help="Prints a diff of all the changes isort would make to a file, instead of "
+ "changing it in place",
+ )
+ parser.add_argument(
+ "--ds",
+ "--no-sections",
+ help="Put all imports into the same section bucket",
+ dest="no_sections",
+ action="store_true",
+ )
+ parser.add_argument(
+ "-e",
+ "--balanced",
+ dest="balanced_wrapping",
+ action="store_true",
+ help="Balances wrapping to produce the most consistent line length possible",
+ )
+ parser.add_argument(
+ "-f",
+ "--future",
+ dest="known_future_library",
+ action="append",
+ help="Force isort to recognize a module as part of the future compatibility libraries.",
+ )
+ parser.add_argument(
+ "--fas",
+ "--force-alphabetical-sort",
+ action="store_true",
+ dest="force_alphabetical_sort",
+ help="Force all imports to be sorted as a single section",
+ )
+ parser.add_argument(
+ "--fass",
+ "--force-alphabetical-sort-within-sections",
+ action="store_true",
+ dest="force_alphabetical_sort_within_sections",
+ help="Force all imports to be sorted alphabetically within a section",
+ )
+ parser.add_argument(
+ "--ff",
+ "--from-first",
+ dest="from_first",
+ help="Switches the typical ordering preference, "
+ "showing from imports first then straight ones.",
+ )
+ parser.add_argument(
+ "--fgw",
+ "--force-grid-wrap",
+ nargs="?",
+ const=2,
+ type=int,
+ dest="force_grid_wrap",
+ help="Force number of from imports (defaults to 2) to be grid wrapped regardless of line "
+ "length",
+ )
+ parser.add_argument(
+ "--fss",
+ "--force-sort-within-sections",
+ action="store_true",
+ dest="force_sort_within_sections",
+ help="Don't sort straight-style imports (like import sys) before from-style imports "
+ "(like from itertools import groupby). Instead, sort the imports by module, "
+ "independent of import style.",
+ )
+ parser.add_argument(
+ "-i",
+ "--indent",
+ help='String to place for indents defaults to " " (4 spaces).',
+ dest="indent",
+ type=str,
+ )
+ parser.add_argument(
+ "-j", "--jobs", help="Number of files to process in parallel.", dest="jobs", type=int
+ )
+ parser.add_argument("--lai", "--lines-after-imports", dest="lines_after_imports", type=int)
+ parser.add_argument("--lbt", "--lines-between-types", dest="lines_between_types", type=int)
+ parser.add_argument(
+ "--le",
+ "--line-ending",
+ dest="line_ending",
+ help="Forces line endings to the specified value. "
+ "If not set, values will be guessed per-file.",
+ )
+ parser.add_argument(
+ "--ls",
+ "--length-sort",
+ help="Sort imports by their string length.",
+ dest="length_sort",
+ action="store_true",
+ )
+ parser.add_argument(
+ "--lss",
+ "--length-sort-straight",
+ help="Sort straight imports by their string length.",
+ dest="length_sort_straight",
+ action="store_true",
+ )
+ parser.add_argument(
+ "-m",
+ "--multi-line",
+ dest="multi_line_output",
+ choices=list(WrapModes.__members__.keys())
+ + [str(mode.value) for mode in WrapModes.__members__.values()],
+ type=str,
+ help="Multi line output (0-grid, 1-vertical, 2-hanging, 3-vert-hanging, 4-vert-grid, "
+ "5-vert-grid-grouped, 6-vert-grid-grouped-no-comma, 7-noqa, "
+ "8-vertical-hanging-indent-bracket, 9-vertical-prefix-from-module-import, "
+ "10-hanging-indent-with-parentheses).",
+ )
+ parser.add_argument(
+ "-n",
+ "--ensure-newline-before-comments",
+ dest="ensure_newline_before_comments",
+ action="store_true",
+ help="Inserts a blank line before a comment following an import.",
+ )
+ inline_args_group.add_argument(
+ "--nis",
+ "--no-inline-sort",
+ dest="no_inline_sort",
+ action="store_true",
+ help="Leaves `from` imports with multiple imports 'as-is' "
+ "(e.g. `from foo import a, c ,b`).",
+ )
+ parser.add_argument(
+ "--nlb",
+ "--no-lines-before",
+ help="Sections which should not be split with previous by empty lines",
+ dest="no_lines_before",
+ action="append",
+ )
+ parser.add_argument(
+ "-o",
+ "--thirdparty",
+ dest="known_third_party",
+ action="append",
+ help="Force isort to recognize a module as being part of a third party library.",
+ )
+ parser.add_argument(
+ "--ot",
+ "--order-by-type",
+ dest="order_by_type",
+ action="store_true",
+ help="Order imports by type, which is determined by case, in addition to alphabetically.\n"
+ "\n**NOTE**: type here refers to the implied type from the import name capitalization.\n"
+ ' isort does not do type introspection for the imports. These "types" are simply: '
+ "CONSTANT_VARIABLE, CamelCaseClass, variable_or_function. If your project follows PEP8"
+ " or a related coding standard and has many imports this is a good default, otherwise you "
+ "likely will want to turn it off. From the CLI the `--dont-order-by-type` option will turn "
+ "this off.",
+ )
+ parser.add_argument(
+ "--dt",
+ "--dont-order-by-type",
+ dest="dont_order_by_type",
+ action="store_true",
+ help="Don't order imports by type, which is determined by case, in addition to "
+ "alphabetically.\n\n"
+ "**NOTE**: type here refers to the implied type from the import name capitalization.\n"
+ ' isort does not do type introspection for the imports. These "types" are simply: '
+ "CONSTANT_VARIABLE, CamelCaseClass, variable_or_function. If your project follows PEP8"
+ " or a related coding standard and has many imports this is a good default. You can turn "
+ "this on from the CLI using `--order-by-type`.",
+ )
+ parser.add_argument(
+ "-p",
+ "--project",
+ dest="known_first_party",
+ action="append",
+ help="Force isort to recognize a module as being part of the current python project.",
+ )
+ parser.add_argument(
+ "--known-local-folder",
+ dest="known_local_folder",
+ action="append",
+ help="Force isort to recognize a module as being a local folder. "
+ "Generally, this is reserved for relative imports (from . import module).",
+ )
+ parser.add_argument(
+ "-q",
+ "--quiet",
+ action="store_true",
+ dest="quiet",
+ help="Shows extra quiet output, only errors are outputted.",
+ )
+ parser.add_argument(
+ "--rm",
+ "--remove-import",
+ dest="remove_imports",
+ action="append",
+ help="Removes the specified import from all files.",
+ )
+ parser.add_argument(
+ "--rr",
+ "--reverse-relative",
+ dest="reverse_relative",
+ action="store_true",
+ help="Reverse order of relative imports.",
+ )
+ parser.add_argument(
+ "-s",
+ "--skip",
+ help="Files that sort imports should skip over. If you want to skip multiple "
+ "files you should specify twice: --skip file1 --skip file2.",
+ dest="skip",
+ action="append",
+ )
+ parser.add_argument(
+ "--sd",
+ "--section-default",
+ dest="default_section",
+ help="Sets the default section for import options: " + str(sections.DEFAULT),
+ )
+ parser.add_argument(
+ "--sg",
+ "--skip-glob",
+ help="Files that sort imports should skip over.",
+ dest="skip_glob",
+ action="append",
+ )
+ parser.add_argument(
+ "--gitignore",
+ "--skip-gitignore",
+ action="store_true",
+ dest="skip_gitignore",
+ help="Treat project as a git repository and ignore files listed in .gitignore",
+ )
+ inline_args_group.add_argument(
+ "--sl",
+ "--force-single-line-imports",
+ dest="force_single_line",
+ action="store_true",
+ help="Forces all from imports to appear on their own line",
+ )
+ parser.add_argument(
+ "--nsl",
+ "--single-line-exclusions",
+ help="One or more modules to exclude from the single line rule.",
+ dest="single_line_exclusions",
+ action="append",
+ )
+ parser.add_argument(
+ "--sp",
+ "--settings-path",
+ "--settings-file",
+ "--settings",
+ dest="settings_path",
+ help="Explicitly set the settings path or file instead of auto determining "
+ "based on file location.",
+ )
+ parser.add_argument(
+ "-t",
+ "--top",
+ help="Force specific imports to the top of their appropriate section.",
+ dest="force_to_top",
+ action="append",
+ )
+ parser.add_argument(
+ "--tc",
+ "--trailing-comma",
+ dest="include_trailing_comma",
+ action="store_true",
+ help="Includes a trailing comma on multi line imports that include parentheses.",
+ )
+ parser.add_argument(
+ "--up",
+ "--use-parentheses",
+ dest="use_parentheses",
+ action="store_true",
+ help="Use parentheses for line continuation on length limit instead of slashes."
+ " **NOTE**: This is separate from wrap modes, and only affects how individual lines that "
+ " are too long get continued, not sections of multiple imports.",
+ )
+ parser.add_argument(
+ "-V",
+ "--version",
+ action="store_true",
+ dest="show_version",
+ help="Displays the currently installed version of isort.",
+ )
+ parser.add_argument(
+ "-v",
+ "--verbose",
+ action="store_true",
+ dest="verbose",
+ help="Shows verbose output, such as when files are skipped or when a check is successful.",
+ )
+ parser.add_argument(
+ "--virtual-env",
+ dest="virtual_env",
+ help="Virtual environment to use for determining whether a package is third-party",
+ )
+ parser.add_argument(
+ "--conda-env",
+ dest="conda_env",
+ help="Conda environment to use for determining whether a package is third-party",
+ )
+ parser.add_argument(
+ "--vn",
+ "--version-number",
+ action="version",
+ version=__version__,
+ help="Returns just the current version number without the logo",
+ )
+ parser.add_argument(
+ "-l",
+ "-w",
+ "--line-length",
+ "--line-width",
+ help="The max length of an import line (used for wrapping long imports).",
+ dest="line_length",
+ type=int,
+ )
+ parser.add_argument(
+ "--wl",
+ "--wrap-length",
+ dest="wrap_length",
+ type=int,
+ help="Specifies how long lines that are wrapped should be, if not set line_length is used."
+ "\nNOTE: wrap_length must be LOWER than or equal to line_length.",
+ )
+ parser.add_argument(
+ "--ws",
+ "--ignore-whitespace",
+ action="store_true",
+ dest="ignore_whitespace",
+ help="Tells isort to ignore whitespace differences when --check-only is being used.",
+ )
+ parser.add_argument(
+ "--case-sensitive",
+ dest="case_sensitive",
+ action="store_true",
+ help="Tells isort to include casing when sorting module names",
+ )
+ parser.add_argument(
+ "--filter-files",
+ dest="filter_files",
+ action="store_true",
+ help="Tells isort to filter files even when they are explicitly passed in as "
+ "part of the CLI command.",
+ )
+ parser.add_argument(
+ "files", nargs="*", help="One or more Python source files that need their imports sorted."
+ )
+ parser.add_argument(
+ "--py",
+ "--python-version",
+ action="store",
+ dest="py_version",
+ choices=tuple(VALID_PY_TARGETS) + ("auto",),
+ help="Tells isort to set the known standard library based on the the specified Python "
+ "version. Default is to assume any Python 3 version could be the target, and use a union "
+ "off all stdlib modules across versions. If auto is specified, the version of the "
+ "interpreter used to run isort "
+ f"(currently: {sys.version_info.major}{sys.version_info.minor}) will be used.",
+ )
+ parser.add_argument(
+ "--profile",
+ dest="profile",
+ type=str,
+ help="Base profile type to use for configuration. "
+ f"Profiles include: {', '.join(profiles.keys())}. As well as any shared profiles.",
+ )
+ parser.add_argument(
+ "--interactive",
+ dest="ask_to_apply",
+ action="store_true",
+ help="Tells isort to apply changes interactively.",
+ )
+ parser.add_argument(
+ "--old-finders",
+ "--magic-placement",
+ dest="old_finders",
+ action="store_true",
+ help="Use the old deprecated finder logic that relies on environment introspection magic.",
+ )
+ parser.add_argument(
+ "--show-config",
+ dest="show_config",
+ action="store_true",
+ help="See isort's determined config, as well as sources of config options.",
+ )
+ parser.add_argument(
+ "--honor-noqa",
+ dest="honor_noqa",
+ action="store_true",
+ help="Tells isort to honor noqa comments to enforce skipping those comments.",
+ )
+ parser.add_argument(
+ "--remove-redundant-aliases",
+ dest="remove_redundant_aliases",
+ action="store_true",
+ help=(
+ "Tells isort to remove redundant aliases from imports, such as `import os as os`."
+ " This defaults to `False` simply because some projects use these seemingly useless "
+ " aliases to signify intent and change behaviour."
+ ),
+ )
+ parser.add_argument(
+ "--color",
+ dest="color_output",
+ action="store_true",
+ help="Tells isort to use color in terminal output.",
+ )
+ parser.add_argument(
+ "--float-to-top",
+ dest="float_to_top",
+ action="store_true",
+ help="Causes all non-indented imports to float to the top of the file having its imports "
+ "sorted. It can be an excellent shortcut for collecting imports every once in a while "
+ "when you place them in the middle of a file to avoid context switching.\n\n"
+ "*NOTE*: It currently doesn't work with cimports and introduces some extra over-head "
+ "and a performance penalty.",
+ )
+ parser.add_argument(
+ "--treat-comment-as-code",
+ dest="treat_comments_as_code",
+ action="append",
+ help="Tells isort to treat the specified single line comment(s) as if they are code.",
+ )
+ parser.add_argument(
+ "--treat-all-comment-as-code",
+ dest="treat_all_comments_as_code",
+ action="store_true",
+ help="Tells isort to treat all single line comments as if they are code.",
+ )
+ parser.add_argument(
+ "--formatter",
+ dest="formatter",
+ type=str,
+ help="Specifies the name of a formatting plugin to use when producing output.",
+ )
+ parser.add_argument(
+ "--ext",
+ "--extension",
+ "--supported-extension",
+ dest="supported_extensions",
+ action="append",
+ help="Specifies what extensions isort can be ran against.",
+ )
+ parser.add_argument(
+ "--blocked-extension",
+ dest="blocked_extensions",
+ action="append",
+ help="Specifies what extensions isort can never be ran against.",
+ )
+ parser.add_argument(
+ "--dedup-headings",
+ dest="dedup_headings",
+ action="store_true",
+ help="Tells isort to only show an identical custom import heading comment once, even if"
+ " there are multiple sections with the comment set.",
+ )
+
+ # deprecated options
+ parser.add_argument(
+ "--recursive",
+ dest="deprecated_flags",
+ action="append_const",
+ const="--recursive",
+ help=argparse.SUPPRESS,
+ )
+ parser.add_argument(
+ "-rc", dest="deprecated_flags", action="append_const", const="-rc", help=argparse.SUPPRESS
+ )
+ parser.add_argument(
+ "--dont-skip",
+ dest="deprecated_flags",
+ action="append_const",
+ const="--dont-skip",
+ help=argparse.SUPPRESS,
+ )
+ parser.add_argument(
+ "-ns", dest="deprecated_flags", action="append_const", const="-ns", help=argparse.SUPPRESS
+ )
+ parser.add_argument(
+ "--apply",
+ dest="deprecated_flags",
+ action="append_const",
+ const="--apply",
+ help=argparse.SUPPRESS,
+ )
+ parser.add_argument(
+ "-k",
+ "--keep-direct-and-as",
+ dest="deprecated_flags",
+ action="append_const",
+ const="--keep-direct-and-as",
+ help=argparse.SUPPRESS,
+ )
+
+ return parser
+
+
+def parse_args(argv: Optional[Sequence[str]] = None) -> Dict[str, Any]:
+ argv = sys.argv[1:] if argv is None else list(argv)
+ remapped_deprecated_args = []
+ for index, arg in enumerate(argv):
+ if arg in DEPRECATED_SINGLE_DASH_ARGS:
+ remapped_deprecated_args.append(arg)
+ argv[index] = f"-{arg}"
+
+ parser = _build_arg_parser()
+ arguments = {key: value for key, value in vars(parser.parse_args(argv)).items() if value}
+ if remapped_deprecated_args:
+ arguments["remapped_deprecated_args"] = remapped_deprecated_args
+ if "dont_order_by_type" in arguments:
+ arguments["order_by_type"] = False
+ del arguments["dont_order_by_type"]
+ multi_line_output = arguments.get("multi_line_output", None)
+ if multi_line_output:
+ if multi_line_output.isdigit():
+ arguments["multi_line_output"] = WrapModes(int(multi_line_output))
+ else:
+ arguments["multi_line_output"] = WrapModes[multi_line_output]
+ return arguments
+
+
+def _preconvert(item):
+ """Preconverts objects from native types into JSONifyiable types"""
+ if isinstance(item, (set, frozenset)):
+ return list(item)
+ elif isinstance(item, WrapModes):
+ return item.name
+ elif isinstance(item, Path):
+ return str(item)
+ elif callable(item) and hasattr(item, "__name__"):
+ return item.__name__
+ else:
+ raise TypeError("Unserializable object {} of type {}".format(item, type(item)))
+
+
+def main(argv: Optional[Sequence[str]] = None, stdin: Optional[TextIOWrapper] = None) -> None:
+ arguments = parse_args(argv)
+ if arguments.get("show_version"):
+ print(ASCII_ART)
+ return
+
+ show_config: bool = arguments.pop("show_config", False)
+
+ if "settings_path" in arguments:
+ if os.path.isfile(arguments["settings_path"]):
+ arguments["settings_file"] = os.path.abspath(arguments["settings_path"])
+ arguments["settings_path"] = os.path.dirname(arguments["settings_file"])
+ else:
+ arguments["settings_path"] = os.path.abspath(arguments["settings_path"])
+
+ if "virtual_env" in arguments:
+ venv = arguments["virtual_env"]
+ arguments["virtual_env"] = os.path.abspath(venv)
+ if not os.path.isdir(arguments["virtual_env"]):
+ warn(f"virtual_env dir does not exist: {arguments['virtual_env']}")
+
+ file_names = arguments.pop("files", [])
+ if not file_names and not show_config:
+ print(QUICK_GUIDE)
+ if arguments:
+ sys.exit("Error: arguments passed in without any paths or content.")
+ else:
+ return
+ if "settings_path" not in arguments:
+ arguments["settings_path"] = (
+ os.path.abspath(file_names[0] if file_names else ".") or os.getcwd()
+ )
+ if not os.path.isdir(arguments["settings_path"]):
+ arguments["settings_path"] = os.path.dirname(arguments["settings_path"])
+
+ config_dict = arguments.copy()
+ ask_to_apply = config_dict.pop("ask_to_apply", False)
+ jobs = config_dict.pop("jobs", ())
+ check = config_dict.pop("check", False)
+ show_diff = config_dict.pop("show_diff", False)
+ write_to_stdout = config_dict.pop("write_to_stdout", False)
+ deprecated_flags = config_dict.pop("deprecated_flags", False)
+ remapped_deprecated_args = config_dict.pop("remapped_deprecated_args", False)
+ wrong_sorted_files = False
+
+ if "src_paths" in config_dict:
+ config_dict["src_paths"] = {
+ Path(src_path).resolve() for src_path in config_dict.get("src_paths", ())
+ }
+
+ config = Config(**config_dict)
+ if show_config:
+ print(json.dumps(config.__dict__, indent=4, separators=(",", ": "), default=_preconvert))
+ return
+ elif file_names == ["-"]:
+ arguments.setdefault("settings_path", os.getcwd())
+ api.sort_stream(
+ input_stream=sys.stdin if stdin is None else stdin,
+ output_stream=sys.stdout,
+ **arguments,
+ )
+ else:
+ skipped: List[str] = []
+
+ if config.filter_files:
+ filtered_files = []
+ for file_name in file_names:
+ if config.is_skipped(Path(file_name)):
+ skipped.append(file_name)
+ else:
+ filtered_files.append(file_name)
+ file_names = filtered_files
+
+ file_names = iter_source_code(file_names, config, skipped)
+ num_skipped = 0
+ if config.verbose:
+ print(ASCII_ART)
+
+ if jobs:
+ import multiprocessing
+
+ executor = multiprocessing.Pool(jobs)
+ attempt_iterator = executor.imap(
+ functools.partial(
+ sort_imports,
+ config=config,
+ check=check,
+ ask_to_apply=ask_to_apply,
+ write_to_stdout=write_to_stdout,
+ ),
+ file_names,
+ )
+ else:
+ # https://github.com/python/typeshed/pull/2814
+ attempt_iterator = (
+ sort_imports( # type: ignore
+ file_name,
+ config=config,
+ check=check,
+ ask_to_apply=ask_to_apply,
+ show_diff=show_diff,
+ write_to_stdout=write_to_stdout,
+ )
+ for file_name in file_names
+ )
+
+ for sort_attempt in attempt_iterator:
+ if not sort_attempt:
+ continue # pragma: no cover - shouldn't happen, satisfies type constraint
+ incorrectly_sorted = sort_attempt.incorrectly_sorted
+ if arguments.get("check", False) and incorrectly_sorted:
+ wrong_sorted_files = True
+ if sort_attempt.skipped:
+ num_skipped += (
+ 1 # pragma: no cover - shouldn't happen, due to skip in iter_source_code
+ )
+
+ num_skipped += len(skipped)
+ if num_skipped and not arguments.get("quiet", False):
+ if config.verbose:
+ for was_skipped in skipped:
+ warn(
+ f"{was_skipped} was skipped as it's listed in 'skip' setting"
+ " or matches a glob in 'skip_glob' setting"
+ )
+ print(f"Skipped {num_skipped} files")
+
+ if not config.quiet and (remapped_deprecated_args or deprecated_flags):
+ if remapped_deprecated_args:
+ warn(
+ "W0502: The following deprecated single dash CLI flags were used and translated: "
+ f"{', '.join(remapped_deprecated_args)}!"
+ )
+ if deprecated_flags:
+ warn(
+ "W0501: The following deprecated CLI flags were used and ignored: "
+ f"{', '.join(deprecated_flags)}!"
+ )
+ warn(
+ "W0500: Please see the 5.0.0 Upgrade guide: "
+ "https://timothycrosley.github.io/isort/docs/upgrade_guides/5.0.0/"
+ )
+
+ if wrong_sorted_files:
+ sys.exit(1)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/venv/Lib/site-packages/isort/output.py b/venv/Lib/site-packages/isort/output.py
new file mode 100644
index 0000000..6a21c13
--- /dev/null
+++ b/venv/Lib/site-packages/isort/output.py
@@ -0,0 +1,552 @@
+import copy
+import itertools
+from functools import partial
+from typing import Iterable, List, Set, Tuple
+
+from isort.format import format_simplified
+
+from . import parse, sorting, wrap
+from .comments import add_to_line as with_comments
+from .settings import DEFAULT_CONFIG, Config
+
+STATEMENT_DECLERATIONS: Tuple[str, ...] = ("def ", "cdef ", "cpdef ", "class ", "@", "async def")
+
+
+def sorted_imports(
+ parsed: parse.ParsedContent,
+ config: Config = DEFAULT_CONFIG,
+ extension: str = "py",
+ import_type: str = "import",
+) -> str:
+ """Adds the imports back to the file.
+
+ (at the index of the first import) sorted alphabetically and split between groups
+
+ """
+ if parsed.import_index == -1:
+ return _output_as_string(parsed.lines_without_imports, parsed.line_separator)
+
+ formatted_output: List[str] = parsed.lines_without_imports.copy()
+ remove_imports = [format_simplified(removal) for removal in config.remove_imports]
+
+ sort_ignore_case = config.force_alphabetical_sort_within_sections
+ sections: Iterable[str] = itertools.chain(parsed.sections, config.forced_separate)
+
+ if config.no_sections:
+ parsed.imports["no_sections"] = {"straight": {}, "from": {}}
+ base_sections: Tuple[str, ...] = ()
+ for section in sections:
+ if section == "FUTURE":
+ base_sections = ("FUTURE",)
+ continue
+ parsed.imports["no_sections"]["straight"].update(
+ parsed.imports[section].get("straight", {})
+ )
+ parsed.imports["no_sections"]["from"].update(parsed.imports[section].get("from", {}))
+ sections = base_sections + ("no_sections",)
+
+ output: List[str] = []
+ seen_headings: Set[str] = set()
+ pending_lines_before = False
+ for section in sections:
+ straight_modules = parsed.imports[section]["straight"]
+ straight_modules = sorting.naturally(
+ straight_modules,
+ key=lambda key: sorting.module_key(
+ key, config, section_name=section, straight_import=True
+ ),
+ )
+ from_modules = parsed.imports[section]["from"]
+ from_modules = sorting.naturally(
+ from_modules, key=lambda key: sorting.module_key(key, config, section_name=section)
+ )
+
+ section_output: List[str] = []
+ if config.from_first:
+ section_output = _with_from_imports(
+ parsed,
+ config,
+ from_modules,
+ section,
+ section_output,
+ sort_ignore_case,
+ remove_imports,
+ import_type,
+ )
+ if config.lines_between_types and from_modules and straight_modules:
+ section_output.extend([""] * config.lines_between_types)
+ section_output = _with_straight_imports(
+ parsed,
+ config,
+ straight_modules,
+ section,
+ section_output,
+ remove_imports,
+ import_type,
+ )
+ else:
+ section_output = _with_straight_imports(
+ parsed,
+ config,
+ straight_modules,
+ section,
+ section_output,
+ remove_imports,
+ import_type,
+ )
+ if config.lines_between_types and from_modules and straight_modules:
+ section_output.extend([""] * config.lines_between_types)
+ section_output = _with_from_imports(
+ parsed,
+ config,
+ from_modules,
+ section,
+ section_output,
+ sort_ignore_case,
+ remove_imports,
+ import_type,
+ )
+
+ if config.force_sort_within_sections:
+ # collapse comments
+ comments_above = []
+ new_section_output: List[str] = []
+ for line in section_output:
+ if not line:
+ continue
+ if line.startswith("#"):
+ comments_above.append(line)
+ elif comments_above:
+ new_section_output.append(_LineWithComments(line, comments_above))
+ comments_above = []
+ else:
+ new_section_output.append(line)
+
+ new_section_output = sorting.naturally(
+ new_section_output,
+ key=partial(
+ sorting.section_key,
+ order_by_type=config.order_by_type,
+ force_to_top=config.force_to_top,
+ lexicographical=config.lexicographical,
+ length_sort=config.length_sort,
+ ),
+ )
+
+ # uncollapse comments
+ section_output = []
+ for line in new_section_output:
+ comments = getattr(line, "comments", ())
+ if comments:
+ if (
+ config.ensure_newline_before_comments
+ and section_output
+ and section_output[-1]
+ ):
+ section_output.append("")
+ section_output.extend(comments)
+ section_output.append(str(line))
+
+ section_name = section
+ no_lines_before = section_name in config.no_lines_before
+
+ if section_output:
+ if section_name in parsed.place_imports:
+ parsed.place_imports[section_name] = section_output
+ continue
+
+ section_title = config.import_headings.get(section_name.lower(), "")
+ if section_title and section_title not in seen_headings:
+ if config.dedup_headings:
+ seen_headings.add(section_title)
+ section_comment = f"# {section_title}"
+ if section_comment not in parsed.lines_without_imports[0:1]:
+ section_output.insert(0, section_comment)
+
+ if pending_lines_before or not no_lines_before:
+ output += [""] * config.lines_between_sections
+
+ output += section_output
+
+ pending_lines_before = False
+ else:
+ pending_lines_before = pending_lines_before or not no_lines_before
+
+ while output and output[-1].strip() == "":
+ output.pop() # pragma: no cover
+ while output and output[0].strip() == "":
+ output.pop(0)
+
+ if config.formatting_function:
+ output = config.formatting_function(
+ parsed.line_separator.join(output), extension, config
+ ).splitlines()
+
+ output_at = 0
+ if parsed.import_index < parsed.original_line_count:
+ output_at = parsed.import_index
+ formatted_output[output_at:0] = output
+
+ imports_tail = output_at + len(output)
+ while [
+ character.strip() for character in formatted_output[imports_tail : imports_tail + 1]
+ ] == [""]:
+ formatted_output.pop(imports_tail)
+
+ if len(formatted_output) > imports_tail:
+ next_construct = ""
+ tail = formatted_output[imports_tail:]
+
+ for index, line in enumerate(tail):
+ should_skip, in_quote, *_ = parse.skip_line(
+ line,
+ in_quote="",
+ index=len(formatted_output),
+ section_comments=config.section_comments,
+ needs_import=False,
+ )
+ if not should_skip and line.strip():
+ if (
+ line.strip().startswith("#")
+ and len(tail) > (index + 1)
+ and tail[index + 1].strip()
+ ):
+ continue
+ next_construct = line
+ break
+ elif in_quote:
+ next_construct = line
+ break
+
+ if config.lines_after_imports != -1:
+ formatted_output[imports_tail:0] = ["" for line in range(config.lines_after_imports)]
+ elif extension != "pyi" and next_construct.startswith(STATEMENT_DECLERATIONS):
+ formatted_output[imports_tail:0] = ["", ""]
+ else:
+ formatted_output[imports_tail:0] = [""]
+
+ if parsed.place_imports:
+ new_out_lines = []
+ for index, line in enumerate(formatted_output):
+ new_out_lines.append(line)
+ if line in parsed.import_placements:
+ new_out_lines.extend(parsed.place_imports[parsed.import_placements[line]])
+ if (
+ len(formatted_output) <= (index + 1)
+ or formatted_output[index + 1].strip() != ""
+ ):
+ new_out_lines.append("")
+ formatted_output = new_out_lines
+
+ return _output_as_string(formatted_output, parsed.line_separator)
+
+
+def _with_from_imports(
+ parsed: parse.ParsedContent,
+ config: Config,
+ from_modules: Iterable[str],
+ section: str,
+ section_output: List[str],
+ ignore_case: bool,
+ remove_imports: List[str],
+ import_type: str,
+) -> List[str]:
+ new_section_output = section_output.copy()
+ for module in from_modules:
+ if module in remove_imports:
+ continue
+
+ import_start = f"from {module} {import_type} "
+ from_imports = list(parsed.imports[section]["from"][module])
+ if not config.no_inline_sort or (
+ config.force_single_line and module not in config.single_line_exclusions
+ ):
+ from_imports = sorting.naturally(
+ from_imports,
+ key=lambda key: sorting.module_key(
+ key, config, True, ignore_case, section_name=section
+ ),
+ )
+ if remove_imports:
+ from_imports = [
+ line for line in from_imports if f"{module}.{line}" not in remove_imports
+ ]
+
+ sub_modules = [f"{module}.{from_import}" for from_import in from_imports]
+ as_imports = {
+ from_import: [
+ f"{from_import} as {as_module}" for as_module in parsed.as_map["from"][sub_module]
+ ]
+ for from_import, sub_module in zip(from_imports, sub_modules)
+ if sub_module in parsed.as_map["from"]
+ }
+ if config.combine_as_imports and not ("*" in from_imports and config.combine_star):
+ if not config.no_inline_sort:
+ for as_import in as_imports:
+ as_imports[as_import] = sorting.naturally(as_imports[as_import])
+ for from_import in copy.copy(from_imports):
+ if from_import in as_imports:
+ idx = from_imports.index(from_import)
+ if parsed.imports[section]["from"][module][from_import]:
+ from_imports[(idx + 1) : (idx + 1)] = as_imports.pop(from_import)
+ else:
+ from_imports[idx : (idx + 1)] = as_imports.pop(from_import)
+
+ while from_imports:
+ comments = parsed.categorized_comments["from"].pop(module, ())
+ above_comments = parsed.categorized_comments["above"]["from"].pop(module, None)
+ if above_comments:
+ if new_section_output and config.ensure_newline_before_comments:
+ new_section_output.append("")
+ new_section_output.extend(above_comments)
+
+ if "*" in from_imports and config.combine_star:
+ if config.combine_as_imports:
+ comments = list(comments or ())
+ comments += parsed.categorized_comments["from"].pop(
+ f"{module}.__combined_as__", []
+ )
+ import_statement = wrap.line(
+ with_comments(
+ comments,
+ f"{import_start}*",
+ removed=config.ignore_comments,
+ comment_prefix=config.comment_prefix,
+ ),
+ parsed.line_separator,
+ config,
+ )
+ from_imports = []
+ elif config.force_single_line and module not in config.single_line_exclusions:
+ import_statement = ""
+ while from_imports:
+ from_import = from_imports.pop(0)
+ single_import_line = with_comments(
+ comments,
+ import_start + from_import,
+ removed=config.ignore_comments,
+ comment_prefix=config.comment_prefix,
+ )
+ comment = (
+ parsed.categorized_comments["nested"].get(module, {}).pop(from_import, None)
+ )
+ if comment:
+ single_import_line += (
+ f"{comments and ';' or config.comment_prefix} " f"{comment}"
+ )
+ if from_import in as_imports:
+ if parsed.imports[section]["from"][module][from_import]:
+ new_section_output.append(
+ wrap.line(single_import_line, parsed.line_separator, config)
+ )
+ from_comments = parsed.categorized_comments["straight"].get(
+ f"{module}.{from_import}"
+ )
+ new_section_output.extend(
+ with_comments(
+ from_comments,
+ wrap.line(import_start + as_import, parsed.line_separator, config),
+ removed=config.ignore_comments,
+ comment_prefix=config.comment_prefix,
+ )
+ for as_import in sorting.naturally(as_imports[from_import])
+ )
+ else:
+ new_section_output.append(
+ wrap.line(single_import_line, parsed.line_separator, config)
+ )
+ comments = None
+ else:
+ while from_imports and from_imports[0] in as_imports:
+ from_import = from_imports.pop(0)
+ as_imports[from_import] = sorting.naturally(as_imports[from_import])
+ from_comments = parsed.categorized_comments["straight"].get(
+ f"{module}.{from_import}"
+ )
+ if parsed.imports[section]["from"][module][from_import]:
+ new_section_output.append(
+ wrap.line(
+ with_comments(
+ from_comments,
+ import_start + from_import,
+ removed=config.ignore_comments,
+ comment_prefix=config.comment_prefix,
+ ),
+ parsed.line_separator,
+ config,
+ )
+ )
+ new_section_output.extend(
+ wrap.line(
+ with_comments(
+ from_comments,
+ import_start + as_import,
+ removed=config.ignore_comments,
+ comment_prefix=config.comment_prefix,
+ ),
+ parsed.line_separator,
+ config,
+ )
+ for as_import in as_imports[from_import]
+ )
+
+ if "*" in from_imports:
+ new_section_output.append(
+ with_comments(
+ comments,
+ f"{import_start}*",
+ removed=config.ignore_comments,
+ comment_prefix=config.comment_prefix,
+ )
+ )
+ from_imports.remove("*")
+ comments = None
+
+ for from_import in copy.copy(from_imports):
+ comment = (
+ parsed.categorized_comments["nested"].get(module, {}).pop(from_import, None)
+ )
+ if comment:
+ single_import_line = with_comments(
+ comments,
+ import_start + from_import,
+ removed=config.ignore_comments,
+ comment_prefix=config.comment_prefix,
+ )
+ single_import_line += (
+ f"{comments and ';' or config.comment_prefix} " f"{comment}"
+ )
+ new_section_output.append(
+ wrap.line(single_import_line, parsed.line_separator, config)
+ )
+ from_imports.remove(from_import)
+ comments = None
+
+ from_import_section = []
+ while from_imports and (
+ from_imports[0] not in as_imports
+ or (
+ config.combine_as_imports
+ and parsed.imports[section]["from"][module][from_import]
+ )
+ ):
+ from_import_section.append(from_imports.pop(0))
+ if config.combine_as_imports:
+ comments = (comments or []) + list(
+ parsed.categorized_comments["from"].pop(f"{module}.__combined_as__", ())
+ )
+ import_statement = with_comments(
+ comments,
+ import_start + (", ").join(from_import_section),
+ removed=config.ignore_comments,
+ comment_prefix=config.comment_prefix,
+ )
+ if not from_import_section:
+ import_statement = ""
+
+ do_multiline_reformat = False
+
+ force_grid_wrap = config.force_grid_wrap
+ if force_grid_wrap and len(from_import_section) >= force_grid_wrap:
+ do_multiline_reformat = True
+
+ if len(import_statement) > config.line_length and len(from_import_section) > 1:
+ do_multiline_reformat = True
+
+ # If line too long AND have imports AND we are
+ # NOT using GRID or VERTICAL wrap modes
+ if (
+ len(import_statement) > config.line_length
+ and len(from_import_section) > 0
+ and config.multi_line_output
+ not in (wrap.Modes.GRID, wrap.Modes.VERTICAL) # type: ignore
+ ):
+ do_multiline_reformat = True
+
+ if do_multiline_reformat:
+ import_statement = wrap.import_statement(
+ import_start=import_start,
+ from_imports=from_import_section,
+ comments=comments,
+ line_separator=parsed.line_separator,
+ config=config,
+ )
+ if config.multi_line_output == wrap.Modes.GRID: # type: ignore
+ other_import_statement = wrap.import_statement(
+ import_start=import_start,
+ from_imports=from_import_section,
+ comments=comments,
+ line_separator=parsed.line_separator,
+ config=config,
+ multi_line_output=wrap.Modes.VERTICAL_GRID, # type: ignore
+ )
+ if max(len(x) for x in import_statement.split("\n")) > config.line_length:
+ import_statement = other_import_statement
+ if not do_multiline_reformat and len(import_statement) > config.line_length:
+ import_statement = wrap.line(import_statement, parsed.line_separator, config)
+
+ if import_statement:
+ new_section_output.append(import_statement)
+ return new_section_output
+
+
+def _with_straight_imports(
+ parsed: parse.ParsedContent,
+ config: Config,
+ straight_modules: Iterable[str],
+ section: str,
+ section_output: List[str],
+ remove_imports: List[str],
+ import_type: str,
+) -> List[str]:
+ new_section_output = section_output.copy()
+ for module in straight_modules:
+ if module in remove_imports:
+ continue
+
+ import_definition = []
+ if module in parsed.as_map["straight"]:
+ if parsed.imports[section]["straight"][module]:
+ import_definition.append(f"{import_type} {module}")
+ import_definition.extend(
+ f"{import_type} {module} as {as_import}"
+ for as_import in parsed.as_map["straight"][module]
+ )
+ else:
+ import_definition.append(f"{import_type} {module}")
+
+ comments_above = parsed.categorized_comments["above"]["straight"].pop(module, None)
+ if comments_above:
+ if new_section_output and config.ensure_newline_before_comments:
+ new_section_output.append("")
+ new_section_output.extend(comments_above)
+ new_section_output.extend(
+ with_comments(
+ parsed.categorized_comments["straight"].get(module),
+ idef,
+ removed=config.ignore_comments,
+ comment_prefix=config.comment_prefix,
+ )
+ for idef in import_definition
+ )
+
+ return new_section_output
+
+
+def _output_as_string(lines: List[str], line_separator: str) -> str:
+ return line_separator.join(_normalize_empty_lines(lines))
+
+
+def _normalize_empty_lines(lines: List[str]) -> List[str]:
+ while lines and lines[-1].strip() == "":
+ lines.pop(-1)
+
+ lines.append("")
+ return lines
+
+
+class _LineWithComments(str):
+ def __new__(cls, value, comments):
+ instance = super().__new__(cls, value) # type: ignore
+ instance.comments = comments
+ return instance
diff --git a/venv/Lib/site-packages/isort/parse.py b/venv/Lib/site-packages/isort/parse.py
new file mode 100644
index 0000000..2ab43ac
--- /dev/null
+++ b/venv/Lib/site-packages/isort/parse.py
@@ -0,0 +1,463 @@
+"""Defines parsing functions used by isort for parsing import definitions"""
+from collections import OrderedDict, defaultdict
+from functools import partial
+from itertools import chain
+from typing import TYPE_CHECKING, Any, Dict, List, NamedTuple, Optional, Tuple
+from warnings import warn
+
+from . import place
+from .comments import parse as parse_comments
+from .deprecated.finders import FindersManager
+from .settings import DEFAULT_CONFIG, Config
+
+if TYPE_CHECKING:
+ from mypy_extensions import TypedDict
+
+ CommentsAboveDict = TypedDict(
+ "CommentsAboveDict", {"straight": Dict[str, Any], "from": Dict[str, Any]}
+ )
+
+ CommentsDict = TypedDict(
+ "CommentsDict",
+ {
+ "from": Dict[str, Any],
+ "straight": Dict[str, Any],
+ "nested": Dict[str, Any],
+ "above": CommentsAboveDict,
+ },
+ )
+
+
+def _infer_line_separator(contents: str) -> str:
+ if "\r\n" in contents:
+ return "\r\n"
+ elif "\r" in contents:
+ return "\r"
+ else:
+ return "\n"
+
+
+def _normalize_line(raw_line: str) -> Tuple[str, str]:
+ """Normalizes import related statements in the provided line.
+
+ Returns (normalized_line: str, raw_line: str)
+ """
+ line = raw_line.replace("from.import ", "from . import ")
+ line = line.replace("from.cimport ", "from . cimport ")
+ line = line.replace("import*", "import *")
+ line = line.replace(" .import ", " . import ")
+ line = line.replace(" .cimport ", " . cimport ")
+ line = line.replace("\t", " ")
+ return (line, raw_line)
+
+
+def import_type(line: str, config: Config = DEFAULT_CONFIG) -> Optional[str]:
+ """If the current line is an import line it will return its type (from or straight)"""
+ if config.honor_noqa and line.lower().rstrip().endswith("noqa"):
+ return None
+ elif "isort:skip" in line or "isort: skip" in line or "isort: split" in line:
+ return None
+ elif line.startswith(("import ", "cimport ")):
+ return "straight"
+ elif line.startswith("from "):
+ return "from"
+ return None
+
+
+def _strip_syntax(import_string: str) -> str:
+ import_string = import_string.replace("_import", "[[i]]")
+ import_string = import_string.replace("_cimport", "[[ci]]")
+ for remove_syntax in ["\\", "(", ")", ","]:
+ import_string = import_string.replace(remove_syntax, " ")
+ import_list = import_string.split()
+ for key in ("from", "import", "cimport"):
+ if key in import_list:
+ import_list.remove(key)
+ import_string = " ".join(import_list)
+ import_string = import_string.replace("[[i]]", "_import")
+ import_string = import_string.replace("[[ci]]", "_cimport")
+ return import_string.replace("{ ", "{|").replace(" }", "|}")
+
+
+def skip_line(
+ line: str,
+ in_quote: str,
+ index: int,
+ section_comments: Tuple[str, ...],
+ needs_import: bool = True,
+) -> Tuple[bool, str]:
+ """Determine if a given line should be skipped.
+
+ Returns back a tuple containing:
+
+ (skip_line: bool,
+ in_quote: str,)
+ """
+ should_skip = bool(in_quote)
+ if '"' in line or "'" in line:
+ char_index = 0
+ while char_index < len(line):
+ if line[char_index] == "\\":
+ char_index += 1
+ elif in_quote:
+ if line[char_index : char_index + len(in_quote)] == in_quote:
+ in_quote = ""
+ elif line[char_index] in ("'", '"'):
+ long_quote = line[char_index : char_index + 3]
+ if long_quote in ('"""', "'''"):
+ in_quote = long_quote
+ char_index += 2
+ else:
+ in_quote = line[char_index]
+ elif line[char_index] == "#":
+ break
+ char_index += 1
+
+ if ";" in line and needs_import:
+ for part in (part.strip() for part in line.split(";")):
+ if (
+ part
+ and not part.startswith("from ")
+ and not part.startswith(("import ", "cimport "))
+ ):
+ should_skip = True
+
+ return (bool(should_skip or in_quote), in_quote)
+
+
+class ParsedContent(NamedTuple):
+ in_lines: List[str]
+ lines_without_imports: List[str]
+ import_index: int
+ place_imports: Dict[str, List[str]]
+ import_placements: Dict[str, str]
+ as_map: Dict[str, Dict[str, List[str]]]
+ imports: Dict[str, Dict[str, Any]]
+ categorized_comments: "CommentsDict"
+ change_count: int
+ original_line_count: int
+ line_separator: str
+ sections: Any
+
+
+def file_contents(contents: str, config: Config = DEFAULT_CONFIG) -> ParsedContent:
+ """Parses a python file taking out and categorizing imports."""
+ line_separator: str = config.line_ending or _infer_line_separator(contents)
+ in_lines = contents.splitlines()
+ if contents and contents[-1] in ("\n", "\r"):
+ in_lines.append("")
+
+ out_lines = []
+ original_line_count = len(in_lines)
+ if config.old_finders:
+ finder = FindersManager(config=config).find
+ else:
+ finder = partial(place.module, config=config)
+
+ line_count = len(in_lines)
+
+ place_imports: Dict[str, List[str]] = {}
+ import_placements: Dict[str, str] = {}
+ as_map: Dict[str, Dict[str, List[str]]] = {
+ "straight": defaultdict(list),
+ "from": defaultdict(list),
+ }
+ imports: OrderedDict[str, Dict[str, Any]] = OrderedDict()
+ for section in chain(config.sections, config.forced_separate):
+ imports[section] = {"straight": OrderedDict(), "from": OrderedDict()}
+ categorized_comments: CommentsDict = {
+ "from": {},
+ "straight": {},
+ "nested": {},
+ "above": {"straight": {}, "from": {}},
+ }
+
+ index = 0
+ import_index = -1
+ in_quote = ""
+ while index < line_count:
+ line = in_lines[index]
+ index += 1
+ statement_index = index
+ (skipping_line, in_quote) = skip_line(
+ line, in_quote=in_quote, index=index, section_comments=config.section_comments
+ )
+
+ if line in config.section_comments and not skipping_line:
+ if import_index == -1:
+ import_index = index - 1
+ continue
+
+ if "isort:imports-" in line and line.startswith("#"):
+ section = line.split("isort:imports-")[-1].split()[0].upper()
+ place_imports[section] = []
+ import_placements[line] = section
+ elif "isort: imports-" in line and line.startswith("#"):
+ section = line.split("isort: imports-")[-1].split()[0].upper()
+ place_imports[section] = []
+ import_placements[line] = section
+
+ if skipping_line:
+ out_lines.append(line)
+ continue
+
+ for line in (
+ (line.strip() for line in line.split(";")) if ";" in line else (line,) # type: ignore
+ ):
+ line, raw_line = _normalize_line(line)
+ type_of_import = import_type(line, config) or ""
+ if not type_of_import:
+ out_lines.append(raw_line)
+ continue
+
+ if import_index == -1:
+ import_index = index - 1
+ nested_comments = {}
+ import_string, comment = parse_comments(line)
+ comments = [comment] if comment else []
+ line_parts = [part for part in _strip_syntax(import_string).strip().split(" ") if part]
+ if (
+ type_of_import == "from"
+ and len(line_parts) == 2
+ and line_parts[1] != "*"
+ and comments
+ ):
+ nested_comments[line_parts[-1]] = comments[0]
+
+ if "(" in line.split("#")[0] and index < line_count:
+ while not line.split("#")[0].strip().endswith(")") and index < line_count:
+ line, new_comment = parse_comments(in_lines[index])
+ index += 1
+ if new_comment:
+ comments.append(new_comment)
+ stripped_line = _strip_syntax(line).strip()
+ if (
+ type_of_import == "from"
+ and stripped_line
+ and " " not in stripped_line
+ and new_comment
+ ):
+ nested_comments[stripped_line] = comments[-1]
+ import_string += line_separator + line
+ else:
+ while line.strip().endswith("\\"):
+ line, new_comment = parse_comments(in_lines[index])
+ index += 1
+ if new_comment:
+ comments.append(new_comment)
+
+ # Still need to check for parentheses after an escaped line
+ if (
+ "(" in line.split("#")[0]
+ and ")" not in line.split("#")[0]
+ and index < line_count
+ ):
+ stripped_line = _strip_syntax(line).strip()
+ if (
+ type_of_import == "from"
+ and stripped_line
+ and " " not in stripped_line
+ and new_comment
+ ):
+ nested_comments[stripped_line] = comments[-1]
+ import_string += line_separator + line
+
+ while not line.split("#")[0].strip().endswith(")") and index < line_count:
+ line, new_comment = parse_comments(in_lines[index])
+ index += 1
+ if new_comment:
+ comments.append(new_comment)
+ stripped_line = _strip_syntax(line).strip()
+ if (
+ type_of_import == "from"
+ and stripped_line
+ and " " not in stripped_line
+ and new_comment
+ ):
+ nested_comments[stripped_line] = comments[-1]
+ import_string += line_separator + line
+
+ stripped_line = _strip_syntax(line).strip()
+ if (
+ type_of_import == "from"
+ and stripped_line
+ and " " not in stripped_line
+ and new_comment
+ ):
+ nested_comments[stripped_line] = comments[-1]
+ if import_string.strip().endswith(
+ (" import", " cimport")
+ ) or line.strip().startswith(("import ", "cimport ")):
+ import_string += line_separator + line
+ else:
+ import_string = import_string.rstrip().rstrip("\\") + " " + line.lstrip()
+
+ if type_of_import == "from":
+ cimports: bool
+ import_string = (
+ import_string.replace("import(", "import (")
+ .replace("\\", " ")
+ .replace("\n", " ")
+ )
+ if " cimport " in import_string:
+ parts = import_string.split(" cimport ")
+ cimports = True
+
+ else:
+ parts = import_string.split(" import ")
+ cimports = False
+
+ from_import = parts[0].split(" ")
+ import_string = (" cimport " if cimports else " import ").join(
+ [from_import[0] + " " + "".join(from_import[1:])] + parts[1:]
+ )
+
+ just_imports = [
+ item.replace("{|", "{ ").replace("|}", " }")
+ for item in _strip_syntax(import_string).split()
+ ]
+ straight_import = True
+ if "as" in just_imports and (just_imports.index("as") + 1) < len(just_imports):
+ straight_import = False
+ while "as" in just_imports:
+ nested_module = None
+ as_index = just_imports.index("as")
+ if type_of_import == "from":
+ nested_module = just_imports[as_index - 1]
+ top_level_module = just_imports[0]
+ module = top_level_module + "." + nested_module
+ as_name = just_imports[as_index + 1]
+ if nested_module == as_name and config.remove_redundant_aliases:
+ pass
+ elif as_name not in as_map["from"][module]:
+ as_map["from"][module].append(as_name)
+ else:
+ module = just_imports[as_index - 1]
+ as_name = just_imports[as_index + 1]
+ if module == as_name and config.remove_redundant_aliases:
+ pass
+ elif as_name not in as_map["straight"][module]:
+ as_map["straight"][module].append(as_name)
+
+ if config.combine_as_imports and nested_module:
+ categorized_comments["from"].setdefault(
+ f"{top_level_module}.__combined_as__", []
+ ).extend(comments)
+ comments = []
+ else:
+ categorized_comments["straight"][module] = comments
+ comments = []
+ del just_imports[as_index : as_index + 2]
+ if type_of_import == "from":
+ import_from = just_imports.pop(0)
+ placed_module = finder(import_from)
+ if config.verbose:
+ print(f"from-type place_module for {import_from} returned {placed_module}")
+ if placed_module == "":
+ warn(
+ f"could not place module {import_from} of line {line} --"
+ " Do you need to define a default section?"
+ )
+ root = imports[placed_module][type_of_import] # type: ignore
+ for import_name in just_imports:
+ associated_comment = nested_comments.get(import_name)
+ if associated_comment:
+ categorized_comments["nested"].setdefault(import_from, {})[
+ import_name
+ ] = associated_comment
+ if associated_comment in comments:
+ comments.pop(comments.index(associated_comment))
+ if comments:
+ categorized_comments["from"].setdefault(import_from, []).extend(comments)
+
+ if len(out_lines) > max(import_index, 1) - 1:
+ last = out_lines and out_lines[-1].rstrip() or ""
+ while (
+ last.startswith("#")
+ and not last.endswith('"""')
+ and not last.endswith("'''")
+ and "isort:imports-" not in last
+ and "isort: imports-" not in last
+ and not config.treat_all_comments_as_code
+ and not last.strip() in config.treat_comments_as_code
+ ):
+ categorized_comments["above"]["from"].setdefault(import_from, []).insert(
+ 0, out_lines.pop(-1)
+ )
+ if out_lines:
+ last = out_lines[-1].rstrip()
+ else:
+ last = ""
+ if statement_index - 1 == import_index: # pragma: no cover
+ import_index -= len(
+ categorized_comments["above"]["from"].get(import_from, [])
+ )
+
+ if import_from not in root:
+ root[import_from] = OrderedDict(
+ (module, straight_import) for module in just_imports
+ )
+ else:
+ root[import_from].update(
+ (module, straight_import | root[import_from].get(module, False))
+ for module in just_imports
+ )
+ else:
+ for module in just_imports:
+ if comments:
+ categorized_comments["straight"][module] = comments
+ comments = []
+
+ if len(out_lines) > max(import_index, +1, 1) - 1:
+
+ last = out_lines and out_lines[-1].rstrip() or ""
+ while (
+ last.startswith("#")
+ and not last.endswith('"""')
+ and not last.endswith("'''")
+ and "isort:imports-" not in last
+ and "isort: imports-" not in last
+ and not config.treat_all_comments_as_code
+ and not last.strip() in config.treat_comments_as_code
+ ):
+ categorized_comments["above"]["straight"].setdefault(module, []).insert(
+ 0, out_lines.pop(-1)
+ )
+ if out_lines:
+ last = out_lines[-1].rstrip()
+ else:
+ last = ""
+ if index - 1 == import_index:
+ import_index -= len(
+ categorized_comments["above"]["straight"].get(module, [])
+ )
+ placed_module = finder(module)
+ if config.verbose:
+ print(f"else-type place_module for {module} returned {placed_module}")
+ if placed_module == "":
+ warn(
+ f"could not place module {module} of line {line} --"
+ " Do you need to define a default section?"
+ )
+ imports.setdefault("", {"straight": OrderedDict(), "from": OrderedDict()})
+ straight_import |= imports[placed_module][type_of_import].get( # type: ignore
+ module, False
+ )
+ imports[placed_module][type_of_import][module] = straight_import # type: ignore
+
+ change_count = len(out_lines) - original_line_count
+
+ return ParsedContent(
+ in_lines=in_lines,
+ lines_without_imports=out_lines,
+ import_index=import_index,
+ place_imports=place_imports,
+ import_placements=import_placements,
+ as_map=as_map,
+ imports=imports,
+ categorized_comments=categorized_comments,
+ change_count=change_count,
+ original_line_count=original_line_count,
+ line_separator=line_separator,
+ sections=config.sections,
+ )
diff --git a/venv/Lib/site-packages/isort/place.py b/venv/Lib/site-packages/isort/place.py
new file mode 100644
index 0000000..34b2eeb
--- /dev/null
+++ b/venv/Lib/site-packages/isort/place.py
@@ -0,0 +1,95 @@
+"""Contains all logic related to placing an import within a certain section."""
+import importlib
+from fnmatch import fnmatch
+from functools import lru_cache
+from pathlib import Path
+from typing import Optional, Tuple
+
+from isort import sections
+from isort.settings import DEFAULT_CONFIG, Config
+from isort.utils import exists_case_sensitive
+
+LOCAL = "LOCALFOLDER"
+
+
+def module(name: str, config: Config = DEFAULT_CONFIG) -> str:
+ """Returns the section placement for the given module name."""
+ return module_with_reason(name, config)[0]
+
+
+@lru_cache(maxsize=1000)
+def module_with_reason(name: str, config: Config = DEFAULT_CONFIG) -> Tuple[str, str]:
+ """Returns the section placement for the given module name alongside the reasoning."""
+ return (
+ _forced_separate(name, config)
+ or _local(name, config)
+ or _known_pattern(name, config)
+ or _src_path(name, config)
+ or (config.default_section, "Default option in Config or universal default.")
+ )
+
+
+def _forced_separate(name: str, config: Config) -> Optional[Tuple[str, str]]:
+ for forced_separate in config.forced_separate:
+ # Ensure all forced_separate patterns will match to end of string
+ path_glob = forced_separate
+ if not forced_separate.endswith("*"):
+ path_glob = "%s*" % forced_separate
+
+ if fnmatch(name, path_glob) or fnmatch(name, "." + path_glob):
+ return (forced_separate, f"Matched forced_separate ({forced_separate}) config value.")
+
+ return None
+
+
+def _local(name: str, config: Config) -> Optional[Tuple[str, str]]:
+ if name.startswith("."):
+ return (LOCAL, "Module name started with a dot.")
+
+ return None
+
+
+def _known_pattern(name: str, config: Config) -> Optional[Tuple[str, str]]:
+ parts = name.split(".")
+ module_names_to_check = (".".join(parts[:first_k]) for first_k in range(len(parts), 0, -1))
+ for module_name_to_check in module_names_to_check:
+ for pattern, placement in config.known_patterns:
+ if pattern.match(module_name_to_check):
+ return (placement, f"Matched configured known pattern {pattern}")
+
+ return None
+
+
+def _src_path(name: str, config: Config) -> Optional[Tuple[str, str]]:
+ for src_path in config.src_paths:
+ root_module_name = name.split(".")[0]
+ module_path = (src_path / root_module_name).resolve()
+ if (
+ _is_module(module_path)
+ or _is_package(module_path)
+ or _src_path_is_module(src_path, root_module_name)
+ ):
+ return (sections.FIRSTPARTY, f"Found in one of the configured src_paths: {src_path}.")
+
+ return None
+
+
+def _is_module(path: Path) -> bool:
+ return (
+ exists_case_sensitive(str(path.with_suffix(".py")))
+ or any(
+ exists_case_sensitive(str(path.with_suffix(ext_suffix)))
+ for ext_suffix in importlib.machinery.EXTENSION_SUFFIXES
+ )
+ or exists_case_sensitive(str(path / "__init__.py"))
+ )
+
+
+def _is_package(path: Path) -> bool:
+ return exists_case_sensitive(str(path)) and path.is_dir()
+
+
+def _src_path_is_module(src_path: Path, module_name: str) -> bool:
+ return (
+ module_name == src_path.name and src_path.is_dir() and exists_case_sensitive(str(src_path))
+ )
diff --git a/venv/Lib/site-packages/isort/profiles.py b/venv/Lib/site-packages/isort/profiles.py
new file mode 100644
index 0000000..cd976cd
--- /dev/null
+++ b/venv/Lib/site-packages/isort/profiles.py
@@ -0,0 +1,62 @@
+"""Common profiles are defined here to be easily used within a project using --profile {name}"""
+from typing import Any, Dict
+
+black = {
+ "multi_line_output": 3,
+ "include_trailing_comma": True,
+ "force_grid_wrap": 0,
+ "use_parentheses": True,
+ "ensure_newline_before_comments": True,
+ "line_length": 88,
+}
+django = {
+ "combine_as_imports": True,
+ "include_trailing_comma": True,
+ "multi_line_output": 5,
+ "line_length": 79,
+}
+pycharm = {"multi_line_output": 3, "force_grid_wrap": 2}
+google = {
+ "force_single_line": True,
+ "force_sort_within_sections": True,
+ "lexicographical": True,
+ "single_line_exclusions": ("typing",),
+}
+open_stack = {
+ "force_single_line": True,
+ "force_sort_within_sections": True,
+ "lexicographical": True,
+}
+plone = {
+ "force_alphabetical_sort": True,
+ "force_single_line": True,
+ "lines_after_imports": 2,
+ "line_length": 200,
+}
+attrs = {
+ "atomic": True,
+ "force_grid_wrap": 0,
+ "include_trailing_comma": True,
+ "lines_after_imports": 2,
+ "lines_between_types": 1,
+ "multi_line_output": 3,
+ "use_parentheses": True,
+}
+hug = {
+ "multi_line_output": 3,
+ "include_trailing_comma": True,
+ "force_grid_wrap": 0,
+ "use_parentheses": True,
+ "line_length": 100,
+}
+
+profiles: Dict[str, Dict[str, Any]] = {
+ "black": black,
+ "django": django,
+ "pycharm": pycharm,
+ "google": google,
+ "open_stack": open_stack,
+ "plone": plone,
+ "attrs": attrs,
+ "hug": hug,
+}
diff --git a/venv/Lib/site-packages/isort/pylama_isort.py b/venv/Lib/site-packages/isort/pylama_isort.py
new file mode 100644
index 0000000..0e14d56
--- /dev/null
+++ b/venv/Lib/site-packages/isort/pylama_isort.py
@@ -0,0 +1,33 @@
+import os
+import sys
+from contextlib import contextmanager
+from typing import Any, Dict, List
+
+from pylama.lint import Linter as BaseLinter
+
+from . import api
+
+
+@contextmanager
+def supress_stdout():
+ stdout = sys.stdout
+ with open(os.devnull, "w") as devnull:
+ sys.stdout = devnull
+ yield
+ sys.stdout = stdout
+
+
+class Linter(BaseLinter):
+ def allow(self, path: str) -> bool:
+ """Determine if this path should be linted."""
+ return path.endswith(".py")
+
+ def run(self, path: str, **meta: Any) -> List[Dict[str, Any]]:
+ """Lint the file. Return an array of error dicts if appropriate."""
+ with supress_stdout():
+ if not api.check_file(path):
+ return [
+ {"lnum": 0, "col": 0, "text": "Incorrectly sorted imports.", "type": "ISORT"}
+ ]
+ else:
+ return []
diff --git a/venv/Lib/site-packages/isort/sections.py b/venv/Lib/site-packages/isort/sections.py
new file mode 100644
index 0000000..f59db69
--- /dev/null
+++ b/venv/Lib/site-packages/isort/sections.py
@@ -0,0 +1,9 @@
+"""Defines all sections isort uses by default"""
+from typing import Tuple
+
+FUTURE: str = "FUTURE"
+STDLIB: str = "STDLIB"
+THIRDPARTY: str = "THIRDPARTY"
+FIRSTPARTY: str = "FIRSTPARTY"
+LOCALFOLDER: str = "LOCALFOLDER"
+DEFAULT: Tuple[str, ...] = (FUTURE, STDLIB, THIRDPARTY, FIRSTPARTY, LOCALFOLDER)
diff --git a/venv/Lib/site-packages/isort/settings.py b/venv/Lib/site-packages/isort/settings.py
new file mode 100644
index 0000000..500790b
--- /dev/null
+++ b/venv/Lib/site-packages/isort/settings.py
@@ -0,0 +1,698 @@
+"""isort/settings.py.
+
+Defines how the default settings for isort should be loaded
+"""
+import configparser
+import fnmatch
+import os
+import posixpath
+import re
+import stat
+import subprocess # nosec: Needed for gitignore support.
+import sys
+from functools import lru_cache
+from pathlib import Path
+from typing import Any, Callable, Dict, FrozenSet, Iterable, List, Optional, Pattern, Set, Tuple
+from warnings import warn
+
+from . import stdlibs
+from ._future import dataclass, field
+from ._vendored import toml
+from .exceptions import FormattingPluginDoesNotExist, InvalidSettingsPath, ProfileDoesNotExist
+from .profiles import profiles
+from .sections import DEFAULT as SECTION_DEFAULTS
+from .sections import FIRSTPARTY, FUTURE, LOCALFOLDER, STDLIB, THIRDPARTY
+from .wrap_modes import WrapModes
+from .wrap_modes import from_string as wrap_mode_from_string
+
+_SHEBANG_RE = re.compile(br"^#!.*\bpython[23w]?\b")
+SUPPORTED_EXTENSIONS = frozenset({"py", "pyi", "pyx"})
+BLOCKED_EXTENSIONS = frozenset({"pex"})
+FILE_SKIP_COMMENTS: Tuple[str, ...] = (
+ "isort:" + "skip_file",
+ "isort: " + "skip_file",
+) # Concatenated to avoid this file being skipped
+MAX_CONFIG_SEARCH_DEPTH: int = 25 # The number of parent directories to for a config file within
+STOP_CONFIG_SEARCH_ON_DIRS: Tuple[str, ...] = (".git", ".hg")
+VALID_PY_TARGETS: Tuple[str, ...] = tuple(
+ target.replace("py", "") for target in dir(stdlibs) if not target.startswith("_")
+)
+CONFIG_SOURCES: Tuple[str, ...] = (
+ ".isort.cfg",
+ "pyproject.toml",
+ "setup.cfg",
+ "tox.ini",
+ ".editorconfig",
+)
+DEFAULT_SKIP: FrozenSet[str] = frozenset(
+ {
+ ".venv",
+ "venv",
+ ".tox",
+ ".eggs",
+ ".git",
+ ".hg",
+ ".mypy_cache",
+ ".nox",
+ "_build",
+ "buck-out",
+ "build",
+ "dist",
+ ".pants.d",
+ "node_modules",
+ }
+)
+
+CONFIG_SECTIONS: Dict[str, Tuple[str, ...]] = {
+ ".isort.cfg": ("settings", "isort"),
+ "pyproject.toml": ("tool.isort",),
+ "setup.cfg": ("isort", "tool:isort"),
+ "tox.ini": ("isort", "tool:isort"),
+ ".editorconfig": ("*", "*.py", "**.py", "*.{py}"),
+}
+FALLBACK_CONFIG_SECTIONS: Tuple[str, ...] = ("isort", "tool:isort", "tool.isort")
+
+IMPORT_HEADING_PREFIX = "import_heading_"
+KNOWN_PREFIX = "known_"
+KNOWN_SECTION_MAPPING: Dict[str, str] = {
+ STDLIB: "STANDARD_LIBRARY",
+ FUTURE: "FUTURE_LIBRARY",
+ FIRSTPARTY: "FIRST_PARTY",
+ THIRDPARTY: "THIRD_PARTY",
+ LOCALFOLDER: "LOCAL_FOLDER",
+}
+
+RUNTIME_SOURCE = "runtime"
+
+DEPRECATED_SETTINGS = ("not_skip", "keep_direct_and_as_imports")
+
+_STR_BOOLEAN_MAPPING = {
+ "y": True,
+ "yes": True,
+ "t": True,
+ "on": True,
+ "1": True,
+ "true": True,
+ "n": False,
+ "no": False,
+ "f": False,
+ "off": False,
+ "0": False,
+ "false": False,
+}
+
+
+@dataclass(frozen=True)
+class _Config:
+ """Defines the data schema and defaults used for isort configuration.
+
+ NOTE: known lists, such as known_standard_library, are intentionally not complete as they are
+ dynamically determined later on.
+ """
+
+ py_version: str = "3"
+ force_to_top: FrozenSet[str] = frozenset()
+ skip: FrozenSet[str] = DEFAULT_SKIP
+ skip_glob: FrozenSet[str] = frozenset()
+ skip_gitignore: bool = False
+ line_length: int = 79
+ wrap_length: int = 0
+ line_ending: str = ""
+ sections: Tuple[str, ...] = SECTION_DEFAULTS
+ no_sections: bool = False
+ known_future_library: FrozenSet[str] = frozenset(("__future__",))
+ known_third_party: FrozenSet[str] = frozenset()
+ known_first_party: FrozenSet[str] = frozenset()
+ known_local_folder: FrozenSet[str] = frozenset()
+ known_standard_library: FrozenSet[str] = frozenset()
+ extra_standard_library: FrozenSet[str] = frozenset()
+ known_other: Dict[str, FrozenSet[str]] = field(default_factory=dict)
+ multi_line_output: WrapModes = WrapModes.GRID # type: ignore
+ forced_separate: Tuple[str, ...] = ()
+ indent: str = " " * 4
+ comment_prefix: str = " #"
+ length_sort: bool = False
+ length_sort_straight: bool = False
+ length_sort_sections: FrozenSet[str] = frozenset()
+ add_imports: FrozenSet[str] = frozenset()
+ remove_imports: FrozenSet[str] = frozenset()
+ append_only: bool = False
+ reverse_relative: bool = False
+ force_single_line: bool = False
+ single_line_exclusions: Tuple[str, ...] = ()
+ default_section: str = THIRDPARTY
+ import_headings: Dict[str, str] = field(default_factory=dict)
+ balanced_wrapping: bool = False
+ use_parentheses: bool = False
+ order_by_type: bool = True
+ atomic: bool = False
+ lines_after_imports: int = -1
+ lines_between_sections: int = 1
+ lines_between_types: int = 0
+ combine_as_imports: bool = False
+ combine_star: bool = False
+ include_trailing_comma: bool = False
+ from_first: bool = False
+ verbose: bool = False
+ quiet: bool = False
+ force_adds: bool = False
+ force_alphabetical_sort_within_sections: bool = False
+ force_alphabetical_sort: bool = False
+ force_grid_wrap: int = 0
+ force_sort_within_sections: bool = False
+ lexicographical: bool = False
+ ignore_whitespace: bool = False
+ no_lines_before: FrozenSet[str] = frozenset()
+ no_inline_sort: bool = False
+ ignore_comments: bool = False
+ case_sensitive: bool = False
+ sources: Tuple[Dict[str, Any], ...] = ()
+ virtual_env: str = ""
+ conda_env: str = ""
+ ensure_newline_before_comments: bool = False
+ directory: str = ""
+ profile: str = ""
+ honor_noqa: bool = False
+ src_paths: FrozenSet[Path] = frozenset()
+ old_finders: bool = False
+ remove_redundant_aliases: bool = False
+ float_to_top: bool = False
+ filter_files: bool = False
+ formatter: str = ""
+ formatting_function: Optional[Callable[[str, str, object], str]] = None
+ color_output: bool = False
+ treat_comments_as_code: FrozenSet[str] = frozenset()
+ treat_all_comments_as_code: bool = False
+ supported_extensions: FrozenSet[str] = SUPPORTED_EXTENSIONS
+ blocked_extensions: FrozenSet[str] = BLOCKED_EXTENSIONS
+ constants: FrozenSet[str] = frozenset()
+ classes: FrozenSet[str] = frozenset()
+ variables: FrozenSet[str] = frozenset()
+ dedup_headings: bool = False
+
+ def __post_init__(self):
+ py_version = self.py_version
+ if py_version == "auto": # pragma: no cover
+ if sys.version_info.major == 2 and sys.version_info.minor <= 6:
+ py_version = "2"
+ elif sys.version_info.major == 3 and (
+ sys.version_info.minor <= 5 or sys.version_info.minor >= 9
+ ):
+ py_version = "3"
+ else:
+ py_version = f"{sys.version_info.major}{sys.version_info.minor}"
+
+ if py_version not in VALID_PY_TARGETS:
+ raise ValueError(
+ f"The python version {py_version} is not supported. "
+ "You can set a python version with the -py or --python-version flag. "
+ f"The following versions are supported: {VALID_PY_TARGETS}"
+ )
+
+ if py_version != "all":
+ object.__setattr__(self, "py_version", f"py{py_version}")
+
+ if not self.known_standard_library:
+ object.__setattr__(
+ self, "known_standard_library", frozenset(getattr(stdlibs, self.py_version).stdlib)
+ )
+
+ if self.force_alphabetical_sort:
+ object.__setattr__(self, "force_alphabetical_sort_within_sections", True)
+ object.__setattr__(self, "no_sections", True)
+ object.__setattr__(self, "lines_between_types", 1)
+ object.__setattr__(self, "from_first", True)
+ if self.wrap_length > self.line_length:
+ raise ValueError(
+ "wrap_length must be set lower than or equal to line_length: "
+ f"{self.wrap_length} > {self.line_length}."
+ )
+
+ def __hash__(self):
+ return id(self)
+
+
+_DEFAULT_SETTINGS = {**vars(_Config()), "source": "defaults"}
+
+
+class Config(_Config):
+ def __init__(
+ self,
+ settings_file: str = "",
+ settings_path: str = "",
+ config: Optional[_Config] = None,
+ **config_overrides,
+ ):
+ self._known_patterns: Optional[List[Tuple[Pattern[str], str]]] = None
+ self._section_comments: Optional[Tuple[str, ...]] = None
+
+ if config:
+ config_vars = vars(config).copy()
+ config_vars.update(config_overrides)
+ config_vars["py_version"] = config_vars["py_version"].replace("py", "")
+ config_vars.pop("_known_patterns")
+ config_vars.pop("_section_comments")
+ super().__init__(**config_vars) # type: ignore
+ return
+
+ sources: List[Dict[str, Any]] = [_DEFAULT_SETTINGS]
+
+ config_settings: Dict[str, Any]
+ project_root: str
+ if settings_file:
+ config_settings = _get_config_data(
+ settings_file,
+ CONFIG_SECTIONS.get(os.path.basename(settings_file), FALLBACK_CONFIG_SECTIONS),
+ )
+ project_root = os.path.dirname(settings_file)
+ elif settings_path:
+ if not os.path.exists(settings_path):
+ raise InvalidSettingsPath(settings_path)
+
+ settings_path = os.path.abspath(settings_path)
+ project_root, config_settings = _find_config(settings_path)
+ else:
+ config_settings = {}
+ project_root = os.getcwd()
+
+ profile_name = config_overrides.get("profile", config_settings.get("profile", ""))
+ profile: Dict[str, Any] = {}
+ if profile_name:
+ if profile_name not in profiles:
+ import pkg_resources
+
+ for plugin in pkg_resources.iter_entry_points("isort.profiles"):
+ profiles.setdefault(plugin.name, plugin.load())
+
+ if profile_name not in profiles:
+ raise ProfileDoesNotExist(profile_name)
+
+ profile = profiles[profile_name].copy()
+ profile["source"] = f"{profile_name} profile"
+ sources.append(profile)
+
+ if config_settings:
+ sources.append(config_settings)
+ if config_overrides:
+ config_overrides["source"] = RUNTIME_SOURCE
+ sources.append(config_overrides)
+
+ combined_config = {**profile, **config_settings, **config_overrides}
+ if "indent" in combined_config:
+ indent = str(combined_config["indent"])
+ if indent.isdigit():
+ indent = " " * int(indent)
+ else:
+ indent = indent.strip("'").strip('"')
+ if indent.lower() == "tab":
+ indent = "\t"
+ combined_config["indent"] = indent
+
+ known_other = {}
+ import_headings = {}
+ for key, value in tuple(combined_config.items()):
+ # Collect all known sections beyond those that have direct entries
+ if key.startswith(KNOWN_PREFIX) and key not in (
+ "known_standard_library",
+ "known_future_library",
+ "known_third_party",
+ "known_first_party",
+ "known_local_folder",
+ ):
+ import_heading = key[len(KNOWN_PREFIX) :].lower()
+ maps_to_section = import_heading.upper()
+ combined_config.pop(key)
+ if maps_to_section in KNOWN_SECTION_MAPPING:
+ section_name = f"known_{KNOWN_SECTION_MAPPING[maps_to_section].lower()}"
+ if section_name in combined_config and not self.quiet:
+ warn(
+ f"Can't set both {key} and {section_name} in the same config file.\n"
+ f"Default to {section_name} if unsure."
+ "\n\n"
+ "See: https://timothycrosley.github.io/isort/"
+ "#custom-sections-and-ordering."
+ )
+ else:
+ combined_config[section_name] = frozenset(value)
+ else:
+ known_other[import_heading] = frozenset(value)
+ if (
+ maps_to_section not in combined_config.get("sections", ())
+ and not self.quiet
+ ):
+ warn(
+ f"`{key}` setting is defined, but {maps_to_section} is not"
+ " included in `sections` config option:"
+ f" {combined_config.get('sections', SECTION_DEFAULTS)}.\n\n"
+ "See: https://timothycrosley.github.io/isort/"
+ "#custom-sections-and-ordering."
+ )
+ if key.startswith(IMPORT_HEADING_PREFIX):
+ import_headings[key[len(IMPORT_HEADING_PREFIX) :].lower()] = str(value)
+
+ # Coerce all provided config values into their correct type
+ default_value = _DEFAULT_SETTINGS.get(key, None)
+ if default_value is None:
+ continue
+
+ combined_config[key] = type(default_value)(value)
+
+ for section in combined_config.get("sections", ()):
+ if section in SECTION_DEFAULTS:
+ continue
+ elif not section.lower() in known_other:
+ config_keys = ", ".join(known_other.keys())
+ warn(
+ f"`sections` setting includes {section}, but no known_{section.lower()} "
+ "is defined. "
+ f"The following known_SECTION config options are defined: {config_keys}."
+ )
+
+ if "directory" not in combined_config:
+ combined_config["directory"] = (
+ os.path.dirname(config_settings["source"])
+ if config_settings.get("source", None)
+ else os.getcwd()
+ )
+
+ path_root = Path(combined_config.get("directory", project_root)).resolve()
+ path_root = path_root if path_root.is_dir() else path_root.parent
+ if "src_paths" not in combined_config:
+ combined_config["src_paths"] = frozenset((path_root, path_root / "src"))
+ else:
+ combined_config["src_paths"] = frozenset(
+ path_root / path for path in combined_config.get("src_paths", ())
+ )
+
+ if "formatter" in combined_config:
+ import pkg_resources
+
+ for plugin in pkg_resources.iter_entry_points("isort.formatters"):
+ if plugin.name == combined_config["formatter"]:
+ combined_config["formatting_function"] = plugin.load()
+ break
+ else:
+ raise FormattingPluginDoesNotExist(combined_config["formatter"])
+
+ # Remove any config values that are used for creating config object but
+ # aren't defined in dataclass
+ combined_config.pop("source", None)
+ combined_config.pop("sources", None)
+ combined_config.pop("runtime_src_paths", None)
+
+ deprecated_options_used = [
+ option for option in combined_config if option in DEPRECATED_SETTINGS
+ ]
+ if deprecated_options_used:
+ for deprecated_option in deprecated_options_used:
+ combined_config.pop(deprecated_option)
+ if not self.quiet:
+ warn(
+ "W0503: Deprecated config options were used: "
+ f"{', '.join(deprecated_options_used)}."
+ "Please see the 5.0.0 upgrade guide: bit.ly/isortv5."
+ )
+
+ if known_other:
+ combined_config["known_other"] = known_other
+ if import_headings:
+ for import_heading_key in import_headings:
+ combined_config.pop(f"{IMPORT_HEADING_PREFIX}{import_heading_key}")
+ combined_config["import_headings"] = import_headings
+
+ super().__init__(sources=tuple(sources), **combined_config) # type: ignore
+
+ def is_supported_filetype(self, file_name: str):
+ _root, ext = os.path.splitext(file_name)
+ ext = ext.lstrip(".")
+ if ext in self.supported_extensions:
+ return True
+ elif ext in self.blocked_extensions:
+ return False
+
+ # Skip editor backup files.
+ if file_name.endswith("~"):
+ return False
+
+ try:
+ if stat.S_ISFIFO(os.stat(file_name).st_mode):
+ return False
+ except OSError:
+ pass
+
+ try:
+ with open(file_name, "rb") as fp:
+ line = fp.readline(100)
+ except OSError:
+ return False
+ else:
+ return bool(_SHEBANG_RE.match(line))
+
+ def is_skipped(self, file_path: Path) -> bool:
+ """Returns True if the file and/or folder should be skipped based on current settings."""
+ if self.directory and Path(self.directory) in file_path.resolve().parents:
+ file_name = os.path.relpath(file_path.resolve(), self.directory)
+ else:
+ file_name = str(file_path)
+
+ os_path = str(file_path)
+
+ if self.skip_gitignore:
+ if file_path.name == ".git": # pragma: no cover
+ return True
+
+ result = subprocess.run( # nosec
+ ["git", "-C", str(file_path.parent), "check-ignore", "--quiet", os_path]
+ )
+ if result.returncode == 0:
+ return True
+
+ normalized_path = os_path.replace("\\", "/")
+ if normalized_path[1:2] == ":":
+ normalized_path = normalized_path[2:]
+
+ for skip_path in self.skip:
+ if posixpath.abspath(normalized_path) == posixpath.abspath(
+ skip_path.replace("\\", "/")
+ ):
+ return True
+
+ position = os.path.split(file_name)
+ while position[1]:
+ if position[1] in self.skip:
+ return True
+ position = os.path.split(position[0])
+
+ for glob in self.skip_glob:
+ if fnmatch.fnmatch(file_name, glob) or fnmatch.fnmatch("/" + file_name, glob):
+ return True
+
+ if not (os.path.isfile(os_path) or os.path.isdir(os_path) or os.path.islink(os_path)):
+ return True
+
+ return False
+
+ @property
+ def known_patterns(self):
+ if self._known_patterns is not None:
+ return self._known_patterns
+
+ self._known_patterns = []
+ for placement in reversed(self.sections):
+ known_placement = KNOWN_SECTION_MAPPING.get(placement, placement).lower()
+ config_key = f"{KNOWN_PREFIX}{known_placement}"
+ known_modules = getattr(self, config_key, self.known_other.get(known_placement, ()))
+ extra_modules = getattr(self, f"extra_{known_placement}", ())
+ all_modules = set(known_modules).union(extra_modules)
+ known_patterns = [
+ pattern
+ for known_pattern in all_modules
+ for pattern in self._parse_known_pattern(known_pattern)
+ ]
+ for known_pattern in known_patterns:
+ regexp = "^" + known_pattern.replace("*", ".*").replace("?", ".?") + "$"
+ self._known_patterns.append((re.compile(regexp), placement))
+
+ return self._known_patterns
+
+ @property
+ def section_comments(self) -> Tuple[str, ...]:
+ if self._section_comments is not None:
+ return self._section_comments
+
+ self._section_comments = tuple(f"# {heading}" for heading in self.import_headings.values())
+ return self._section_comments
+
+ def _parse_known_pattern(self, pattern: str) -> List[str]:
+ """Expand pattern if identified as a directory and return found sub packages"""
+ if pattern.endswith(os.path.sep):
+ patterns = [
+ filename
+ for filename in os.listdir(os.path.join(self.directory, pattern))
+ if os.path.isdir(os.path.join(self.directory, pattern, filename))
+ ]
+ else:
+ patterns = [pattern]
+
+ return patterns
+
+
+def _get_str_to_type_converter(setting_name: str) -> Callable[[str], Any]:
+ type_converter: Callable[[str], Any] = type(_DEFAULT_SETTINGS.get(setting_name, ""))
+ if type_converter == WrapModes:
+ type_converter = wrap_mode_from_string
+ return type_converter
+
+
+def _as_list(value: str) -> List[str]:
+ if isinstance(value, list):
+ return [item.strip() for item in value]
+ filtered = [item.strip() for item in value.replace("\n", ",").split(",") if item.strip()]
+ return filtered
+
+
+def _abspaths(cwd: str, values: Iterable[str]) -> Set[str]:
+ paths = {
+ os.path.join(cwd, value)
+ if not value.startswith(os.path.sep) and value.endswith(os.path.sep)
+ else value
+ for value in values
+ }
+ return paths
+
+
+@lru_cache()
+def _find_config(path: str) -> Tuple[str, Dict[str, Any]]:
+ current_directory = path
+ tries = 0
+ while current_directory and tries < MAX_CONFIG_SEARCH_DEPTH:
+ for config_file_name in CONFIG_SOURCES:
+ potential_config_file = os.path.join(current_directory, config_file_name)
+ if os.path.isfile(potential_config_file):
+ config_data: Dict[str, Any]
+ try:
+ config_data = _get_config_data(
+ potential_config_file, CONFIG_SECTIONS[config_file_name]
+ )
+ except Exception:
+ warn(f"Failed to pull configuration information from {potential_config_file}")
+ config_data = {}
+ if config_data:
+ return (current_directory, config_data)
+
+ for stop_dir in STOP_CONFIG_SEARCH_ON_DIRS:
+ if os.path.isdir(os.path.join(current_directory, stop_dir)):
+ return (current_directory, {})
+
+ new_directory = os.path.split(current_directory)[0]
+ if new_directory == current_directory:
+ break
+
+ current_directory = new_directory
+ tries += 1
+
+ return (path, {})
+
+
+@lru_cache()
+def _get_config_data(file_path: str, sections: Tuple[str]) -> Dict[str, Any]:
+ settings: Dict[str, Any] = {}
+
+ with open(file_path) as config_file:
+ if file_path.endswith(".toml"):
+ config = toml.load(config_file)
+ for section in sections:
+ config_section = config
+ for key in section.split("."):
+ config_section = config_section.get(key, {})
+ settings.update(config_section)
+ else:
+ if file_path.endswith(".editorconfig"):
+ line = "\n"
+ last_position = config_file.tell()
+ while line:
+ line = config_file.readline()
+ if "[" in line:
+ config_file.seek(last_position)
+ break
+ last_position = config_file.tell()
+
+ config = configparser.ConfigParser(strict=False)
+ config.read_file(config_file)
+ for section in sections:
+ if section.startswith("*.{") and section.endswith("}"):
+ extension = section[len("*.{") : -1]
+ for config_key in config.keys():
+ if config_key.startswith("*.{") and config_key.endswith("}"):
+ if extension in map(
+ lambda text: text.strip(), config_key[len("*.{") : -1].split(",")
+ ):
+ settings.update(config.items(config_key))
+
+ elif config.has_section(section):
+ settings.update(config.items(section))
+
+ if settings:
+ settings["source"] = file_path
+
+ if file_path.endswith(".editorconfig"):
+ indent_style = settings.pop("indent_style", "").strip()
+ indent_size = settings.pop("indent_size", "").strip()
+ if indent_size == "tab":
+ indent_size = settings.pop("tab_width", "").strip()
+
+ if indent_style == "space":
+ settings["indent"] = " " * (indent_size and int(indent_size) or 4)
+
+ elif indent_style == "tab":
+ settings["indent"] = "\t" * (indent_size and int(indent_size) or 1)
+
+ max_line_length = settings.pop("max_line_length", "").strip()
+ if max_line_length and (max_line_length == "off" or max_line_length.isdigit()):
+ settings["line_length"] = (
+ float("inf") if max_line_length == "off" else int(max_line_length)
+ )
+ settings = {
+ key: value
+ for key, value in settings.items()
+ if key in _DEFAULT_SETTINGS.keys() or key.startswith(KNOWN_PREFIX)
+ }
+
+ for key, value in settings.items():
+ existing_value_type = _get_str_to_type_converter(key)
+ if existing_value_type == tuple:
+ settings[key] = tuple(_as_list(value))
+ elif existing_value_type == frozenset:
+ settings[key] = frozenset(_as_list(settings.get(key))) # type: ignore
+ elif existing_value_type == bool:
+ # Only some configuration formats support native boolean values.
+ if not isinstance(value, bool):
+ value = _as_bool(value)
+ settings[key] = value
+ elif key.startswith(KNOWN_PREFIX):
+ settings[key] = _abspaths(os.path.dirname(file_path), _as_list(value))
+ elif key == "force_grid_wrap":
+ try:
+ result = existing_value_type(value)
+ except ValueError: # backwards compatibility for true / false force grid wrap
+ result = 0 if value.lower().strip() == "false" else 2
+ settings[key] = result
+ elif key == "comment_prefix":
+ settings[key] = str(value).strip("'").strip('"')
+ else:
+ settings[key] = existing_value_type(value)
+
+ return settings
+
+
+def _as_bool(value: str) -> bool:
+ """Given a string value that represents True or False, returns the Boolean equivalent.
+ Heavily inspired from distutils strtobool.
+ """
+ try:
+ return _STR_BOOLEAN_MAPPING[value.lower()]
+ except KeyError:
+ raise ValueError(f"invalid truth value {value}")
+
+
+DEFAULT_CONFIG = Config()
diff --git a/venv/Lib/site-packages/isort/setuptools_commands.py b/venv/Lib/site-packages/isort/setuptools_commands.py
new file mode 100644
index 0000000..f670088
--- /dev/null
+++ b/venv/Lib/site-packages/isort/setuptools_commands.py
@@ -0,0 +1,61 @@
+import glob
+import os
+import sys
+from typing import Any, Dict, Iterator, List
+from warnings import warn
+
+import setuptools
+
+from . import api
+from .settings import DEFAULT_CONFIG
+
+
+class ISortCommand(setuptools.Command):
+ """The :class:`ISortCommand` class is used by setuptools to perform
+ imports checks on registered modules.
+ """
+
+ description = "Run isort on modules registered in setuptools"
+ user_options: List[Any] = []
+
+ def initialize_options(self) -> None:
+ default_settings = vars(DEFAULT_CONFIG).copy()
+ for key, value in default_settings.items():
+ setattr(self, key, value)
+
+ def finalize_options(self) -> None:
+ "Get options from config files."
+ self.arguments: Dict[str, Any] = {} # skipcq: PYL-W0201
+ self.arguments["settings_path"] = os.getcwd()
+
+ def distribution_files(self) -> Iterator[str]:
+ """Find distribution packages."""
+ # This is verbatim from flake8
+ if self.distribution.packages:
+ package_dirs = self.distribution.package_dir or {}
+ for package in self.distribution.packages:
+ pkg_dir = package
+ if package in package_dirs:
+ pkg_dir = package_dirs[package]
+ elif "" in package_dirs:
+ pkg_dir = package_dirs[""] + os.path.sep + pkg_dir
+ yield pkg_dir.replace(".", os.path.sep)
+
+ if self.distribution.py_modules:
+ for filename in self.distribution.py_modules:
+ yield "%s.py" % filename
+ # Don't miss the setup.py file itself
+ yield "setup.py"
+
+ def run(self) -> None:
+ arguments = self.arguments
+ wrong_sorted_files = False
+ for path in self.distribution_files():
+ for python_file in glob.iglob(os.path.join(path, "*.py")):
+ try:
+ if not api.check_file(python_file, **arguments):
+ wrong_sorted_files = True # pragma: no cover
+ except OSError as error: # pragma: no cover
+ warn(f"Unable to parse file {python_file} due to {error}")
+ if wrong_sorted_files:
+ sys.exit(1) # pragma: no cover
diff --git a/venv/Lib/site-packages/isort/sorting.py b/venv/Lib/site-packages/isort/sorting.py
new file mode 100644
index 0000000..1664a2f
--- /dev/null
+++ b/venv/Lib/site-packages/isort/sorting.py
@@ -0,0 +1,93 @@
+import re
+from typing import Any, Callable, Iterable, List, Optional
+
+from .settings import Config
+
+_import_line_intro_re = re.compile("^(?:from|import) ")
+_import_line_midline_import_re = re.compile(" import ")
+
+
+def module_key(
+ module_name: str,
+ config: Config,
+ sub_imports: bool = False,
+ ignore_case: bool = False,
+ section_name: Optional[Any] = None,
+ straight_import: Optional[bool] = False,
+) -> str:
+ match = re.match(r"^(\.+)\s*(.*)", module_name)
+ if match:
+ sep = " " if config.reverse_relative else "_"
+ module_name = sep.join(match.groups())
+
+ prefix = ""
+ if ignore_case:
+ module_name = str(module_name).lower()
+ else:
+ module_name = str(module_name)
+
+ if sub_imports and config.order_by_type:
+ if module_name in config.constants:
+ prefix = "A"
+ elif module_name in config.classes:
+ prefix = "B"
+ elif module_name in config.variables:
+ prefix = "C"
+ elif module_name.isupper() and len(module_name) > 1: # see issue #376
+ prefix = "A"
+ elif module_name in config.classes or module_name[0:1].isupper():
+ prefix = "B"
+ else:
+ prefix = "C"
+ if not config.case_sensitive:
+ module_name = module_name.lower()
+
+ length_sort = (
+ config.length_sort
+ or (config.length_sort_straight and straight_import)
+ or str(section_name).lower() in config.length_sort_sections
+ )
+ _length_sort_maybe = length_sort and (str(len(module_name)) + ":" + module_name) or module_name
+ return f"{module_name in config.force_to_top and 'A' or 'B'}{prefix}{_length_sort_maybe}"
+
+
+def section_key(
+ line: str,
+ order_by_type: bool,
+ force_to_top: List[str],
+ lexicographical: bool = False,
+ length_sort: bool = False,
+) -> str:
+ section = "B"
+
+ if lexicographical:
+ line = _import_line_intro_re.sub("", _import_line_midline_import_re.sub(".", line))
+ else:
+ line = re.sub("^from ", "", line)
+ line = re.sub("^import ", "", line)
+ if line.split(" ")[0] in force_to_top:
+ section = "A"
+ if not order_by_type:
+ line = line.lower()
+
+ return f"{section}{len(line) if length_sort else ''}{line}"
+
+
+def naturally(to_sort: Iterable[str], key: Optional[Callable[[str], Any]] = None) -> List[str]:
+ """Returns a naturally sorted list"""
+ if key is None:
+ key_callback = _natural_keys
+ else:
+
+ def key_callback(text: str) -> List[Any]:
+ return _natural_keys(key(text)) # type: ignore
+
+ return sorted(to_sort, key=key_callback)
+
+
+def _atoi(text: str) -> Any:
+ return int(text) if text.isdigit() else text
+
+
+def _natural_keys(text: str) -> List[Any]:
+ return [_atoi(c) for c in re.split(r"(\d+)", text)]
diff --git a/venv/Lib/site-packages/isort/stdlibs/__init__.py b/venv/Lib/site-packages/isort/stdlibs/__init__.py
new file mode 100644
index 0000000..9021bc4
--- /dev/null
+++ b/venv/Lib/site-packages/isort/stdlibs/__init__.py
@@ -0,0 +1 @@
+from . import all, py2, py3, py27, py35, py36, py37, py38, py39
diff --git a/venv/Lib/site-packages/isort/stdlibs/all.py b/venv/Lib/site-packages/isort/stdlibs/all.py
new file mode 100644
index 0000000..08a365e
--- /dev/null
+++ b/venv/Lib/site-packages/isort/stdlibs/all.py
@@ -0,0 +1,3 @@
+from . import py2, py3
+
+stdlib = py2.stdlib | py3.stdlib
diff --git a/venv/Lib/site-packages/isort/stdlibs/py2.py b/venv/Lib/site-packages/isort/stdlibs/py2.py
new file mode 100644
index 0000000..74af019
--- /dev/null
+++ b/venv/Lib/site-packages/isort/stdlibs/py2.py
@@ -0,0 +1,3 @@
+from . import py27
+
+stdlib = py27.stdlib
diff --git a/venv/Lib/site-packages/isort/stdlibs/py27.py b/venv/Lib/site-packages/isort/stdlibs/py27.py
new file mode 100644
index 0000000..87aa67f
--- /dev/null
+++ b/venv/Lib/site-packages/isort/stdlibs/py27.py
@@ -0,0 +1,300 @@
+"""
+File contains the standard library of Python 2.7.
+
+DO NOT EDIT. If the standard library changes, a new list should be created
+using the mkstdlibs.py script.
+"""
+
+stdlib = {
+ "AL",
+ "BaseHTTPServer",
+ "Bastion",
+ "CGIHTTPServer",
+ "Carbon",
+ "ColorPicker",
+ "ConfigParser",
+ "Cookie",
+ "DEVICE",
+ "DocXMLRPCServer",
+ "EasyDialogs",
+ "FL",
+ "FrameWork",
+ "GL",
+ "HTMLParser",
+ "MacOS",
+ "MimeWriter",
+ "MiniAEFrame",
+ "Nav",
+ "PixMapWrapper",
+ "Queue",
+ "SUNAUDIODEV",
+ "ScrolledText",
+ "SimpleHTTPServer",
+ "SimpleXMLRPCServer",
+ "SocketServer",
+ "StringIO",
+ "Tix",
+ "Tkinter",
+ "UserDict",
+ "UserList",
+ "UserString",
+ "W",
+ "__builtin__",
+ "_winreg",
+ "abc",
+ "aepack",
+ "aetools",
+ "aetypes",
+ "aifc",
+ "al",
+ "anydbm",
+ "applesingle",
+ "argparse",
+ "array",
+ "ast",
+ "asynchat",
+ "asyncore",
+ "atexit",
+ "audioop",
+ "autoGIL",
+ "base64",
+ "bdb",
+ "binascii",
+ "binhex",
+ "bisect",
+ "bsddb",
+ "buildtools",
+ "bz2",
+ "cPickle",
+ "cProfile",
+ "cStringIO",
+ "calendar",
+ "cd",
+ "cfmfile",
+ "cgi",
+ "cgitb",
+ "chunk",
+ "cmath",
+ "cmd",
+ "code",
+ "codecs",
+ "codeop",
+ "collections",
+ "colorsys",
+ "commands",
+ "compileall",
+ "compiler",
+ "contextlib",
+ "cookielib",
+ "copy",
+ "copy_reg",
+ "crypt",
+ "csv",
+ "ctypes",
+ "curses",
+ "datetime",
+ "dbhash",
+ "dbm",
+ "decimal",
+ "difflib",
+ "dircache",
+ "dis",
+ "distutils",
+ "dl",
+ "doctest",
+ "dumbdbm",
+ "dummy_thread",
+ "dummy_threading",
+ "email",
+ "encodings",
+ "ensurepip",
+ "errno",
+ "exceptions",
+ "fcntl",
+ "filecmp",
+ "fileinput",
+ "findertools",
+ "fl",
+ "flp",
+ "fm",
+ "fnmatch",
+ "formatter",
+ "fpectl",
+ "fpformat",
+ "fractions",
+ "ftplib",
+ "functools",
+ "future_builtins",
+ "gc",
+ "gdbm",
+ "gensuitemodule",
+ "getopt",
+ "getpass",
+ "gettext",
+ "gl",
+ "glob",
+ "grp",
+ "gzip",
+ "hashlib",
+ "heapq",
+ "hmac",
+ "hotshot",
+ "htmlentitydefs",
+ "htmllib",
+ "httplib",
+ "ic",
+ "icopen",
+ "imageop",
+ "imaplib",
+ "imgfile",
+ "imghdr",
+ "imp",
+ "importlib",
+ "imputil",
+ "inspect",
+ "io",
+ "itertools",
+ "jpeg",
+ "json",
+ "keyword",
+ "lib2to3",
+ "linecache",
+ "locale",
+ "logging",
+ "macerrors",
+ "macostools",
+ "macpath",
+ "macresource",
+ "mailbox",
+ "mailcap",
+ "marshal",
+ "math",
+ "md5",
+ "mhlib",
+ "mimetools",
+ "mimetypes",
+ "mimify",
+ "mmap",
+ "modulefinder",
+ "msilib",
+ "msvcrt",
+ "multifile",
+ "multiprocessing",
+ "mutex",
+ "netrc",
+ "new",
+ "nis",
+ "nntplib",
+ "ntpath",
+ "numbers",
+ "operator",
+ "optparse",
+ "os",
+ "ossaudiodev",
+ "parser",
+ "pdb",
+ "pickle",
+ "pickletools",
+ "pipes",
+ "pkgutil",
+ "platform",
+ "plistlib",
+ "popen2",
+ "poplib",
+ "posix",
+ "posixfile",
+ "posixpath",
+ "pprint",
+ "profile",
+ "pstats",
+ "pty",
+ "pwd",
+ "py_compile",
+ "pyclbr",
+ "pydoc",
+ "quopri",
+ "random",
+ "re",
+ "readline",
+ "resource",
+ "rexec",
+ "rfc822",
+ "rlcompleter",
+ "robotparser",
+ "runpy",
+ "sched",
+ "select",
+ "sets",
+ "sgmllib",
+ "sha",
+ "shelve",
+ "shlex",
+ "shutil",
+ "signal",
+ "site",
+ "smtpd",
+ "smtplib",
+ "sndhdr",
+ "socket",
+ "spwd",
+ "sqlite3",
+ "sre",
+ "sre_compile",
+ "sre_constants",
+ "sre_parse",
+ "ssl",
+ "stat",
+ "statvfs",
+ "string",
+ "stringprep",
+ "struct",
+ "subprocess",
+ "sunau",
+ "sunaudiodev",
+ "symbol",
+ "symtable",
+ "sys",
+ "sysconfig",
+ "syslog",
+ "tabnanny",
+ "tarfile",
+ "telnetlib",
+ "tempfile",
+ "termios",
+ "test",
+ "textwrap",
+ "thread",
+ "threading",
+ "time",
+ "timeit",
+ "token",
+ "tokenize",
+ "trace",
+ "traceback",
+ "ttk",
+ "tty",
+ "turtle",
+ "types",
+ "unicodedata",
+ "unittest",
+ "urllib",
+ "urllib2",
+ "urlparse",
+ "user",
+ "uu",
+ "uuid",
+ "videoreader",
+ "warnings",
+ "wave",
+ "weakref",
+ "webbrowser",
+ "whichdb",
+ "winsound",
+ "wsgiref",
+ "xdrlib",
+ "xml",
+ "xmlrpclib",
+ "zipfile",
+ "zipimport",
+ "zlib",
+}
diff --git a/venv/Lib/site-packages/isort/stdlibs/py3.py b/venv/Lib/site-packages/isort/stdlibs/py3.py
new file mode 100644
index 0000000..78e0984
--- /dev/null
+++ b/venv/Lib/site-packages/isort/stdlibs/py3.py
@@ -0,0 +1,3 @@
+from . import py35, py36, py37, py38
+
+stdlib = py35.stdlib | py36.stdlib | py37.stdlib | py38.stdlib
diff --git a/venv/Lib/site-packages/isort/stdlibs/py35.py b/venv/Lib/site-packages/isort/stdlibs/py35.py
new file mode 100644
index 0000000..274d8a7
--- /dev/null
+++ b/venv/Lib/site-packages/isort/stdlibs/py35.py
@@ -0,0 +1,222 @@
+"""
+File contains the standard library of Python 3.5.
+
+DO NOT EDIT. If the standard library changes, a new list should be created
+using the mkstdlibs.py script.
+"""
+
+stdlib = {
+ "_dummy_thread",
+ "_thread",
+ "abc",
+ "aifc",
+ "argparse",
+ "array",
+ "ast",
+ "asynchat",
+ "asyncio",
+ "asyncore",
+ "atexit",
+ "audioop",
+ "base64",
+ "bdb",
+ "binascii",
+ "binhex",
+ "bisect",
+ "builtins",
+ "bz2",
+ "cProfile",
+ "calendar",
+ "cgi",
+ "cgitb",
+ "chunk",
+ "cmath",
+ "cmd",
+ "code",
+ "codecs",
+ "codeop",
+ "collections",
+ "colorsys",
+ "compileall",
+ "concurrent",
+ "configparser",
+ "contextlib",
+ "copy",
+ "copyreg",
+ "crypt",
+ "csv",
+ "ctypes",
+ "curses",
+ "datetime",
+ "dbm",
+ "decimal",
+ "difflib",
+ "dis",
+ "distutils",
+ "doctest",
+ "dummy_threading",
+ "email",
+ "encodings",
+ "ensurepip",
+ "enum",
+ "errno",
+ "faulthandler",
+ "fcntl",
+ "filecmp",
+ "fileinput",
+ "fnmatch",
+ "formatter",
+ "fpectl",
+ "fractions",
+ "ftplib",
+ "functools",
+ "gc",
+ "getopt",
+ "getpass",
+ "gettext",
+ "glob",
+ "grp",
+ "gzip",
+ "hashlib",
+ "heapq",
+ "hmac",
+ "html",
+ "http",
+ "imaplib",
+ "imghdr",
+ "imp",
+ "importlib",
+ "inspect",
+ "io",
+ "ipaddress",
+ "itertools",
+ "json",
+ "keyword",
+ "lib2to3",
+ "linecache",
+ "locale",
+ "logging",
+ "lzma",
+ "macpath",
+ "mailbox",
+ "mailcap",
+ "marshal",
+ "math",
+ "mimetypes",
+ "mmap",
+ "modulefinder",
+ "msilib",
+ "msvcrt",
+ "multiprocessing",
+ "netrc",
+ "nis",
+ "nntplib",
+ "ntpath",
+ "numbers",
+ "operator",
+ "optparse",
+ "os",
+ "ossaudiodev",
+ "parser",
+ "pathlib",
+ "pdb",
+ "pickle",
+ "pickletools",
+ "pipes",
+ "pkgutil",
+ "platform",
+ "plistlib",
+ "poplib",
+ "posix",
+ "posixpath",
+ "pprint",
+ "profile",
+ "pstats",
+ "pty",
+ "pwd",
+ "py_compile",
+ "pyclbr",
+ "pydoc",
+ "queue",
+ "quopri",
+ "random",
+ "re",
+ "readline",
+ "reprlib",
+ "resource",
+ "rlcompleter",
+ "runpy",
+ "sched",
+ "select",
+ "selectors",
+ "shelve",
+ "shlex",
+ "shutil",
+ "signal",
+ "site",
+ "smtpd",
+ "smtplib",
+ "sndhdr",
+ "socket",
+ "socketserver",
+ "spwd",
+ "sqlite3",
+ "sre",
+ "sre_compile",
+ "sre_constants",
+ "sre_parse",
+ "ssl",
+ "stat",
+ "statistics",
+ "string",
+ "stringprep",
+ "struct",
+ "subprocess",
+ "sunau",
+ "symbol",
+ "symtable",
+ "sys",
+ "sysconfig",
+ "syslog",
+ "tabnanny",
+ "tarfile",
+ "telnetlib",
+ "tempfile",
+ "termios",
+ "test",
+ "textwrap",
+ "threading",
+ "time",
+ "timeit",
+ "tkinter",
+ "token",
+ "tokenize",
+ "trace",
+ "traceback",
+ "tracemalloc",
+ "tty",
+ "turtle",
+ "turtledemo",
+ "types",
+ "typing",
+ "unicodedata",
+ "unittest",
+ "urllib",
+ "uu",
+ "uuid",
+ "venv",
+ "warnings",
+ "wave",
+ "weakref",
+ "webbrowser",
+ "winreg",
+ "winsound",
+ "wsgiref",
+ "xdrlib",
+ "xml",
+ "xmlrpc",
+ "zipapp",
+ "zipfile",
+ "zipimport",
+ "zlib",
+}
diff --git a/venv/Lib/site-packages/isort/stdlibs/py36.py b/venv/Lib/site-packages/isort/stdlibs/py36.py
new file mode 100644
index 0000000..8ae02a1
--- /dev/null
+++ b/venv/Lib/site-packages/isort/stdlibs/py36.py
@@ -0,0 +1,223 @@
+"""
+File contains the standard library of Python 3.6.
+
+DO NOT EDIT. If the standard library changes, a new list should be created
+using the mkstdlibs.py script.
+"""
+
+stdlib = {
+ "_dummy_thread",
+ "_thread",
+ "abc",
+ "aifc",
+ "argparse",
+ "array",
+ "ast",
+ "asynchat",
+ "asyncio",
+ "asyncore",
+ "atexit",
+ "audioop",
+ "base64",
+ "bdb",
+ "binascii",
+ "binhex",
+ "bisect",
+ "builtins",
+ "bz2",
+ "cProfile",
+ "calendar",
+ "cgi",
+ "cgitb",
+ "chunk",
+ "cmath",
+ "cmd",
+ "code",
+ "codecs",
+ "codeop",
+ "collections",
+ "colorsys",
+ "compileall",
+ "concurrent",
+ "configparser",
+ "contextlib",
+ "copy",
+ "copyreg",
+ "crypt",
+ "csv",
+ "ctypes",
+ "curses",
+ "datetime",
+ "dbm",
+ "decimal",
+ "difflib",
+ "dis",
+ "distutils",
+ "doctest",
+ "dummy_threading",
+ "email",
+ "encodings",
+ "ensurepip",
+ "enum",
+ "errno",
+ "faulthandler",
+ "fcntl",
+ "filecmp",
+ "fileinput",
+ "fnmatch",
+ "formatter",
+ "fpectl",
+ "fractions",
+ "ftplib",
+ "functools",
+ "gc",
+ "getopt",
+ "getpass",
+ "gettext",
+ "glob",
+ "grp",
+ "gzip",
+ "hashlib",
+ "heapq",
+ "hmac",
+ "html",
+ "http",
+ "imaplib",
+ "imghdr",
+ "imp",
+ "importlib",
+ "inspect",
+ "io",
+ "ipaddress",
+ "itertools",
+ "json",
+ "keyword",
+ "lib2to3",
+ "linecache",
+ "locale",
+ "logging",
+ "lzma",
+ "macpath",
+ "mailbox",
+ "mailcap",
+ "marshal",
+ "math",
+ "mimetypes",
+ "mmap",
+ "modulefinder",
+ "msilib",
+ "msvcrt",
+ "multiprocessing",
+ "netrc",
+ "nis",
+ "nntplib",
+ "ntpath",
+ "numbers",
+ "operator",
+ "optparse",
+ "os",
+ "ossaudiodev",
+ "parser",
+ "pathlib",
+ "pdb",
+ "pickle",
+ "pickletools",
+ "pipes",
+ "pkgutil",
+ "platform",
+ "plistlib",
+ "poplib",
+ "posix",
+ "posixpath",
+ "pprint",
+ "profile",
+ "pstats",
+ "pty",
+ "pwd",
+ "py_compile",
+ "pyclbr",
+ "pydoc",
+ "queue",
+ "quopri",
+ "random",
+ "re",
+ "readline",
+ "reprlib",
+ "resource",
+ "rlcompleter",
+ "runpy",
+ "sched",
+ "secrets",
+ "select",
+ "selectors",
+ "shelve",
+ "shlex",
+ "shutil",
+ "signal",
+ "site",
+ "smtpd",
+ "smtplib",
+ "sndhdr",
+ "socket",
+ "socketserver",
+ "spwd",
+ "sqlite3",
+ "sre",
+ "sre_compile",
+ "sre_constants",
+ "sre_parse",
+ "ssl",
+ "stat",
+ "statistics",
+ "string",
+ "stringprep",
+ "struct",
+ "subprocess",
+ "sunau",
+ "symbol",
+ "symtable",
+ "sys",
+ "sysconfig",
+ "syslog",
+ "tabnanny",
+ "tarfile",
+ "telnetlib",
+ "tempfile",
+ "termios",
+ "test",
+ "textwrap",
+ "threading",
+ "time",
+ "timeit",
+ "tkinter",
+ "token",
+ "tokenize",
+ "trace",
+ "traceback",
+ "tracemalloc",
+ "tty",
+ "turtle",
+ "turtledemo",
+ "types",
+ "typing",
+ "unicodedata",
+ "unittest",
+ "urllib",
+ "uu",
+ "uuid",
+ "venv",
+ "warnings",
+ "wave",
+ "weakref",
+ "webbrowser",
+ "winreg",
+ "winsound",
+ "wsgiref",
+ "xdrlib",
+ "xml",
+ "xmlrpc",
+ "zipapp",
+ "zipfile",
+ "zipimport",
+ "zlib",
+}
diff --git a/venv/Lib/site-packages/isort/stdlibs/py37.py b/venv/Lib/site-packages/isort/stdlibs/py37.py
new file mode 100644
index 0000000..0eb1dd6
--- /dev/null
+++ b/venv/Lib/site-packages/isort/stdlibs/py37.py
@@ -0,0 +1,224 @@
+"""
+File contains the standard library of Python 3.7.
+
+DO NOT EDIT. If the standard library changes, a new list should be created
+using the mkstdlibs.py script.
+"""
+
+stdlib = {
+ "_dummy_thread",
+ "_thread",
+ "abc",
+ "aifc",
+ "argparse",
+ "array",
+ "ast",
+ "asynchat",
+ "asyncio",
+ "asyncore",
+ "atexit",
+ "audioop",
+ "base64",
+ "bdb",
+ "binascii",
+ "binhex",
+ "bisect",
+ "builtins",
+ "bz2",
+ "cProfile",
+ "calendar",
+ "cgi",
+ "cgitb",
+ "chunk",
+ "cmath",
+ "cmd",
+ "code",
+ "codecs",
+ "codeop",
+ "collections",
+ "colorsys",
+ "compileall",
+ "concurrent",
+ "configparser",
+ "contextlib",
+ "contextvars",
+ "copy",
+ "copyreg",
+ "crypt",
+ "csv",
+ "ctypes",
+ "curses",
+ "dataclasses",
+ "datetime",
+ "dbm",
+ "decimal",
+ "difflib",
+ "dis",
+ "distutils",
+ "doctest",
+ "dummy_threading",
+ "email",
+ "encodings",
+ "ensurepip",
+ "enum",
+ "errno",
+ "faulthandler",
+ "fcntl",
+ "filecmp",
+ "fileinput",
+ "fnmatch",
+ "formatter",
+ "fractions",
+ "ftplib",
+ "functools",
+ "gc",
+ "getopt",
+ "getpass",
+ "gettext",
+ "glob",
+ "grp",
+ "gzip",
+ "hashlib",
+ "heapq",
+ "hmac",
+ "html",
+ "http",
+ "imaplib",
+ "imghdr",
+ "imp",
+ "importlib",
+ "inspect",
+ "io",
+ "ipaddress",
+ "itertools",
+ "json",
+ "keyword",
+ "lib2to3",
+ "linecache",
+ "locale",
+ "logging",
+ "lzma",
+ "macpath",
+ "mailbox",
+ "mailcap",
+ "marshal",
+ "math",
+ "mimetypes",
+ "mmap",
+ "modulefinder",
+ "msilib",
+ "msvcrt",
+ "multiprocessing",
+ "netrc",
+ "nis",
+ "nntplib",
+ "ntpath",
+ "numbers",
+ "operator",
+ "optparse",
+ "os",
+ "ossaudiodev",
+ "parser",
+ "pathlib",
+ "pdb",
+ "pickle",
+ "pickletools",
+ "pipes",
+ "pkgutil",
+ "platform",
+ "plistlib",
+ "poplib",
+ "posix",
+ "posixpath",
+ "pprint",
+ "profile",
+ "pstats",
+ "pty",
+ "pwd",
+ "py_compile",
+ "pyclbr",
+ "pydoc",
+ "queue",
+ "quopri",
+ "random",
+ "re",
+ "readline",
+ "reprlib",
+ "resource",
+ "rlcompleter",
+ "runpy",
+ "sched",
+ "secrets",
+ "select",
+ "selectors",
+ "shelve",
+ "shlex",
+ "shutil",
+ "signal",
+ "site",
+ "smtpd",
+ "smtplib",
+ "sndhdr",
+ "socket",
+ "socketserver",
+ "spwd",
+ "sqlite3",
+ "sre",
+ "sre_compile",
+ "sre_constants",
+ "sre_parse",
+ "ssl",
+ "stat",
+ "statistics",
+ "string",
+ "stringprep",
+ "struct",
+ "subprocess",
+ "sunau",
+ "symbol",
+ "symtable",
+ "sys",
+ "sysconfig",
+ "syslog",
+ "tabnanny",
+ "tarfile",
+ "telnetlib",
+ "tempfile",
+ "termios",
+ "test",
+ "textwrap",
+ "threading",
+ "time",
+ "timeit",
+ "tkinter",
+ "token",
+ "tokenize",
+ "trace",
+ "traceback",
+ "tracemalloc",
+ "tty",
+ "turtle",
+ "turtledemo",
+ "types",
+ "typing",
+ "unicodedata",
+ "unittest",
+ "urllib",
+ "uu",
+ "uuid",
+ "venv",
+ "warnings",
+ "wave",
+ "weakref",
+ "webbrowser",
+ "winreg",
+ "winsound",
+ "wsgiref",
+ "xdrlib",
+ "xml",
+ "xmlrpc",
+ "zipapp",
+ "zipfile",
+ "zipimport",
+ "zlib",
+}
diff --git a/venv/Lib/site-packages/isort/stdlibs/py38.py b/venv/Lib/site-packages/isort/stdlibs/py38.py
new file mode 100644
index 0000000..9bcea9a
--- /dev/null
+++ b/venv/Lib/site-packages/isort/stdlibs/py38.py
@@ -0,0 +1,223 @@
+"""
+File contains the standard library of Python 3.8.
+
+DO NOT EDIT. If the standard library changes, a new list should be created
+using the mkstdlibs.py script.
+"""
+
+stdlib = {
+ "_dummy_thread",
+ "_thread",
+ "abc",
+ "aifc",
+ "argparse",
+ "array",
+ "ast",
+ "asynchat",
+ "asyncio",
+ "asyncore",
+ "atexit",
+ "audioop",
+ "base64",
+ "bdb",
+ "binascii",
+ "binhex",
+ "bisect",
+ "builtins",
+ "bz2",
+ "cProfile",
+ "calendar",
+ "cgi",
+ "cgitb",
+ "chunk",
+ "cmath",
+ "cmd",
+ "code",
+ "codecs",
+ "codeop",
+ "collections",
+ "colorsys",
+ "compileall",
+ "concurrent",
+ "configparser",
+ "contextlib",
+ "contextvars",
+ "copy",
+ "copyreg",
+ "crypt",
+ "csv",
+ "ctypes",
+ "curses",
+ "dataclasses",
+ "datetime",
+ "dbm",
+ "decimal",
+ "difflib",
+ "dis",
+ "distutils",
+ "doctest",
+ "dummy_threading",
+ "email",
+ "encodings",
+ "ensurepip",
+ "enum",
+ "errno",
+ "faulthandler",
+ "fcntl",
+ "filecmp",
+ "fileinput",
+ "fnmatch",
+ "formatter",
+ "fractions",
+ "ftplib",
+ "functools",
+ "gc",
+ "getopt",
+ "getpass",
+ "gettext",
+ "glob",
+ "grp",
+ "gzip",
+ "hashlib",
+ "heapq",
+ "hmac",
+ "html",
+ "http",
+ "imaplib",
+ "imghdr",
+ "imp",
+ "importlib",
+ "inspect",
+ "io",
+ "ipaddress",
+ "itertools",
+ "json",
+ "keyword",
+ "lib2to3",
+ "linecache",
+ "locale",
+ "logging",
+ "lzma",
+ "mailbox",
+ "mailcap",
+ "marshal",
+ "math",
+ "mimetypes",
+ "mmap",
+ "modulefinder",
+ "msilib",
+ "msvcrt",
+ "multiprocessing",
+ "netrc",
+ "nis",
+ "nntplib",
+ "ntpath",
+ "numbers",
+ "operator",
+ "optparse",
+ "os",
+ "ossaudiodev",
+ "parser",
+ "pathlib",
+ "pdb",
+ "pickle",
+ "pickletools",
+ "pipes",
+ "pkgutil",
+ "platform",
+ "plistlib",
+ "poplib",
+ "posix",
+ "posixpath",
+ "pprint",
+ "profile",
+ "pstats",
+ "pty",
+ "pwd",
+ "py_compile",
+ "pyclbr",
+ "pydoc",
+ "queue",
+ "quopri",
+ "random",
+ "re",
+ "readline",
+ "reprlib",
+ "resource",
+ "rlcompleter",
+ "runpy",
+ "sched",
+ "secrets",
+ "select",
+ "selectors",
+ "shelve",
+ "shlex",
+ "shutil",
+ "signal",
+ "site",
+ "smtpd",
+ "smtplib",
+ "sndhdr",
+ "socket",
+ "socketserver",
+ "spwd",
+ "sqlite3",
+ "sre",
+ "sre_compile",
+ "sre_constants",
+ "sre_parse",
+ "ssl",
+ "stat",
+ "statistics",
+ "string",
+ "stringprep",
+ "struct",
+ "subprocess",
+ "sunau",
+ "symbol",
+ "symtable",
+ "sys",
+ "sysconfig",
+ "syslog",
+ "tabnanny",
+ "tarfile",
+ "telnetlib",
+ "tempfile",
+ "termios",
+ "test",
+ "textwrap",
+ "threading",
+ "time",
+ "timeit",
+ "tkinter",
+ "token",
+ "tokenize",
+ "trace",
+ "traceback",
+ "tracemalloc",
+ "tty",
+ "turtle",
+ "turtledemo",
+ "types",
+ "typing",
+ "unicodedata",
+ "unittest",
+ "urllib",
+ "uu",
+ "uuid",
+ "venv",
+ "warnings",
+ "wave",
+ "weakref",
+ "webbrowser",
+ "winreg",
+ "winsound",
+ "wsgiref",
+ "xdrlib",
+ "xml",
+ "xmlrpc",
+ "zipapp",
+ "zipfile",
+ "zipimport",
+ "zlib",
+}
diff --git a/venv/Lib/site-packages/isort/stdlibs/py39.py b/venv/Lib/site-packages/isort/stdlibs/py39.py
new file mode 100644
index 0000000..7bcb8f2
--- /dev/null
+++ b/venv/Lib/site-packages/isort/stdlibs/py39.py
@@ -0,0 +1,223 @@
+"""
+File contains the standard library of Python 3.9.
+
+DO NOT EDIT. If the standard library changes, a new list should be created
+using the mkstdlibs.py script.
+"""
+
+stdlib = {
+ "_thread",
+ "abc",
+ "aifc",
+ "argparse",
+ "array",
+ "ast",
+ "asynchat",
+ "asyncio",
+ "asyncore",
+ "atexit",
+ "audioop",
+ "base64",
+ "bdb",
+ "binascii",
+ "binhex",
+ "bisect",
+ "builtins",
+ "bz2",
+ "cProfile",
+ "calendar",
+ "cgi",
+ "cgitb",
+ "chunk",
+ "cmath",
+ "cmd",
+ "code",
+ "codecs",
+ "codeop",
+ "collections",
+ "colorsys",
+ "compileall",
+ "concurrent",
+ "configparser",
+ "contextlib",
+ "contextvars",
+ "copy",
+ "copyreg",
+ "crypt",
+ "csv",
+ "ctypes",
+ "curses",
+ "dataclasses",
+ "datetime",
+ "dbm",
+ "decimal",
+ "difflib",
+ "dis",
+ "distutils",
+ "doctest",
+ "email",
+ "encodings",
+ "ensurepip",
+ "enum",
+ "errno",
+ "faulthandler",
+ "fcntl",
+ "filecmp",
+ "fileinput",
+ "fnmatch",
+ "formatter",
+ "fractions",
+ "ftplib",
+ "functools",
+ "gc",
+ "getopt",
+ "getpass",
+ "gettext",
+ "glob",
+ "graphlib",
+ "grp",
+ "gzip",
+ "hashlib",
+ "heapq",
+ "hmac",
+ "html",
+ "http",
+ "imaplib",
+ "imghdr",
+ "imp",
+ "importlib",
+ "inspect",
+ "io",
+ "ipaddress",
+ "itertools",
+ "json",
+ "keyword",
+ "lib2to3",
+ "linecache",
+ "locale",
+ "logging",
+ "lzma",
+ "mailbox",
+ "mailcap",
+ "marshal",
+ "math",
+ "mimetypes",
+ "mmap",
+ "modulefinder",
+ "msilib",
+ "msvcrt",
+ "multiprocessing",
+ "netrc",
+ "nis",
+ "nntplib",
+ "ntpath",
+ "numbers",
+ "operator",
+ "optparse",
+ "os",
+ "ossaudiodev",
+ "parser",
+ "pathlib",
+ "pdb",
+ "pickle",
+ "pickletools",
+ "pipes",
+ "pkgutil",
+ "platform",
+ "plistlib",
+ "poplib",
+ "posix",
+ "posixpath",
+ "pprint",
+ "profile",
+ "pstats",
+ "pty",
+ "pwd",
+ "py_compile",
+ "pyclbr",
+ "pydoc",
+ "queue",
+ "quopri",
+ "random",
+ "re",
+ "readline",
+ "reprlib",
+ "resource",
+ "rlcompleter",
+ "runpy",
+ "sched",
+ "secrets",
+ "select",
+ "selectors",
+ "shelve",
+ "shlex",
+ "shutil",
+ "signal",
+ "site",
+ "smtpd",
+ "smtplib",
+ "sndhdr",
+ "socket",
+ "socketserver",
+ "spwd",
+ "sqlite3",
+ "sre",
+ "sre_compile",
+ "sre_constants",
+ "sre_parse",
+ "ssl",
+ "stat",
+ "statistics",
+ "string",
+ "stringprep",
+ "struct",
+ "subprocess",
+ "sunau",
+ "symbol",
+ "symtable",
+ "sys",
+ "sysconfig",
+ "syslog",
+ "tabnanny",
+ "tarfile",
+ "telnetlib",
+ "tempfile",
+ "termios",
+ "test",
+ "textwrap",
+ "threading",
+ "time",
+ "timeit",
+ "tkinter",
+ "token",
+ "tokenize",
+ "trace",
+ "traceback",
+ "tracemalloc",
+ "tty",
+ "turtle",
+ "turtledemo",
+ "types",
+ "typing",
+ "unicodedata",
+ "unittest",
+ "urllib",
+ "uu",
+ "uuid",
+ "venv",
+ "warnings",
+ "wave",
+ "weakref",
+ "webbrowser",
+ "winreg",
+ "winsound",
+ "wsgiref",
+ "xdrlib",
+ "xml",
+ "xmlrpc",
+ "zipapp",
+ "zipfile",
+ "zipimport",
+ "zlib",
+ "zoneinfo",
+}
diff --git a/venv/Lib/site-packages/isort/utils.py b/venv/Lib/site-packages/isort/utils.py
new file mode 100644
index 0000000..27f17b4
--- /dev/null
+++ b/venv/Lib/site-packages/isort/utils.py
@@ -0,0 +1,29 @@
+import os
+import sys
+from contextlib import contextmanager
+from typing import Iterator
+
+
+def exists_case_sensitive(path: str) -> bool:
+ """Returns if the given path exists and also matches the case on Windows.
+
+ When finding files that can be imported, it is important for the cases to match because while
+ file os.path.exists("module.py") and os.path.exists("MODULE.py") both return True on Windows,
+ Python can only import using the case of the real file.
+ """
+ result = os.path.exists(path)
+ if (sys.platform.startswith("win") or sys.platform == "darwin") and result: # pragma: no cover
+ directory, basename = os.path.split(path)
+ result = basename in os.listdir(directory)
+ return result
+
+
+@contextmanager
+def chdir(path: str) -> Iterator[None]:
+ """Context manager for changing dir and restoring previous workdir after exit."""
+ curdir = os.getcwd()
+ os.chdir(path)
+ try:
+ yield
+ finally:
+ os.chdir(curdir)
diff --git a/venv/Lib/site-packages/isort/wrap.py b/venv/Lib/site-packages/isort/wrap.py
new file mode 100644
index 0000000..872b096
--- /dev/null
+++ b/venv/Lib/site-packages/isort/wrap.py
@@ -0,0 +1,123 @@
+import copy
+import re
+from typing import List, Optional, Sequence
+
+from .settings import DEFAULT_CONFIG, Config
+from .wrap_modes import WrapModes as Modes
+from .wrap_modes import formatter_from_string
+
+
+def import_statement(
+ import_start: str,
+ from_imports: List[str],
+ comments: Sequence[str] = (),
+ line_separator: str = "\n",
+ config: Config = DEFAULT_CONFIG,
+ multi_line_output: Optional[Modes] = None,
+) -> str:
+ """Returns a multi-line wrapped form of the provided from import statement."""
+ formatter = formatter_from_string((multi_line_output or config.multi_line_output).name)
+ dynamic_indent = " " * (len(import_start) + 1)
+ indent = config.indent
+ line_length = config.wrap_length or config.line_length
+ statement = formatter(
+ statement=import_start,
+ imports=copy.copy(from_imports),
+ white_space=dynamic_indent,
+ indent=indent,
+ line_length=line_length,
+ comments=comments,
+ line_separator=line_separator,
+ comment_prefix=config.comment_prefix,
+ include_trailing_comma=config.include_trailing_comma,
+ remove_comments=config.ignore_comments,
+ )
+ if config.balanced_wrapping:
+ lines = statement.split(line_separator)
+ line_count = len(lines)
+ if len(lines) > 1:
+ minimum_length = min(len(line) for line in lines[:-1])
+ else:
+ minimum_length = 0
+ new_import_statement = statement
+ while len(lines[-1]) < minimum_length and len(lines) == line_count and line_length > 10:
+ statement = new_import_statement
+ line_length -= 1
+ new_import_statement = formatter(
+ statement=import_start,
+ imports=copy.copy(from_imports),
+ white_space=dynamic_indent,
+ indent=indent,
+ line_length=line_length,
+ comments=comments,
+ line_separator=line_separator,
+ comment_prefix=config.comment_prefix,
+ include_trailing_comma=config.include_trailing_comma,
+ remove_comments=config.ignore_comments,
+ )
+ lines = new_import_statement.split(line_separator)
+ if statement.count(line_separator) == 0:
+ return _wrap_line(statement, line_separator, config)
+ return statement
+
+
+def line(content: str, line_separator: str, config: Config = DEFAULT_CONFIG) -> str:
+ """Returns a line wrapped to the specified line-length, if possible."""
+ wrap_mode = config.multi_line_output
+ if len(content) > config.line_length and wrap_mode != Modes.NOQA: # type: ignore
+ line_without_comment = content
+ comment = None
+ if "#" in content:
+ line_without_comment, comment = content.split("#", 1)
+ for splitter in ("import ", ".", "as "):
+ exp = r"\b" + re.escape(splitter) + r"\b"
+ if re.search(exp, line_without_comment) and not line_without_comment.strip().startswith(
+ splitter
+ ):
+ line_parts = re.split(exp, line_without_comment)
+ if comment:
+ _comma_maybe = (
+ "," if (config.include_trailing_comma and config.use_parentheses) else ""
+ )
+ line_parts[-1] = f"{line_parts[-1].strip()}{_comma_maybe} #{comment}"
+ next_line = []
+ while (len(content) + 2) > (
+ config.wrap_length or config.line_length
+ ) and line_parts:
+ next_line.append(line_parts.pop())
+ content = splitter.join(line_parts)
+ if not content:
+ content = next_line.pop()
+
+ cont_line = _wrap_line(
+ config.indent + splitter.join(next_line).lstrip(), line_separator, config
+ )
+ if config.use_parentheses:
+ if splitter == "as ":
+ output = f"{content}{splitter}{cont_line.lstrip()}"
+ else:
+ _comma = "," if config.include_trailing_comma and not comment else ""
+ if wrap_mode in (
+ Modes.VERTICAL_HANGING_INDENT, # type: ignore
+ Modes.VERTICAL_GRID_GROUPED, # type: ignore
+ ):
+ _separator = line_separator
+ else:
+ _separator = ""
+ output = (
+ f"{content}{splitter}({line_separator}{cont_line}{_comma}{_separator})"
+ )
+ lines = output.split(line_separator)
+ if config.comment_prefix in lines[-1] and lines[-1].endswith(")"):
+ content, comment = lines[-1].split(config.comment_prefix, 1)
+ lines[-1] = content + ")" + config.comment_prefix + comment[:-1]
+ return line_separator.join(lines)
+ return f"{content}{splitter}\\{line_separator}{cont_line}"
+ elif len(content) > config.line_length and wrap_mode == Modes.NOQA: # type: ignore
+ if "# NOQA" not in content:
+ return f"{content}{config.comment_prefix} NOQA"
+
+ return content
+
+
+_wrap_line = line
diff --git a/venv/Lib/site-packages/isort/wrap_modes.py b/venv/Lib/site-packages/isort/wrap_modes.py
new file mode 100644
index 0000000..92a63c3
--- /dev/null
+++ b/venv/Lib/site-packages/isort/wrap_modes.py
@@ -0,0 +1,311 @@
+"""Defines all wrap modes that can be used when outputting formatted imports"""
+import enum
+from inspect import signature
+from typing import Any, Callable, Dict, List
+
+import isort.comments
+
+_wrap_modes: Dict[str, Callable[[Any], str]] = {}
+
+
+def from_string(value: str) -> "WrapModes":
+ return getattr(WrapModes, str(value), None) or WrapModes(int(value))
+
+
+def formatter_from_string(name: str):
+ return _wrap_modes.get(name.upper(), grid)
+
+
+def _wrap_mode_interface(
+ statement: str,
+ imports: List[str],
+ white_space: str,
+ indent: str,
+ line_length: int,
+ comments: List[str],
+ line_separator: str,
+ comment_prefix: str,
+ include_trailing_comma: bool,
+ remove_comments: bool,
+) -> str:
+ """Defines the common interface used by all wrap mode functions"""
+ return ""
+
+
+def _wrap_mode(function):
+ """Registers an individual wrap mode. Function name and order are significant and used for
+ creating enum.
+ """
+ _wrap_modes[function.__name__.upper()] = function
+ function.__signature__ = signature(_wrap_mode_interface)
+ function.__annotations__ = _wrap_mode_interface.__annotations__
+ return function
+
+
+@_wrap_mode
+def grid(**interface):
+ if not interface["imports"]:
+ return ""
+
+ interface["statement"] += "(" + interface["imports"].pop(0)
+ while interface["imports"]:
+ next_import = interface["imports"].pop(0)
+ next_statement = isort.comments.add_to_line(
+ interface["comments"],
+ interface["statement"] + ", " + next_import,
+ removed=interface["remove_comments"],
+ comment_prefix=interface["comment_prefix"],
+ )
+ if (
+ len(next_statement.split(interface["line_separator"])[-1]) + 1
+ > interface["line_length"]
+ ):
+ lines = [f"{interface['white_space']}{next_import.split(' ')[0]}"]
+ for part in next_import.split(" ")[1:]:
+ new_line = f"{lines[-1]} {part}"
+ if len(new_line) + 1 > interface["line_length"]:
+ lines.append(f"{interface['white_space']}{part}")
+ else:
+ lines[-1] = new_line
+ next_import = interface["line_separator"].join(lines)
+ interface["statement"] = (
+ isort.comments.add_to_line(
+ interface["comments"],
+ f"{interface['statement']},",
+ removed=interface["remove_comments"],
+ comment_prefix=interface["comment_prefix"],
+ )
+ + f"{interface['line_separator']}{next_import}"
+ )
+ interface["comments"] = []
+ else:
+ interface["statement"] += ", " + next_import
+ return interface["statement"] + ("," if interface["include_trailing_comma"] else "") + ")"
+
+
+@_wrap_mode
+def vertical(**interface):
+ if not interface["imports"]:
+ return ""
+
+ first_import = (
+ isort.comments.add_to_line(
+ interface["comments"],
+ interface["imports"].pop(0) + ",",
+ removed=interface["remove_comments"],
+ comment_prefix=interface["comment_prefix"],
+ )
+ + interface["line_separator"]
+ + interface["white_space"]
+ )
+
+ _imports = ("," + interface["line_separator"] + interface["white_space"]).join(
+ interface["imports"]
+ )
+ _comma_maybe = "," if interface["include_trailing_comma"] else ""
+ return f"{interface['statement']}({first_import}{_imports}{_comma_maybe})"
+
+
+def _hanging_indent_common(use_parentheses=False, **interface):
+ if not interface["imports"]:
+ return ""
+ line_length_limit = interface["line_length"] - (1 if use_parentheses else 3)
+
+ def end_line(line):
+ if use_parentheses:
+ return line
+ if not line.endswith(" "):
+ line += " "
+ return line + "\\"
+
+ if use_parentheses:
+ interface["statement"] += "("
+ next_import = interface["imports"].pop(0)
+ next_statement = interface["statement"] + next_import
+ # Check for first import
+ if len(next_statement) > line_length_limit:
+ next_statement = (
+ isort.comments.add_to_line(
+ interface["comments"],
+ end_line(interface["statement"]),
+ removed=interface["remove_comments"],
+ comment_prefix=interface["comment_prefix"],
+ )
+ + f"{interface['line_separator']}{interface['indent']}{next_import}"
+ )
+ interface["comments"] = []
+ interface["statement"] = next_statement
+ while interface["imports"]:
+ next_import = interface["imports"].pop(0)
+ next_statement = isort.comments.add_to_line(
+ interface["comments"],
+ interface["statement"] + ", " + next_import,
+ removed=interface["remove_comments"],
+ comment_prefix=interface["comment_prefix"],
+ )
+ current_line = next_statement.split(interface["line_separator"])[-1]
+ if len(current_line) > line_length_limit:
+ next_statement = (
+ isort.comments.add_to_line(
+ interface["comments"],
+ end_line(interface["statement"] + ","),
+ removed=interface["remove_comments"],
+ comment_prefix=interface["comment_prefix"],
+ )
+ + f"{interface['line_separator']}{interface['indent']}{next_import}"
+ )
+ interface["comments"] = []
+ interface["statement"] = next_statement
+ _comma_maybe = "," if interface["include_trailing_comma"] else ""
+ _close_parentheses_maybe = ")" if use_parentheses else ""
+ return interface["statement"] + _comma_maybe + _close_parentheses_maybe
+
+
+@_wrap_mode
+def hanging_indent(**interface):
+ return _hanging_indent_common(use_parentheses=False, **interface)
+
+
+@_wrap_mode
+def vertical_hanging_indent(**interface):
+ _line_with_comments = isort.comments.add_to_line(
+ interface["comments"],
+ "",
+ removed=interface["remove_comments"],
+ comment_prefix=interface["comment_prefix"],
+ )
+ _imports = ("," + interface["line_separator"] + interface["indent"]).join(interface["imports"])
+ _comma_maybe = "," if interface["include_trailing_comma"] else ""
+ return (
+ f"{interface['statement']}({_line_with_comments}{interface['line_separator']}"
+ f"{interface['indent']}{_imports}{_comma_maybe}{interface['line_separator']})"
+ )
+
+
+def _vertical_grid_common(need_trailing_char: bool, **interface):
+ if not interface["imports"]:
+ return ""
+
+ interface["statement"] += (
+ isort.comments.add_to_line(
+ interface["comments"],
+ "(",
+ removed=interface["remove_comments"],
+ comment_prefix=interface["comment_prefix"],
+ )
+ + interface["line_separator"]
+ + interface["indent"]
+ + interface["imports"].pop(0)
+ )
+ while interface["imports"]:
+ next_import = interface["imports"].pop(0)
+ next_statement = f"{interface['statement']}, {next_import}"
+ current_line_length = len(next_statement.split(interface["line_separator"])[-1])
+ if interface["imports"] or need_trailing_char:
+ # If we have more interface["imports"] we need to account for a comma after this import
+ # We might also need to account for a closing ) we're going to add.
+ current_line_length += 1
+ if current_line_length > interface["line_length"]:
+ next_statement = (
+ f"{interface['statement']},{interface['line_separator']}"
+ f"{interface['indent']}{next_import}"
+ )
+ interface["statement"] = next_statement
+ if interface["include_trailing_comma"]:
+ interface["statement"] += ","
+ return interface["statement"]
+
+
+@_wrap_mode
+def vertical_grid(**interface) -> str:
+ return _vertical_grid_common(need_trailing_char=True, **interface) + ")"
+
+
+@_wrap_mode
+def vertical_grid_grouped(**interface):
+ return (
+ _vertical_grid_common(need_trailing_char=True, **interface)
+ + interface["line_separator"]
+ + ")"
+ )
+
+
+@_wrap_mode
+def vertical_grid_grouped_no_comma(**interface):
+ return (
+ _vertical_grid_common(need_trailing_char=False, **interface)
+ + interface["line_separator"]
+ + ")"
+ )
+
+
+@_wrap_mode
+def noqa(**interface):
+ _imports = ", ".join(interface["imports"])
+ retval = f"{interface['statement']}{_imports}"
+ comment_str = " ".join(interface["comments"])
+ if interface["comments"]:
+ if (
+ len(retval) + len(interface["comment_prefix"]) + 1 + len(comment_str)
+ <= interface["line_length"]
+ ):
+ return f"{retval}{interface['comment_prefix']} {comment_str}"
+ elif "NOQA" in interface["comments"]:
+ return f"{retval}{interface['comment_prefix']} {comment_str}"
+ else:
+ return f"{retval}{interface['comment_prefix']} NOQA {comment_str}"
+ else:
+ if len(retval) <= interface["line_length"]:
+ return retval
+ else:
+ return f"{retval}{interface['comment_prefix']} NOQA"
+
+
+@_wrap_mode
+def vertical_hanging_indent_bracket(**interface):
+ if not interface["imports"]:
+ return ""
+ statement = vertical_hanging_indent(**interface)
+ return f'{statement[:-1]}{interface["indent"]})'
+
+
+@_wrap_mode
+def vertical_prefix_from_module_import(**interface):
+ if not interface["imports"]:
+ return ""
+ prefix_statement = interface["statement"]
+ interface["statement"] += interface["imports"].pop(0)
+ while interface["imports"]:
+ next_import = interface["imports"].pop(0)
+ next_statement = isort.comments.add_to_line(
+ interface["comments"],
+ interface["statement"] + ", " + next_import,
+ removed=interface["remove_comments"],
+ comment_prefix=interface["comment_prefix"],
+ )
+ if (
+ len(next_statement.split(interface["line_separator"])[-1]) + 1
+ > interface["line_length"]
+ ):
+ next_statement = (
+ isort.comments.add_to_line(
+ interface["comments"],
+ f"{interface['statement']}",
+ removed=interface["remove_comments"],
+ comment_prefix=interface["comment_prefix"],
+ )
+ + f"{interface['line_separator']}{prefix_statement}{next_import}"
+ )
+ interface["comments"] = []
+ interface["statement"] = next_statement
+ return interface["statement"]
+
+
+@_wrap_mode
+def hanging_indent_with_parentheses(**interface):
+ return _hanging_indent_common(use_parentheses=True, **interface)
+
+
+WrapModes = enum.Enum( # type: ignore
+ "WrapModes", {wrap_mode: index for index, wrap_mode in enumerate(_wrap_modes.keys())}
+)
diff --git a/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/AUTHORS.rst b/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/AUTHORS.rst
new file mode 100644
index 0000000..dbc0324
--- /dev/null
+++ b/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/AUTHORS.rst
@@ -0,0 +1,10 @@
+
+Authors
+=======
+
+* Ionel Cristian Mărieș - https://blog.ionelmc.ro
+* Alvin Chow - https://github.com/alvinchow86
+* Astrum Kuo - https://github.com/xowenx
+* Erik M. Bray - http://iguananaut.net
+* Ran Benita - https://github.com/bluetech
+* "hugovk" - https://github.com/hugovk
diff --git a/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/INSTALLER b/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/INSTALLER
new file mode 100644
index 0000000..a1b589e
--- /dev/null
+++ b/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/INSTALLER
@@ -0,0 +1 @@
+pip
diff --git a/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/LICENSE b/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/LICENSE
new file mode 100644
index 0000000..de39b84
--- /dev/null
+++ b/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/LICENSE
@@ -0,0 +1,21 @@
+BSD 2-Clause License
+
+Copyright (c) 2014-2019, Ionel Cristian Mărieș
+All rights reserved.
+
+Redistribution and use in source and binary forms, with or without modification, are permitted provided that the
+following conditions are met:
+
+1. Redistributions of source code must retain the above copyright notice, this list of conditions and the following
+disclaimer.
+
+2. Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following
+disclaimer in the documentation and/or other materials provided with the distribution.
+
+THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES,
+INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
+DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
+SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
+SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY,
+WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF
+THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
diff --git a/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/METADATA b/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/METADATA
new file mode 100644
index 0000000..b0e7326
--- /dev/null
+++ b/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/METADATA
@@ -0,0 +1,176 @@
+Metadata-Version: 2.1
+Name: lazy-object-proxy
+Version: 1.5.1
+Summary: A fast and thorough lazy object proxy.
+Home-page: https://github.com/ionelmc/python-lazy-object-proxy
+Author: Ionel Cristian Mărieș
+Author-email: contact@ionelmc.ro
+License: BSD-2-Clause
+Project-URL: Documentation, https://python-lazy-object-proxy.readthedocs.io/
+Project-URL: Changelog, https://python-lazy-object-proxy.readthedocs.io/en/latest/changelog.html
+Project-URL: Issue Tracker, https://github.com/ionelmc/python-lazy-object-proxy/issues
+Platform: UNKNOWN
+Classifier: Development Status :: 5 - Production/Stable
+Classifier: Intended Audience :: Developers
+Classifier: License :: OSI Approved :: BSD License
+Classifier: Operating System :: Unix
+Classifier: Operating System :: POSIX
+Classifier: Operating System :: Microsoft :: Windows
+Classifier: Programming Language :: Python
+Classifier: Programming Language :: Python :: 2.7
+Classifier: Programming Language :: Python :: 3
+Classifier: Programming Language :: Python :: 3.5
+Classifier: Programming Language :: Python :: 3.6
+Classifier: Programming Language :: Python :: 3.7
+Classifier: Programming Language :: Python :: 3.8
+Classifier: Programming Language :: Python :: Implementation :: CPython
+Classifier: Programming Language :: Python :: Implementation :: PyPy
+Classifier: Topic :: Utilities
+Requires-Python: >=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*
+
+========
+Overview
+========
+
+
+
+A fast and thorough lazy object proxy.
+
+* Free software: BSD 2-Clause License
+
+Note that this is based on `wrapt`_'s ObjectProxy with one big change: it calls a function the first time the proxy object is
+used, while `wrapt.ObjectProxy` just forwards the method calls to the target object.
+
+In other words, you use `lazy-object-proxy` when you only have the object way later and you use `wrapt.ObjectProxy` when you
+want to override few methods (by subclassing) and forward everything else to the target object.
+
+Example::
+
+ import lazy_object_proxy
+
+ def expensive_func():
+ from time import sleep
+ print('starting calculation')
+ # just as example for a very slow computation
+ sleep(2)
+ print('finished calculation')
+ # return the result of the calculation
+ return 10
+
+ obj = lazy_object_proxy.Proxy(expensive_func)
+ # function is called only when object is actually used
+ print(obj) # now expensive_func is called
+
+ print(obj) # the result without calling the expensive_func
+
+Installation
+============
+
+::
+
+ pip install lazy-object-proxy
+
+Documentation
+=============
+
+https://python-lazy-object-proxy.readthedocs.io/
+
+Development
+===========
+
+To run the all tests run::
+
+ tox
+
+Acknowledgements
+================
+
+This project is based on some code from `wrapt`_ as you can see in the git history.
+
+.. _wrapt: https://github.com/GrahamDumpleton/wrapt
+
+
+Changelog
+=========
+
+1.5.1 (2020-07-22)
+------------------
+
+* Added ARM64 wheels (manylinux2014).
+
+1.5.0 (2020-06-05)
+------------------
+
+* Added support for ``__fspath__``.
+* Dropped support for Python 3.4.
+
+1.4.3 (2019-10-26)
+------------------
+
+* Added binary wheels for Python 3.8.
+* Fixed license metadata.
+
+1.4.2 (2019-08-22)
+------------------
+
+* Included a ``pyproject.toml`` to allow users install the sdist with old python/setuptools, as the
+ setuptools-scm dep will be fetched by pip instead of setuptools.
+ Fixes `#30 <https://github.com/ionelmc/python-lazy-object-proxy/issues/30>`_.
+
+1.4.1 (2019-05-10)
+------------------
+
+* Fixed wheels being built with ``-coverage`` cflags. No more issues about bogus ``cext.gcda`` files.
+* Removed useless C file from wheels.
+* Changed ``setup.py`` to use setuptools-scm.
+
+1.4.0 (2019-05-05)
+------------------
+
+* Fixed ``__mod__`` for the slots backend. Contributed by Ran Benita in
+ `#28 <https://github.com/ionelmc/python-lazy-object-proxy/pull/28>`_.
+* Dropped support for Python 2.6 and 3.3. Contributed by "hugovk" in
+ `#24 <https://github.com/ionelmc/python-lazy-object-proxy/pull/24>`_.
+
+1.3.1 (2017-05-05)
+------------------
+
+* Fix broken release (``sdist`` had a broken ``MANIFEST.in``).
+
+1.3.0 (2017-05-02)
+------------------
+
+* Speed up arithmetic operations involving ``cext.Proxy`` subclasses.
+
+1.2.2 (2016-04-14)
+------------------
+
+* Added `manylinux <https://www.python.org/dev/peps/pep-0513/>`_ wheels.
+* Minor cleanup in readme.
+
+1.2.1 (2015-08-18)
+------------------
+
+* Fix a memory leak (the wrapped object would get bogus references). Contributed by Astrum Kuo in
+ `#10 <https://github.com/ionelmc/python-lazy-object-proxy/pull/10>`_.
+
+1.2.0 (2015-07-06)
+------------------
+
+* Don't instantiate the object when __repr__ is called. This aids with debugging (allows one to see exactly in
+ what state the proxy is).
+
+1.1.0 (2015-07-05)
+------------------
+
+* Added support for pickling. The pickled value is going to be the wrapped object *without* any Proxy container.
+* Fixed a memory management issue in the C extension (reference cycles weren't garbage collected due to improper
+ handling in the C extension). Contributed by Alvin Chow in
+ `#8 <https://github.com/ionelmc/python-lazy-object-proxy/pull/8>`_.
+
+1.0.2 (2015-04-11)
+-----------------------------------------
+
+* First release on PyPI.
+
+
diff --git a/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/RECORD b/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/RECORD
new file mode 100644
index 0000000..d8ae2e0
--- /dev/null
+++ b/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/RECORD
@@ -0,0 +1,21 @@
+lazy_object_proxy-1.5.1.dist-info/AUTHORS.rst,sha256=8CeCjODba0S8UczLyZBPhpO_J6NMZ9Hz_fE1A1uNe9Y,278
+lazy_object_proxy-1.5.1.dist-info/INSTALLER,sha256=zuuue4knoyJ-UwPPXg8fezS7VCrXJQrAP7zeNuwvFQg,4
+lazy_object_proxy-1.5.1.dist-info/LICENSE,sha256=W-1KNkH2bsSNuN7SNqKV8z2H0CkxXzYXZVhUzw1wxUA,1329
+lazy_object_proxy-1.5.1.dist-info/METADATA,sha256=z053kywfZh9ucyFWHpdMAL55fGxvzJBM-cwIzb-cX1c,5235
+lazy_object_proxy-1.5.1.dist-info/RECORD,,
+lazy_object_proxy-1.5.1.dist-info/REQUESTED,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+lazy_object_proxy-1.5.1.dist-info/WHEEL,sha256=z-ezgbNu1Y2ixypRrBmFDHP9mmiBhiGywozViqVfAIc,105
+lazy_object_proxy-1.5.1.dist-info/top_level.txt,sha256=UNH-FQB-j_8bYqPz3gD90kHvaC42TQqY0thHSnbaa0k,18
+lazy_object_proxy/__init__.py,sha256=mlcq2RyFCnUz1FNBaTI1Ow5K1ZHp1VpfBMIYGSILfHc,410
+lazy_object_proxy/__pycache__/__init__.cpython-38.pyc,,
+lazy_object_proxy/__pycache__/_version.cpython-38.pyc,,
+lazy_object_proxy/__pycache__/compat.cpython-38.pyc,,
+lazy_object_proxy/__pycache__/simple.cpython-38.pyc,,
+lazy_object_proxy/__pycache__/slots.cpython-38.pyc,,
+lazy_object_proxy/__pycache__/utils.cpython-38.pyc,,
+lazy_object_proxy/_version.py,sha256=bT8zyTb1DAzMJtJMpir1ZyrfjmU_UitIT0AeNOufA9I,120
+lazy_object_proxy/cext.cp38-win_amd64.pyd,sha256=W2E-nsw3kkOFJl_mlukC1Gfxl8ULtgqo7daRolyyJk8,33280
+lazy_object_proxy/compat.py,sha256=W9iIrb9SWePDvo5tYCyY_VMoFoZ84nUux_tyLoDqonw,286
+lazy_object_proxy/simple.py,sha256=leXvG0RyqfrEmA-AM7eSvjkuhqOSA9Wq3uVu6-4mCMA,8568
+lazy_object_proxy/slots.py,sha256=iLu_hvEn6G6_jhnxicWRDcxfQcnaUt_MdGPGfpXHpgs,11731
+lazy_object_proxy/utils.py,sha256=x4XTrtlp_mDTWO_EOq_ILIOv2Qol8RLMnRm5M8l3OfU,291
diff --git a/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/REQUESTED b/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/REQUESTED
new file mode 100644
index 0000000..e69de29
diff --git a/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/WHEEL b/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/WHEEL
new file mode 100644
index 0000000..c69d2a3
--- /dev/null
+++ b/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/WHEEL
@@ -0,0 +1,5 @@
+Wheel-Version: 1.0
+Generator: bdist_wheel (0.33.6)
+Root-Is-Purelib: false
+Tag: cp38-cp38-win_amd64
+
diff --git a/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/top_level.txt b/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/top_level.txt
new file mode 100644
index 0000000..bdf032e
--- /dev/null
+++ b/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/top_level.txt
@@ -0,0 +1 @@
+lazy_object_proxy
diff --git a/venv/Lib/site-packages/lazy_object_proxy/__init__.py b/venv/Lib/site-packages/lazy_object_proxy/__init__.py
new file mode 100644
index 0000000..2068a3d
--- /dev/null
+++ b/venv/Lib/site-packages/lazy_object_proxy/__init__.py
@@ -0,0 +1,23 @@
+try:
+ import copy_reg as copyreg
+except ImportError:
+ import copyreg
+
+from .utils import identity
+
+copyreg.constructor(identity)
+
+try:
+ from .cext import Proxy
+ from .cext import identity
+except ImportError:
+ from .slots import Proxy
+else:
+ copyreg.constructor(identity)
+
+try:
+ from ._version import version as __version__
+except ImportError:
+ __version__ = '1.5.1'
+
+__all__ = "Proxy",
diff --git a/venv/Lib/site-packages/lazy_object_proxy/_version.py b/venv/Lib/site-packages/lazy_object_proxy/_version.py
new file mode 100644
index 0000000..2136e63
--- /dev/null
+++ b/venv/Lib/site-packages/lazy_object_proxy/_version.py
@@ -0,0 +1,4 @@
+# coding: utf-8
+# file generated by setuptools_scm
+# don't change, don't track in version control
+version = '1.5.1'
diff --git a/venv/Lib/site-packages/lazy_object_proxy/cext.cp38-win_amd64.pyd b/venv/Lib/site-packages/lazy_object_proxy/cext.cp38-win_amd64.pyd
new file mode 100644
index 0000000000000000000000000000000000000000..cfd4158cc4c8e930c52886334a8337a6c36b24a1
GIT binary patch
literal 33280
zcmeHwdwf(yo^J)xAw1dyr7_~G!33f_3<MaS(jf_+NC#pFhzN8-(jhHLckBlw$nJy*
zQNo$tWn6F=$C=CZ5kg>BbbKJ=i~)2A0*d$oac1J)(P@O)PvnjYKDO`oS5>F`bf-JX
zs{ia=JD=)b)vtc_d)50?^-1Bft*k#|ED<3XWNbemeJuRD=da`h#;&;Wz!mJ-fhR`p
zPq3aCSyJWjm}}jx)$Xzyb9tH5>GGOa+0AaB)9i4X^A;{L*SIR|6O6_|>5}z3x7dIE
zv-yKhXkkb8juZcaben0=ae}YiBw(8<nWx)KR~-K(&rdnN12AdSpyLk#{%roB6JG+F
zP5qB=<!~^E{Y`&AA<_eRy4X=(MY5tTE6QiA;(-C|(7~&1T3#0$Wggt`3dZt)u?Xze
zs{m7ZyaDEmct6IHI4TTTClKUReEP9ckcvVY=$;msEEi)-QD!q>1r=^*>=MD9j1>)_
zi2R(Cco1Eu;bK5D^0(>nrQlB$9_KT`Yp?Sn@2y;Xk;-`pi3qxnnX%Fd?us&R8Dm)_
zycFRE1O-9&vA}B+1Q|;uzcnDhovac;_p!jr3AKWd+qe^%$q1x~?qeZ-t1BH99_hV(
z$b|3N1|1Qi7NT=|+~tUK-?bw`bpME;`&c-gz1jsrP6wZIx&|E)q87&HMq>W|Nd+?o
z-HD!`u>s%5L!ZjZlp8m3BbAxPGiZtzeOD?652jXraWELX=<9d!uyXKd>bb-Hc_F3o
zLT1w`@ASq`61<u8HN5f51n;2z)IXHQS27O=9x^a?-Vi7UNO``U;|kQ11ka^_sIaL$
zW&1&%9EU<m^YZj$rP-UFsx)s%H|H#Y0JEZAw5p$G9}Og-t8Hrc4ajak7eLv-18ALF
zPH)ajw^&|CXq?@)5lHW#7pboVDhD!l#IOx0(j{;Vq?_8ks{;=Yf)u~;EI?ooT3X<5
z_yXc{ieE<2Kr%`ye$$F#j$Z%}2o7Pasoi&Tph&PWBY(Wezk%}4ApeMA41`fzvrGzZ
zITkR2mt|8hrD;Jh7!15YQq<E*<22??SJaL`F}KB=rl{8{>aoDjp^sJl!vQK^puQe_
zD`;4LKgMKIUQw5)XDO;TeVU?fNLS!2bI!`c$3wnKyNkSJ+48As$V8d!vrX+kPRwpU
zUli<UHVg+QumZJZ*>VY<n$|eGu>opoZkj`8-wUgnudfC^@Xv@^w!9Ho2=%g0S+=|$
zaBxLawjWjxhZM1p4z|O`k1OgcO7l{)wb_!^T!cDPl9$}YE6q}%cBx;Y+L})JQl^`>
zu4nAWRBz9~9{=26<E4akw*;O?LOtD_m!5@Iu*r`UT%f)O`vZ@E6AWru-nAk0b#SUc
zHwF`YV^Jq#ke7XmiZJAb66Gi#N-O~9rl8l*80_!6CB)037jabxJu;-!`K0W#XpdRK
z@H*IR$ysTG=V7;Kr`6O>z3HL?6!rSMi>UT4sTURXoYHjGXYl7HoWGLl_XYUbsvc3_
zRn!x~x1=MhsYbo&(wm|BOy%`SeBM{oPtl=#hQK=XA1aTcuZOB(8n1?P>;5wsgie-4
zqO+XIJ{mOr$V%<zSkN>Yk)SDyCp!)dOk~st&G#t5jC8^^ThZSdFHC#!YM33kjHchz
z?j7(VHNz7(qgy;!4|E$+ii*agG#i|#NySg`#&+~n!+(N6Q4Mzyy4lcCCnzn5A4kp+
z!(+gZ)FXyR5u@gO#LyyR`{5L(tZAqI_iHM7Br$;`hw-X$$r|9Bt%+t0nV_h~0u70R
ze?#pCuz(4|u4z;^mPJd*ffhwQ6Er<IAH~(*TmskZV19PH;x9=rg%5+KZ|*=2jGeAD
zR-{jZ3fA;0MMbVv?I5>gp+yj~mJ*rSN2z+uLDTCf7Ch1z?6=`*Y7n-S_we?BaWJq4
z=78ZyyP_s$WRYpAl6>Bv%<S+E%Wm&dQl2)Z{sUva|Cl7k!F>tmzo526WnH4|fWX7(
zZs)HF+=VnoiH8I_aZ>yF0Ra_>eF>17d6>#zK+J(ZH(>x3{4`z<f)2wZ6}mF8UL*zt
z?nC7K1zq`o4Vb_(d`TpgkI}9R)XUVF(H74II?%_^>8@`4Dgo1i`bOZ-yj`LPQoDYS
z{I^uKrWeI(;OAaOVNJ&$b4K1&RA3_Ja5C!L?|=)uE+iNNzePlE>(erQt`!l{)>EE0
ze1YMu>F95%U8Uq5-fZ|Q4R^&*DzFh`(hI`^UXd6GpE(dc|H&4(5ZxfumlrGQ1!^?v
zna0ZrDG#=QU*IgN0`)l-9eE7&r16-K>cEk2*8^8dxXYX_Wn26C)rx9*vI=8BV@FUu
z^r8h^8awBV?bw%4@K%R4`;fIczY`&llFDJ%#gx>-u9TsM1hDCzH`I6;y-K6`jK_x>
zzoDLn8KDRUSXLZ<5w@~G9l8x%OKmC5svg{5xC~3J>4s|p!Jw~RDK}UV!JIXagCVIK
zr_-X>XWKs*<tnG=r1?s$V-KagkTXp2-<hWLKZ$6P;vdpr^$&SXX&#ndF!N1sntI0&
z>&%1hLF(M({s*ly+uayB4rQMIGb$gWJh^08<N9>=4-^}O#+?M%kGJ(S(J!H$dCQqV
zBUH{l1uqWXbk;XOdC>GFjUl``M7=i5z7a;UEoZ!mn@;(zz-0O?iU9m80B@{RbJ}=k
z%3e(#IitR&WSd?9tHuxKC~v){G=3TM4WhAk4N9F)Q80G;jXy_zU;!y`w5eT5$vdW~
zwE7@^)TaWwXdwCG^tJ6@oDOy%BU8+?X4yW>N~1lEDZicc*q_J$Vl0U@JXZ-Y^RUmQ
z_zTm5rqAaQHa|^i&QA@RI+0S_m5CHTF5><|vq(Qn>3lPar78zI%}O@n+4-qT_Ce)E
zXn_wn-GoH8CT!+mXnYVuYfdEzS&p^97blUNK}i^~f{zO{VWcXJvyT<PhrXnsX$=I0
zS7gWGg*R!i4Q4Du2HK3@co6Ax$(Z^Tzu{HH4~HQ6<gZXgX-rNGd@LgUq+k37DtDNV
z8H*MF-gL`XAl!JN9qv`nh#6%URvy$})MF=ZZp^3yJ!BMiWuMB~e-iQnzd$}Af~G&_
zBc}c;z$vz$CS}xP7_oz<MU(?3v$T=g-^p`1QFye5(*6Kt(0ENeDPpF{a0F-F)IpgT
z(TkMkCK7{o>*vUv{X0l1pU|2%BO2&OYN?_G)+eP$^3sb;7<K?lXsp4!3Z7WS&{PP1
zSb{44{H~O3@J3#`LPDR*6Vfa}(_@HY)ExBr*=yTJ8ocX>_oL}24S*Y8A#be+jYE9x
z%jbW^fBn5QdHJW51DqeOs52ETV$h=B2slWE_msxN$;!+>xj%|p5P(_KS^~T#2wr2l
z@w&cOUcro;Z%0ERo~g7fPt!U>qdkCrl#RK)qg*U~Qy$Ax4<0c*ha|aa<EQ00g?V}E
zYkBIaoQ<E_onA-I#)}T8y&z{}m(y#n&L4a-Pd%Hb8p_u)mb3By=J>o-`Ge1>Z{-a>
zv+?5XcBe1<sCp@H@G0JYQyy#1@5)n;<~0{yQahSg{JnYc*ZCNFij_uVAw&jq8aom*
zy5<B^@|q1p!EttbQUdd4&Mr;r$GjtF*Af_E*mwDBEI`fcu2nE^&>y^<^7vuTU=&Y4
z$@hGW<zvvlX5)t}r7LCQWtLLP+?1P$+!v9%A9Dz6Ufc;q{xb8@hV<;CTs6|D@Dh}2
zUJ*z+@P7t!j{Q)k31xCp4tzMw<2+*6u}b*rh~Xi`lE8_wuJtS;aGl2rW(g;iga2+;
z2A@=#7pG!0Nlj0hmE@bG8Y)ntu_O72VG$x|qwMqifVtUFh?MuL#t!ol!wf{xqFA$G
z8e-HkreW2CeS<}e5XX;mSE7w%w@)`@f(FZn!-r76!Hf}e;lm6s|6a+zOZm53hhNL%
zb^Loh|K7mA|B-(;@b91S?@jpLmv9(zsC6Gder_<-;xX|h#_t24!3+#R|8Xz%s+}l9
z+a&asWT?#tW@J8HO_~3K%%=9bzw&kMyF`gW;S8p=d-(*=5i}hoWV2xeo*q!%@01|3
z`VAhGR)U6V0)Ep-I{>YW6S=JLIzXoyk4E<)H75;ga%@I1*N}oE6t%#tG#&L$%sv$~
z{UJxloT)VDVpBIC)9?|6miwW-8;r4G(B00(8b2oBH+@k`+6=_J!O<Y5+M=x<kqgI3
z#kBb@2kavi7)c7`O9jSi3UKd1;5H%9Cj>sA32Z`Ib8)ok@$Ap(!G24W{dsZh|0C(C
z8b2lg`|-$4*w4{D+25@`&R|)JI!IR3FN3CcQ65!(Bdyw1EJQJ}M|<8wDypa*QF-&j
zl{YY2d5udni!P!3%|iJZn)1^%<+1LIQ+wh4*&zk92n3QcXRMe%EO;IOS5(soX8I@O
zz>bC86dg^KTsjA(kewwexrEBj$Eu?frDShWjVdMlrbkzj1T?K*A|0cqxj)5Jqkaih
zf~NPWAe`d}n&yxo)o{92V6ZMUKDvtZ`<Q5&4KGs$p5stQdYn+A(+(D1=WUmETf8QM
zrro!JqH!#?ZkK!md6^eDfAkRYaJQx&ZhulgY(6eyk?HNP1p8^-Ziv!&a{^!A5U*yN
zndHT1hi4TzW()`fBKnoq`1SsXl7}X9)Ekob6<O14OY22m{Qf$Ms&e~ma6wg$6IF?3
zNxA{R8~5N*i}4i_<2Svt9Du6vZKPvVqo%%?^QFINjG#J|O<jyrStRxbDRxF^nDCpP
zDdi6r!rsHE@q3c48s`WliZmq_BF!6lcSpy!H<JWEIZN0(NhkPb2-b$F-%-A5e4X_3
zoBn(crC{}+kdAG2FY>0ukhj|wmRBg`trYTHnmlJ*dHVJd)4v5|=I>`h1gdqB&dgB|
zi|HU}a)5c`rJ#2zdM&oTrlBGu!tvh-z5YPJZ+Z_KIqrvdk&fed*#dg;M}|~P@BfV}
z!~U2}`Kob&kZaTAu0%Sv|NG{Tf13feQU3U3h4jbWWR%VyABv0!fBa48^*jN;>B!xr
zCECRwkp52oFiFMq{>XuRtv!yXeARfHkh@Tmy8!8L=?~ujemxy*;SYWPJFvWa|KoC1
z<IALl-*j>*DFd_LKst`uz16=IthaX}1Z(!rrhL@D5NOi`u0;B~*!yqOz&6U>wtKqU
z%jK%ZH%JS=sq-#U2KN3L>2GK66e(D5?==vt*;`2Ys&S<d=+Xo_k&bPzMIJ^_-~SXQ
z`9{f^C}mRzLm_njgFgaKdY1h<5K8mBG)$Z0mr)eMWzh5x$%>vRS7NL`M%$`sK~n<P
zi53IL?xxB1GV#Nj3&KXy{3$2T^_&bPpr|(Efeq%5FwGK9vm}kr!f#-|N~{`h#T0y+
zxBxR*<DzI!_A&F2HpV+B$8Wl42}wsKEJIrOgg^Z5b-cNieDT~=lt#r*r-9H)6Pw@o
z&0^wcT3-b~(;ViR30w=~d!(M<6yO99`B$W)sv&;+9!v7_rMxL(;9VpvH?|O3${Iy+
z)wo8;+Mvn0zq>3lF}^&$-hO8an8Cho>+KJSy=pWFDZ@1>rr1)XGXeN`s@wm^-EXWU
zbC*c*Rl0d*%U#rHyp+RRnRmXn3BlgzdhQ7Q8Z4W;L$1NXdk*McKskQXvJ&Ei+PIrj
zq774ni@7=ZFYEvCWblUj^!h)tg!F%wa=Pokg3O9oLwdNOvGi}I9KY$2MZ^jE|AJHY
zqJJ;-{ZTfU#j5YUl%X0;Lgr{qW(LwxEjV1)6zg++TdBS)rT8VG`o`w6Dd@v<AzF%s
zY6V?t5gf=XK04zQq3IfOu-~+S4lv0(_j8AXm=Cn^s<-#`<;|q$?<Wa2Wry{|Zj3ZR
zC#3!Fc%j6{1hD_Z;WJm_bEK(tX_VcU=)JBtxcu9ClmDcU&;98)t<&VM1v<_|Bde{K
z_VMaOVR*Ok;8D^@HGW3GZ%Wbx8b}Y4NP|;%YkM7k7RQtK1ZAkkCL!-(97%EqZ%4Y<
z_9%`Xu|?ADAHvhz8*-X^ABS7$3Mrf3;nN(3c6DJgY#T(=E6zi+l$o!22L(<44o%Qw
zvK94qjQ;Cr<LxzIK0ALM3Yck6br&@mmDurF&bv}+PNJurOK4k*-6PsP_a04w-W-mU
zo4&PVWw1Y=yGUa5{h-IgF5b*&5^Ev?zv<zH#2l@BJJMqKLT}L%E*FF~8ez304AIE?
zr}o!3{~Wj#GGqAX6HMxQ{~Utheelm3Vi(UpQ^U@S@Xr#$_v9Zt5%^7OaeT`C<3l>8
ze`X27LXFTW31j&OC&E!@;+GZw_=`(P20f^GUzvHrYgE*Cf~HqtRnNw|sBt(aP+4C8
zYh~kbq8;GDx5j8gh!L$ZJX$L|O|48k<Kd4^GB~5t)R4w=MrXYlbS6Ygp)<%ke+?Q<
z5xLrLDl3#uDMeZvmDI@Ndf6(%K#u3J?8m&^-G0dIi~Zw!wLiqDXZty$*!CX{*^da>
zZ`JHa`oCg-&;8>yIet7c4(zFaoQxblUc>ya?;npr<(^$sOig4yu@g<?ZrMcc42>W2
z$Ra+NT+*Hw%_L9s)HUuP0<3@O$b^QDWk|>D8Y2baB#m&QB#iDFypi;M{8&F0f@6#y
zZHs}|jjum};XV6@kFR5iUA*z5C7c;Ceheq4_T;1tBJi80;ywg-(iEg)I_YbY;5QjH
z!Xc6{+DU!)&$3&<F@}G(lmM^u&nigngMS7SyLkSY5YCM7&*y~i$v*~R_V5B?jz(lc
zI;MX<AWnYM-xNuB0cp|aA`b!j?w=VqgH;Uw+`9;Poqy&+QXl+tK9e-#LvZ)`c{FJ+
zG9&!+F6q#de?B4tzv*)vEpq>ShICB-yd(%uXoSZl;kR!;Bgmi_{<)(Vc%6SnK~f+5
zb8HNm5XV2Chn*MUpXUkRlYd?%0>9~9oY8atyn}R1|2!%P|5YR0D+y!zhvsMPx*DBl
z1;WpX!|S}Ga-6<68nVexZ$ysMqwWM==cg~>fS&ziqjCCiVki7mDaYxRG&Eb)SNT%!
zH)M#&pT~!6xztn1zrs~~l}F1xzJkMyYzeLRwiA`#)RIq3(BGa!8kZn(L}6SnvQ#Z=
z3#Ewz`7^{LJd=x9-}~EZ8Q>SAJ$<<lc%7e4!2vz{iI3O!6T5ir>9(*FBid6X;d^RN
zJ|gg&9-wOp<ew&_W40%&AY7plE|-Kc+f$75hHyKgW<wR<mJXRQ{PX?-;C23a28Q>+
zKlc#3c>Y-s&W!NSJaTGJ{#i@}ep6*GF^7NbNXPWgI6*jDBb+4(zrBC9+yt31{BxiX
zc%6S9f^B{9&rD($&p)H%_=n?r^3N11=r_%yV`TDAKGHG$Gei(xuMu7+3BSF6?i~f0
zG5qt06?mP0+%UWk{<)Ue#q-b9u=66?PZHsK@{frK{HD?TC>Z|9Ksu&>E|7S?=^G1a
z0m845Cc<d{^zyu6@ko@1wcVaK%;M%5n}nE$H8I<Tn0QYcdVSvTkvWdMYElHxzl6Ne
zn!JqO<k9#Vd%t+-4&oTKU)&BcJy$N@FWyFKipq_%U$ll8^|)X9>_%b~d%yHFgz){M
znQZr)Ce9&R)MXaZqAoE-ee3<=p#owTZ9io8#eS|fUyQ`FKg6hK`)`PE|HhF0h>-ns
zO3dv?`g^cniDf?w>x=zd?H=t9G3wd=>*L#h5P72h$=k4hwq`%l--G?P$Fd)W^~HX!
zc8~Ul81-!bb@A>06nVma@;2<BrP+`4_hA3LSoXuPzSz&z?$Q1bqn_=*HopDMA^XYO
zuz#jzKhk}*znAgdNAh8CxAA=wSIqb%8R|DZPv^DN^`1i-qQCX{ZipxE2_bKakT*}0
zmydK$kFR?>KifVcj(t`Vq#9o(vDp9cGgH|24$|MnzKnSCh6s6!g}h2lp8Y$@d+wSz
z_Ps)aRO3ga5B9(O{1f(lhIEhiMa`EHKajg@^-uX}F7Yi$=9{|r3ueCVH5RDv22IPs
zxaW@JrbW7e^c53lz1*GMhh125n9)@sM)5ihKY@8EjToJ#wu{H|c$|OMo5{C$;#uoA
z$mV0mUr3<e^ckI#QUm@w(%t)x{ughNJG3Z&$ejp1Z>IaF-R955VBfPF`1;{Lucop+
zjUPiojN-Y0KW~1HGvaRO_Plu`Sa2V7lCS)xPx<*Oe9(n-cOTHnS@#p79_-JFWj|Q=
z#s1;F+8<)nv;CY=Z2RlMLfB7Eg8g)MN^PJE>F>dQODy}rx-a&ddbK~qsAu~*quBNj
z1q)$6ISKaj6Iikz>F>e*IkD^q>%Q1OtXKO(jC!`8Gm35hLHI`4PfmjU{7jbYNBVoP
z|F&56gLPl*zp7XJLyUU1pEHVW|7G|_*iTM^{rr%V>_@t<_IF!9gde>8oPiC-^ogVc
zZJd7vMEF2HC;5wpR$%Z+^OZsVedK>!LBbuSsUiD)*9A?}cnWr67|x2gph~~^!^znj
zSE6LZwW2@rA~=Di5_~nH1QQ}Iww@;nzv*i_cco7M71A&|dgap1z7ZJH&2(za@82vY
z$*9n7>!YtJ1Lwa&%EOwJ?XjhV=agRLeKa(VybUA>`(Gh%v?ecu(mgGZ@O!gqih5@<
zey?X$3*h47v_cqX=J%BSMn5sakBKs^^fRWQsfOg!Ph3H4#$BpkQ9jbRQc;YoupL@V
zvj-QuKjbdKl~eE^rX0ylrK;DC!^VlsG%XWjb2u|aWOBDtNwYrlBB`Y2;#~I_uRSHW
z(~=NUB_to!7F+T&ygUy2rCJe^w~Nf!lIxHe-DKo^h<69br2u{(aEZ&tPc|T7Al^F=
zd>2>gM)QZugrUdIgc$}57Zk$u3-!Xd_hBp~2HX70bf14I`K16q^~3MWmRi+Q{I_QX
z>T6cN@q@{@j^j5J;wTw6=7Xj@cpowcinftu<3FIY(DR?A`~lNK?vK!Ib3e$n>k=Vk
z9U((k-YxJx_-GX`A@_%H1znmy16QDteMzne@yX)Mh3z5awVe6=X3Yh$mmhL{k74F#
zS*Uce;`1f(hHyA&x*~-%%uNLo`aw){u9>cC==-?VKIpCqzo<T4>)%(?*yXzd4A8$v
z^73LJQH@U#TfeED4qj>Ocp2&FhM?I`Rv!v`g$y_HMn3?3W-1DX^QcHcV`hSHPyv36
z5zI*ImW%sZLHwAh+b8_Kj9{l_G5x|-Q9s#INL6B9aW45){4_s=4oo~83~njp$9gNy
zU3f*yLnHb`Q4`cu{?o<gl5{hg&HsLh-e8blt1hlm)WXt0*`Z)?D^)apEC`OgME22*
z(+qfpO3Jo_>OtVC5%&4BrCyLeA>n=r-<I&Agh}fK-3SS%N?0UerGy(Kd|1L~B<zrI
zt>mXE*zbN38ztc<l1|INP2%s6aH)j%O1MeF76}hY_$LWJmymv6uK!G0D^hbMES9iJ
z!u1k9BH=R<zAj;>gnySXX`SFVT*52~=Sf&1p;N*Q68@8fJ0*Nx!W$&t4`ll95+>IP
zIX6f+K|-s9D<!OzutCCY61GXWU&6N~yeMHmSwB}wm@c73!V(EnrG8)gggyZYPf2({
z!krTSR6@6et0Y_?;VcO=B}|p@ORwPnv4p22JS5>W5<Vv3PbKt9xJ<%%5{{E_xP*xk
zUhoJxuS<A9!bc_CETLP%QVBa`y(ls*xG*;42G)Q9krgcxP{V&;Fx4;k?vt><SwTOn
z_12p!ea>>P!{wY|cH6x^x6@<xR@u!ShjVqc-CX8g?W+MH?!$yX+B>g|K$Y}k?AZzg
zoT|`gn*iVccSCHyEG-xKQVF{WhEs3PEwR$OsVsQb!QWSvUgIP>%Ob|GQVHSGv$9w*
za2rE7H1bmM{;LTNdf!y~6l5{T<gdD#kd;+lxtg&mq?4&kZZY0uk()y_wUM}GgsY3d
z6>z$SNF1lz9Dyt1bXy~FoNh-1u7uO=1P-Q3T}n9JKHw4)fRpdwqWYqG6Y2Ez>(^JT
zf*C9sU)&D2w>-Tdhx1E~z%Aqa()73zL1&J@3A#+ef#HNY`R*^5cvsm3yGYYJ%Zf->
z;oC`wveUq&g>l)0>!Nb~Lv)h~NBt*2yhYimgkuc|Xq4JJ#F!txNJ4s*2h{lN6z@dS
z-W|sFNni1IgvpVsUA&%*zYi=uYa$gZ1#SnR#Bn_d-_r-~W<yQM%;X)&Oceu|X>t-X
zO&Z!c9M8Hb?+sMaa;!(Gz0oHDzcNpn)URl0N)k({NM<RZPnk5hR-^wMw8PL?9UA?x
zWHt<R!%7CQVW1s0DYbUsh$J>*ata&a9^N^u_Nr2?Y(2`|bQRW*C`*vbD(+X5Fff4)
zT!l1V;*ji4tnFXgFH7o?H4qIZaTH@3kF!_fogb)}-+~9hgnkLEA1W`wn8=Ki2Qi~N
zsVITU%++uMnQ;<uCIf6gz)T7ISrXB6`v!#UOSm$LUFl6`S56+luADTuh<u~z(2Z93
zD61Pjnx{rLD3J|<Zw5_Ds!fO&k43BDG^j88ec%L-(vgOK%mDqeaARl<LY{-MkyIDn
z0gOfCSt5R|9}ACn>gmdde5dKD!Dt^vr{mG-ZP&*&dJXct0o>Qzu8Jg<n#CC1C{DW<
zb}<Y%-EioCIvP<&kvyme(yi^~Iv$ZY*sr5Wh|w=%;$rAqgpq}QVbY<K6^X<6p`(eV
zZ!Kns=Mjdi3ELcr!`z^wiN#|pMzePjigY|8ag6EHv3TtJ5nl6vuuaD!5{LIJ=xAc`
zI5`dde>%ow9gj#HWBN4jmnAfIp?_oS(%L~6c-%Gv@13j;`y>*FF<wU#OBeG@j5`Pw
zIv$ZY#`Nh}JS?*qdjO$T$0HJlHGz&M7LU@|jI|(K(D8`GVZPAO#NyF_CyjqV$f^nZ
zBNB(HOh?nLPxrNre-}EfU-t$_3}PcN$Bn>TG@@hx<{!*KlZJQ3>~r5mpIBw3ZoHj&
zlUREp-b;epVL!#{j*mCpaM<<gXuA28<}aELqiv2JD;FfP1(TCmQgOe?c_peGpV;xG
zt(R9}9mD50n&S|bBE1};6rmRDg7tummE(n~6Uu9|r;T6daN5dhDyB}JP+MQYis}oT
z4zG=}K^3SaTJfpE9_v!6SSM+?57r|FT&<379QL*iz-`sxuE0KbCvfpTKkWB~XNu+i
z^@shw@W&7Pec^|1yWhXDUs3%6U(G7J+g9K#sxB+H7rEBi-E0x?3s>E1FZbH!)_d(9
zyePRF<w7^+u`t~tyEn({1+Kk+QT<}4qa3fy22-!y?VRU!)hzP5v6p9Te3(y>%j57m
z*4o)kVVu;W#O<@^Io3KV?0DsB0>+%0T9?~v6QIyl;j6YYQ@9jJ@rG`8YZy~(uPJlj
z;R5uj0#@3BmvY(Nj`G{3s;Oc6oK+rIwa;s34~D6wMVjVUhpFdPyIgKfzt!Oqx98dx
zJ4@VU<!hKXj8)1!Rcvy&^imhJ`Vd~S&Gk8|E0&a1`|PYHOs}cO++iGe2=5*OZjt>y
zpWRt*x8=H=UYO}&tr(Z{9H=emT;R2bynRbpYN4;%>!_`+XQx4%?{*WZH0{2y9LPp_
z=r=T6GN%GN^^xJUtfOL2m7@}qz;x74eqFhZ+X2R8-L>7Qt&;jDVOjK2^ITU=ZJ8Uj
zoYt)biB;gGlKNUSB+nw>DlcM;O$<{K4&L^%vj!X7nP)Gnrq^O8fI>798|)#!Ft#cz
zH_rhLuMBg^al*c@V1+CL!J@q|W)GJ_-R9Y=+0rm37t-d*$5tqi<6ez^@*7?2r*=Qj
z<*q4%{OiN=r2j${!m`47(y8BswaInc%e?kUjExRc6*$-0-ClNw=AB}DSp{ZaXIMAc
zhP1YOjlL}J=VbIVvL)nJ+soYSUVUlaPqZ%mgx0zi*w^9tLztHsELcVuLl5-ou!qz%
zlRYkn*UK)@72Bb@$6jHhYGq@?B^TINm+{fy*P1lZ7DH{h7PO&$%v(8Q>EZIytJJy1
zgt1l^2A#p+h}y9gl|gceueRC_>*w3+*SXvk9+s)27L9a$SW<z9h9b5ljDbt>o_k$d
z^f(;lg!$-(uW?~42267}rS+oFKsBOUo_?5VMy|Aekz>6bPtHPVYKLrixHO7UiyIZj
zNLiuo!UlEo2$pGKj%esKieTMV@2zq<v!_j{pf}LHm00Yp&Mm9O^I1C$J+uaVpKw-}
zYmKi~>kIi#uN$rLL&{m=aC?1a)r*~2MWUCzWLWI1Dsxs;+bb|+*lX#D?>t8}A93zC
zpuNS-zP=xtL$1&5#$(_jx2xQahiQ)(O6=|$hZFrnL$T)m1s<7jx#ywlK-VI--GgGR
zDDh68-CbW~cUMxc#0Z+}^3e>1*{vJ*f(m#rj4i1`Kdb<fbrE(^y$22|an#szJTSmc
zF*Yh8&*3Rsg%l^YI##*M-1SsF9#-9-*3FKxYE<4LtHa|}z>fU{+UD6;`BtyCyEQH6
z=NB)?w`NZgK2K&gTdvJhYcF?HI?8Rrd1!$dz<azEHX0Lc4risyR$=#e-L86DHJD?k
z%WCX39y?-7a*G!)C@Cn+pEx;7@SMs}!r_JCHS9;>xXsSyFq_9-Wvk>>Vxvk=W43aa
zv(m8|ezZBuFubp`;c-0Hq1mFOFiFd@JJ&kgE+;*#$HSut3YXJfhn<6$9K_fxW^>zD
zLscw2WR7+Oz(z5fz0O{a=~&AWg>HZ@SOuWE!H5k<ibq&ktz&$Rhc+tXkv|^)x5JC-
z7+*bc{KWCn<ais4AMpPzJ)phA_{0kHsmizMeZ%y|VX>dZ6FzpUnNr~o?Q`{?@)^su
zp>2HK)XB>o&hlzsg?+h;uX!g_X|z~?^5ZE=XD-ZKcr%`H(g!0<UA?)g%;OwG|0>2#
z|0srfx7S`V!)&uvVol<5*V}An{9~CKhlh@_CQ!L`?y}lidj(rKLyYB|5AgV}AIq!D
z*4NvF0=8P>zg+CWsoZzXpOxV;mwC+@wPvmX)G=oiYZ!;O$}BYo7EgT8JHzxbav8>+
zN>6Q>x5{QC>hG@KceU?_@;$d7n+@$4Bdx5iUfUDsX{_etZp@LG_V}kaKd-`u#!DL#
ze6+Sr@!raP*L)l1pBlT+S1(tOCp~Po`>+}b({@i|ABoMS<|v!3w{(T89K<$TG%T+!
z^LR8i$mjo63JYA9ld#>>tL@%0Y@cO`-u$t6hRvog0r?Ip8(q)(dKC8SOOZcT(e_@a
zr(0W}^SZZTlCJP!rzsmwC~dFfsOWJ3`P5o8a_|rPI=26#{j2%0H~-0zR7%nfxg>^l
z8%rmM2bTKroapv9M4sno-73;q69jA+FJQY>!ub;3Az^`pih%oW7tkW%$$27ODq&Z?
zNH=IOPo{GvoGW3Dgcbo)B_y5cvvZEjzfC|q>u;br4(A3O;tYaAoM&)|^AQel*1{pq
zZ8*dk5QjKV5-?lBNdn?bi{o)V#^FxsAFhP%t4jK@vslp4`8|E`ZgpNxq~d>TeveNP
zJ7=G)r|8_&CaJfqzr-klG?`yCPSD|4KjM=q^S6$Toj*<H*NznV(d!FE=9^{tX!%QJ
z{=Qp8`RM#AnQw`cUl*0H`CBt$v&_di1NVP4{~a<PXSOl(H9qlRw7v1@%nu0uTE1AR
z;WFTZk$5dX9&FX@$rR-*5=PVSmvkq`2)ZH(qv<*%UFT@YPr_)r(;B}FL6;?AG+n2p
zYfl$+(fL}sOVSldx|27>p_hIumHDZ0=u#zJ*C@efr-YikZwuqq?-PwePG%J2&V_O8
zh@xwdbhT3Nld>HwmFZNOZ@y95vq18dcI`7q$;pds*(ZxceyN1!DEfVpucnrHb0oj6
z=E$^07Y$P-!g8mePf8WgBF8^me(KY>7tQyFbl*H+Mg`;`(A_S&lfDh%I_%mAzC4t%
zalp3&&b<=PwTK3A`c;fQiuf$Rtq7YDCwKzEg0d$86NfR@2|U4f5RM~$8nD2`*xQI(
z0h<s=)@Hz$WSroeGX6H;*D_9U=x{+l4A6%_a_azFC7$3*GEUHNwa_6M@J)nN$a)*F
z2KSu;C|e7-4T1C|__B<*1EyRf@Tq`f5J=BVz_$_7i4Wix5}!VTu{j7tqX7D^#a#fz
zw*tP8KtA~ZaP)N|PX9CW^Xsv$2fhL4#Ks$O4+3%YRrUlzHR9-BY_J*s+LG{qPatd}
zJm9L4&=+ycnd~!!ClJS@9`?@&dlARj#r}k_A90L#YyrY6h+_<7FCm;n9OEUsJsov|
zIL1)+48mU!$GFQzW#B#p;uxb@JHp?I9&i%g0mE>o$pUy1AsKOu`)uwQ++{-?a|Anr
za2?{9H`t_1_>AZQUqHx0yd99<s5A?4{XHkTFV&1-1)ktZgi^!_UVRJd8F7MB5w;?Z
z`JC-W*oipienv0WYDFCD1a?2dKE$!+U^(O92gI>HVF}~0jzT;Ya1Fv~#IY`AW;{{o
zL>y~X_P-Fi5XX9mnQuk=BRrrVA^Bd&1N;gh6><GtC%PB)0YW<P1Pv1zn}#^Sn-Q#t
z>+dzu9Vq(kQx)(8GbW*~5hqxHuodwlz&Y8FNpZkAlW{MX;(*${CW2Q_L3;$Apamg-
zIKc{puMyYZPold_v!>#dXpMk&#K$2{uo=OExc)8@-CJ7zBLv_HHX+m^PH;EECdBpk
zj_8ikhH20lc!EzNJc~HNqX->{>+cxReWXVb{sKI~R}n5DPVgMU5Iil{-zB1ZN5>Jy
z0Z;I+2o}T%rq0AYSj6@BhUkvb1%z7Q37Td>XT%9kN7#Y5{*DmcCmMqLKF<PAa0)^P
z;sozT_yBSJeIU9!G!9RCE&)$)F~X1<0qYSrBd)*uL-&NNbKra63HlI<5GVKxgbKv5
zCt+V9co9#vpsgZoK)eCal>_}L4(OT-{V5LU%0=I&IG`&J{fy#(u6(o&iUXcS2q2EV
z6SK|(L>&7m_FIHYh+~h%#@>!T?u1VOe~FNcIQC-fX$86<-VXRw0s1w?0iU`9won}K
zsrj&l;($+CVGG3ppDINEr8uB=pNHUW2-|=s=s;*ioZxnZmk{3x_!Yu&#Ic@X^m5j>
z5y#qxy^in!;#e;+`iGl;K^$up)`4&Vajaih)}0u;5Xahry@`<M0zKe_V(>#8YYbM8
za2?_efNvtCBaS=!{2p&<m4I|dcj;<zSC{VGQk)>&oqYvyf^Q)tgZ{tU2i=>YdKsz@
zr+Ytq{%3n2f#20nLwAVu1MY?ckre|!FcE7W<dwEF_Or-BJT+@hT}`!_PO9<1ZuXdo
z6SBsbapS^OfhXs)$1E<HH-6d}v&V~*%(7~nUd<j;Z}*IubDMF{EIjqI*Q~0pH-mxG
zGkXkv$}+=KUWHR$&-fZgx!dJ&ReHylyJ}{Xd1@xCojAsfgGfgu&hD1zr4g%JHC{->
z(D8pXs#N?wW9j3ikMDoH{qeddwmz}r33#LdV<mvnvb3eNrK+X2rLLu+Wpm5cmK`lS
zTUuN8wd`+cZ|P_`*>bw2vn9~d)xvfq?@Ha3w#&RLb63``X}c`DlwC!;mhLLuRkf>j
zSKY3yyLRkq-F0$Ta;v#Dv(?h7w3fD3wKlYFZr$11+S=aQ(c0M>Xl1*Tcbj)-?zZe!
zcDL?s-`%zQ(r(t4)@E+YY_qf}ZAEQWZMAK6ZCl%RwC!(eZ|i95Yzwq?wI%OK-IKPb
zZqL>|`}ef(>DY5}&*?p#djfm9_FUSNw%5EjbMLgh%HE}WH}BoLcgNnHdturSA9&#Z
E0l)}qTL1t6
literal 0
HcmV?d00001
diff --git a/venv/Lib/site-packages/lazy_object_proxy/compat.py b/venv/Lib/site-packages/lazy_object_proxy/compat.py
new file mode 100644
index 0000000..e950fdf
--- /dev/null
+++ b/venv/Lib/site-packages/lazy_object_proxy/compat.py
@@ -0,0 +1,14 @@
+import sys
+
+PY2 = sys.version_info[0] == 2
+PY3 = sys.version_info[0] == 3
+
+if PY3:
+ string_types = str, bytes
+else:
+ string_types = basestring, # noqa: F821
+
+
+def with_metaclass(meta, *bases):
+ """Create a base class with a metaclass."""
+ return meta("NewBase", bases, {})
diff --git a/venv/Lib/site-packages/lazy_object_proxy/simple.py b/venv/Lib/site-packages/lazy_object_proxy/simple.py
new file mode 100644
index 0000000..92e355a
--- /dev/null
+++ b/venv/Lib/site-packages/lazy_object_proxy/simple.py
@@ -0,0 +1,258 @@
+import operator
+
+from .compat import PY2
+from .compat import PY3
+from .compat import string_types
+from .compat import with_metaclass
+from .utils import cached_property
+from .utils import identity
+
+
+def make_proxy_method(code):
+ def proxy_wrapper(self, *args):
+ return code(self.__wrapped__, *args)
+
+ return proxy_wrapper
+
+
+class _ProxyMethods(object):
+ # We use properties to override the values of __module__ and
+ # __doc__. If we add these in ObjectProxy, the derived class
+ # __dict__ will still be setup to have string variants of these
+ # attributes and the rules of descriptors means that they appear to
+ # take precedence over the properties in the base class. To avoid
+ # that, we copy the properties into the derived class type itself
+ # via a meta class. In that way the properties will always take
+ # precedence.
+
+ @property
+ def __module__(self):
+ return self.__wrapped__.__module__
+
+ @__module__.setter
+ def __module__(self, value):
+ self.__wrapped__.__module__ = value
+
+ @property
+ def __doc__(self):
+ return self.__wrapped__.__doc__
+
+ @__doc__.setter
+ def __doc__(self, value):
+ self.__wrapped__.__doc__ = value
+
+ # Need to also propagate the special __weakref__ attribute for case
+ # where decorating classes which will define this. If do not define
+ # it and use a function like inspect.getmembers() on a decorator
+ # class it will fail. This can't be in the derived classes.
+
+ @property
+ def __weakref__(self):
+ return self.__wrapped__.__weakref__
+
+
+class _ProxyMetaType(type):
+ def __new__(cls, name, bases, dictionary):
+ # Copy our special properties into the class so that they
+ # always take precedence over attributes of the same name added
+ # during construction of a derived class. This is to save
+ # duplicating the implementation for them in all derived classes.
+
+ dictionary.update(vars(_ProxyMethods))
+ dictionary.pop('__dict__')
+
+ return type.__new__(cls, name, bases, dictionary)
+
+
+class Proxy(with_metaclass(_ProxyMetaType)):
+ __factory__ = None
+
+ def __init__(self, factory):
+ self.__dict__['__factory__'] = factory
+
+ @cached_property
+ def __wrapped__(self):
+ self = self.__dict__
+ if '__factory__' in self:
+ factory = self['__factory__']
+ return factory()
+ else:
+ raise ValueError("Proxy hasn't been initiated: __factory__ is missing.")
+
+ __name__ = property(make_proxy_method(operator.attrgetter('__name__')))
+ __class__ = property(make_proxy_method(operator.attrgetter('__class__')))
+ __annotations__ = property(make_proxy_method(operator.attrgetter('__anotations__')))
+ __dir__ = make_proxy_method(dir)
+ __str__ = make_proxy_method(str)
+
+ if PY3:
+ __bytes__ = make_proxy_method(bytes)
+
+ def __repr__(self, __getattr__=object.__getattribute__):
+ if '__wrapped__' in self.__dict__:
+ return '<{} at 0x{:x} wrapping {!r} at 0x{:x} with factory {!r}>'.format(
+ type(self).__name__, id(self),
+ self.__wrapped__, id(self.__wrapped__),
+ self.__factory__
+ )
+ else:
+ return '<{} at 0x{:x} with factory {!r}>'.format(
+ type(self).__name__, id(self),
+ self.__factory__
+ )
+
+ def __fspath__(self):
+ wrapped = self.__wrapped__
+ if isinstance(wrapped, string_types):
+ return wrapped
+ else:
+ fspath = getattr(wrapped, '__fspath__', None)
+ if fspath is None:
+ return wrapped
+ else:
+ return fspath()
+
+ __reversed__ = make_proxy_method(reversed)
+
+ if PY3:
+ __round__ = make_proxy_method(round)
+
+ __lt__ = make_proxy_method(operator.lt)
+ __le__ = make_proxy_method(operator.le)
+ __eq__ = make_proxy_method(operator.eq)
+ __ne__ = make_proxy_method(operator.ne)
+ __gt__ = make_proxy_method(operator.gt)
+ __ge__ = make_proxy_method(operator.ge)
+ __hash__ = make_proxy_method(hash)
+ __nonzero__ = make_proxy_method(bool)
+ __bool__ = make_proxy_method(bool)
+
+ def __setattr__(self, name, value):
+ if hasattr(type(self), name):
+ self.__dict__[name] = value
+ else:
+ setattr(self.__wrapped__, name, value)
+
+ def __getattr__(self, name):
+ if name in ('__wrapped__', '__factory__'):
+ raise AttributeError(name)
+ else:
+ return getattr(self.__wrapped__, name)
+
+ def __delattr__(self, name):
+ if hasattr(type(self), name):
+ del self.__dict__[name]
+ else:
+ delattr(self.__wrapped__, name)
+
+ __add__ = make_proxy_method(operator.add)
+ __sub__ = make_proxy_method(operator.sub)
+ __mul__ = make_proxy_method(operator.mul)
+ __div__ = make_proxy_method(operator.div if PY2 else operator.truediv)
+ __truediv__ = make_proxy_method(operator.truediv)
+ __floordiv__ = make_proxy_method(operator.floordiv)
+ __mod__ = make_proxy_method(operator.mod)
+ __divmod__ = make_proxy_method(divmod)
+ __pow__ = make_proxy_method(pow)
+ __lshift__ = make_proxy_method(operator.lshift)
+ __rshift__ = make_proxy_method(operator.rshift)
+ __and__ = make_proxy_method(operator.and_)
+ __xor__ = make_proxy_method(operator.xor)
+ __or__ = make_proxy_method(operator.or_)
+
+ def __radd__(self, other):
+ return other + self.__wrapped__
+
+ def __rsub__(self, other):
+ return other - self.__wrapped__
+
+ def __rmul__(self, other):
+ return other * self.__wrapped__
+
+ def __rdiv__(self, other):
+ return operator.div(other, self.__wrapped__)
+
+ def __rtruediv__(self, other):
+ return operator.truediv(other, self.__wrapped__)
+
+ def __rfloordiv__(self, other):
+ return other // self.__wrapped__
+
+ def __rmod__(self, other):
+ return other % self.__wrapped__
+
+ def __rdivmod__(self, other):
+ return divmod(other, self.__wrapped__)
+
+ def __rpow__(self, other, *args):
+ return pow(other, self.__wrapped__, *args)
+
+ def __rlshift__(self, other):
+ return other << self.__wrapped__
+
+ def __rrshift__(self, other):
+ return other >> self.__wrapped__
+
+ def __rand__(self, other):
+ return other & self.__wrapped__
+
+ def __rxor__(self, other):
+ return other ^ self.__wrapped__
+
+ def __ror__(self, other):
+ return other | self.__wrapped__
+
+ __iadd__ = make_proxy_method(operator.iadd)
+ __isub__ = make_proxy_method(operator.isub)
+ __imul__ = make_proxy_method(operator.imul)
+ __idiv__ = make_proxy_method(operator.idiv if PY2 else operator.itruediv)
+ __itruediv__ = make_proxy_method(operator.itruediv)
+ __ifloordiv__ = make_proxy_method(operator.ifloordiv)
+ __imod__ = make_proxy_method(operator.imod)
+ __ipow__ = make_proxy_method(operator.ipow)
+ __ilshift__ = make_proxy_method(operator.ilshift)
+ __irshift__ = make_proxy_method(operator.irshift)
+ __iand__ = make_proxy_method(operator.iand)
+ __ixor__ = make_proxy_method(operator.ixor)
+ __ior__ = make_proxy_method(operator.ior)
+ __neg__ = make_proxy_method(operator.neg)
+ __pos__ = make_proxy_method(operator.pos)
+ __abs__ = make_proxy_method(operator.abs)
+ __invert__ = make_proxy_method(operator.invert)
+
+ __int__ = make_proxy_method(int)
+
+ if PY2:
+ __long__ = make_proxy_method(long) # noqa
+
+ __float__ = make_proxy_method(float)
+ __oct__ = make_proxy_method(oct)
+ __hex__ = make_proxy_method(hex)
+ __index__ = make_proxy_method(operator.index)
+ __len__ = make_proxy_method(len)
+ __contains__ = make_proxy_method(operator.contains)
+ __getitem__ = make_proxy_method(operator.getitem)
+ __setitem__ = make_proxy_method(operator.setitem)
+ __delitem__ = make_proxy_method(operator.delitem)
+
+ if PY2:
+ __getslice__ = make_proxy_method(operator.getslice)
+ __setslice__ = make_proxy_method(operator.setslice)
+ __delslice__ = make_proxy_method(operator.delslice)
+
+ def __enter__(self):
+ return self.__wrapped__.__enter__()
+
+ def __exit__(self, *args, **kwargs):
+ return self.__wrapped__.__exit__(*args, **kwargs)
+
+ __iter__ = make_proxy_method(iter)
+
+ def __call__(self, *args, **kwargs):
+ return self.__wrapped__(*args, **kwargs)
+
+ def __reduce__(self):
+ return identity, (self.__wrapped__,)
+
+ def __reduce_ex__(self, protocol):
+ return identity, (self.__wrapped__,)
diff --git a/venv/Lib/site-packages/lazy_object_proxy/slots.py b/venv/Lib/site-packages/lazy_object_proxy/slots.py
new file mode 100644
index 0000000..38668b8
--- /dev/null
+++ b/venv/Lib/site-packages/lazy_object_proxy/slots.py
@@ -0,0 +1,426 @@
+import operator
+
+from .compat import PY2
+from .compat import PY3
+from .compat import string_types
+from .compat import with_metaclass
+from .utils import identity
+
+
+class _ProxyMethods(object):
+ # We use properties to override the values of __module__ and
+ # __doc__. If we add these in ObjectProxy, the derived class
+ # __dict__ will still be setup to have string variants of these
+ # attributes and the rules of descriptors means that they appear to
+ # take precedence over the properties in the base class. To avoid
+ # that, we copy the properties into the derived class type itself
+ # via a meta class. In that way the properties will always take
+ # precedence.
+
+ @property
+ def __module__(self):
+ return self.__wrapped__.__module__
+
+ @__module__.setter
+ def __module__(self, value):
+ self.__wrapped__.__module__ = value
+
+ @property
+ def __doc__(self):
+ return self.__wrapped__.__doc__
+
+ @__doc__.setter
+ def __doc__(self, value):
+ self.__wrapped__.__doc__ = value
+
+ # We similar use a property for __dict__. We need __dict__ to be
+ # explicit to ensure that vars() works as expected.
+
+ @property
+ def __dict__(self):
+ return self.__wrapped__.__dict__
+
+ # Need to also propagate the special __weakref__ attribute for case
+ # where decorating classes which will define this. If do not define
+ # it and use a function like inspect.getmembers() on a decorator
+ # class it will fail. This can't be in the derived classes.
+
+ @property
+ def __weakref__(self):
+ return self.__wrapped__.__weakref__
+
+
+class _ProxyMetaType(type):
+ def __new__(cls, name, bases, dictionary):
+ # Copy our special properties into the class so that they
+ # always take precedence over attributes of the same name added
+ # during construction of a derived class. This is to save
+ # duplicating the implementation for them in all derived classes.
+
+ dictionary.update(vars(_ProxyMethods))
+
+ return type.__new__(cls, name, bases, dictionary)
+
+
+class Proxy(with_metaclass(_ProxyMetaType)):
+ """
+ A proxy implementation in pure Python, using slots. You can subclass this to add
+ local methods or attributes, or enable __dict__.
+
+ The most important internals:
+
+ * ``__factory__`` is the callback that "materializes" the object we proxy to.
+ * ``__target__`` will contain the object we proxy to, once it's "materialized".
+ * ``__wrapped__`` is a property that does either:
+
+ * return ``__target__`` if it's set.
+ * calls ``__factory__``, saves result to ``__target__`` and returns said result.
+ """
+
+ __slots__ = '__target__', '__factory__'
+
+ def __init__(self, factory):
+ object.__setattr__(self, '__factory__', factory)
+
+ @property
+ def __wrapped__(self, __getattr__=object.__getattribute__, __setattr__=object.__setattr__,
+ __delattr__=object.__delattr__):
+ try:
+ return __getattr__(self, '__target__')
+ except AttributeError:
+ try:
+ factory = __getattr__(self, '__factory__')
+ except AttributeError:
+ raise ValueError("Proxy hasn't been initiated: __factory__ is missing.")
+ target = factory()
+ __setattr__(self, '__target__', target)
+ return target
+
+ @__wrapped__.deleter
+ def __wrapped__(self, __delattr__=object.__delattr__):
+ __delattr__(self, '__target__')
+
+ @__wrapped__.setter
+ def __wrapped__(self, target, __setattr__=object.__setattr__):
+ __setattr__(self, '__target__', target)
+
+ @property
+ def __name__(self):
+ return self.__wrapped__.__name__
+
+ @__name__.setter
+ def __name__(self, value):
+ self.__wrapped__.__name__ = value
+
+ @property
+ def __class__(self):
+ return self.__wrapped__.__class__
+
+ @__class__.setter # noqa: F811
+ def __class__(self, value): # noqa: F811
+ self.__wrapped__.__class__ = value
+
+ @property
+ def __annotations__(self):
+ return self.__wrapped__.__anotations__
+
+ @__annotations__.setter
+ def __annotations__(self, value):
+ self.__wrapped__.__annotations__ = value
+
+ def __dir__(self):
+ return dir(self.__wrapped__)
+
+ def __str__(self):
+ return str(self.__wrapped__)
+
+ if PY3:
+ def __bytes__(self):
+ return bytes(self.__wrapped__)
+
+ def __repr__(self, __getattr__=object.__getattribute__):
+ try:
+ target = __getattr__(self, '__target__')
+ except AttributeError:
+ return '<{} at 0x{:x} with factory {!r}>'.format(
+ type(self).__name__, id(self),
+ self.__factory__
+ )
+ else:
+ return '<{} at 0x{:x} wrapping {!r} at 0x{:x} with factory {!r}>'.format(
+ type(self).__name__, id(self),
+ target, id(target),
+ self.__factory__
+ )
+
+ def __fspath__(self):
+ wrapped = self.__wrapped__
+ if isinstance(wrapped, string_types):
+ return wrapped
+ else:
+ fspath = getattr(wrapped, '__fspath__', None)
+ if fspath is None:
+ return wrapped
+ else:
+ return fspath()
+
+ def __reversed__(self):
+ return reversed(self.__wrapped__)
+
+ if PY3:
+ def __round__(self):
+ return round(self.__wrapped__)
+
+ def __lt__(self, other):
+ return self.__wrapped__ < other
+
+ def __le__(self, other):
+ return self.__wrapped__ <= other
+
+ def __eq__(self, other):
+ return self.__wrapped__ == other
+
+ def __ne__(self, other):
+ return self.__wrapped__ != other
+
+ def __gt__(self, other):
+ return self.__wrapped__ > other
+
+ def __ge__(self, other):
+ return self.__wrapped__ >= other
+
+ def __hash__(self):
+ return hash(self.__wrapped__)
+
+ def __nonzero__(self):
+ return bool(self.__wrapped__)
+
+ def __bool__(self):
+ return bool(self.__wrapped__)
+
+ def __setattr__(self, name, value, __setattr__=object.__setattr__):
+ if hasattr(type(self), name):
+ __setattr__(self, name, value)
+ else:
+ setattr(self.__wrapped__, name, value)
+
+ def __getattr__(self, name):
+ if name in ('__wrapped__', '__factory__'):
+ raise AttributeError(name)
+ else:
+ return getattr(self.__wrapped__, name)
+
+ def __delattr__(self, name, __delattr__=object.__delattr__):
+ if hasattr(type(self), name):
+ __delattr__(self, name)
+ else:
+ delattr(self.__wrapped__, name)
+
+ def __add__(self, other):
+ return self.__wrapped__ + other
+
+ def __sub__(self, other):
+ return self.__wrapped__ - other
+
+ def __mul__(self, other):
+ return self.__wrapped__ * other
+
+ def __div__(self, other):
+ return operator.div(self.__wrapped__, other)
+
+ def __truediv__(self, other):
+ return operator.truediv(self.__wrapped__, other)
+
+ def __floordiv__(self, other):
+ return self.__wrapped__ // other
+
+ def __mod__(self, other):
+ return self.__wrapped__ % other
+
+ def __divmod__(self, other):
+ return divmod(self.__wrapped__, other)
+
+ def __pow__(self, other, *args):
+ return pow(self.__wrapped__, other, *args)
+
+ def __lshift__(self, other):
+ return self.__wrapped__ << other
+
+ def __rshift__(self, other):
+ return self.__wrapped__ >> other
+
+ def __and__(self, other):
+ return self.__wrapped__ & other
+
+ def __xor__(self, other):
+ return self.__wrapped__ ^ other
+
+ def __or__(self, other):
+ return self.__wrapped__ | other
+
+ def __radd__(self, other):
+ return other + self.__wrapped__
+
+ def __rsub__(self, other):
+ return other - self.__wrapped__
+
+ def __rmul__(self, other):
+ return other * self.__wrapped__
+
+ def __rdiv__(self, other):
+ return operator.div(other, self.__wrapped__)
+
+ def __rtruediv__(self, other):
+ return operator.truediv(other, self.__wrapped__)
+
+ def __rfloordiv__(self, other):
+ return other // self.__wrapped__
+
+ def __rmod__(self, other):
+ return other % self.__wrapped__
+
+ def __rdivmod__(self, other):
+ return divmod(other, self.__wrapped__)
+
+ def __rpow__(self, other, *args):
+ return pow(other, self.__wrapped__, *args)
+
+ def __rlshift__(self, other):
+ return other << self.__wrapped__
+
+ def __rrshift__(self, other):
+ return other >> self.__wrapped__
+
+ def __rand__(self, other):
+ return other & self.__wrapped__
+
+ def __rxor__(self, other):
+ return other ^ self.__wrapped__
+
+ def __ror__(self, other):
+ return other | self.__wrapped__
+
+ def __iadd__(self, other):
+ self.__wrapped__ += other
+ return self
+
+ def __isub__(self, other):
+ self.__wrapped__ -= other
+ return self
+
+ def __imul__(self, other):
+ self.__wrapped__ *= other
+ return self
+
+ def __idiv__(self, other):
+ self.__wrapped__ = operator.idiv(self.__wrapped__, other)
+ return self
+
+ def __itruediv__(self, other):
+ self.__wrapped__ = operator.itruediv(self.__wrapped__, other)
+ return self
+
+ def __ifloordiv__(self, other):
+ self.__wrapped__ //= other
+ return self
+
+ def __imod__(self, other):
+ self.__wrapped__ %= other
+ return self
+
+ def __ipow__(self, other):
+ self.__wrapped__ **= other
+ return self
+
+ def __ilshift__(self, other):
+ self.__wrapped__ <<= other
+ return self
+
+ def __irshift__(self, other):
+ self.__wrapped__ >>= other
+ return self
+
+ def __iand__(self, other):
+ self.__wrapped__ &= other
+ return self
+
+ def __ixor__(self, other):
+ self.__wrapped__ ^= other
+ return self
+
+ def __ior__(self, other):
+ self.__wrapped__ |= other
+ return self
+
+ def __neg__(self):
+ return -self.__wrapped__
+
+ def __pos__(self):
+ return +self.__wrapped__
+
+ def __abs__(self):
+ return abs(self.__wrapped__)
+
+ def __invert__(self):
+ return ~self.__wrapped__
+
+ def __int__(self):
+ return int(self.__wrapped__)
+
+ if PY2:
+ def __long__(self):
+ return long(self.__wrapped__) # noqa
+
+ def __float__(self):
+ return float(self.__wrapped__)
+
+ def __oct__(self):
+ return oct(self.__wrapped__)
+
+ def __hex__(self):
+ return hex(self.__wrapped__)
+
+ def __index__(self):
+ return operator.index(self.__wrapped__)
+
+ def __len__(self):
+ return len(self.__wrapped__)
+
+ def __contains__(self, value):
+ return value in self.__wrapped__
+
+ def __getitem__(self, key):
+ return self.__wrapped__[key]
+
+ def __setitem__(self, key, value):
+ self.__wrapped__[key] = value
+
+ def __delitem__(self, key):
+ del self.__wrapped__[key]
+
+ def __getslice__(self, i, j):
+ return self.__wrapped__[i:j]
+
+ def __setslice__(self, i, j, value):
+ self.__wrapped__[i:j] = value
+
+ def __delslice__(self, i, j):
+ del self.__wrapped__[i:j]
+
+ def __enter__(self):
+ return self.__wrapped__.__enter__()
+
+ def __exit__(self, *args, **kwargs):
+ return self.__wrapped__.__exit__(*args, **kwargs)
+
+ def __iter__(self):
+ return iter(self.__wrapped__)
+
+ def __call__(self, *args, **kwargs):
+ return self.__wrapped__(*args, **kwargs)
+
+ def __reduce__(self):
+ return identity, (self.__wrapped__,)
+
+ def __reduce_ex__(self, protocol):
+ return identity, (self.__wrapped__,)
diff --git a/venv/Lib/site-packages/lazy_object_proxy/utils.py b/venv/Lib/site-packages/lazy_object_proxy/utils.py
new file mode 100644
index 0000000..ceb3050
--- /dev/null
+++ b/venv/Lib/site-packages/lazy_object_proxy/utils.py
@@ -0,0 +1,13 @@
+def identity(obj):
+ return obj
+
+
+class cached_property(object):
+ def __init__(self, func):
+ self.func = func
+
+ def __get__(self, obj, cls):
+ if obj is None:
+ return self
+ value = obj.__dict__[self.func.__name__] = self.func(obj)
+ return value
diff --git a/venv/Lib/site-packages/six-1.15.0.dist-info/INSTALLER b/venv/Lib/site-packages/six-1.15.0.dist-info/INSTALLER
new file mode 100644
index 0000000..a1b589e
--- /dev/null
+++ b/venv/Lib/site-packages/six-1.15.0.dist-info/INSTALLER
@@ -0,0 +1 @@
+pip
diff --git a/venv/Lib/site-packages/six-1.15.0.dist-info/LICENSE b/venv/Lib/site-packages/six-1.15.0.dist-info/LICENSE
new file mode 100644
index 0000000..de66331
--- /dev/null
+++ b/venv/Lib/site-packages/six-1.15.0.dist-info/LICENSE
@@ -0,0 +1,18 @@
+Copyright (c) 2010-2020 Benjamin Peterson
+
+Permission is hereby granted, free of charge, to any person obtaining a copy of
+this software and associated documentation files (the "Software"), to deal in
+the Software without restriction, including without limitation the rights to
+use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
+the Software, and to permit persons to whom the Software is furnished to do so,
+subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
+FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
+COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
+IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
+CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
diff --git a/venv/Lib/site-packages/six-1.15.0.dist-info/METADATA b/venv/Lib/site-packages/six-1.15.0.dist-info/METADATA
new file mode 100644
index 0000000..869bf25
--- /dev/null
+++ b/venv/Lib/site-packages/six-1.15.0.dist-info/METADATA
@@ -0,0 +1,49 @@
+Metadata-Version: 2.1
+Name: six
+Version: 1.15.0
+Summary: Python 2 and 3 compatibility utilities
+Home-page: https://github.com/benjaminp/six
+Author: Benjamin Peterson
+Author-email: benjamin@python.org
+License: MIT
+Platform: UNKNOWN
+Classifier: Development Status :: 5 - Production/Stable
+Classifier: Programming Language :: Python :: 2
+Classifier: Programming Language :: Python :: 3
+Classifier: Intended Audience :: Developers
+Classifier: License :: OSI Approved :: MIT License
+Classifier: Topic :: Software Development :: Libraries
+Classifier: Topic :: Utilities
+Requires-Python: >=2.7, !=3.0.*, !=3.1.*, !=3.2.*
+
+.. image:: https://img.shields.io/pypi/v/six.svg
+ :target: https://pypi.org/project/six/
+ :alt: six on PyPI
+
+.. image:: https://travis-ci.org/benjaminp/six.svg?branch=master
+ :target: https://travis-ci.org/benjaminp/six
+ :alt: six on TravisCI
+
+.. image:: https://readthedocs.org/projects/six/badge/?version=latest
+ :target: https://six.readthedocs.io/
+ :alt: six's documentation on Read the Docs
+
+.. image:: https://img.shields.io/badge/license-MIT-green.svg
+ :target: https://github.com/benjaminp/six/blob/master/LICENSE
+ :alt: MIT License badge
+
+Six is a Python 2 and 3 compatibility library. It provides utility functions
+for smoothing over the differences between the Python versions with the goal of
+writing Python code that is compatible on both Python versions. See the
+documentation for more information on what is provided.
+
+Six supports Python 2.7 and 3.3+. It is contained in only one Python
+file, so it can be easily copied into your project. (The copyright and license
+notice must be retained.)
+
+Online documentation is at https://six.readthedocs.io/.
+
+Bugs can be reported to https://github.com/benjaminp/six. The code can also
+be found there.
+
+
diff --git a/venv/Lib/site-packages/six-1.15.0.dist-info/RECORD b/venv/Lib/site-packages/six-1.15.0.dist-info/RECORD
new file mode 100644
index 0000000..c38259f
--- /dev/null
+++ b/venv/Lib/site-packages/six-1.15.0.dist-info/RECORD
@@ -0,0 +1,9 @@
+__pycache__/six.cpython-38.pyc,,
+six-1.15.0.dist-info/INSTALLER,sha256=zuuue4knoyJ-UwPPXg8fezS7VCrXJQrAP7zeNuwvFQg,4
+six-1.15.0.dist-info/LICENSE,sha256=i7hQxWWqOJ_cFvOkaWWtI9gq3_YPI5P8J2K2MYXo5sk,1066
+six-1.15.0.dist-info/METADATA,sha256=W6rlyoeMZHXh6srP9NXNsm0rjAf_660re8WdH5TBT8E,1795
+six-1.15.0.dist-info/RECORD,,
+six-1.15.0.dist-info/REQUESTED,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+six-1.15.0.dist-info/WHEEL,sha256=kGT74LWyRUZrL4VgLh6_g12IeVl_9u9ZVhadrgXZUEY,110
+six-1.15.0.dist-info/top_level.txt,sha256=_iVH_iYEtEXnD8nYGQYpYFUvkUW9sEO1GYbkeKSAais,4
+six.py,sha256=U4Z_yv534W5CNyjY9i8V1OXY2SjAny8y2L5vDLhhThM,34159
diff --git a/venv/Lib/site-packages/six-1.15.0.dist-info/REQUESTED b/venv/Lib/site-packages/six-1.15.0.dist-info/REQUESTED
new file mode 100644
index 0000000..e69de29
diff --git a/venv/Lib/site-packages/six-1.15.0.dist-info/WHEEL b/venv/Lib/site-packages/six-1.15.0.dist-info/WHEEL
new file mode 100644
index 0000000..ef99c6c
--- /dev/null
+++ b/venv/Lib/site-packages/six-1.15.0.dist-info/WHEEL
@@ -0,0 +1,6 @@
+Wheel-Version: 1.0
+Generator: bdist_wheel (0.34.2)
+Root-Is-Purelib: true
+Tag: py2-none-any
+Tag: py3-none-any
+
diff --git a/venv/Lib/site-packages/six-1.15.0.dist-info/top_level.txt b/venv/Lib/site-packages/six-1.15.0.dist-info/top_level.txt
new file mode 100644
index 0000000..ffe2fce
--- /dev/null
+++ b/venv/Lib/site-packages/six-1.15.0.dist-info/top_level.txt
@@ -0,0 +1 @@
+six
diff --git a/venv/Lib/site-packages/six.py b/venv/Lib/site-packages/six.py
new file mode 100644
index 0000000..83f6978
--- /dev/null
+++ b/venv/Lib/site-packages/six.py
@@ -0,0 +1,982 @@
+# Copyright (c) 2010-2020 Benjamin Peterson
+#
+# Permission is hereby granted, free of charge, to any person obtaining a copy
+# of this software and associated documentation files (the "Software"), to deal
+# in the Software without restriction, including without limitation the rights
+# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+# copies of the Software, and to permit persons to whom the Software is
+# furnished to do so, subject to the following conditions:
+#
+# The above copyright notice and this permission notice shall be included in all
+# copies or substantial portions of the Software.
+#
+# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+# SOFTWARE.
+
+"""Utilities for writing code that runs on Python 2 and 3"""
+
+from __future__ import absolute_import
+
+import functools
+import itertools
+import operator
+import sys
+import types
+
+__author__ = "Benjamin Peterson <benjamin@python.org>"
+__version__ = "1.15.0"
+
+
+# Useful for very coarse version differentiation.
+PY2 = sys.version_info[0] == 2
+PY3 = sys.version_info[0] == 3
+PY34 = sys.version_info[0:2] >= (3, 4)
+
+if PY3:
+ string_types = str,
+ integer_types = int,
+ class_types = type,
+ text_type = str
+ binary_type = bytes
+
+ MAXSIZE = sys.maxsize
+else:
+ string_types = basestring,
+ integer_types = (int, long)
+ class_types = (type, types.ClassType)
+ text_type = unicode
+ binary_type = str
+
+ if sys.platform.startswith("java"):
+ # Jython always uses 32 bits.
+ MAXSIZE = int((1 << 31) - 1)
+ else:
+ # It's possible to have sizeof(long) != sizeof(Py_ssize_t).
+ class X(object):
+
+ def __len__(self):
+ return 1 << 31
+ try:
+ len(X())
+ except OverflowError:
+ # 32-bit
+ MAXSIZE = int((1 << 31) - 1)
+ else:
+ # 64-bit
+ MAXSIZE = int((1 << 63) - 1)
+ del X
+
+
+def _add_doc(func, doc):
+ """Add documentation to a function."""
+ func.__doc__ = doc
+
+
+def _import_module(name):
+ """Import module, returning the module after the last dot."""
+ __import__(name)
+ return sys.modules[name]
+
+
+class _LazyDescr(object):
+
+ def __init__(self, name):
+ self.name = name
+
+ def __get__(self, obj, tp):
+ result = self._resolve()
+ setattr(obj, self.name, result) # Invokes __set__.
+ try:
+ # This is a bit ugly, but it avoids running this again by
+ # removing this descriptor.
+ delattr(obj.__class__, self.name)
+ except AttributeError:
+ pass
+ return result
+
+
+class MovedModule(_LazyDescr):
+
+ def __init__(self, name, old, new=None):
+ super(MovedModule, self).__init__(name)
+ if PY3:
+ if new is None:
+ new = name
+ self.mod = new
+ else:
+ self.mod = old
+
+ def _resolve(self):
+ return _import_module(self.mod)
+
+ def __getattr__(self, attr):
+ _module = self._resolve()
+ value = getattr(_module, attr)
+ setattr(self, attr, value)
+ return value
+
+
+class _LazyModule(types.ModuleType):
+
+ def __init__(self, name):
+ super(_LazyModule, self).__init__(name)
+ self.__doc__ = self.__class__.__doc__
+
+ def __dir__(self):
+ attrs = ["__doc__", "__name__"]
+ attrs += [attr.name for attr in self._moved_attributes]
+ return attrs
+
+ # Subclasses should override this
+ _moved_attributes = []
+
+
+class MovedAttribute(_LazyDescr):
+
+ def __init__(self, name, old_mod, new_mod, old_attr=None, new_attr=None):
+ super(MovedAttribute, self).__init__(name)
+ if PY3:
+ if new_mod is None:
+ new_mod = name
+ self.mod = new_mod
+ if new_attr is None:
+ if old_attr is None:
+ new_attr = name
+ else:
+ new_attr = old_attr
+ self.attr = new_attr
+ else:
+ self.mod = old_mod
+ if old_attr is None:
+ old_attr = name
+ self.attr = old_attr
+
+ def _resolve(self):
+ module = _import_module(self.mod)
+ return getattr(module, self.attr)
+
+
+class _SixMetaPathImporter(object):
+
+ """
+ A meta path importer to import six.moves and its submodules.
+
+ This class implements a PEP302 finder and loader. It should be compatible
+ with Python 2.5 and all existing versions of Python3
+ """
+
+ def __init__(self, six_module_name):
+ self.name = six_module_name
+ self.known_modules = {}
+
+ def _add_module(self, mod, *fullnames):
+ for fullname in fullnames:
+ self.known_modules[self.name + "." + fullname] = mod
+
+ def _get_module(self, fullname):
+ return self.known_modules[self.name + "." + fullname]
+
+ def find_module(self, fullname, path=None):
+ if fullname in self.known_modules:
+ return self
+ return None
+
+ def __get_module(self, fullname):
+ try:
+ return self.known_modules[fullname]
+ except KeyError:
+ raise ImportError("This loader does not know module " + fullname)
+
+ def load_module(self, fullname):
+ try:
+ # in case of a reload
+ return sys.modules[fullname]
+ except KeyError:
+ pass
+ mod = self.__get_module(fullname)
+ if isinstance(mod, MovedModule):
+ mod = mod._resolve()
+ else:
+ mod.__loader__ = self
+ sys.modules[fullname] = mod
+ return mod
+
+ def is_package(self, fullname):
+ """
+ Return true, if the named module is a package.
+
+ We need this method to get correct spec objects with
+ Python 3.4 (see PEP451)
+ """
+ return hasattr(self.__get_module(fullname), "__path__")
+
+ def get_code(self, fullname):
+ """Return None
+
+ Required, if is_package is implemented"""
+ self.__get_module(fullname) # eventually raises ImportError
+ return None
+ get_source = get_code # same as get_code
+
+_importer = _SixMetaPathImporter(__name__)
+
+
+class _MovedItems(_LazyModule):
+
+ """Lazy loading of moved objects"""
+ __path__ = [] # mark as package
+
+
+_moved_attributes = [
+ MovedAttribute("cStringIO", "cStringIO", "io", "StringIO"),
+ MovedAttribute("filter", "itertools", "builtins", "ifilter", "filter"),
+ MovedAttribute("filterfalse", "itertools", "itertools", "ifilterfalse", "filterfalse"),
+ MovedAttribute("input", "__builtin__", "builtins", "raw_input", "input"),
+ MovedAttribute("intern", "__builtin__", "sys"),
+ MovedAttribute("map", "itertools", "builtins", "imap", "map"),
+ MovedAttribute("getcwd", "os", "os", "getcwdu", "getcwd"),
+ MovedAttribute("getcwdb", "os", "os", "getcwd", "getcwdb"),
+ MovedAttribute("getoutput", "commands", "subprocess"),
+ MovedAttribute("range", "__builtin__", "builtins", "xrange", "range"),
+ MovedAttribute("reload_module", "__builtin__", "importlib" if PY34 else "imp", "reload"),
+ MovedAttribute("reduce", "__builtin__", "functools"),
+ MovedAttribute("shlex_quote", "pipes", "shlex", "quote"),
+ MovedAttribute("StringIO", "StringIO", "io"),
+ MovedAttribute("UserDict", "UserDict", "collections"),
+ MovedAttribute("UserList", "UserList", "collections"),
+ MovedAttribute("UserString", "UserString", "collections"),
+ MovedAttribute("xrange", "__builtin__", "builtins", "xrange", "range"),
+ MovedAttribute("zip", "itertools", "builtins", "izip", "zip"),
+ MovedAttribute("zip_longest", "itertools", "itertools", "izip_longest", "zip_longest"),
+ MovedModule("builtins", "__builtin__"),
+ MovedModule("configparser", "ConfigParser"),
+ MovedModule("collections_abc", "collections", "collections.abc" if sys.version_info >= (3, 3) else "collections"),
+ MovedModule("copyreg", "copy_reg"),
+ MovedModule("dbm_gnu", "gdbm", "dbm.gnu"),
+ MovedModule("dbm_ndbm", "dbm", "dbm.ndbm"),
+ MovedModule("_dummy_thread", "dummy_thread", "_dummy_thread" if sys.version_info < (3, 9) else "_thread"),
+ MovedModule("http_cookiejar", "cookielib", "http.cookiejar"),
+ MovedModule("http_cookies", "Cookie", "http.cookies"),
+ MovedModule("html_entities", "htmlentitydefs", "html.entities"),
+ MovedModule("html_parser", "HTMLParser", "html.parser"),
+ MovedModule("http_client", "httplib", "http.client"),
+ MovedModule("email_mime_base", "email.MIMEBase", "email.mime.base"),
+ MovedModule("email_mime_image", "email.MIMEImage", "email.mime.image"),
+ MovedModule("email_mime_multipart", "email.MIMEMultipart", "email.mime.multipart"),
+ MovedModule("email_mime_nonmultipart", "email.MIMENonMultipart", "email.mime.nonmultipart"),
+ MovedModule("email_mime_text", "email.MIMEText", "email.mime.text"),
+ MovedModule("BaseHTTPServer", "BaseHTTPServer", "http.server"),
+ MovedModule("CGIHTTPServer", "CGIHTTPServer", "http.server"),
+ MovedModule("SimpleHTTPServer", "SimpleHTTPServer", "http.server"),
+ MovedModule("cPickle", "cPickle", "pickle"),
+ MovedModule("queue", "Queue"),
+ MovedModule("reprlib", "repr"),
+ MovedModule("socketserver", "SocketServer"),
+ MovedModule("_thread", "thread", "_thread"),
+ MovedModule("tkinter", "Tkinter"),
+ MovedModule("tkinter_dialog", "Dialog", "tkinter.dialog"),
+ MovedModule("tkinter_filedialog", "FileDialog", "tkinter.filedialog"),
+ MovedModule("tkinter_scrolledtext", "ScrolledText", "tkinter.scrolledtext"),
+ MovedModule("tkinter_simpledialog", "SimpleDialog", "tkinter.simpledialog"),
+ MovedModule("tkinter_tix", "Tix", "tkinter.tix"),
+ MovedModule("tkinter_ttk", "ttk", "tkinter.ttk"),
+ MovedModule("tkinter_constants", "Tkconstants", "tkinter.constants"),
+ MovedModule("tkinter_dnd", "Tkdnd", "tkinter.dnd"),
+ MovedModule("tkinter_colorchooser", "tkColorChooser",
+ "tkinter.colorchooser"),
+ MovedModule("tkinter_commondialog", "tkCommonDialog",
+ "tkinter.commondialog"),
+ MovedModule("tkinter_tkfiledialog", "tkFileDialog", "tkinter.filedialog"),
+ MovedModule("tkinter_font", "tkFont", "tkinter.font"),
+ MovedModule("tkinter_messagebox", "tkMessageBox", "tkinter.messagebox"),
+ MovedModule("tkinter_tksimpledialog", "tkSimpleDialog",
+ "tkinter.simpledialog"),
+ MovedModule("urllib_parse", __name__ + ".moves.urllib_parse", "urllib.parse"),
+ MovedModule("urllib_error", __name__ + ".moves.urllib_error", "urllib.error"),
+ MovedModule("urllib", __name__ + ".moves.urllib", __name__ + ".moves.urllib"),
+ MovedModule("urllib_robotparser", "robotparser", "urllib.robotparser"),
+ MovedModule("xmlrpc_client", "xmlrpclib", "xmlrpc.client"),
+ MovedModule("xmlrpc_server", "SimpleXMLRPCServer", "xmlrpc.server"),
+]
+# Add windows specific modules.
+if sys.platform == "win32":
+ _moved_attributes += [
+ MovedModule("winreg", "_winreg"),
+ ]
+
+for attr in _moved_attributes:
+ setattr(_MovedItems, attr.name, attr)
+ if isinstance(attr, MovedModule):
+ _importer._add_module(attr, "moves." + attr.name)
+del attr
+
+_MovedItems._moved_attributes = _moved_attributes
+
+moves = _MovedItems(__name__ + ".moves")
+_importer._add_module(moves, "moves")
+
+
+class Module_six_moves_urllib_parse(_LazyModule):
+
+ """Lazy loading of moved objects in six.moves.urllib_parse"""
+
+
+_urllib_parse_moved_attributes = [
+ MovedAttribute("ParseResult", "urlparse", "urllib.parse"),
+ MovedAttribute("SplitResult", "urlparse", "urllib.parse"),
+ MovedAttribute("parse_qs", "urlparse", "urllib.parse"),
+ MovedAttribute("parse_qsl", "urlparse", "urllib.parse"),
+ MovedAttribute("urldefrag", "urlparse", "urllib.parse"),
+ MovedAttribute("urljoin", "urlparse", "urllib.parse"),
+ MovedAttribute("urlparse", "urlparse", "urllib.parse"),
+ MovedAttribute("urlsplit", "urlparse", "urllib.parse"),
+ MovedAttribute("urlunparse", "urlparse", "urllib.parse"),
+ MovedAttribute("urlunsplit", "urlparse", "urllib.parse"),
+ MovedAttribute("quote", "urllib", "urllib.parse"),
+ MovedAttribute("quote_plus", "urllib", "urllib.parse"),
+ MovedAttribute("unquote", "urllib", "urllib.parse"),
+ MovedAttribute("unquote_plus", "urllib", "urllib.parse"),
+ MovedAttribute("unquote_to_bytes", "urllib", "urllib.parse", "unquote", "unquote_to_bytes"),
+ MovedAttribute("urlencode", "urllib", "urllib.parse"),
+ MovedAttribute("splitquery", "urllib", "urllib.parse"),
+ MovedAttribute("splittag", "urllib", "urllib.parse"),
+ MovedAttribute("splituser", "urllib", "urllib.parse"),
+ MovedAttribute("splitvalue", "urllib", "urllib.parse"),
+ MovedAttribute("uses_fragment", "urlparse", "urllib.parse"),
+ MovedAttribute("uses_netloc", "urlparse", "urllib.parse"),
+ MovedAttribute("uses_params", "urlparse", "urllib.parse"),
+ MovedAttribute("uses_query", "urlparse", "urllib.parse"),
+ MovedAttribute("uses_relative", "urlparse", "urllib.parse"),
+]
+for attr in _urllib_parse_moved_attributes:
+ setattr(Module_six_moves_urllib_parse, attr.name, attr)
+del attr
+
+Module_six_moves_urllib_parse._moved_attributes = _urllib_parse_moved_attributes
+
+_importer._add_module(Module_six_moves_urllib_parse(__name__ + ".moves.urllib_parse"),
+ "moves.urllib_parse", "moves.urllib.parse")
+
+
+class Module_six_moves_urllib_error(_LazyModule):
+
+ """Lazy loading of moved objects in six.moves.urllib_error"""
+
+
+_urllib_error_moved_attributes = [
+ MovedAttribute("URLError", "urllib2", "urllib.error"),
+ MovedAttribute("HTTPError", "urllib2", "urllib.error"),
+ MovedAttribute("ContentTooShortError", "urllib", "urllib.error"),
+]
+for attr in _urllib_error_moved_attributes:
+ setattr(Module_six_moves_urllib_error, attr.name, attr)
+del attr
+
+Module_six_moves_urllib_error._moved_attributes = _urllib_error_moved_attributes
+
+_importer._add_module(Module_six_moves_urllib_error(__name__ + ".moves.urllib.error"),
+ "moves.urllib_error", "moves.urllib.error")
+
+
+class Module_six_moves_urllib_request(_LazyModule):
+
+ """Lazy loading of moved objects in six.moves.urllib_request"""
+
+
+_urllib_request_moved_attributes = [
+ MovedAttribute("urlopen", "urllib2", "urllib.request"),
+ MovedAttribute("install_opener", "urllib2", "urllib.request"),
+ MovedAttribute("build_opener", "urllib2", "urllib.request"),
+ MovedAttribute("pathname2url", "urllib", "urllib.request"),
+ MovedAttribute("url2pathname", "urllib", "urllib.request"),
+ MovedAttribute("getproxies", "urllib", "urllib.request"),
+ MovedAttribute("Request", "urllib2", "urllib.request"),
+ MovedAttribute("OpenerDirector", "urllib2", "urllib.request"),
+ MovedAttribute("HTTPDefaultErrorHandler", "urllib2", "urllib.request"),
+ MovedAttribute("HTTPRedirectHandler", "urllib2", "urllib.request"),
+ MovedAttribute("HTTPCookieProcessor", "urllib2", "urllib.request"),
+ MovedAttribute("ProxyHandler", "urllib2", "urllib.request"),
+ MovedAttribute("BaseHandler", "urllib2", "urllib.request"),
+ MovedAttribute("HTTPPasswordMgr", "urllib2", "urllib.request"),
+ MovedAttribute("HTTPPasswordMgrWithDefaultRealm", "urllib2", "urllib.request"),
+ MovedAttribute("AbstractBasicAuthHandler", "urllib2", "urllib.request"),
+ MovedAttribute("HTTPBasicAuthHandler", "urllib2", "urllib.request"),
+ MovedAttribute("ProxyBasicAuthHandler", "urllib2", "urllib.request"),
+ MovedAttribute("AbstractDigestAuthHandler", "urllib2", "urllib.request"),
+ MovedAttribute("HTTPDigestAuthHandler", "urllib2", "urllib.request"),
+ MovedAttribute("ProxyDigestAuthHandler", "urllib2", "urllib.request"),
+ MovedAttribute("HTTPHandler", "urllib2", "urllib.request"),
+ MovedAttribute("HTTPSHandler", "urllib2", "urllib.request"),
+ MovedAttribute("FileHandler", "urllib2", "urllib.request"),
+ MovedAttribute("FTPHandler", "urllib2", "urllib.request"),
+ MovedAttribute("CacheFTPHandler", "urllib2", "urllib.request"),
+ MovedAttribute("UnknownHandler", "urllib2", "urllib.request"),
+ MovedAttribute("HTTPErrorProcessor", "urllib2", "urllib.request"),
+ MovedAttribute("urlretrieve", "urllib", "urllib.request"),
+ MovedAttribute("urlcleanup", "urllib", "urllib.request"),
+ MovedAttribute("URLopener", "urllib", "urllib.request"),
+ MovedAttribute("FancyURLopener", "urllib", "urllib.request"),
+ MovedAttribute("proxy_bypass", "urllib", "urllib.request"),
+ MovedAttribute("parse_http_list", "urllib2", "urllib.request"),
+ MovedAttribute("parse_keqv_list", "urllib2", "urllib.request"),
+]
+for attr in _urllib_request_moved_attributes:
+ setattr(Module_six_moves_urllib_request, attr.name, attr)
+del attr
+
+Module_six_moves_urllib_request._moved_attributes = _urllib_request_moved_attributes
+
+_importer._add_module(Module_six_moves_urllib_request(__name__ + ".moves.urllib.request"),
+ "moves.urllib_request", "moves.urllib.request")
+
+
+class Module_six_moves_urllib_response(_LazyModule):
+
+ """Lazy loading of moved objects in six.moves.urllib_response"""
+
+
+_urllib_response_moved_attributes = [
+ MovedAttribute("addbase", "urllib", "urllib.response"),
+ MovedAttribute("addclosehook", "urllib", "urllib.response"),
+ MovedAttribute("addinfo", "urllib", "urllib.response"),
+ MovedAttribute("addinfourl", "urllib", "urllib.response"),
+]
+for attr in _urllib_response_moved_attributes:
+ setattr(Module_six_moves_urllib_response, attr.name, attr)
+del attr
+
+Module_six_moves_urllib_response._moved_attributes = _urllib_response_moved_attributes
+
+_importer._add_module(Module_six_moves_urllib_response(__name__ + ".moves.urllib.response"),
+ "moves.urllib_response", "moves.urllib.response")
+
+
+class Module_six_moves_urllib_robotparser(_LazyModule):
+
+ """Lazy loading of moved objects in six.moves.urllib_robotparser"""
+
+
+_urllib_robotparser_moved_attributes = [
+ MovedAttribute("RobotFileParser", "robotparser", "urllib.robotparser"),
+]
+for attr in _urllib_robotparser_moved_attributes:
+ setattr(Module_six_moves_urllib_robotparser, attr.name, attr)
+del attr
+
+Module_six_moves_urllib_robotparser._moved_attributes = _urllib_robotparser_moved_attributes
+
+_importer._add_module(Module_six_moves_urllib_robotparser(__name__ + ".moves.urllib.robotparser"),
+ "moves.urllib_robotparser", "moves.urllib.robotparser")
+
+
+class Module_six_moves_urllib(types.ModuleType):
+
+ """Create a six.moves.urllib namespace that resembles the Python 3 namespace"""
+ __path__ = [] # mark as package
+ parse = _importer._get_module("moves.urllib_parse")
+ error = _importer._get_module("moves.urllib_error")
+ request = _importer._get_module("moves.urllib_request")
+ response = _importer._get_module("moves.urllib_response")
+ robotparser = _importer._get_module("moves.urllib_robotparser")
+
+ def __dir__(self):
+ return ['parse', 'error', 'request', 'response', 'robotparser']
+
+_importer._add_module(Module_six_moves_urllib(__name__ + ".moves.urllib"),
+ "moves.urllib")
+
+
+def add_move(move):
+ """Add an item to six.moves."""
+ setattr(_MovedItems, move.name, move)
+
+
+def remove_move(name):
+ """Remove item from six.moves."""
+ try:
+ delattr(_MovedItems, name)
+ except AttributeError:
+ try:
+ del moves.__dict__[name]
+ except KeyError:
+ raise AttributeError("no such move, %r" % (name,))
+
+
+if PY3:
+ _meth_func = "__func__"
+ _meth_self = "__self__"
+
+ _func_closure = "__closure__"
+ _func_code = "__code__"
+ _func_defaults = "__defaults__"
+ _func_globals = "__globals__"
+else:
+ _meth_func = "im_func"
+ _meth_self = "im_self"
+
+ _func_closure = "func_closure"
+ _func_code = "func_code"
+ _func_defaults = "func_defaults"
+ _func_globals = "func_globals"
+
+
+try:
+ advance_iterator = next
+except NameError:
+ def advance_iterator(it):
+ return it.next()
+next = advance_iterator
+
+
+try:
+ callable = callable
+except NameError:
+ def callable(obj):
+ return any("__call__" in klass.__dict__ for klass in type(obj).__mro__)
+
+
+if PY3:
+ def get_unbound_function(unbound):
+ return unbound
+
+ create_bound_method = types.MethodType
+
+ def create_unbound_method(func, cls):
+ return func
+
+ Iterator = object
+else:
+ def get_unbound_function(unbound):
+ return unbound.im_func
+
+ def create_bound_method(func, obj):
+ return types.MethodType(func, obj, obj.__class__)
+
+ def create_unbound_method(func, cls):
+ return types.MethodType(func, None, cls)
+
+ class Iterator(object):
+
+ def next(self):
+ return type(self).__next__(self)
+
+ callable = callable
+_add_doc(get_unbound_function,
+ """Get the function out of a possibly unbound function""")
+
+
+get_method_function = operator.attrgetter(_meth_func)
+get_method_self = operator.attrgetter(_meth_self)
+get_function_closure = operator.attrgetter(_func_closure)
+get_function_code = operator.attrgetter(_func_code)
+get_function_defaults = operator.attrgetter(_func_defaults)
+get_function_globals = operator.attrgetter(_func_globals)
+
+
+if PY3:
+ def iterkeys(d, **kw):
+ return iter(d.keys(**kw))
+
+ def itervalues(d, **kw):
+ return iter(d.values(**kw))
+
+ def iteritems(d, **kw):
+ return iter(d.items(**kw))
+
+ def iterlists(d, **kw):
+ return iter(d.lists(**kw))
+
+ viewkeys = operator.methodcaller("keys")
+
+ viewvalues = operator.methodcaller("values")
+
+ viewitems = operator.methodcaller("items")
+else:
+ def iterkeys(d, **kw):
+ return d.iterkeys(**kw)
+
+ def itervalues(d, **kw):
+ return d.itervalues(**kw)
+
+ def iteritems(d, **kw):
+ return d.iteritems(**kw)
+
+ def iterlists(d, **kw):
+ return d.iterlists(**kw)
+
+ viewkeys = operator.methodcaller("viewkeys")
+
+ viewvalues = operator.methodcaller("viewvalues")
+
+ viewitems = operator.methodcaller("viewitems")
+
+_add_doc(iterkeys, "Return an iterator over the keys of a dictionary.")
+_add_doc(itervalues, "Return an iterator over the values of a dictionary.")
+_add_doc(iteritems,
+ "Return an iterator over the (key, value) pairs of a dictionary.")
+_add_doc(iterlists,
+ "Return an iterator over the (key, [values]) pairs of a dictionary.")
+
+
+if PY3:
+ def b(s):
+ return s.encode("latin-1")
+
+ def u(s):
+ return s
+ unichr = chr
+ import struct
+ int2byte = struct.Struct(">B").pack
+ del struct
+ byte2int = operator.itemgetter(0)
+ indexbytes = operator.getitem
+ iterbytes = iter
+ import io
+ StringIO = io.StringIO
+ BytesIO = io.BytesIO
+ del io
+ _assertCountEqual = "assertCountEqual"
+ if sys.version_info[1] <= 1:
+ _assertRaisesRegex = "assertRaisesRegexp"
+ _assertRegex = "assertRegexpMatches"
+ _assertNotRegex = "assertNotRegexpMatches"
+ else:
+ _assertRaisesRegex = "assertRaisesRegex"
+ _assertRegex = "assertRegex"
+ _assertNotRegex = "assertNotRegex"
+else:
+ def b(s):
+ return s
+ # Workaround for standalone backslash
+
+ def u(s):
+ return unicode(s.replace(r'\\', r'\\\\'), "unicode_escape")
+ unichr = unichr
+ int2byte = chr
+
+ def byte2int(bs):
+ return ord(bs[0])
+
+ def indexbytes(buf, i):
+ return ord(buf[i])
+ iterbytes = functools.partial(itertools.imap, ord)
+ import StringIO
+ StringIO = BytesIO = StringIO.StringIO
+ _assertCountEqual = "assertItemsEqual"
+ _assertRaisesRegex = "assertRaisesRegexp"
+ _assertRegex = "assertRegexpMatches"
+ _assertNotRegex = "assertNotRegexpMatches"
+_add_doc(b, """Byte literal""")
+_add_doc(u, """Text literal""")
+
+
+def assertCountEqual(self, *args, **kwargs):
+ return getattr(self, _assertCountEqual)(*args, **kwargs)
+
+
+def assertRaisesRegex(self, *args, **kwargs):
+ return getattr(self, _assertRaisesRegex)(*args, **kwargs)
+
+
+def assertRegex(self, *args, **kwargs):
+ return getattr(self, _assertRegex)(*args, **kwargs)
+
+
+def assertNotRegex(self, *args, **kwargs):
+ return getattr(self, _assertNotRegex)(*args, **kwargs)
+
+
+if PY3:
+ exec_ = getattr(moves.builtins, "exec")
+
+ def reraise(tp, value, tb=None):
+ try:
+ if value is None:
+ value = tp()
+ if value.__traceback__ is not tb:
+ raise value.with_traceback(tb)
+ raise value
+ finally:
+ value = None
+ tb = None
+
+else:
+ def exec_(_code_, _globs_=None, _locs_=None):
+ """Execute code in a namespace."""
+ if _globs_ is None:
+ frame = sys._getframe(1)
+ _globs_ = frame.f_globals
+ if _locs_ is None:
+ _locs_ = frame.f_locals
+ del frame
+ elif _locs_ is None:
+ _locs_ = _globs_
+ exec("""exec _code_ in _globs_, _locs_""")
+
+ exec_("""def reraise(tp, value, tb=None):
+ try:
+ raise tp, value, tb
+ finally:
+ tb = None
+""")
+
+
+if sys.version_info[:2] > (3,):
+ exec_("""def raise_from(value, from_value):
+ try:
+ raise value from from_value
+ finally:
+ value = None
+""")
+else:
+ def raise_from(value, from_value):
+ raise value
+
+
+print_ = getattr(moves.builtins, "print", None)
+if print_ is None:
+ def print_(*args, **kwargs):
+ """The new-style print function for Python 2.4 and 2.5."""
+ fp = kwargs.pop("file", sys.stdout)
+ if fp is None:
+ return
+
+ def write(data):
+ if not isinstance(data, basestring):
+ data = str(data)
+ # If the file has an encoding, encode unicode with it.
+ if (isinstance(fp, file) and
+ isinstance(data, unicode) and
+ fp.encoding is not None):
+ errors = getattr(fp, "errors", None)
+ if errors is None:
+ errors = "strict"
+ data = data.encode(fp.encoding, errors)
+ fp.write(data)
+ want_unicode = False
+ sep = kwargs.pop("sep", None)
+ if sep is not None:
+ if isinstance(sep, unicode):
+ want_unicode = True
+ elif not isinstance(sep, str):
+ raise TypeError("sep must be None or a string")
+ end = kwargs.pop("end", None)
+ if end is not None:
+ if isinstance(end, unicode):
+ want_unicode = True
+ elif not isinstance(end, str):
+ raise TypeError("end must be None or a string")
+ if kwargs:
+ raise TypeError("invalid keyword arguments to print()")
+ if not want_unicode:
+ for arg in args:
+ if isinstance(arg, unicode):
+ want_unicode = True
+ break
+ if want_unicode:
+ newline = unicode("\n")
+ space = unicode(" ")
+ else:
+ newline = "\n"
+ space = " "
+ if sep is None:
+ sep = space
+ if end is None:
+ end = newline
+ for i, arg in enumerate(args):
+ if i:
+ write(sep)
+ write(arg)
+ write(end)
+if sys.version_info[:2] < (3, 3):
+ _print = print_
+
+ def print_(*args, **kwargs):
+ fp = kwargs.get("file", sys.stdout)
+ flush = kwargs.pop("flush", False)
+ _print(*args, **kwargs)
+ if flush and fp is not None:
+ fp.flush()
+
+_add_doc(reraise, """Reraise an exception.""")
+
+if sys.version_info[0:2] < (3, 4):
+ # This does exactly the same what the :func:`py3:functools.update_wrapper`
+ # function does on Python versions after 3.2. It sets the ``__wrapped__``
+ # attribute on ``wrapper`` object and it doesn't raise an error if any of
+ # the attributes mentioned in ``assigned`` and ``updated`` are missing on
+ # ``wrapped`` object.
+ def _update_wrapper(wrapper, wrapped,
+ assigned=functools.WRAPPER_ASSIGNMENTS,
+ updated=functools.WRAPPER_UPDATES):
+ for attr in assigned:
+ try:
+ value = getattr(wrapped, attr)
+ except AttributeError:
+ continue
+ else:
+ setattr(wrapper, attr, value)
+ for attr in updated:
+ getattr(wrapper, attr).update(getattr(wrapped, attr, {}))
+ wrapper.__wrapped__ = wrapped
+ return wrapper
+ _update_wrapper.__doc__ = functools.update_wrapper.__doc__
+
+ def wraps(wrapped, assigned=functools.WRAPPER_ASSIGNMENTS,
+ updated=functools.WRAPPER_UPDATES):
+ return functools.partial(_update_wrapper, wrapped=wrapped,
+ assigned=assigned, updated=updated)
+ wraps.__doc__ = functools.wraps.__doc__
+
+else:
+ wraps = functools.wraps
+
+
+def with_metaclass(meta, *bases):
+ """Create a base class with a metaclass."""
+ # This requires a bit of explanation: the basic idea is to make a dummy
+ # metaclass for one level of class instantiation that replaces itself with
+ # the actual metaclass.
+ class metaclass(type):
+
+ def __new__(cls, name, this_bases, d):
+ if sys.version_info[:2] >= (3, 7):
+ # This version introduced PEP 560 that requires a bit
+ # of extra care (we mimic what is done by __build_class__).
+ resolved_bases = types.resolve_bases(bases)
+ if resolved_bases is not bases:
+ d['__orig_bases__'] = bases
+ else:
+ resolved_bases = bases
+ return meta(name, resolved_bases, d)
+
+ @classmethod
+ def __prepare__(cls, name, this_bases):
+ return meta.__prepare__(name, bases)
+ return type.__new__(metaclass, 'temporary_class', (), {})
+
+
+def add_metaclass(metaclass):
+ """Class decorator for creating a class with a metaclass."""
+ def wrapper(cls):
+ orig_vars = cls.__dict__.copy()
+ slots = orig_vars.get('__slots__')
+ if slots is not None:
+ if isinstance(slots, str):
+ slots = [slots]
+ for slots_var in slots:
+ orig_vars.pop(slots_var)
+ orig_vars.pop('__dict__', None)
+ orig_vars.pop('__weakref__', None)
+ if hasattr(cls, '__qualname__'):
+ orig_vars['__qualname__'] = cls.__qualname__
+ return metaclass(cls.__name__, cls.__bases__, orig_vars)
+ return wrapper
+
+
+def ensure_binary(s, encoding='utf-8', errors='strict'):
+ """Coerce **s** to six.binary_type.
+
+ For Python 2:
+ - `unicode` -> encoded to `str`
+ - `str` -> `str`
+
+ For Python 3:
+ - `str` -> encoded to `bytes`
+ - `bytes` -> `bytes`
+ """
+ if isinstance(s, binary_type):
+ return s
+ if isinstance(s, text_type):
+ return s.encode(encoding, errors)
+ raise TypeError("not expecting type '%s'" % type(s))
+
+
+def ensure_str(s, encoding='utf-8', errors='strict'):
+ """Coerce *s* to `str`.
+
+ For Python 2:
+ - `unicode` -> encoded to `str`
+ - `str` -> `str`
+
+ For Python 3:
+ - `str` -> `str`
+ - `bytes` -> decoded to `str`
+ """
+ # Optimization: Fast return for the common case.
+ if type(s) is str:
+ return s
+ if PY2 and isinstance(s, text_type):
+ return s.encode(encoding, errors)
+ elif PY3 and isinstance(s, binary_type):
+ return s.decode(encoding, errors)
+ elif not isinstance(s, (text_type, binary_type)):
+ raise TypeError("not expecting type '%s'" % type(s))
+ return s
+
+
+def ensure_text(s, encoding='utf-8', errors='strict'):
+ """Coerce *s* to six.text_type.
+
+ For Python 2:
+ - `unicode` -> `unicode`
+ - `str` -> `unicode`
+
+ For Python 3:
+ - `str` -> `str`
+ - `bytes` -> decoded to `str`
+ """
+ if isinstance(s, binary_type):
+ return s.decode(encoding, errors)
+ elif isinstance(s, text_type):
+ return s
+ else:
+ raise TypeError("not expecting type '%s'" % type(s))
+
+
+def python_2_unicode_compatible(klass):
+ """
+ A class decorator that defines __unicode__ and __str__ methods under Python 2.
+ Under Python 3 it does nothing.
+
+ To support Python 2 and 3 with a single code base, define a __str__ method
+ returning text and apply this decorator to the class.
+ """
+ if PY2:
+ if '__str__' not in klass.__dict__:
+ raise ValueError("@python_2_unicode_compatible cannot be applied "
+ "to %s because it doesn't define __str__()." %
+ klass.__name__)
+ klass.__unicode__ = klass.__str__
+ klass.__str__ = lambda self: self.__unicode__().encode('utf-8')
+ return klass
+
+
+# Complete the moves implementation.
+# This code is at the end of this module to speed up module loading.
+# Turn this module into a package.
+__path__ = [] # required for PEP 302 and PEP 451
+__package__ = __name__ # see PEP 366 @ReservedAssignment
+if globals().get("__spec__") is not None:
+ __spec__.submodule_search_locations = [] # PEP 451 @UndefinedVariable
+# Remove other six meta path importers, since they cause problems. This can
+# happen if six is removed from sys.modules and then reloaded. (Setuptools does
+# this for some reason.)
+if sys.meta_path:
+ for i, importer in enumerate(sys.meta_path):
+ # Here's some real nastiness: Another "instance" of the six module might
+ # be floating around. Therefore, we can't use isinstance() to check for
+ # the six meta path importer, since the other six instance will have
+ # inserted an importer with different class.
+ if (type(importer).__name__ == "_SixMetaPathImporter" and
+ importer.name == __name__):
+ del sys.meta_path[i]
+ break
+ del i, importer
+# Finally, add the importer to the meta path import hook.
+sys.meta_path.append(_importer)
diff --git a/venv/Scripts/isort.exe b/venv/Scripts/isort.exe
new file mode 100644
index 0000000000000000000000000000000000000000..1b3bbc7643c4725afe88359343908f2140aca750
GIT binary patch
literal 106369
zcmeFadwf*owfH^BWXJ#sdr(FK3XTvIjhE0=O&rh+%*Y;@2r6h)P&62^qEeU<tSE^)
zX*2B3DLtpQ_F`*q=h)Mp)5|$W0=AkEAc<VX8;VuD?{QEOH3`@K`>totB*9DH^Zx#M
z|9Sc7?EO6ZxvpnD>sf0(YpvAWu-4^vxm*SOZ`&?cD^K}Xt$zRUkHzN^r*9bH`tPCJ
z&uGnyZ9ik~;yacHmM**J_GP!+6{x%A?z``a2X4JBuq<(R;EuZk;n~*&?z(5uZRZyk
z4=c?!{p(8>-uvE-BPQkkkNbZ(>0Q!CxBPa}7WMqir0=We+DRYs{BYu<liuX{-i_L%
z^(z0dZ22E#pZ}tsSKm>$SlZ0ZU{1v4TJ-H9t_RLKHb0klz%{`&Jb#$WwV#~-baJ~c
z;^|ZG)p_!e_k5SjBR~AhJzYN104>p+5B#bdbCt4nDd{wldq~}Ej=Z`aJ3r4gRlVf7
zelv%cwRx`7hD%27U%qPz11NWspUe7RJ@Z_x&QQO!^!f4IR>t}A;rsl^fMo8n_=Elh
zT&{)ZFI#j={1%tXx>!CikV+m0<bB{@HE43aQ_R&w!X*$J#d9*xLI0{<uD0`+ItA4n
znX9Xa0#m<GuKN6C%a_&hNx|eXzF$p3|FUwoExCt+R|xXT+Q=M!@`ZBK<?H|d@2eru
z+?}{9X1*FtUgN7t&M2u#&I;&_`*klsH$DGWk>}DYHtETx(sFWQ<}(`v&e7D2l5lFe
zt*2t8<$5w)8nAvF097haqD(4GUP@o6r~Lbh@?4f(>~gJ_b+P?xKXSRYb!^-A6@Ah&
zeO3(WlbnChXX8Tp+%)pUKK~$n&KT3*=V{qK_2m3gubzyT`mWQB{Q=YSU(=bJd000;
zuGkwhyJM;8N42MRMa^!j`DE#~OK)zAk25`{Dz_sP%!_K_m!o!jw2Z>xs-u}*x*0F6
z)XfgvoX?z%O@W&`w)OW@q9<3C2Iht4hUSH?4PB?3`{}njW~O5)&shu-_$<9z9yOJb
zinn9Q+bXSv?1_-Mt+|bFMHJC~&~EKIZri#^8Q_{<vD@+iXh~c5Ko#UAR(Bwjdg>^}
zn(dILAB|MBnJ-!C(`61)ZB=RBQw6|3WWE$Nw};IwmZyXzG`H*KF6&*@`W~6;>5OEb
z^fF35%=;a!*V)msW4ilD`a3M&laPx7bF1}J&FPm;AqYpB8Qp<_e!rRRH*9u9&6jj@
zhxMb;QhtXtx{}_QAG5o1I5TIS<{s_gc5DAJ=1A|l`CO<~=!f;<<Ene9S9Y8cST%q~
zO~Z^FP~fO&b4T{;Wqr)`*m!5IF>?!jGBax;eL5W#I~_?c-=>$4wl3nT4|+}_JK?D@
z-^tWVYpEY8`0ZvM&jUZ}_g`r7*;8^YJ~?dg(5KMom8tn<c1`f_%f@Q!Jgt1L4^_G2
z!)nT2Cv*A1jJw8sOD);TGXz)XmsUs3O;Pj4@~F9-*ZcLT`Bv!W&`qHQq4^8g9u5x8
zyH*gjyaM=soVxCO!KQ`QKXX{=sq<zE;;?4th1Sb{WXQVtVnw%<nXD(5lm=}7*P-jp
zZCX<k;Cx!PU*-W2Z@dgXHMexJY~5Px2=mlUNtz_hJ=SaN;O4!Ft5rHv>NFoSzu5c>
z8EHN-wnFwo=|YzDxuI;lTV=7y-;(jDPE|YBS{XHaWKQqv`l)UD#LeuL@|$lOm}~#O
ztk%s}bn}qyPtm?^OmuZZP2@CtN~WL&(iJne>gG%A<jKaO(g0+oo3iE}dM&d3|G~S_
zH$)4+CY!U?*_(6duUht|v41kO=OnXu$n|-y=I*$+Vz=%88dX}Qc}h+0kp1fuK$gtY
zQ-3IJ=mj+!_csic8F+rgp{?j)^HN114^`~0=(hcnX(5)1><g`5E6tdDbYL=P19eDj
zRRq%Zf5L&wl8tO!RXRtCB?=W)%;d9fDgUEhp!fD++it8m;3^;7T&@}0e+Mm4^q(ne
zc3JBvT(Mi$aVfNTvGwblpm{yEZ3D8Ui|N4jKcXtkYtt$I1KH^*f5NH!Eh?}7jKa2m
zxl^c13f<!rTIv*<Cxt#$g|2i8LGik*E1W`iI)%z9q^F91N#+ItVrS$J!Y$bTGO7r&
z*T#UTE)ZE75flxVR_iQWCE#9ETJGX!vV*`cRdh4-fHY$Jo6`!vBDQ}oZ%$E2#8L+%
z!)9B>?r<_D*d8kltQSVc_TNXz7-g7dPhlR|(pk}Mop#8!&9Gqj+|pWBBk37-T^@zQ
z(kxiN(Dr{n`&w%}13XU6rDUJXVIGoB`H#{flMhLAG0E?+ILxwpRrVZ66E7{f4tjsB
z95A~1KD9oimcr-rKoQ7%=qd1q97S=%+PYcZdeE?}-Z(TNJ}G3rXsze$0h7m2_b*a6
zHOp)J4+!*Coy0c1d2f7p)D3#~rgutPDgTct7-|)MN;h{}bwhKM>X+m<w*dw@M_T%1
zomP}+>qbbIBc-z#ohc-wN4G;S|A#u%u&$Tl#+LkS@ggZc&KaAfo3GV}tImv%(bf%@
ze2<eqOgB36`7kl@UiQO&p(br{Z+$p9Q9jCX5IB-M10It3sqt}w2!Vcwy;g5rHX(6#
zy%C(?j3-4QhA%_fBA;_D8J+nuJZAr2lnAwQD5=@s27Ku<P;aarKOsJ5prQYkh8|W8
zJwQW@P{5#I9&v^_MjFp(%t%|;WtBUbMKW$}ox2_oy`v`=&<XTgH<y6Y<`$tbLR<n6
z@A)^w2f!-T!euN48CI4Ioc*cCE5RG+$YX^vOwa6da&%<v5W(El??R*}FopW6%D5*r
z`*@~MTenj;+6uIF&&r<r2~@tKC!DJH3UwVCOP#lvGd(jgmRg*jIXPrLFGGF+R*1Qe
zh#H&oor8|DZvi6j6#^n*0)$%KN@w*|(>{rU(7WQab)m&;W;icz@S+><1J=}1`0Dyl
z^6S@b@w8Osx#n0Cff~ng%D-WVTDR=kT@K07Q-(CIo5zLR1@|l;-B48=*BYvZ#fRy3
zyB_RX_F=}&KA=AQLdyR=nvfO$1QJx;a<L+pWk+IW2QyipKIU?T&7IJK$*NW1FKz!{
z-+{>QP^?j-44|%08u$wh)F<Ps=IHP_bLy*DjyNdJB0g{34N(9bLv?VazUtzH1#V4L
zGgvC!vnS%zmIYVPyUZ!hf_Jjug=)d6afYgKcecj#!8MA%q=pa;&|{|%gKFz_kX_ZU
zmmv$T?~_p<g{a2NRi)MDjv57z71BH(-r~cP3YAmEdzrlAqMo<bdSoVvRUF{cbQ(&f
z76R@K0v&5A%v?6Z_U~kAQ`ejf|1r08eBzuaheIHB!-v+59HD9)mr{pu)PSg_0^m34
zu|9dRUe}?g9+p;Vs{v%INfm@`|95CFminz^RJ28nZaZoogF{Zu$*({7$Ea!Rz0bx{
zA#%G_`Y37L?vA<Jb2-O9mqRj|n(r+HPpl0L3S4;7qlUzIs<nr=Kp|fH1n59eD`UX0
zJeDecmJ;9w+#!IC36B#?a`IbM!vyDcT2W|~I@_)LkMj0q|LW_t(}feFLa_MRGhzNl
z>h0~m`rdZiPUL^mp|^MY(%X?56z?@a%I66Srb}-TbDtwEL@GWAnVa?IZtdYV7G<>c
zt%;m^F8D*2Rmf{aTe^{VRc5y;6MvNigz+3FwZmEqlPvTc%$_6rx!Af$wZT%lGEY<T
z{KN!nVt=y$$sz8nru7H1*RHK-%bbpg5|MROT=oJb4fF|IZx|x2cM756z>CA2!EFg|
z2?w-oTlF<^Iz>%z@fqEGnRz7q);eg<lQM&3i8X_Fvjg6*wSf%Sb`gn`oRD-g*mwbb
z7h26y3R<x#aAU`|%+UJa#`s9xXlLi-$<FzRj6{KMws%yt!FLH=oC8#KZ!B3|5=-iV
zYZP}IfF{7Z=3wc!&ZpTdET23BPOi(&%#s3GK)$Z0*x}Yb@NuoIyc=Mcdt&Ae#R1P1
zn!M9GESU%iF9C}u1X_|AVGBX88Sl+EF=EbbsQ<+Z7BRD3H;d<AlIId`@DFdOy*AqV
zHT|<lw*LllAi=Xp0|95oIXJ?-RI@|iX{?>+JB!NfPpu*&?za|76M$^EbuDkO4b@4n
zh>It-!76MCl~8bZVzqVsRH`Ir_;hn^n}9!gvTnAts<&BQJ?K9M2O2-cZ0I7Z+4D5#
zNWyDPy+levU_JkNHk+wxhBtnyZqD$TEvi`YBT{Ur6`7*iW(YHUJ*tKL#3)0R$=@=g
zB#%SKm;Z^jI&bh8`_Ht+tlv_E+LeLOTu`VQZYFA4&YlRFn`%VZct!>aMvb*@3-mAK
zL9o3QE^>AH_v-WR_#48tf`iXmhhZCIAZj2|RW~YenO@ebtvl_~dgDlF*)V=@SW!@K
zbOeMP8+|IPPi3_Qgi7o7_IPzY{7|qyxF^0P^L3aNp}zs^BcRABpc2};J=W_2Rbdyh
zwT4M8kJQ@6!Ktn5C~FT_!jr~}ge5FDekpJ}rbHGw>a*JjioKY%s}9WvfdIke3O3R1
znE7&*=kiJ*yaE`+zm=Uolg=XYL4+(df9fJ%G&BEL*()=&bwww`_o-POQnP9gaB81a
zZyZ*6hgIIjK-AcnAGN#UjJaFJ{7ih4wr-=guDh%Y#FZvttF3v$l&khn)N{xdHxBJv
zvC0w0n!9x^atL(4>tdn0-HCwp-gKBihUl^$sOHU<w+?}qS*%k?xM;S;qpwNM0ijms
zR(al=1{RJGV)GfbnRRjI_tr8R=~QYx>-PRvn54`})=o-USNCU%xGEYGr9P1@Dez2r
zzBw+>)#1=5)ARO%JlB(=3!ulsR#EU}Ji!hv)}hyRZGg#hB|YsFv5rO<Skm)wjXFgV
zrKvgK_txaN-^j<;osTQC9}8Q@QZaL{lDORTrYA?`>BdHMH|<{C-U_c^dS+2L^R5t-
zl>f+Sd9FxGcSp^xSjzt~Y!rl3Z}0OMZ=4=A3pVO^cGt$tQF&40unkvk96lcR)Uc0-
zbmp@jcGPZ@)}wZJ;%~I4w!Pqu6^y!E4bv80l;?8AJ=XTi6|{H97!XUCz6Gu!OQ&V|
zQpL3lLl3^Z>{5XA>gn>nXT{g#IBfm>zpH=e=w;99z3=Poham#b=<VstQn8UfYyTB&
zgAI3<XxXk)vy_(VM%|wD!mFHh4y+NmjYFdzIN50TSsOlI<BI+ozm^)ZPX6vwWeCqK
zyO813sNr<2I9uEBP5LQ&X3&^=)1Mnq`bOprtjig|e43MPi?t2QN;LXTUn(C{bZAey
z%;`(^Q&Hu}IBV0+7D#*=?cJjk2<;u)s^^JbO$d>mS|VD=1^l0=)RPZXqf66S$oI!H
z%!<u=GJ@pQQzNwMVD`j2#oB!8z=?Mi@9BG33#+1rAq2N98-gfMk$EL*MqH*oihVaX
z1oHzAvO#3qu;?CyISE+5ioqb&?E^<IvzAGd=Llw&SoOS{t~Bcg9daw;Rm|@VD<EWT
zfqFSdl&n;d*ayGx8I_{uwrKFv<tIze)>+cj1ai|0K%?fi2X7ZifBHVX_ha4Y%U@PI
z3j*rX8xOfS30F+fQz)*2?JI`qtp`M0N4(LEeFv<^7@c0WPk7^U81MMmorT-Bu>nrD
zUIfM9xa4rsI$eMNyDUqmF9V_<r(nWo{g$2LZ07U@v?q|rf&hSIp|D8AZ*-j2&t@qi
za1yivJ(Q4ze?{qQ?#UEc3uq?`6g@TjKx38kmGD>(z_STUSHlu*w{909!ej+aR?uVx
zO;#{<n@@CNXo-|gRkUH%@C%|La*mH()|0d%r*FXF4XyXk#x<-$xA0|z9Lf!$VPmKN
zz>Ls&D_ys-zY=x!<Y;onfv8buxhxan!hWd~nglHkpoi<%;leqI0@wUl)DDZ;YBlDe
z8et3%>dCpKO9fxY)_^Yln&zIwS=K@r%IqQV0lb|<_EySf%&GfC38tHWEp1?}Wraqt
z&M-aE-cMt}u6xhcjpKIQhhDQ{x2QGSWIauhq2j+DRIqQw!%;N&+8<x<omqm~m@=98
zkgz$sG&2N!2~vuvN*1Cy(3)!boGlgF02o%sZ;I8e@J5<@;&ZeXQNBcjABMH*pGC|a
zv0%6Mo%b18%!FY_4rR{P+t<?E*(<yub4v{Ry;v`^^gKR`8j7EVG4}zztSkLXRgLcv
zvppKLmMx9|mH^WTzJD)DgN+gMV5s-w3<P&`*!(QodmvnPFf&YEgYQSQnFncJF!~<F
z-_vCz+g;Rr5nk-nd4h0`a?|Lu<99-p%dGUhOh_s;0Vm1k+-6w9>75m7Q2>Euh}v6_
zQ4~aE4=<Lbq|68D*VPdUz>E6<J{!cgeu7T3lbb?z<AoG4W|su?vcCg=RNTFvrYAdj
zzRdekvok%Gl*8{1=mBEMg@KTgB%<cWiVhu)nQsWPEEHt9Q4T{{ox}uP&XHj;b0doW
z=OD$_c-6OX=GO1|&0HXx>kV`XYZY$7`PLwdh|+tTbtT9zdzup0iBit&M7P)`jaSP_
z3rR#oj+u*KXOuvo^q~k@uwpfwZ{|iF{g+iOFm%xWEBJQB{!JFny@%#=ynBhYi~(k`
z-S#WqJ^eZZmohmyD3)4;68j7pf6vU4YOVR(6p$6GpX;pHIY!^{_$0k<mpaA{d60PT
zpONP>-aK8ub9ZgjJ*tc2a7-yD^hjQOynvV#x|Tvc(<@geCds;wl~(*P3J4(C(^^jI
zsJp1GCsf%GKiS&C0JCGgM#j3sX2YH%Bl#1vF!$7$LMXC2!=2VvhL;m5>R6JsQu3gX
zFcB#xBU&k;q8?a!l}rJ@CzSt{`e0W=1g1!<92}&U`#70=XCdyd>(<s4=$SK>0xkwc
z;~<+`S{^prZU4*{fLk{R;?dUeL0i|Zt=l?LxIGcK6z>_S*jr=nLWl#85~HopV3o2H
zdWctu-1h~vFq>}+n|EQ<M03=gI4|=8Y<GR6YD~N&BC=XIh{6aaB_CyEetm?t_9K6e
zg?<hQbKDfQXUaZbFYn9hB~(3H7?aqU5xw6SX@{L0O%97{VG(^MXXQcJAA@Cz>~S8*
z9?>P%gn=pj5e*|`F?|C-v@W@t#Qk15cONJ)>b!_;=nBz+=UKPkB<s}NwsN<5O-b)Y
zG}Nxdu(IV|b4waN#bpLTm9h|euaC;^^!03X$EV7%i*(x0(zOYq^n|_M1`r52DKo60
za#$kY-mJsR1>MU&22V~kH>Y<2-KO0uKekpeGzakM8`wHM8}qcLKk`vVm?*6HApI*6
zW%v7P%>6ayr|$c`(e~q>knzsxv&@16HFthc8|n#r=xtSQ7WvjM7r0!(Es2RrgxjgR
zyK;l*RD)<=_Hplw5?26nFasntUu5>yUDSahw!8@aQQUH{Z^g)-871EMa48I%VD`n`
z=KZDcY-d;Jxvrph)pJ2S-|j5yO@%LHD-EbNMXw3H5K<w^O|%Eu^AITzBv*H+tkfU^
z;J3bs$~23E$5BO!@IKc1IvO*!%T}w9kvY^!E*>2HM5Q#3-n3t4aV}ouymjtN=LnYX
z<II&KHdV7H%uy|8;UW0FUDlt3y@y>Xv3lq)+qL0zo&GoAUeo+`+@o{0z1A7Arjr4S
zxR3vLMH|r+*_Yirv@^1Ym(`iV8L5KOWCUG8jUF>2?8Ta0(AALrf^bPa@%bQC)UMgH
z5_vqbtEEJKWi^tKU71mOYThnnu*Mlo8uD|7e3Y^UEhQOW_T!@L#{$T*R<&SH{q*Gg
z`s3Q89jO_|<(gy;7lMey%O`Uo$i?7Wxy!&TYzE&isG|fmRMbpIg(}I783&2h^s$<9
zTf#3}eT<OZ=GVxA7|1Cuq`GN`dfBZtZRRB!+;#69YXb~IEOmJv1oZ;2$YgHe(v>lD
zyXdE&^IY7Bl1bFC*41*@^&L+vwVJ49R8G*Eze_{by`+*Q=>~cK2Jf`>)_h?cxNv4i
ztM*vtFSI9O5>#Tz&BvwHvBK}Lnv<Qj6JNK+^A=79GUqh6-FG$xFOXv6tU|J#BRMnN
zI*h_JyY}DV6|@sXo-;^rAFTg^i>#CZEp$eM0w>_Ie#9_9#T?HEW$K4F<pXA@BxLp}
z>EUq$=D4N5N5S!L82dh|_#jCcqc0CN%Xm@x9)k@6>3?3u_{|$jB29bm8x}I&IvP&i
zSdtkV>gmXfkK)%G9}&_vyftiDVdsoe5pt!{^++LMvr}<84_~iv3f1W5R76dzTqed8
z&@Vf?$Kg}ims~#$Y|fCmM+SVNdTr;3eo)QlRYrdvnvh|}k-WIaIFg_EyVdkD`xU*j
z@bNpX4`tKtk+*__yuqu^|B}9eSI(}&nD)#xD6MXetK*R4>RM|uKnme*D)g#xmy#Jz
zSV!(4E9seY1~U4(#X`C68*06KySyZ@lo)rG)Ma3^Wb0in*GB)rN5$L>2aV$u)}xXR
zcHTQiH;307Q}3IW&>ZQ*`lw!-i4Q@-@@97GrkmS^mH9bV2<VB;h9Wy(&8I1zUQ9#Q
z7YauICdiRrv6tyL_c&VLldUEsoSe$k$9v{pJvm-DbGM#6-Ryw!INIJ9g*AH#Fvbu-
z8P{yN&Uu|N#!%vm3S1;V>pwFfU~-74S4LT9(_B`OGM-lxgn`S8n$JsBSX+V8DXObj
z@+@bB`Dg%9+WHk&h(3sOL9V8)-NO~L^3^P0RtFHNK#$cepdBGR!%$%=#<AZ<T0biq
znCE2PbLz`zSr^(W7i6pe^+#JiT3<-5{Y)ZF0|{S!gt}tSqQuzDMtGpk0XZ&U>;#vU
z@_CeX38k|8x0B%x@624@6Dl#{mskrgl11NY_F20HVb~g%!W07p+rb$R&14|RvnI>P
zhgp-~mu*}(*=5v~xSSJ4sV|g%i8JQJvx~}uj;~SHU+6qLj>~w3PM^s*s^de9TS{D+
z1J*Y_%${Tya$-0q*+*n$*eJ3o9F%hI50vFbYt0RE(dPLHx5{YE_hu^fI!`wVh~u~A
z;cjoN6tl#{TkD5|2=!HZNn%gMUZb^%H6C&A(5grJc+np2VCdD>Xe3BhWr8s+fMO#b
zz0r9WpszcPB38$_InCYBvq>&FD_8V0lw49YUy4FBUDhN0MPHjtvilwo#H!;ndvMr#
z^bRiT42szPt<M1Rr047C#jQWyt==D@HS70xWy>NbyR6U3q|I++vxZ96n`9}b)>_D5
zK#M|FY&)4T({t%WG>S>jWju7#AK+mYpTe&-?OlPXoH0-esjx^IUcpahwAp8@Dy>G*
zP4@NVY_sm+cdfI)I)E={fuYlrtvi_w>B;GP*>FM^VO6+wZDCjd{re1``+S*~=~*S(
zA^NKoJ|D(=p~#B0)(dSiQ@NL+&pEDmNar51lKM0dMuy@O)@`Wwo#P|rnM$Mb9*9vN
z@ro8jY*@(VGiWO_K{uO9)c}$nuk@M9CXF`8rsrX)ZhAgct$1!0MIYtYN`FbuLUKDj
z7m+!%z}432Dd!F1Diw;6^QGIxybsO3FSY#_b&F#3G0HhBFam(co$o2+1A&{j%F5=E
zFs6NrLU6}Uxp!G$+h5Yft)g@Vp|SnDN$HK7WbE*M%0}=;Z!~#lNi?}UAohZT^&-_Z
z=6&88bBY-%h?@6R)|B<um~X_efiTmL*K5rm&`7lIn|d@ks|z#3U8seF7i&hN92IWh
zKfklcoY5Bx9?%|ooTBE8qw;S2jCbSy0+-hG&+-<`i;od{j*32Nz7TbH+Pj43P4ex*
zc;f@Ey5)E6OH9^{Y4@VIcE!gtW6^V4k1#v%aKr`&c-w9NwPc&K3PQ^6N42%nddMrZ
zn58wZDTvjfm;$_TWAfvEDJBG1aYO;^F*?CbgW{+Xj1Hg7WF2EjS3wwHw*JI>jTs75
zd;pVHQ`Y%-AResPT{Ze%6sEJiW{A19Eh{whc-&iLBX+m@f}@w0WZpppcek0bP9N;s
z5OYaqQN|sH#{+JdTm&y(K2Nu~seG$IcfW4VKtpt3S(O8|<x?WfAH+T3U|D>Myaew&
z8lP+gT`+;*;!2piKj(#*jvfZGHSW%ky(>5LW&fjKkTpvao3uNtVM7PoqzU<SXt(f1
z@EB-52d{m(dEt2OolvsEkw#JvI(Mb7z_p`9ikL4(l)cC$iJXB*Fy4bw)PcRxcT2q7
z=vx+_X!Na!kG9Sm(ocjpcoge81Jd|(o|~;y95RoGh9AgypB~CW8aueo>BtY6yBzZj
zt*L`tc;2Q@fj`$e#-VFg-xvQzsBEX!^ekCMdU$-M-5tNwNSDOVGSb81V~j%uiSI^)
zPyROwM9f{rPG9=BQhmcmg=xXQ>Yh&26oO&K&g%3URccRW71{ZTdyV&w8}A-9cIImv
zJ}k^ErJ=;FG!hzaXX=df-1uxGJt97pF3*v^M;nKRXw756k={;M8+-2}dKr<aLNk^q
zi<n*7hMp0bGD(e7sSihF#$`(uQBuoj+J^UvmU}Qz$rO-*sGT!S(V7crHX;hXrx;?U
zKt3Ub18MfaeV}Wo6$nB&p0ifRWix2a-&Z_u$B@B=F_)R9HLq~K^f%zIRt>NmG_cjm
ze@9f(YBh&3jFU1~awl+}D#DgfMP7fqzle__BQs?bnV^akW{dn)715f9Ih~E5nD2z4
zgsUpFX2&uVy<-Fk-|S?kiiubQ3vC(8oq4>B+ROHQb_yFBa+pk%BqOJVlL>B`6O3gu
z4<G*{$B2>*)_JLLfGg$H=vTrH!tX2}TVAm@H7n2h{S;yRY*BItr(Hb*txambjK8iI
zvO7Txm5r$fTybnj3l8*Dml%n8z11bI2G%x~nt9CV^R4iuX8WvF<!Y!+LKryq(q9uQ
zKk6V{^|v_oV&=G)$l*Te6KO+K*Sq-iI-fEgZlE)(?9TLkOmclK^)2%pX`~C|T*mNo
zX)0NSh}s=TENm~|@R%l){MrubF)^M?y!%yeMTe|mZ>YZRl)jA8Bd$y-4J>fJ_DNma
z|MW&VrN`+~#60bYuu;N>k89+GS&6a*{>sPCM0tVHnsu7(oFEOb5OQw}n5!LiWA<E5
z7N^H@uP2<TBcsfNcIc@;l=|cjqH+HL@QQ&<6*CYqHE)*NeI;(0FB^w!n3w2cx?WVe
zloKpg8b?pk`U3&PUoI3TdOi!9iXdgzu*_m;2${n=FQR7hThRc?=?+N~g`U;ZN}8kK
z;;acG)UjGxT_~&q2Rkf)Sbme3EG^cE;R5<m4)Z6dnK?~2o4qpLWV6$9F7>!tS(So1
zE(KxYdNR^r`+wUm2e8>^`~QVE=|H#r4ZN~CK2#S)#t|C^X{)v9c0QXanY>=H&6@Xj
z7Ay6$Qh^Sd0nVZ2N-Hq`X1Nc6*Kx?_hS8kXp_HCy{fvFYy0>wHOP*i|j1YHe!|7}=
z{dN{Xai|>5AjlPCunsd{jtWbA5dMhrVRLKlE@!)d>x`JNG%@Zt0yby2TH+<5QFhGV
z;J^As>VS0<15r9kc;ZE+0nUYfabyLb7?#M{*!A4v#^j<6y<#|3?F|l#m)UJm_b#LF
zyk!Sdp%09{kt>F@BLBEL8r#EEY(+E6l_3K2<!v4MBOx=~UXbPce!(r1$WBAiZY{^e
zNeD@sPXK_%5x#Kspzqh^zK>Ghv-iy}TQ?3WQ_)|ByS(Xq;P&@a@&pzIvD6$N3l?NZ
zp(JOJqmu>1gZ>S&H)`C!hc&IKXshAcSuBZS!dF<!o?yt0o8+62AO2yY6edsctU$UX
zOgUe)vpwMXmoXV{w#?dr!cBm~shrgjtt#~?-FyJi${ICINlJfHtdG|8BZ^v&>=W>}
zm2-crw9+SA-*$2qO3n(!2-u!~ADQPuX9!d2O4P+tlfE{ZiP!Z-jj2ani86JcWDPkJ
zv`iKp6`+^ssTl!fvyyZx&!gmw(&P+pW=zy9Ix1=nA4mEOuRQeREYNRw<E)Z=v~;S!
zL4r9KcLGhNYQ#q*{xzja@10(vs+zCF*?!MhvnIP-&?6hs%cv{Oks_f<Y9Ry`C4=wm
zpfmxLeNY;;w@lA&cxZ>x?BYy>`$rH3=qvT)yaqP?+Nim!#{5|BMdq*q@vym%$9yH6
z$dU+wS<3&l*0fh`+gio(gY?X9ZxtoSxz?RzWW~rn`bAG4u3YeVe7J5#9y1>6VjYg5
zcS(;QCZsmfAlE=!QN>RVnFqrxdv(M-9Kxz3Iqy%X<3G@v-W&?t%muBA`g5HJI}}b`
z-z7443=)GzqUC9dAdGLW50!P)b8F`3&@bKT<Y`aEy!(tdv<wEm&**g<^*YSW<r>A4
zPYLa*QTgqM3+Q)=`Hb*Rr+PU)&=XFiNqO$brqO1rbba<YHv8;@U!z>}+1VkiU&I81
z?b`Rej8khW1;SYFXiZzdCZlhL)}*VKh}QJq>Sd<Z^n3Mkjn>pcRim#~Yr31dT$aNz
z_1&U1{ZM_c)0&`DE~R*nnnR+-7EX8}Kfo`jo7^UFP<`#`^JoK&+S|jImuOFm_dqR`
zTt6<`_-tR;>`Tiw2y0JQ3Z!e(Nm6K=?kEN!*wMEvg$EQxNMGizQ12%3cuKe<!{0&@
z408iMo=Y8jwH9V4Wc!XZy`?oN8K!wJ%cg7LapP25pETPKo*Aw@C4PqX1SU!I)>^mS
zquOS$Zr$DzvOD<=2klj_h#pUkI*iTcQmy%32!5z%Q?=F<fi%ceyqZzOYdwd`LS@Cn
zi=Hl%uY(53`YWL1rmTQd51uY!l<|vOl&Bb48*Z6fdPl6TL3TH`@@wUATnyIlvS!?s
z9pQZ=Xk)2>EmKgBep^p1*cDP8r>_A5osky#Rv&R^)^lcI7O;&Ylp^NG&9;`jnzai(
z4OXDH1#anw)mq-BeRni<RfS;tgIm|%K>^UDi6elezFTW*Cu2Q8Qn^3pY4k0P-(>VH
z*P2#ww5?BMKfNgBRyv914!)#9f6PQ!{M^K46@D>XR<t8iWbcFv_F+K6ZsD}$YPv&r
zFrkI2PeYOf#QU{YVM_s4JfyTFp})yCi!{A`-@Tz!6l3zXt5R3(mg~KR0@7PEb)ofO
zhbnPpw(#(GGSR4cX+LsUuiTjhsMhoztWG3#LqL|ogSl-cKY4Ku$muog5dmUoJtV>9
zw8n9(x4IetV)H(<aSpy`sstU1mSL!{#VbvXQHw0t5-+ULp1!;<a~hO{hhOClsj1_=
zAYxwLH&Cz`f^(l2LmHX4m*x}0oL1ctv#r^_uTZUYW_ZYWyEha(7Sd)P14ZLv_mp~c
zC#$9R?m4x4;xoVkwXnUjxqCGxPq>fCwM<(S>eBl$embe?NOe^Y=DWAFfbd&0&kLUG
zsb*<G@Pc))JJ^wt=6AHFqtMCbw$^f{ANN+ewWf>^Y<nx)q{W?njYMK3H<jr`D2s=`
zgvN$~heA*PS|Fy)J|s<sg7$-FHFhqLG1l$0>Q3jGjQj}#p*1a~0<5&z8|G3gEMheq
zdI-$V-w-AHmn@_`bxg18p;nvipD3)N>=0&JZq~G5lFpm3g>BdeAV~>+!w!YaqmA#e
zQm*)^5m4+D8f~Ca+y5py0onVI7JHY%d^Lx$*+SQ-LVp`vNYR1n%3#8)7DuFg$kH?5
zkw6d9BqZ#4aEay3i)*cD!5|CVWu)JBGV|jnw+3>Vsg-XqLOnB-DeEdbOf&Oi=91Et
zk+R-!Suf2LB~DUz&t?}YW^v}2I-OCQiPr3mG#JkZx&9Gzr{#R466U4+79{+t(0W<7
zZ0+MAIZ-ixtxa%x*$>{Ln@2(>(o$rtLv3QEi?Y;*J0*LEwSBSLB(XXRE2l|HTOn88
ziyWKU6*L!hA7kdtJ*zjUk!Q|U4{q!kQ8iZ3u+%7@82d{A%Ngc2s!>OP*4(plf{ZnO
znln~`PIjzUQz{Erv1FMOdQv_zR0m}uPyo1S>$&I9OoB9WGH@t6rP5`5l_S^ai^k^|
zeT(BW)-R!UusvR)4r;U+TJsoHXv6;DX^l6m^1bR?VuT#tvcyH{o;=zyw)xT@@WNS>
z-X|GClIlZ7<wc28c&yC-x~fv3^3zXILOxbxKYp$M<EL8smwaqp#7O9k^Y@=6DYVu}
z8j=(u>m=in6vCR)-*R$pCnpsOI0?CJ=gq4%&EZXs%q41p)Y>rl?KzTb?YyiXl<B<?
zR)%-%oW$87ha9R&D+(mrR1OKzVxoSRWLmT}siLO^n5k9zE|s^JypVZVx(ugxsPRgJ
z=Y||YIH*B5Gxm4#k5a+dR?xeL?Jz(67)i7N^HW6)s@*W{O1>e*=qMEIKn>J4G5)pn
zvWHl;iR*=P;ANCT=U}_DQa8}3H-q)xwt`HQ-@MEWS%kvOR1*1_i<m?>Ij=<qx>SDV
z%a0y0-;`;{du`?<K_2M&65;k7{!O(lJfGt5nx|m>7OtG9c*L5=vc|_kVp77OiZnQL
zr;x9om6nU_*|<qb$XSO`WkH6FgLJz=_+;for(7m&|H}WOc+%4-ry(TzY}<bmIa7x$
z9}AJXlU!NJ^3Zx%31$0U$yddcE6FIU^Akxi5S2^7!=hyv2d|s8L=1K=*Q{0C3p$ro
zT=6W>wLczmTEMRbRtfIfu=lMfp}!-;@?03_B3Ih}*?(bRhz{o&(|(Gy;fkZD+-dy|
z0gueB!pZ%m(_O@<GXE}#Ax=UB&lB!*P@tc1PphY{M?_$Q&?LkFUuW#7%t=BF_Ufqz
ze4*5=AuNAKIJuxGmRwL!|H<$5)U+#lC|!1JO~L7MRB<ltNPL1947zuhGIU&1P}Pzr
zZcJQmed3G(5?U$3Z?y;=BK)Ezs711I?Bj79eS9SZ8Ihww7R>bA43aw{$5LR;y`mW{
z5Y7ul#jAhjj!gE098*(y%5?-5X)SqJ7ufB=j%A;%371~G1(qxzhMd=C&eoo|E-$P-
z(H0JFTyaXMj1#Esid3vX+(7gG60m+!N*5TquPJP5OFU;@UW620sg_#AmU8p*0>pdX
zILexrLYI_QTx8QQ6u$c#?94@_)h>#e*A|giiF#!zLRGmGm@HHjL%)uSZnCg{g?xXZ
zc(X8%C)Nllo0M#&yQsv$xHLxpl+?>!jHMoxk?5%_$HmIFgnHb0@u3YveQUzQ-pY(1
znIHEx3=M?VguQRIGzzdXg<I6qC6>YHI$;(PU75=SH?JHA9DWf>RR@f|F)O?@lbRmL
z6mdB}X2l3v0eL^y1}b;}{oFE)S5s<z*l{mxb@VT?faqUJ(7&(=?ne*v78aXK&Iu!6
z{SKaud+D5~#rcOo=96`!wGHHTi9Puvuo14zlJ&(rtQ*Iv>)2mNo-~3aKJG{_1*Z#|
zpL)O^4*!tyw0<Iuib5*bh5qZR?XvqlyD6wAzoY7!o=qyndLFPTOH)n{hq%F`t%Nr<
zD`3?^53)KrC0UCiU+Ful#jITPTDz^4G;U0~tq`CZM~){Zb$YJlofI6*9LTC;PJ4|S
zPL?!fBF2$piIX}#=k}KzPsz;l#*w25q6dISogQEIn^|3ud9vRom+@w0U{r+|<ld-Y
znUmL{G}TOW%Et^_RDptg=0Pip<iPEFAGD!ZYyt9M2-By4FStQ&XY+FGo0%vqz+Yw9
zRh3#34qmR1dt21KU(_AOA<wdOqir1%iBtrRMq7LgwI)EwMZr$nf6sq9`|n*@7xrZU
z&elIYo4HwKUU`}*9)+@4RcC<S4;CbEDhgLEDh+7g{;nz!E<Lkye(9O<^D1le;*+%}
zDzzu{yx^e~{<594dGR;~)G(|d>V7_2wk`3QNF<ddiRbjx<>S{Mr-25qH|pM`zL{4R
zG^T$8?U!qcg7~RM8gELj5eg7##<mtfLNX_}o+OW=)&k^^jHh)ZspREF;bgrx<4)e>
z)l(1ppmgg+5QEGqOU$Zqt5LFQ&8?i!qJqH4P`2E_#1;kwrgQJ&XWWv{K>YSM3;ssK
zuGy*ZIX;{qLX{=)DV5jf#n08A7^yuG$_wsVF$R+GwQ->}?vVTWkT*|qYuwwgECTlJ
z`IQ&~!tHo#+^<H<_9vbMZjB$w)MTVw`g~M?l>bq2e7L<cG4@GkYEL>-d(xTOlQOkf
z*^7Xi!TM&UR-N<d2ALM-lUjWe|Bd$iXxa0~cA&;G3|~c~69aSD#afqhZZ=R{&`o*4
zW#bMgn#~E~`05VW=$eN@#&+A<MHe`{SUwR&%%97y<A{2S6bhl>i~_AG0WPc$fQD8d
zhHpq0glZ5Xek=L9`9o))c7<A15l=nqgP!6!G1l`Ujf71&Uamh>;eV3CsM?<Xh>#lg
zP@EG@l@$$cll|Y#5Rz&L2W)rGx4S5uuQea$(c^iNqb1L|V0}tx3_$p-L~h4t6eK;r
z2HVXU-lXT}>ZK^@`LVpbgc)SPzuPwaNx(Slc>q({XS8+USw0+ooAi~}BfV_Qyh)4&
zzBe8goPXeCimVBbIc<7NQ{K{<s(?rrfks<s#RI1xajj_@BWI?RXh6$jcV=)>_nZbT
zJ79ZdO2t0johdyi3zHmYAC!-7#vB?A8kb=`mpBtRtou+3zKYzA{Bt#BE&uyDty;!Y
z0q{N&|4K&@9se@ZW~C!Hrp*(bQDW430B&1D!TV0nWn_^l=d9?557@Z7HTuXA7Rjxs
zX=C8TWXXxi^1;bes5aCp=*SJ%*M)9Z%{d^-KA+gp&>RZlm3_(|0mr2NthRvovtWSK
zSW9CE?1qIrFfT&m_9NO7SBnGTJdTh4krj{z9Q{MfrE_D;rE`OG(t}6$Lx8PD#|4ub
zofP3tR)z;%b%vMCbH;~*s58EBUW*J6J77hx*)=(PFG@^SUohrri{FRh@u%P=2EXyU
zbkoRz^%kSjm6)%arUTgS_$fveF1Xf;EwZ^xX~9|!=fS%(pZ*f_29<aRL5332s5Na+
z{uK3Y<YqooI-5?xN*P#VT8OJv?34#DT~9a2YL)G@4sBMw&yivz-*=MIjP;uHE{nr?
zyjTt-j^eS#dI5us{EpkmGEFI9{aFg9?yr5yK?BcuQoL&Bf%r+fsVU1OnXSi4N;zXS
z;KpWYHrRm8lJn&r^`$c)yysIQ#wt!12GcpV)3f=`1wg;QmLO6{>Q9ZCBV)nc@eA}M
z8|)eDd=MQ6v^d^r&shIKB4k`5zRoGnB5*Sn+yyzggl!<oF>wxneZ`>MY1jI@%oZhy
z@(67%zV!eHP)R>8Gs60t`u<285Xh9R7xvs*GfEhmlqq@KYzm)iUCUmh8K=M<C-Wi4
zk947B6Mn?$b=x+WPJ7aS{i}07g$!dBpGgC9=~qm=6!MMYQDn%K(d6`xAhN(f-E}CL
zM7f^A$9R56?|QQFF~(rr;&XL|#InWJ*(h{U-nKM~pgUtrW3N1@Q2V~BAVk;UnmQOI
zdKyD=pa4$hf6}2diQlNt$tT<REcV8DK6>K7Q%@Qy%T)8X{tVB*)~T_Ky3Qgp*8%$p
zHE!GQ{VjC5_!3%>i^0RBfEW8GLENmo4PA1iOoEm>nehs<Sd-4oUAF&4Rdy>|?G$*o
z1FWR&e?{^P;)EpKIA)i2C}s)%WrHfKZe+7kQ+A!d=`4_R=uPQ9YYKSVzbuLdoeiJ{
zm|VFaF{71&ZysyYMp@lix|4dsN!2>3$DPz-C-oC2wbV&{*Ga8(QV*(>*`NR_&EDl?
zJSG__&r477P`vLv@}E}c+D>a6KxLIoStX^FleSKi^KvwG42#?x(>%mFjf!hIu`PID
zXH8xksjBBzF<vGzXHq<6g46z$EgK(8E7L%FJ=hl?VO)mGw3HY=u&O^({Pb3<ji>>#
zx;dsg3s>16))Gxv$@oGj;h)v=%=ir_zo&){#5P=4%e$VEE-N%#Ml1^-pJEo53DuA_
zKKN_Z!gz!kPQM~Ky8J!lW!Jb>>ax&VVMY3Pu(L0G$^j*3I<I_Ca5>SM{#`+}W}k&`
z2?JlS&$xe-D{+>#ZXUAH)A%Kh5kKpVfrba5O`Kgd2eO<#j>eg#+PWH_5`^(RUOq`l
zi`Gd<4WQ2u!fE+3)1(BuM~JKTM1ePRt~m>v_(&k6=BeWJ5FQEnIE=`651R?jhl+8c
zn?%0YsX%ryTYip;59PpC<dxznzZ0RvEua8oV>oa%a+IywyT5WW2~frbb&kH|>RRi7
zAz%F3FBJ_@y8HAFR%+We=Y8V{dC#unZ6dpKe@;BC5o&8}wJv&HvbI{+szYk4b$Ryr
zin_Jms(MU|jq)}eW0#-z1tNvj8bi*Pv320a|N62I22+QD;w-3yq<dLf84Z9rD3rl-
zzWr>jW_obV6X>Ba?QS_6&6lCtsp2}`t)I_Sxa5_|Uo9EM*8nKuBMH1x#hpB?2LTRU
z-9Y-22<c~JZmDrURYj)#j7J87_r(bq(+Z_K2^?2^T%+wNPG_1JA9sfc5@P$`C12(=
zptw<URs2I3bWrh<ocMUie#F=?UkRIs)S6i5vnFeeY10v@^Ry=6LOVSoU-RM$w@jMI
zD+W)^&kJ&!#f#|4_TT-OBn}9sl>>3D31pG4m#VLG)Ym?RhcOd9zxeTDmaPO$<0IG_
zI9fe;eA!a#7JSt7s=`Em=3U9SnUmc1`&9isR#-kJ3+?A<dH)FMx91nq4LY*o=T-V$
z(y`zt2~R9&#s3;JKapuq)}3d0f1j9K$ezgjge5V4NfW8!MLeu^Y<jX9oUCt3)^EsK
z8^NDNbD-nn{3V$<v(q!K&jE__p%<zWf^Ky{A9&jSu|F5IWC@n$ET5_eSw6{P?M~N2
zs<w%R49k|6t|cYr<DyVX&r+YZWwk_Mb7Q(na{BkyzvY8+TdisUO??$VKpL@5cIqK&
zT#q0vb{@O1@fd+t%h>2M`c7H)F`+^9N3eLr#<I;Tb`1g~sKg02hA7eI&;uv#*f)5H
zTA-=4TKYU>JqG4h^f)9`Yx*z`Me>zy>!CY^)Pgc1ph?Cz$pFENjcGgfDO{S*herD-
zBi5RPoa(9b-a(HL`s*mSh+&>b{wN)8mmora-$fUA;%UvJD2T%0Ln)|YDb*)0Oapmr
z(ro{TN6AGy_a6P6Lknlpf)k4HXEeap_YYXX2-*d#%2xrRIQ2ev5uFKC`ljAHQ!+M^
zK@)p{T4+53VtBF0U*Wx@Wt+LYB<3MkC)PHY;V)}<-(K3K`dX?hmx1lp7*#Y8!hb!R
zQ|RPy;Q3FJZd!dX=FHf7x1K9@_y(3TXSCxCH!012J~KWz(<yh0WMzZKjlqC2>tv2?
z8i(I(6HQ;Zw0h0(P>Z*|sv<tp-l$?EbmTW4{uKBwdq>n#)zvNkU0T5sTRZ0nD3oQ^
zT$HWmPKf|0;IsV&KwLM!t588i{ZfuQF_;o$aSW#J#9(T9W!9C-;lbcB6-2F@001}=
zAMGS(JMb81O#8!YU<d-EAcwVtJ?8|(xK%c!h>PH8@f%1u**F!7H7edk2Iuxq84*ju
zQOF_0OQCaA5AfMp+NX5Z1Q>MO%0ck8&LYdSBEW1zE$P%Zx>%3#tUq?O@CCG-@QT*v
zPT37f&mu1?=5evv&F#tJOC=TDwLHS+BH+~(y>@-)blWv7oLuJS?E=@ZEz_q+YG$})
z*$g(*B&lF*tR>(=uhWb~>Dp`-e~R9YJM(zyty<I9Wp9X8r6Q%GREyOGo^+vcBJNm0
zjr*Od5-nB|+^VI%qh>JeB`T}Y3ohL%0|g9=P5&>**HbMrTIi<xg`{8Nx*;Vl59z5n
z&VU<ky`bTQL6;93G~mK74z}C$&y-e-PH*tJRV|qz=D3SVV<g<X_rX<|E0x;u#qu~F
zza`WYaplEtkcXG+GP9@@`}Uux9Td^)KGIXgqo}HkCv|f(-kIVNs^guhyU!(<RRLB%
z5m#tUgjv-1S|Y^c`}D_BTWh)lGG|AM?9QmYIcjY329K<2ikR<4O_U$go*p9On;Ntw
zIMUSM@%XTYSkT*$ZU$T-c7oV|cpH27v~mMvpW1D-e+Eg{!WiHG{Sg7ZrM69tKv7qG
z&Uk0cLA3vR^4uV?AQFYrWOZhk(dSNh<Q?5#Ea=M`g4Se*xe)}m!@;6Vu_~^276fJB
zFcq~Sdz0RH1blF5-_^-8iw~eCwEh21RU+K5rvyLQQvqzlQGh${iTysIIX&87UtYN~
zGN)}uzghvK^D%d2a8Em|h3o0jk#r{GDOGA>iNA<m%xOQNXgKw#1-gfWuZPS`NSnDo
z6x^SH3+umYk$Y^BQ*zvd<CFST{Y&6f9N^N@IR}#pOtIZM`<?zFoKxkQNVoS+kV8`7
z9Zvni8Nj&V<cGMq)@B|J1&=1E{0|55RWXtRvU6eQ)ELBvl3h`Hn=Gs_{fP_2hl^1>
z%8|k-cG&*w)F^(Q9YwPoHRdOb;?q#@Q&9~3!%<{;!9jOo%8!<%5W{>9jrT>dN#p@#
z+KC_dHtWtW4#w9%m}h<@Aju7;4}GvRn9oAN&k|3{U|0>Yz;c$PT9{xb%-8^rCju`a
zY*VxItea8eu1($S=8O*n$9b^Ve&9B}?h|Oy%VPSg45?|W=zwzm@>#QRk&;7Wh}{WW
zR%#p>wQ355{~(1a<rplFXN)jiKXNiZw$A)-W#jxE(%3kE;<7t3-*bemeNZFEW2jn2
ztutD28_M}L<n&p%ddi}`T<V^hpSY|yR3iH#evw&Kb|2=t51wcJ74bzkukne4W|wu+
z5-yE96Ph`rq^a#b&DeL07}}XaV^&E33kBq4pV&;xU9RYIlE_vAoN!LwkTV3Me>8C@
zW71z|uUWUV4cYS^=zS(2{@c|I0)O<a)-<}O-*3?`b~tSVN}K_hD<5igwkYW1K|-Jg
zJ9TBA^(rvHk1-@y?`joR!_;W02D*&Zy#;V*W8->-F?F9SzW54r)V`kSn4{lBug@Vs
zt>ya#^4%=jr<SOKOa8pXN!CRSHWciPPqepiG?!*DgZUtF3PrfJv&J|dLt0pF`zNC#
z%AkR!@i%GqsK{j<>81QSixdRd(yA6d?yMCEK@?x{L|-Ti2Hz^4=&Epf7}W-^Uv}O?
zdr%?IeG}r-Q?WN{9yL~b^Acz3bz2;oxJAb-08#&IpRkgtqAooNYd`4+>M%Hy`(LBe
zXB;VA)vZo%XTj9!F$f38=M#gfLx*oQN;g3vGkXW0>k<Q2hVXPLP(_T|_67@v0ZbVo
zM!3nj-<u~33E``wM<EEy|14x!?CCpvqW^oIO242I$kQhZj^VgHC5G7k3MsG3>?EkC
z!lMCt0P29u%C^&UgH(2Rvq`#8uYLN@q*!f7XY0U79LNKD-OFN0LYvcW&hSi(wqE5J
z;{Mc%6BN?ndo~bH2ooON4R3W`9t}s0RmZ@^0>XOTw|+9!tRo@}IRs6!?%qAf8lYAg
zv{|r}qPE%UR85?hJ(>QCfk6aE3s&FrC)D#_8>ripDUK%RA9H1fSabPA?c!28xBX{Q
zDPw%uqKL9U%~L_2$#JtkXP-b~FSO-#(b;~+i6>lCN*`%WBgiBWdVOF+0;{&~e*so1
zhU@<(7D1_py66V|);FHbT~%1UyVOlv=HC851Q1^*zyL>~y*d_rgV1@L4BE_gIE!7K
zCq^kC9zlNqf(il<oFPF4yt)cNknwSaE>Q=Db7l&iEWlxP1c3#nx6D7&{$Iou_=<BA
zrulPG1@^Ok;txD1s=&)+;pp}b4^UKV>Q*n954Z6mQ3YzOMNB;#RiGK}+KDQ#cyLsK
zg>oW__-lzRra1O5vCbEONmK!0D6IggWJ%^hYcwzLXj5ruAfy0|aT|e6g5!ITYfSi>
zE#cE`fHDwK;6)5*Xg5(|ZR0IWM1iw0gPgpjP?Z{IJwa}NK!M+>#3?d@i=>_tP@sD7
ziRVPdD2EoYl`8w4A0|5<57sXj1N2J#92_}0BJ;;1uA3MDeW4y#LCkzMPTbyVZ%y4C
ztd?T#X9-smoA_+Bt^?xeQ=va}ukN1Z?FqTHcoEmCZbEwLkHp+vv5IGi$>|&y=lvcc
z$QUN$aL73L@T`>twH)H5B$mN6Qk@9VI#}90=3(<=oXsBOOxh)T@M7jG5u6q)_f=r4
z^mY>0Dqy}8HoJsBdHQ=SIHU(y3_3!U-T=Xjdxw({9rEyC5_wkQzHD6f;U@s$3;zcB
zM;QBY+!<9W&O6>3{uBe(?<KLaT{YVD=WdIcr%giV>Z%Dow;W5j#y4FDYEnN%MQ?|;
zxFt7nfbe^z5<$`nJbZN3Z;P|IguC4UAx9m8U~-xDigjG%rCB9<-GQF=hoE>*p~viW
z4W$cpWFuaQ%+u3e9WS<irM^wzTjtFQyQdxJ)8zf$o_3$slq6G@$av$po^&T?m2m#^
zjX)4aS3VrT@09bz1=d-A6g*H47x59+7$>z*oGpgK4xceiQ9w5IR_i~Oai9~fh2FKM
z6wPyBz-17o25YN4Ix%OI+FiI+G=K2mm@pQZJFFkpQK~O<ozWd&1nJ9IbqN<X(Kvn_
z*H?1~KDNmBQ;|)HR_Mqx-N-XV8#9IMrRQH^o*{1_J{m*G9cX&;t;jc-6{JLK`bh8>
z<^{{6@|L{JDWcitFe5w>Ma|9DsjBPXF|BzsCAB9++r}DzfJ+8&!@2ixmVVHBqsK7%
zyvwf9p4c5-pO^hd@Umygu3k1??|s>LqcA=sR@Sa3eFVQDHdWNvcUiPOJtR@(BnnBm
z<0I?q>({Q8i!Y)#N{q!%#SVE`%Sf>a;&!#CLp#0NC58AeO02xoT(0HiQa*VVr{PsT
z>Q(dH!~grJ&%@$>l!sUKCH7=~koCvWI!5YR2Q~O{s_?Q$QmPV9OA-g<r!TSVKtoZf
zD?OLR`24;LNbousJ-?-6T$FVYc>yjreKO#M@qFCSngjtJuhyDH%lUXdhksXq$RcU(
z28h;?$E$-{h1RO2atolFArxlZVDGfVV<T+N#47tb9~@#|A=eHwy*VAIT2_Qd7jd^9
zO57|J4kE|P!7)`5@2JFaE)q%XA;D8mU3k2gx4J!g`w@?|k=(Gk2MTt2&7FH|WA4*l
z%M@ZMvStrV+nO2P(ubx#l<;U9?kOp5T&;qcBu=F_Z`{wQh&ks%08rjTTDUza<J9cg
zUhN5GT9?!^qlBL|_W5w!8alJYxZNw^Nd}$t4vWJXKeyC}A+~oOA%q<bO6WT0fUec+
z+6jBo8QBL?+Q|iP%Ly>XI*j=QKAe@-v%EN)J-r#deud4^)$$wOf}Z0@J(}?d?`V&4
z0Kq%$tro%_w%Z=#T|zZ|_fX(&<c>RgYS)CPcppc(xP-EeN9bquy`!xk(J~z@RUOE|
zk-nMFVe>ul$i0-;$FbMANLq(RJ{w-MWJ)DEM9M|-KM3u@$o{GA;g-7=V&XFjJRWX#
z^zM2*FaEgk*72BmFtae5e&pFqD2Uzu^gR%aCWv6n3CMb?)r*NlHeyJT8Ust^O7DXu
zf!n}rTw-JGL}XxEMNBJZ?wMsasVPBr%d2w<g6oA^hY6B|%fa_16k4t|vGSpzOSnY(
zClWH9Z}SYbjL6jq5i~C3ekGc^HZPJ|*c)yMmk*6JeGtDjSAYhpXdr$S7H%~y!*bcw
z(d~^?>60o|p$24$^K&1mbBWX$N1ZVPb({)^s48_X$t??(<*#Cr2s<}LY4C0T=@4ka
z{1#xW*Ufts&!(1Dyi+K+OZ(0@c|}E<_Z?UP_nUOuC#x%yZqS-8<RhcW*P6bIxWsxD
zhZ-&&CTf;)Z$ZY>u&CU7BwDu#1y7CnVbr}vPev>itbnMfsF3BZQWQl~$7)UQ%ljpp
z;>F6a6a`Uw8#(ZAmTq@(Gq8MgG!@B{0AslBY|hU-$i+bV*A!u9YDh9O*t}Yqn&a?E
zBiT6yTh!?>%=WKmN#M`ws~&hYehc$D``flXcv5<NY{LV!!{VohTPEgOUK6Qp2~QcC
z2}XmjC5FrAglCI;Sf&hwae7kG0Dr<=kbI=o=b8y)qREc;bn!}C7|X_jcUjs)MQno%
zyJP^4)egM!GeZRyYWiXGtw`Cs4G%2DTIpFJE1Iq*x$DMuv&Y?#@X}oR&rDw3G-Nd6
zaKY-)jBeRU6tFjHPq?R7{?)bgDgp?-tvxY(y7m;7NTitg$yN^r5}mGdsBLVu(+OI&
z+lWB!6^A$Xp3H*5W7F{$vpZVAYvXYKs*!8lIhaUpcuJLV*q!)7?j_Pv*`CbFz^C_>
zEQIQITld`oRz=>9nRm?zmA&??g=uY#xkb3rirwlj8Av31^t#8IgdXe@Hk$kYW-4`A
zjSO0b`wWN^?BH4!q4cgM+rA<TNP<3fM%-^FSC#AOf2B<G?hUdz<HZ=|pYjh8a-l-V
z+XfJli&hu+yx`>dWY&j*o8nv+yOAgJ1@qFvuYi{eVOEX{VvYqd`J)NG#85sLr2m6%
z1vmfBGY73KZtih#6Nn=lZqCml=g*lTa~)y(Ph;Y8eey#JfS?X@0}eGApGVT5nq7U>
zygfwq=1*~~i9n^CeITg1Ci3#2WL0iOTjrKul8Ffx`}*rA@Uc2Mb1_S$cW#uk00QW?
zcH9nb2>|JR2)(PGPRSJI@(w<vVv$W0pn%s4wTFbc$xO)gB=n&luZyrF2c!-N9n@w4
z1r2I~pT)gV__Lq<lI1;e9M#9GSle80`$rmb;Cd3LS~D@ya84p?zIugHyV4<av_{`u
zi30QW%>RHNx9}-_E}7^U##$AmIAe+is{R-g2RS2+O||_OdN<vejh72sfGR=`%7If7
zsXrvg+xvRmA;Xrl@im&L*o%|%|L~GM8?n7`RqU0s@loD_)870@&PGIIP~g3o*((7I
zW2tFxk&TlWyujPF#4_w<L&gGL<Bh!d9sC`S#y&Y3wI8;D1*5DLv`!~;R3~yiX0C(H
z_&a-Nt*Y7+4xkqqiNQX%X?z(?Z2}+ot?~WCvMN*?>=(Yzf-H$GtolyF@@E{f@ND8W
z%Q!$boxgrC5N_A;7k9X@jjEE2#+vO^%DBzYX@HY!p3mzAqv9Zc0BtUT_LT4RwN4`s
zP%{?>Y$)%HYO1iIC+QfJ6G)a*=|#&sl^NqvFJWEfZ+}Qsv(0+&$nqj<n$({l5P3@Z
zw|{}*Y2N){?922^#6V;~<}1}}h)0a&`is?Tw%c2+s_VhA%g_ci?_K>~wy}P#ah8Qr
zbIaLWtG`W``a@|sxXxA7E+NSL9f1xWa@X421!WNJx$==-D%{s%G!+ewlQeX05r(Wh
zYWw}8W2ENu|6FU_FVO1DZ_D{dKPGly=UTJK$TGisp3eD4KO$x)k+p;Tqc_06ilUMj
zmesH=^Hw8gH2)SrDOptpoAUd1PzKH8WEj2p#8_P$1<$3RSSlO)ka-SyYVK^St#LPX
z%K@K}$hs66N|8`cHPK?vmfGW`_81j&cB2HERX0BpZ1xB3iY=H<#MpDKA28PJu+QMt
zaqB*D*dgNox*4{3ipi~+;6Z0(4SUY<>{h-(S>JAaO9@yb93igVp(kB{otsdB-D2_R
z{vBWBf@t5=+7%~7wWl_*yT0q)cM_p+zu?NvrymS+AwxKh+zTB??yDGxIB<UpR#2W3
zvd=fN`P;J3HQ8sJ9>tM+qV!CMM&Basd&^n;oI7?%YpNuvoVZ_L9gIGlxaCgJ=);M7
zoO-z?9#;<BFRE0|fg6`-3gN*02dbsTaXIV2E%#ao9FFhynfPntTlLQH<tP0Z$FjLp
za*5k^y2s7Y3Es_3@8=DF?e#kyEco-+Xzm5_LcN=nv$lu&9}LG+8&^=XQ)$?cHN?G>
z5<UQ+HQ{s#6E4oesskNo;bl&9={M={b1e<jjGu+S)|GuQV{LLpt=E_xmN+qsYa+Ht
zv?oRdF8-R(n#=o0>5^)RP<TOGx{@)Hw^Hcw9#+pFaR_bK8HH=f1ka~R0G((_3e
zefUeesbuus{@`w-?+%BRRDRNbqL9&dk7Fk+KGJo{N4n6Kvm@ce^)&icYRw%q)Or@B
zGjr@N)G`uAADs;J7%%9p`m={J0RSNYxPxuPuF4FvyTU}<FGPN()WNc?oF01me%i@7
zN`KJrD80yWl!nv4Z+^j5cqh#%52da;h@1IUnb|q#=nw9zjttMhV>*6-R@eDifPo5P
zozk;8FxVYhK`^~k78C$E?$GAk(pc6J+Da4(eiSY5_lG`TEv>XdEX~dRPSB$rCupC_
z8{`D7(u4h<KfwRlQvT2H6fOIL|MNTeKXU~*`v|AVBFFz(e4_{apJV?Q{?F0^7a@-S
zGrL`nG-tFXB5c4U;qw$M*P4_|04y&bx46sGM_9syFVt}K_QVXq5<wz7!JVN=Q;qho
z$$Ie20oUinZ$cg&*JoB!+@3RDsVe0hx92SgA_{ogQ%4<-=T_T4<$h)dZO7ADXX(pP
z1`-B#3$K%T4dcAPYk(51;`Mwi>-9Wd`TK^I<MVfD*7m2rCG8MQL+l{bz;iy&H>>a6
zgTFTf&r|Ns9|-?1w0$o~0>rD?Sppvki!fhnzJY10^_wC%;9XuQD0d!i>OGtD;yy`~
zDaUmH63dJvH$Se51Tq%)HnFe@drq@U!)1$TwCp{K<b0o*Bc?uo4p?hpJ2-|OQ?A0Y
z&FAnbr&m7fYBd6Hyo9O+S-0tI)pBc|a4g(UD`3ox-_BiO9p+v{)h7PK!)=TnxION8
z3fMd4Z_!xax-GjK5*L{B9!Jnbkxk#69C*fI1%nTwss|JT*6*%z3fqZ4WC#_~E6(TD
z5?nAlT4$i9^T#Hw`<>DPMjW8ekO9X}9cbB^?XP+nvIA(E`I8W1O&p%z{GmFr#o3t|
zh1F5UHeBeOQk<XND=4srU<Pk%%`>_E!FN?1gf(ji`>qP(Aci^S4+N+`D-E!(@m&=L
zV}M&-&;fo#<CXj_j-So%5)rqLu1Nesk@CzVp@zyOiD4X#k}k@$KpA|QhxiSskXWHL
za%Oy>O}!}L4>hdJa~!3`xB3GuT?<W|TH$<foTTN$XPQ!#PF<umT`UD4t{2D?l6sar
zp`oYCb0ynSp2Q>3c*+U1P_R0rJ+Vz4N7nbtV2yeJ8>(9Te;v2zHQTKJnaxbeSsY$7
z0hNW~nbdhN+x*0$YbcssgY>_^)G+sR5-<!ZjD&1%IUm-_2a^$yPNU+rmAmv)oBG|Q
z<<EBZyG!4iYv$Cfw>0=uiv*U8$_HaRw+$H$B&$`<(X`??N7ts$b}9zqAx1GVK84@1
z_ym5><EEnFXt~xbA-rk9n?8<EB2A?~b6)b&5~xj}UYLH<$;wYlU^W5NO8HTa(Y5jx
zi(rV5osEKH`cD+JzWzi%f7Sj!{8hlp#3SjSb00ZycbU7`b7F&Swa!@pG*Ms@khzx{
z4*w79pSc<WhQ){ZqB5B|bp;^qlX6(?{8Iwri9wbSTTtDmUWO}!tzyFfKlv6dI-%h8
z>|gh3SmgB{bMB&1apxQ|vhsn_L*}%Qa;J)P6*k|@N>?RT1I-%&msQ(8y!7`V!Oh((
zmj|brZ=#OAQ#W6anIA>lk0DZBxRxxmt2)|M#G(%os7jPT6+z_r(|ku*`miU=ErF7i
z*v5Pie|u!5Q>=skodbeZ=ydD|OXGnPV#%r2#}ts^bPp7~R<ay5Ypq-;IicQfzA5Ju
zf(1Y|cSZ8&0KVnJhb3gY=&7p|O|JZf1A+}DJO<$o^KEnq%9rH-NnX*`W#tv(2OzIJ
z%+~r}$t!5=`+dE0b}caRCDkJ2EJPX#n-im^WgaB#WV|S9tW?9z8=0BG-8zFJcFMXM
zB-l<Jd(9ozIQkWR1$`&{M(`X={)l0a{chR7l!z1CB!s3LRfP0GM@w=RF9NCTAJh~4
z{Jbo6V!Wwap8%_rEcL&MH-&TcKH0HKo|5ZLkqMUYf7sgoefCMwe<|wB@!smlQ%C;N
zzj0c4{i=9V^U-`r1OgFCvhk*N6SF8{J|l#leOc{<n>vGX$Rur;ucWTLKAgJgjA$;>
z6iU>-p-^uEC=8A?wdS9kJne}SB296jT|_*XcCK*HYu!d6eAbKdLhb1SxmjEsG7fpU
zX_5xbZZ0CVrYo`{N)34;vh-!szs)|^W}lJl^DIYnX`YiERDbNLlk$btzmNk*#h%&*
z*;Qf-+Cp9sTSUdE#Fjs+7h+Gfv-nDM5q4K%Pt8`br+%isBf3oBB@6<D`(rgN(V7>C
ztfXQ!U4Q}y@+YyHdXR4<R@3}`ekASZ>*r%uRpsQKa@C?#9=`k(WT0^Bp67o|NPKui
zCumjX`x3DVswvbmEY=U>)@_tU+G_oAlHv-uut?twLJy7yg$1Ynl`*TXVK!h-HfGfw
zsx=Ws{%H)Y5VuNe^6`?3UG+P*yCdfiA7RTt?5Y>j@5_PkB|)e{>cUWkrcpCd!9OHo
z(bo|W7Qt<(I8?WNE)LZqSS0?Y(}Zkq_YIf2O9p~aMa*OA2k7zh5vWvb0nGg1m=^5f
z&wp@aiWD^vg-TC9N?J)(mDJBgq3Z09LM1G>lCCy^2K`Z}ex-0?Y5W!?Vf|iea(t)&
zRiX&(k3#hsjY||Ne4_R`GZ(4q)OHbDSw_y5e-w!7_ndw?`6?TT%8{+u^Glx+#Xux=
zhcH|Bt&%uYXhxTm&KFrrz<X2X&YZCI_I+2W(&6Fnq7NM$i0Y~{vJlmp8o*f2{^~)&
zs0s;2Rfu%31Q@u|YuPjcN=N!q4Tk<!&KLNZoFMl9O+>1p5|Ju+T$_Dd!Wb?6vVc@4
z2xJ5|_>zEBc&TS2Qaz`F{^<Q7sU$R*3P}}iei!^lJ{2Y*Tv<lU01{k6fcfE;vh-)%
z`eox$U6zeU^&{3W*yn_!(q{Lu`}NO7qk7?aVP&$Rg%(p>iDeRvN*@%B>Vl^ovCIkA
zH8>j8!*{V`|L>wv9YmpP`|;|hfv=24wOJLqU~nNtm%b2<YN~@wM54-g99k$;G5tP%
zbdbWqQK{yq4?CHIqf*UxqEf|FRH|5O0L+r*RI1u9i%O*gtQW0+MOJ}q3`C_Oj8(s6
z_IEzg_m@Pa%GO>?0WnJas*qF*PY6kM$#}J0J|B{5q2lkYx8X?#LQ)A!xH5B|dT<dc
z$7lv_Av;jjJyyS2sq8`-2G$l7YTmu_W)+s|dL`<u7dT`G`y?GG)TF2rY)UH7rbuX7
z(=`wTk<z9n9f6Zla)5JOOR;QpstYMJD5h1WUC!)(7^-R{H8_Lz4^J2JCQ+Z907xU`
z^p_7s=?@_gkOp7+9bP0<)gH;<llGONs-B?4SB9$kF&_tos#+t-JAi`|eCmEl-qW8H
z>U3hLs+-A4g#u3Lt4YY9o%oV+P%1N~m5xm2gsM`S6RY$ywFv1QkaH(Y72>oKx737l
zVX83Y(~?K&-aO7dimnVWPK;8er?Gp0cTrKQ^z>FW)US+Er6e%Xe*!@#N>y!Iu2=d6
zF`{4P1hEDw_WveI)pa!L&0Hl-XD;VAFH<e+Qiz&JqEuDnLR2jgz~qFmH=UU|OodMf
z5jdm_z=Tayz!(To)hAHH7<C9-TVZ0_7o$~e)CZzf{g^w<e-N$8iay@YvA+0kvKn8E
zkcxTffA-(O^z;3QSaamh9&r!ziu#*JZTy9;wzLJj<Thrk^%2cwmGrB4ZH0+ho$gkj
z`K!B8=Td6L9#QRJ=lHC3KR4xKJXRjU*ohWq>Sad=D{?wlr6>HgVQn3MWah*_)hoAz
znCt!@_Ra)8>grnjce0Qn3zGoRu*rZRQ3N7H4F+sR5}atFVH32diCG{uBr%y0P|!ev
zC5(BcYFlfyrE0D9)s|;n0IP;Yh>8$gQEN%9+Fy)I+#o74|L?i?H<J*8weP*Y_j#Xx
z2Yxx{?)RR%pL_1P@+>cc+H8b;JN1)p&EvOroS)6(iGf{P9LTQGdQxSN;I@9w)l2xQ
z<E-3pF0(S&Qn(uCl24H#%(Blv+Gk+FNvw7jec*6|Y}Sh2?Z{4q_RTEFrmFz`Q^@~u
zHw&4<?5PQlGl%$>8G0PJFHDaLP)!egz9n)f-So&C{{rnTil>Kr7n?_zdl!3K=rv-y
z*iVOwZ6fCMtUa5)#eFr`W5`R%%P=qaKl38a#oe`Fi%0_sJvg7_o}ZRS6rss12DK4x
zvTolr^>bAL>r{65C1c#o5zlk=OYS5FlOHO@S25ave9I70(og7E2a(m2%~F<dv5N8n
zD0qBcd@~b6{cJgbzn)+?o+Fi?#X;O-@bi$VJ&B4$0#B~D`v1*bRrLye3n-4(Yb~5O
zT7JCfVh6Xj*E8@w-SLW)Bftq6rx!=PV@GAcDH!3~B(uodXor+-+6Xq;?OSMwka)Vh
zxF)Oj*Mv+>3uo|XdL*sL|JSDT9r|fwL_w`FQX+0`G)50)YL;Sg1#rYk#0oF}WZxW#
z;C30qP}$#9?eI<X7JsN|Au{EE+b!gXkx+1Ox3lGyDI@82E&n`AZcHH!?`;}BL*nv3
zOvFz=CZvDPdS^8~qH*k_7<pW1SM(Pzn!BZjGFd(Lz>FBeG7uTq?t6iGjntO4@E#FL
z4I~sk!P)AqCdRqo?FY%QUH?7z^TIj_Ca<P~(9=el$#!1Z)R7#bO7oeT;y)BZJ{-Rb
zD{rwSrCfy=oq3bmmy{Pk9Sl=#i}f?6Z=TDbX#|tUNmG&X%dHD4HA6a07P;=NlL3|u
ztd#v1;9W%GF7*bYBloeyXD(FrL0<LBYS;wnc`qgN3;&3NS%q93w0?tkeHDSVoOP#!
zMXlgT#Is&-c|zsvV%_DD(Mbk_OA~<}tG(8aT$!E^h=?6Wlp;_E^Xb-B2^9aV$kv^=
zGkb^=X)9kmRdN~B6t<S!Bh&@a+1Gpr_R&t^KM4U5c^3s<DORlbht2cW-O~Bl8>{wJ
z{DJFKnmHnwRBA65k$&zX>x2BUL$Rv=8(gR00&co}2G=P=bDhp6?Q<x}da*s2odMS=
z4y#?%A&b8O*6MKl9Mj_PD1MPaA7(Y;AQ>nMd$2zIr7nZyUpf{#zI*VPc<hPuW#4G7
zj5tNdcW$C}MO`q6lJ7$-wJ9}H7L79!5q_1R=qr)&&Kq#7%FqwKjIUpo66GHo$Z}72
zqbl8(Jbjda0n<kdh?%ake#!+3tAn$!-9%=N_e~t=XkerbCLb!&huq>MbnV?Xxk$!s
z<8%Hfa~1b0_R~O-4r9sT4Xob)X_330I+c5$O{<&5#CtAsnezRRnO8rfaOZJld11@d
zAd8i}fX4|d1})DRkbI5yC*(EeI#FA9Sc@QI<?!qKo^r(M4gCB45_97p1k^8&a=PSl
znA(yiwt@N$0=QO<((;Hd@2W4GF|YXBs;Mwtngfq-#N>DFsux(#*ZwR1teUzW$B^|Z
zvBo#n2zoU8<BjhIY&x!6HTBjWc5B40Y}M4J9(Jq6ZuY9Fa5uwYZxXw6S53X8huu1{
zJ8jj}M<TlY5f41YRZ}0vjyY2@;mY3DsB;^*Rr0Lwwew_6qb>=j_z(&Oir9D?HC@_Y
zqD_W+N3U+)M}4N%PoKV*c>U4VD=<nK{hoS=`bR9|4gWA1s2|30T6mbgU@*jOS{UhA
z7l}f}zx5oXZ`>6cq)QncWZY^dwrhy3E>rmmWI&B4bX|`jn%bnsp0~0ks2QSbyNBrO
zM(Y9N!q5;Mxu1yqj}hr`B9-{ER}!v%Y&=G)d>lFvF4=RuA==DfdIIepqOB+IGNbcD
zjPcgzD|B?f0$1%yuS5En(?V~vit61$l;d-q&{NOYng_Ex@S10rC}*JfFZg2e8WAYl
z;hge8UFK+i5{&i_vK}4nx~-Y5b--dh8qC2TFJ7#RTpQyJ?s7dkMO^k+MHfrKIcVtR
z0oSaCgT7(x-X6@VJL2~B<8OceFC~)xJI{w54NvO1DF-2wtKqNYqArs&<+{xNejcOS
z-tn=vm$kXvz~S|(X=5aNo?t&)p8>OaaC>lTUFJd`ag6q#)$pu;1mZcI+RZ>Rb2QN~
zY{!X`1mrSqYYueoYwt)xSe*3x?TlGS86?ZB9Xq6X_%7ysSm!ji@BC@~eKR1)*{&yB
ztcHt(IzdXoBUJ0i@OE8z324)yBMv7BvR&*n4G@OBRI0<IgOH?7r+qMXQj};epN+vM
zI;@XoP21CQ_|aB9Pv|@IdaZ>%4bEVt>AwN9m^)GnSzQ=?1~Rn0x-<GB7GdxU4qq<q
zZN!=Q_BKwx?-41%8$ww);v8D&*U<Fdm6H~&sYWletS5xEQ7n@z2L$>z(wq5l?Lu!c
zvIJgKJJrtO`GJqUnfq#3W<6^?u^s<r%FoDait6l+S5N2m&Uq2BX6u4BPVb<1dZ_Z|
z?8XsqfOkaFWzEE*840@4AAfC@6-*vN(O8<9WL*uvp}bTwOCjV4WLd8lMF+#!`?9FX
zK=@N&ns?t<dL^38`#@;Oz$#TQdbm%{2@NX~Dsq-|@V{=8l6A_U;L$PY;1Z0jfnJ+d
zgx97&At(#LIJqQUyj%pBKGW-$MG_@@AskrET#Ctza*Qk$hG$YJcOw@wsb$GsB$>OU
zn%&$X9JZ3MP16Sh`qtla^jabu?$Z@I-1~rU6VBXrWW99#U4&z-NmJgZCf|Kv!cRFJ
z<%LeRFNYYXqf2n+jZE2j1(SDu7dJ^inEWs(w+eEnyn%j|9{6qI1>YGV$Lq0>y;?>d
zi$vMU@WbZh{oYMe?Bwz?59GPBsizSi-pQ<b=tZ#i!Au`9tG@cN3A?Cp*@oyJ`;^V*
zp+=`KQZ$kjd#7<^F{OFcRQ)z%{1)>z<E#{VKX;k(iapcxUh9RtNMWmF4Q7|TpdSi&
zRSFMqvHqJCk4CndSSI+$ZD?Gpae2@kT)#CnC-b?Qw<HC$=!H_JowAn63vA_By=H+_
z{4>_~C>V`qbpCj*X|;+CBKx9R(&q|fjoE6AJk(m>=CE)6im0O5Pvx=A;mVWTj0hb`
znu`%=A*R4nf}Tg}c%y->^R65#1)J=qMUKXm`?J=rT;Oe7*_qSuywBOVvdi;WVn<AN
zV`*3RI>v|m{nmMT(l}jfPUW~oi{h;5^d}zLsj^}iMyBTM_eJK!ejV6jbd|^=x!H5_
zGbsFJEcShuD-9mL49mynqcMZCLhAyskjUgKKVdNmMeZEaf`7yV>Hs~(1F{319YeAX
z?sWQ`B&kU90}msX%IZK~r!$aW$Wvd<o+l!(s&7y9O^`n)%by|g$5sDDmcJn<vy&T^
zw{1f%B(M)nz=4-LVmLePhzPtI*twZFRpY!JCvPRoOk=*89-c&>I$ap=zSE|wNWe+c
zRTSX#=_(qKI$iYx3}DMYqJ0cilM{HSW02>MxG4lu{)krwrJTTDHrIhQ=I{2b>GYkj
zF8VaqG6!2n=PbUzuF12?mED39CCl=i;M&qY6o$=*iS^G$krnKvRIV-W#@F`q#M%Cs
z`tUcbBbG3Uz8LV~c(fLOhcqJPczcwU2sI6j-~F+y{iT+zH$VfbUG|DF5wo%bIXlqs
zRj^A6i|9IyXT_K_+77Cn^DSNgkRgrT*y#(XkH(xfeIaa30Kc30nmvJ?CvWA{cZR-T
znAOnfn@Sv^NGZg@k$pxe1qvp=I=?$oKO*&U9D4t3yL8a4J?^Nn-`FYV?ni>jf1XDk
zTdet%!5Sz9$!Px>^wpcIfkeijd7+7B?l(pA6CI7{^CAvP-xf^16D!txzp)<Y2zr-F
zpl}^`dNQB(_w&^4&Fbhc>NKK2o!-E_wm_U!m`Soa!|!biW!Sz3fW$yfY?tI(9*@sn
zy8;y)#SGbflqsXmvu@WI@7kPJ*P42g%xQql_$!*4r{Qy-KM<FL@{wnQR?Gn^GN(mq
zb%=Ei8C;bizJ2**<ou733YQCdfjId2FPS`)HLiTg`U`i-AjpYj^($W*>QCh2OAG#o
z&7^Cvr`<v9GF4j-{F%KN7Jo27brwdGg)P#fH>)h@@`*nokhA~fZT_gZk2@mbI;r$+
zH1`?PWu@sml`R!uG^PmM9kKv&nK4S~?N*fXkH}t|v!LU|&GK%e-C|<7;k2M5N`@QL
zlMw=>33_;7F*~rbxp8HSYt1jj0?AFv+I;d>VpLhK1`!_>w9Z$Zxz)8s7{mJRNR1$w
z?_8VcsXrWb?F9Ztb0mwU>&g5D+`W<`<YbH@)jAWnE2kxRgjMbUa7}4wvE^*)l96?H
zh&aCy3#j92koOTaiBaK8DU`LEn^oFH-bbXRaGRetQnYGi%SZ6s{0Y2bc0`J;buDu{
zpk?|ICMf?<>fqLoXuq>>4Uc<)ui9TC7t<v_{*gLuMkOopO*@5TQV??KEm<gQpZrO?
zc1)-AzGal$b<;pbA1S@-`$u$cX+9L{owIbITn(QZOI_=&VoCP>=eCP>F^D0#_B<g)
z3&iCX?;tEUJfmB3#_zB)Pt|RPO|C4wBHMB@-@ozo4)n&aY_{8caa{JgQci88jeF|e
zzA<#a)b6_(b=l4mCl4N@!0sra>OlO?0G&H2<HoI4Vsl%JGdn3GD`RD=->nDvp?!Cp
zJg3ub4?nwP_;IcI5!v=Mbdp05)1#k7=&i?C6dr~cln(JsNWR4(rwF0Z!d?v~=fRED
z^f;4u5+r1c^)d1ldBwwWxxOGQ8M?LbVx&ap)s>_;k5G}Z88o08xDvW#&uVe;FHjVO
zxOgCbkGC-@78&pfUuZ^w?rkip8DHI2?t0mDh1O?TdYvR|xfSqmIcoS(GaWa@nnVsl
zQ{&@=2yE8^L-j7%-NHH$Z@$-fk7^k@WIczr-be+@M5|bv;PRBdvYjpb&TQm50$XJb
zEh{eTb&j3_@-{{~fzz1E@IA^~jJ)4gU2{#zgPB!j3}yuLBKxGr-+;^d3k8;2e>Jo;
zve7P!6SLT6$*J|HaR1#C*eVAHg}i;5$MS-?gvQP6fwX9LfGLB6*yprN4eM076A$CV
zpTbJW^_WAr=L5?!Bhc(F7sl%~ciI0gF0RL7$Foq9^-=v7NBjxaKnP;^SsmxW%$k^)
z;C%vS7K%N1(JWc`i$@Q+QViFV*-oxyXLSs;Ui?8QxK#)WL51C;>x5-f#Td8ENXud^
z`}<pnOhk6F$E1k}6!$({kA3V~vxaiXt_9I0)<zT7-^Bv7Y3yr%G$ZVptkSJJagqxK
zFsSxgKhR9vy`dYlbr^fxpv{jQ{-=(}yuh2>p3N9@<20@u%2+1>FVV3CeLBkAo>5La
zI?4&(93>Z3h3hO)M%q!LL}#yc5C*a2a*P<-g<A|Sve?}7eH~-K5*=9Rzsij~{Z9vT
z<X&W>#KRTvG18*k2)6F=Y?399_0T!2F5jRYV_B8cJ;dYGg=5?|oa=3>7&C@TzROPF
zvaj3&<f3wn>ro_qn_+!)3}B!pYp+^fu7m_yMDOnt$N&eQ&Ls4TU9QJ=c4T>rFBY-&
zBaIh3sq<5ar>yY|-nlP6AM55L`iAo|nsH27W16=<23ES>Exk(itj!)NIn7_hP@`zM
z(r~L~>$J>ln1lxz?vt`-y73pty2omQ#j#J6ZM(kVMUMCSJM@l)keYc6d%F=1nlz(l
z9Nwu3V_4nM3t7wB{F83I^7Cx{A?!KL9U`sq=LO#&k;NL24U=K4oG?To+A&JT1pQF0
zPfmCk9rBP|mh7SpmDPBgoLW77wVYaA-j*}9c(DIu*_QWnJqiILvolJ&^hKIZ`yfd#
z(mEb=J?dhq&}Ow!GT}M?M3*qXEj!Q{PlMx3&v8SVC-dVK<Atq80qF5RYL*kM{`i!&
zp-_oM;n{2jWU!_G4)hkUlE7YGq2{T(MGl`kpe-a5u7<PpI1yGP+kOgWtKeqof~OJZ
zF*y~sTLgYc-Dr(9c|gv^Nj`KI0xU))8v$=rF!{j?by3#zCrrnE?19*mwbwBmYJD4_
z_bseDbgj#H=z5f+g|)0()Oj3rT{>3Pv7%VP!zku_EiH7u#;^v5+1A?;iib(H;6ELc
z?DdY)e}IYu?{C<3D4(lr{W_HXG&j89yYl`R|EIZ|f=Bf4hFso+(Z5wFYe(w=joq0S
z`K<TQ3%OJF<(~Ya&q8B+7vW~X9XsE<^}R&!so;}rd=&VJ#yYm)pno%r6$hP*zen`n
zul3)<`tMiz@0a@T7y574_AIUWM&AzO)Kz+NmbdY8KEIdUA`FP=b#QLIQ@D<t;|yG0
zI3);QFbAo{dCV6#oR%GUF*mT)6MQx+BLfNto8@urPPr`3>^gp1uqAVQ(*nneh`|2r
zK<To;A=Whh7<l^Gfx@UmcTqRW+@u}$0uLt0DPH|saOGFf2)6~3H|8?#3a3RM|H>0u
zxtls^2>e_;BX$M+sHXGUau4yyMps15#TPc^O-S^j0D_&v($l<69v7Mim%@&x@3wVX
z*FDb2FuqM5*U1ug+i!Qp?1t;rG057e>s+5l#qLsXzDape4kdng4NmU)Y9=BX6qzjg
zh-5E$5Sf!smPfX-1AaA14uJXN_Q+%C9Aoa%>kl8NC8!}0pCVhx=9Apztm*P`ZM9lX
z38Zsne(d@ID!1r!Ig6Q1Q^VnjOY_^<rx8zk8}y>!i%h}2hhSb&aFjddot2oI*|L;}
z=S`twy<tM>vfr@9F1s)hWuE^rG3|;BmA_oZOgZlG4G5Kgdm@~NH)PPM?3tVJF?TTe
z4hSGBQ+?9{Io0HdjKjp?Kpg%QgE6%hCuPyggN_8dYcJNtft11Ib%cj+)^uU#s;NSA
zf3$UR85wE1xZC1fECOg%%XfOGJa46zNIq$t0UBq3#@SSw7-AxX^+E{`R6p8NEouSx
z$t+gDtxlxLEuX~JFh*8V*{~v-f!aBn;U<d=X5c6X5uj;aa5;p@Gg3XN7&l-Pb#SlX
z?$&yD8CVwE152Sju;`bnQKFcLQqmNZlFHiYs6Lh@eJrh4A3J3oS<!t=1^kPrz-nmE
z7a8*}VKc+}bp)!T4qaXy*dsk;7^J2J(ov+3+|0HwuUJNE5s`S7EZ(pvT=^)TYFoO1
ze!(%k-7n5KUK9B)v%2mca)wH^|3|oa{BTjYdANEs56vFN<J$bd4yvDy64`7;)6i%y
zp+18e8R4AT(@I;8G+$pby0HpbFzQ!Q;CFf`0<7Vl4PhoV9pLbsbp!RDcGW*p?}g!d
z&oa+lTPui7DqQN5db}MV^`0g5u2~{d*-Y}(uDplMg#ul}IZQLu@B+Jr3qn(eSzVaN
z<qM^LyMNu|e;zk!$M18k{yE*6Lq2Cs(ZQ`TzOzKVP~5sGZo0JS$HoqBjbL^NU{P;H
z*st6i+#2OeFji6e-J2*;hqJXk+CR%6k?^l^7lkmkN*taFZHtlRHaF6@YkfGRp%V}d
zIiHFp3UcJ<8reWWkuK=gm*Zx2eV#<f>))}m3UhlKJ#BfSCMS>`+bOnPT5pc06U#3D
zOC&b3{TfE$p7E{cJW?K}t9fJ-5h_<oRIDo{J2uO^YHJ;4vhhBTbcl~lS(x(z@g}`I
z*Y^H=GXLkrCQ4!{7;_WFE=BCzVwXy`vc$ek>@Bf38AHJaww+?z<$oY|l_e=40VKdx
zFPSu&dNxy;$Ce+RLF;oPQ9N{X1$l$dgz89Fkhi`)qDLj^3c@ZbTuGq{D(J4D`gW(#
zR1?nO4_8o(sUQw|!byC~`pJ&%5=wNEuvAbAb&)6)1mOmoWIQ~ToaBF5S5K{}p6>eA
z^~3DB)YK1kA=MJDCR0CKd(=;!ou1IQOXv&1^I{?W+*qlETubcQ#BRUXwURGgLsEUS
zsK`8%GgCoMER(*eezs6Q`qcbww(j~ta9KSEa-G&Wh0^;k<oybRq*$p2aa$t|l4_k`
zkTfenBXL%=vB<IxU#UZTtxpY7V7+IM1=e2-QfTcr$YN`+K{BkJ2C255Fvv3NVT}ZY
zX4d@%Un}^X2464udV|aOVl^0igW$^yF2j#iVepND7aCmVBWtd~n+5k8yhZS725%KS
z&EWe5A7k(~!BY%w2_A3oPQjJIy9EF23ZX+lxWSfXaHrsZGPr2?w^|LJBKQu2y9M85
zaM|r!zcqN8;2R8{A^2?umxZ^r*5F>jR~WoN@M?os3tnRIWr8m-c%9&R245?9mciEx
zo^J5l1y42jV!?+S{C>d`4ZczED1&bjyz6pZ_GZD~H+YNSZ3b@@{3U~L5WL0U`vw1_
z!P^AiXmCsLdkx+x`0WPo68vU^%dvu0XK;BU-SQbcQSikEPZ4~f!QFxv7(7+*Y=fr>
zo?-9|!B00htXT9W8r&=RV1pM3?lkxU!4EIgWiJ%G)8LB*f7{^Ig6}u@GQoEnyiV|D
zgRd3*VS}$1{C<PqF8G}W-yryUgWoTBgTXfnzRcj81g{XBy|rw<WH(&a-PikjGZS*?
zNIVlWQ-`>aCo~c=jZM0-LE<Li3}Z9e*et+ik+DfMHYnapxZKzr`EDpRJ+>%ns5`yf
z6g<BF1D)W@;xTZc8=JR`&30pxip_pw^B=~B*BTS{7@J=hn+$Ar7@H<zlZDL|V{^T+
z@nW;l*pwTa#n?P)Y~~xAYHS`hHaW&-88#0Xn<?5RP)BFR@-Aa}lChML2+Q@xvcIu}
z0%BQjEI+#}M2V2DN}+y&2y=*ll7D#iT8H(M72SNvlfhZa>#9PbW&ZdUF5%8t8|C1V
zE&>q9Q#|YcfZ+ZCYm=-iB;aTg?06a_HqV9^MBVER7DIV~XJrjEY@Or0b%Xn#v(0}A
z8VHDLzW2~p*(UqnUEjSOzMyGv|FTtY1zlyUzU*=>eU3#i3NvXU+x$=EZV7Fl^CDmH
z)_2mN&<r?bTke|ezFi$I?=Uue`-9uzJjyDE4f8lQ$tT+z=3%m7ws9ADoY_1_v3U;2
zsjVH@6yd1+>s7*NDZ*g(^Nw?(V*RHZ9fa8VKeVTQ|43o?xQshHVy&a_V=jzuN9`TC
zTF*)@!gn_1@n#akcTw#}GiMt2=V>i}po#wJptR2H*cAUnS&)g^!{=pQ53MhL779O1
zmmTL1WeLcwF-Q^q0`cfHZ1K9DVIyo(57$iZ@=2!srjoiVLCQMPR2K!I#^$q}^j$=q
zT@b3Xzx1l8eLX7bX`Q!v%h_FF*P_L-Gf1`B)wQ)FUPu$7`nRvEwGxa%2;bO><LC^o
zPph<e;jjhwbtvoHNtg`p7eC&ngndDN$>U*TBBxLx@&ejb&eao2#n_loX22o?76Wt|
zfrNQt6C8VRD#C@Dmzb#aF7?#8loogm^@C`zo^mj-ul_x_yib!K5Z_huCtv<7sDCfg
zH>du+DBr~T_xkxx2tMmO(;Bs0*kvc++4|iw*j!ogn&12x=>-yA0kq4}2Uf2es}}(s
zD==>}=EuccVKs2-WW-R6IH8=Hb&D<L6-S>v7k2HXQSxf-RyL>2-mPs>-pFkt!Dt<2
ztc@0L5y+W06*=<*r;q7ylUlY(Z8{)y;jxf+e==kxZ{?!PTkk&)lhu4=xMDp``H|Lb
zKjkn4E{YTN#oqhS?_B?t)0b5LRh%!r{;Md2$Y6Y?cATCUcv6-|d9u0n*54;MZ`3;d
zgR%pUZUo<Tll&DbbVSP~qC#<;8c4X5qn*G$cnt19^ephmmdt%CPvZegtrh#G4Fo_?
zrNzlBm)wVN2NF{8)bXOV<cA1gG)9dfXEEgLclUBJ&xz;E1009`SkemYMIUoVbbza1
zFJ~U$kub8{pDer9q|k)&8g+g%54bd2GP_advi<8LQUmg)l`XL^YRvWX3Htn`G2zrZ
z<n2crYW}5Li-9*?kfL=caoP<RCYanPXOoT5*WIVV)dD!dj&4HZd_U13u8%add@TD{
zr{;GEM<Ddh2x38bfsd`=ZAPK?6v79SrxRyhpp7OqOq(Z28i?a$?r^Q9O2NBw#~;pX
zs&Z17PS@)1V<#^MOg&xPI&(9huAQgf9cKXcy3T9$Mz*42u_j6Uyz_HWE(Z6=KUDLK
znl5pBGheC66}M+_6TZ?k?^dpkHx2L7NBX~(L(0bJ+kYjApl|pm+KfA|+a<3vj<wqH
z&l02c9m-<McV`K8y}~j#0><I@DP$bzkSY-UqKEbeTTJiHniCe2VW<#(=9Xn7ZVr9C
zo&ft9xk_#=kh7vUyi-Tqdb_5EYt73-mZpSS4h@6J37TFa<>hL)Rk~JF@&!2P(#(<!
zi^Fxg&mj-K>rCw<Mf-q*7kw^~29s08qsWW@+PJqBh*{iE(eBQW`}d9ehOqkp?QV&+
zgkJ=La!&$AOKzd>XfkxE@g7WW4*C0zAdS)ce?q%wuNb{okO3e&LGl74b^%0o>nbFw
zd`OEE^<W(~;X!c;bn^a=PO42*nN5>~&JMmJ0QM?8K97EJPcC0&Xf_{g{LhKS6MP9T
zF$cM)fkZaiB9b}a2_$%QYI}X@!Q|hin{1zoY_DNFj>JQ%?O{+bxykmx9$H>{!%raL
ziysRSYi*ZAu71E~LXn*ILOW@eLm;ml0tGLo9dMQsQgd+mckOq4<QAQl&PMQ)l}~?J
z`HbK^Cds;!4Rh#7HWfUy^g&24iTAzb(2@nu$Fkt*SC-S5)bV^SD<aops_eW*)<pXL
zi@hpp7f*@e$(kv#>UGimtcxCGzB2uO${YECR#7oWHuRqt{BAt(QphtbPRQ9naYVi0
zkPb_)&cLiMIGhb-aSeDVi?Etdc$Uk#ntyoy_}9r)MA?kSs6n}$vdX#ZB;f(IcckWx
z-#3FZk)gc)8<{KekGKgV3L#V04{vLYceo8BLD!l}209&OTv_A7Sw|39FX&h=xu}&~
zNRit8c+vAOCwA`oFCuP8sQ)6;e?lO7@fw=hs6ccfurc8>F%7aZ31`o8E!S`=sTCTA
z<?uuAa+n)mLX=oJfIVRj^Wpb|o-x+s0`P_2`Y+p-&Y(5i3d>Y>cQQD7MH*0~E#cM%
zlgp>*wo5bhSMm1C4_V;T@1L{IKq!bJkN4Jp)pqR@VlxsO>uz#ml<Jy8xilGJGH5=W
z|5<Br)PwT0Gnf`ytO=NTfAeLlBIIzgaTu%}M2PcobJiH<L%ZdL8t$=4+wqMM*8TZy
z-b0_}W;WNltg!?OCEhU|_1JLXpYb`Zt*1yC7%h2wZjbe<o?2w|@tq+01e3huk<5*c
zkpgeGe#itSO2C<Wdgk4%Q{3U<4=KT>-;Qa02T_8wVXQU2$F&V%_y(fyuO%@V5!bkf
ziUc7NcPNh>g&G<zo8&;o7<mMsAD*a)k=75ZgTYZ5*7pE*g&wNX723WPKY0NJXa9;S
zhzB?|&)s^MdoO<*DUXSWTx>x;w@*Cle69?c?F+La4ra9;LDD-y%X@SG2Dvk>6ZsC$
z!E6^=%M-Xq`<&KVerOOC@SOG10jWe+!?SEANhF6vE(k=m;XOu9um6Cxb$Fc~%Q?he
z$f~eekK@t9@HzF;!IBeXI9#sVwg;0hrtT!Nm4t$m&F!Cqt_Il>bKZgz6hPkNO_;$8
zbC3#e$j3#ztZAU#twUJ6?u%H?f^p9yD_dA1%4;f~`V}V@D4*N2F8jp1wRvNTJhJgs
zYqL?UR9}LVoURvkpzZG&>xRGTCYhc~^^M=28_9~97w!J-K|RC3p*BHj1y&S3wN%nW
z;)clka9cu$79zZC>#uLw9)2hu5Io7yf729$;zG^?#}t}Nvic^|lov#LBU&iKVWDul
zd7qZ`GD=B=9v4Xzgky>=8RHf@oAqdXi->}A-b4X}h&h2B!Q`t5CxPU6i?@`<e;rA~
z$(~v=W`XPGXzY+g$)i<J`DR5Nj<b=42O7N!6Ljl1Dq>T%U~)e@?w#b6cosNZH_L?x
zbf#tV?)Y`I9EWZ>5&o07T*twCS$$V*8Rg+(>}@+lv|G*}@?_lz=;8ew*JDDoAD;{-
zJQMH!MfJNPMBr+at=c)Tn`xm0FSTJWBq<5&qR8py)1J(owWqYd_jNFcuzyqXX4ZGX
zT@>am&)RHP9?kMC&#vs40%)M<n|bYD=$7>fORB*B_V+Pp+YS&Yd_AFs5W3;hl8<05
z)5JTv#mUtM-3CX%9&MVFAQ}a-y-km}>2W;5$!WUD&N$Dys4=<09n)g{acfU7Iy~6A
z@qcYUlzMOq6r>;3?D39TC@S98NO;t-W{+p`%%;A18}z4A_wie`8Y)?#>zbB&_oCrU
z{0Eb(CYUOp#0)@f<Det*j_>pqqsz^kxzlxXJozVITSVg0WX`pECjQ$$g&xx7U2FD-
z3MCvY?eTcUn#`m|x$1XBNCo>54mrU?g^7MOJvB2umo>6D#<=Q>BT~Zc$1h>hw<uu~
zl_ZTipON=?B|MFS^e$nhlrRYgU0K!QW0O!o`Y4B_-4!+I=n}=#+T=7xi$;lflzkS&
zq00S`yk=+59xc7OdOUp*ApLkADInh7{<Ts+9gp(aeO<ic5vmi@xkpeQbU8?oWVtVI
zUrBYF?p?gc+jLukRBaB2ZcPcDdhr*JSeYI*q~-(h&g}6!gUNoR{h5X0B3XoIXCAq6
zQ-?E{>^@Cev>21Q2Wtw<IN(8x$LdH3qFWKtZ)+rJ#@U7SUq$;bv`*#N-PY!NE@)#)
z`=&4OoxJZ<iLT=r8DYGP!E8UtLXKYR@m@HINiqI#m=zFhZ^|1T_cAXGCx-TAgb%gj
z@wyOETlLJ4<%{#wtyJj6o{Sgk_Z)cdl6NBDbA#5qRr_@8$J3|e)UipXL0LyWmLu`q
zIc6>MB|_^mZHD)BS0Jdv{;MzDU~*l`XkJdSN=*FLG@WFBlI)=ytcn$FFWq21td6G}
z?6$;Xbc6BGCz4%*x}b&V276_3n4}$`6wK%bi%5c`q8sdGV{1Lw?eQG3>QgtEluxUc
z?!J4f^+_jMmEqu8y8&_xYgy%?MEb5DQKFS{afrvT%)QgQv9e2qjHTQ=HQLTZHS{)D
z_}-~#I~$KxCRTbUvV~^A+Jj5A&Es@~U?)i9Nw$(m9A(h&aV%{sgVV~QPl7s>ageny
z>|k918ooBfitecUsD0=>8ymd9xh%mOh**m#ScL1*tsPF8rho8LqCuuMs()k;6=<P#
zURZCzKcuhhTz2y4D@*sR>!GfUgYF=z|Lf6KHc+&cao?Ht`0{^z$MWKWs<M6GLRFd0
zS8rWqN9%olv|JjvtoY<0MAp51>3#l!vEv)`K98k$SS83*u&eSm=4=oy#p%`@EbL`r
zTdBB-)`z1ND2ou-8*qF*Xri$7K3_hzr{3r9$cnZpImL&c%$>f}9(teC@tFI~dY_Z<
z64v{?^IPhDzLUJ#**+DtuWYk6Z68CnrMQ8)@OfCz??U(EQF@<qP(6*F7Oe;JZAR2?
zz0V;Pk)rqcaa?-oeSY+2=f>eZ^*-B*)tb4bG}HBHL;qG>JzFibs_B(v7fMiMKJ^4z
zSfaZcipiOX!ru%lOJKSUKeg@uY{NTk*gzIUWPXff<)5zzIwrS%ms2({lR^s7zP%#o
zjeeoybJqR)8RPp>1U-_erl%t4UEin(y4*z9ry}TZNUaF^Vx&@fD1zR|&_v}^h@%ui
zpZ|YN5p*H_3VQxC6+wSTs@r<%B|SLkRR_~G`f0heTh@3ss>se};qnhCg4WHaW1_^W
zW9e1|eSTMmD1rur6+weX<pj>>0XCFH|No!}`pUJ8m&a8Ejl5;T6E$qcg?K#`L8p$Q
z9sHLRLEk{M!Q?i##M74|=u5PFb5HkU6hXg0BZ1?RMbBbn`yW*V{e9t12XZ#(3(m4c
zFX*9e>?9Udw4mcCg3cqTUVb)DMaTTNQUrZXoIQMe8%59?j1n<kn$(J*4`w6Qczi|B
zHO9A)@%W0Me|lG#&=h*348};*w^*-D)4epL2->JLmZg7K6ZBIf5TIK(T5EznlZ7%9
zjxW|z-xY)Ud8qWwilJ-HF^lMLQVcyE#lwqz6Zsob485M~JRih$G}fI{!JU!dHZjJx
zFO>-o)zIz2o&<5XGgk-K8AZ@2haOyao#=*^4U`0MwaW~NZfLPbHMDJyYUqh#U&6x%
z0?S<uCkaF~^a%n{4Lv|0s-gP{L^ZVByAl;zh0@NuRYPC94^C4bs-f@rT*}NE;qR-4
zuEML`{M%QN3N+BFq4fv~lT53ImJ2{UcrJ|~yS)ZOZ`IIOXb)OPS$6xZP&BB9)&nQ~
zN-HK4t(c<E`FN_KQ%t~bPz`+$W(P4i+dnW!RQuZoakRf72t<!*-)F2M+FL+`YJIAP
zHl-2gx$VEeqcvn<cnNkNA`DtJ^z{dO-luZIk3^7HG;L?F9!P{20>ca~jn<n4Fq;7{
zt4p4p!H4XRr-_n#IoCMMZVxhKh<DBxmavth5%;J0zeUgvbRr;Pu$@Kcr)!C{59QFZ
zugo~=YKS=p=KN9X<_YP}&@b=w*#8kb+c0ZdID_rCuv3C%er@LTD$=U0JW4mT539cR
ze{zB6HrOQckdCbzdZ2zsC!`x1E_KI=*2{=_*n8^tKuOtac7SrhnF4kUw_Y&z)&t#M
z&juB`N%2J4(=qy?gV8INNch+E!+zFBtMHGi9vMOscu~{2YsMIn9PAi`AqtfmZY;<w
zhfjEt2Q+yd+bdUWj9wpeZW-P;aWLnGMGj3CWhQ+0`_SY{_Rn0rS_IBUQnVJamlVxK
z)WYW!X<AIspIJZs-Gy9K^^b*Pegc=z<2c0_viUQ5Y)AZNdR4F^dNa)jj>1yezw3~V
z!{KGKQGW2!FrBu6LMOZUaM1hKA0>Ckv|PEHd|s28@Q0hoXSsfWc*0ZQ=vvaZ34`SG
z4aw)%yfi19+8nZ*67-#0KmBZ--Elp#JFJiFPI)1iyi*tu5{0)uK9W0Z<oK%v;T$LS
zm19V2-_z6g=#s7X2tc{4ZQ+0&9PunWBQv3ky?X7b-eQE~6QXq1d*0ndYIW<u>_l>o
z<atygEoOrq)3R_(Ry3$?F(N|I$6YATCAw0JIhp#a90G6w{0>qLx9s$HwG=`9iYf8R
zpWbwFe{0-LA|Rm6Lz#-FB--ys*QV$v&|f(D%V74Dc=OcsR}E~2d8O{cK>WM-9g-MK
ze*Z*v|Lm2+XCO?@S;DIIn)a;aICO~zl8>Wrt4fK9CXp*TV}DCL!uROwTs_OEPJB0K
z$_GtXh{~>j<b&f8Hin`C6Puznl!61Frs#i1&YIzSOnorR)fB)rulUdff#DqDaQ)(A
z-8aZ9OyW*&v|?qzYq75SXRtpw!^zWm{|;7vJ;a%2itLn#wZ$lo$wS1sgxr#Wxa_9I
z4t+VLBQiL{CekbQGEslvN8R#;5a_uROw`=c(dO-#QDw{)Ts(beC#iZHr|@RlC-pr3
zHlB=bx+gGki*<KkqW4e-EG?=rDmSphyVd$mUSwNf*VeXZt_*860v)1Hg@I#_6#OB=
zw~wUTWoN$YTJuB75!}@-C-YktfHz&xVx`?6!-rh5VEm}{7QafWD+q;9Mr(carC@G&
zf2~N48^Ua@9lA4129UI!S^Z<{3*+e)%?or49j|QtTQp>5W?-Dxmt5`Jt?-(fcXBJ#
z!NB=lrWZCL*{Br$n|R&~y_NOIYME5gl5o^TJeo_EIXBk)JtvG=BuqF(Gq?NThI1;%
z&63yTFw9)-lOwx`QD{MG=S-4AvS)me_5Fjk8p>;vt*m+72e-TDGTm?QC_&vomR$6+
z4ooq({5<v74_2-<4-o^G$}{x4?5LZ(_5wM2A1IfR67&(LoCp4b^}h8UF_~L-)&bDE
zm0c>J<XT|(HlDC9>m*0@I|{E9ekCzM^PvA!>p?;^T{#*yS|%7bv$@MBOQ{~A+sSp1
zQv-Nz{dPstfO#RZOL5m;d&>#kJ#3H0Twj_BEBr!+{v0lQ$V91cKIb*%WSDDytnEd*
zhxH35P3x2O<U6Q-Why16{D_FW;rk`$s&@sGUxa&K-*ug9%`k0$Oxf@GK4t%qb76f5
zO#!Y0H#xhPM#joEoU_}+T>rk#3<Kc=ZRBQhc)VJS6jybMw{e+U>()!lEtc2c(7+z}
zi#(Z)qy)FyTC6Dgo`@iDwy{_wPYSt%1)W=EPPSwSc*EzWB@d_Isrm}Z&cMrDak4Lp
zMNry~6UXn@+69`tM_k^mTHhe!KsGFPxsk<`1B=}UL!Q`W0v2tH=KMB=wN7HsGhEb8
zPWd44B_ck7H)(1-GyIp?(h%s*%Bloy{}L=OFbefiMpf39=~##`&a^aXY8JhY^HcGZ
z*=982mrY$9;SHR5`_*ztz%#YC?eb=xc?%|g6&KqBAJVZz-&MzDoUk~#)H`*6|MOsT
zSchfdbwVGy1%n$`P@25`t*2{sRnQrleZ#!tKazdM8aPs-3XN?jBQCNI&3<dj2j0d>
z6ndGr@ysD4NIIeC-=e?x9?c}^%au5?t=~ULjE&Jzr4;k(-%5X8zTCQlXVG!3w%(i-
zqJf^r!|lFX28;HeLu^q@rUxYHlbgIw>y+g>(jSnLq(YBRg%0br@u1(WHPTrQ<LNrv
z)6b2ktHl`jQ2Nx(-ax<n@$Y*BM{@UlEf0ZK=NBUy+w9AEQb?aKIxA7|v)jsifb9ZT
z=KMqCCi8hy(-*rMeu)pzcu-jX^i`pbsPyzRo1Gagsf<4&(o=^HFz;}Rvi4@Fx~WU(
zimN3+@ga_CKUda3PUED6WqDI8K3BdG%xIqzl>;TDA`{vu3#Z^t?dZ1{bVJIOf@tn)
zb=AwN6h^^qaE3jbs3~RrNXktquJ5QJC)W$h*yN<0%0&vU<a3qZII)AXagKJrBE*{D
z@`ytRn$C~N+~vC2M{nb)zV1}=GMioXvQIJXhG8t-B!Dt!>6yiQ^BTvrK)x0y(Nfj@
zNilmWx43<NA>J*&2?n3ki^`_>e!RB$9-BdFb>wiKxYyv$RW!Nb-ZZ$M6*ohghJO~z
zD7g$Smgh5;pXQBxg$(Dqa$XK5{{n^{eg?2awtj}pkQq*;TR%O)5R+Htc3Yb;kR`M<
z+|5MNtzu8A+HGBO5nB}T_Cw>X{SG{Z&IW9`mMjqf(RUHup1>Du5iASOlC@O1vFvGB
z5jny?lBSd_c5b8=vKVmn4d#<~if9vsjMmaFecfed3}NID?dr^3ECK`jJe#>?3a_%6
z+tSG0pp3Q8F^@fqQ6m<3Z%R<!k3Qdl<Y3b$W|&~B<SW1~LSBxymSQWLEg!PUZ=xkl
z)-nIKl~jVs-T}0kr(^@rG@lmN!YN`fc@CCdJ=plqu+D`>_QTavKm)k+Iqt~|o;<j+
zeT%ANIkm_7Gw~ynz^l)>nFlxs$#LcH!usSlnR3WVy!UpKlN*M0ykUKjk8MV@KhD|<
zW_0~{(OD|*=j^d=)mgoZqf)IywndiNzsA%tZ~5gAipcSF%g3gWMprWy4}K=q#Qw1Y
zuZQ+~haq2h04)Jt7FYhUR#`Y9>v~WvDKrqDven^0L$eWxTwXifW1Sg}{1EM()q()M
z*39Gil%^5OuamJtKWUk3KWT|Tz;oxV%XVaN0<h5GjA-_(`YV*-iIpc?J^Q}o#$6WD
zO$&h7`s4;4R~&q)0wa{qEf6g|-t+469L_q{n$Mx(L}jePtTG%OX}#=MYx{_f6nr_H
zH+Ce3+{pws8FeT=^T%l2U_5|$==EXEV^y<4Sr(a)3U$hyC9>8`OD9?v<b{T0>(vVp
zI+6*hBQ_9ySrzngKyleRg!)Ovn3T{VBa<(pU+f31jCC}XIVoJ9KDcc)8j`w*#y;`8
zFvYz|YoW-XpB&r<o7Z|>yN;Gr+NJ~#ZgcpCG+ysKxGmAuuntST4SnkfyU@ltDS;U&
zxYf6PRNoTOI3wjZatYf%$+~iaRDUx!JoftrShI|&5EE~;@3Ag@T#qQUaP%j427`xY
zu)SlorghT<#(M*E631Vi$dz<nM~)247{iTDblI-?;D#aDfu{-o{9h<eSI7MNXWe9>
z9j;rDSH4hVcI1ffB#{F}2&gH!b{Xp*6tuvC&`Me&<F|Fhuu+S<l!AH?i8@ibqZWx;
z@sVU#lo-7)Es1?L1Dv~KxK@)ULOMiB(pa($vM$oeXMXKk^CZ3zKhP`RELnUQQCh95
zS1(Q4`&H;MLu6`$twhc66T4ZjFcciGgVFhy)4+I*Q4dL5Sm0!Nn!FKK@O<7*iG<kJ
zPp_6S&~6JutaC32w}t0&CDXR_pVnQI&~g=LkX+>0k;(?_)BYl2zq?HMDthr2NU+#9
zdqp`+ytP@^WWp=PCP-_PR?solNHW+`Dsx3}ike|)YGS2N=3jF?md!e=UaO@EwK;oi
zPSb1oXMA~9+C5B85t2fa*THJW3XT)9>M3TTmzVFg0@oI6BUQ(=fy&Tb9VsT|?n%L#
z$x*E+AT}c$auOtqhH=V7aWIsin1??snDvT~s$D-;#_DIbkTQ3Y8UKUHKZ+$6jnN-|
zS4zIaYxLtVJ-?|f(4Z181o8C?CO<B#D(OnWv8j+QIQBICH{FntRLw7I9;v&%ya^r1
z&$3QBU4+A78E|c0yFdhSDYT+&m$Z<J9fo_8<9mg%UDB-9-Yyc`X3iOvHOp@T^@<Ma
z?h81rrT6s_r4~@LQtW`?97<}N8CsR~wXd&G@#6GWpH4c|t{zUBBw>nZA!h5>J>0`i
z^-t6hExRhS60GmbkGD9Vys?r`?z)z$2n>GKit9m;V=BOuFQd<>0tsU-k!E`e#5<~f
zr1Vm8Q|a;{hfvH%mxdMJlxJ3DL@U+ox@~KKf4%FuekGcrrmz96u3wpsMmKLUvbK8b
z%s%|HS~L8hA4+!6Mn6=nwe`b3>al)hq0*N-u4X|P%2k+lR%1yYwx}eue0F3<*DWnx
zS)=-j$#6jW^>8}6$YwkLE(@JdCZy8-_3KH2+s}{zQK|cExXFe)ZP;eRPi)w4vhhFM
zh8Z@TYr`@duCU=PHvF9pci3>h4J{jX*)Va6iGQ>Wcb{#{TWt7%4cFUnh3#*x4R5pI
zZ*924hOgMrvf*JHrlgzr&$8hKHoU@y%WQbF4ezkwHXFWR!?$eMWy5}Fns^7>&~3xh
zY<QLpy*9kWh9x$vwBZdlyv>FiZ1|83ciQj;8@_GBPiz=<mdVF(8;-GIx(%~zINOF5
zHoVD(ciQkF8}7E@pKSPv4dd<l7;3}QY?xs~uMID=VWkaku;G3ihT7&_yME5KVWAB}
z?#F}cM~iYwrS@N9;QD6_?E1NZy~8yhGWOLc_wC->znE8!`<iuzETvhP^KC%HdBZ?M
z=e9WxoqpY11B+F$V(3)!)Lb=FO;8!&@(Y>IP-m$;m18Wm{Y5HQ%}^JsY;EgRUUiOI
z!oPEfM`AL+5@r6KuH59o{BvtNu~}~all<kYN!osrwv*5W*vZdhL&39EDLE}AovZlE
z@x1-JNL8t8`>?+l-#*+zzUSbl8k^oRc$8l);;Y3?eiwjOkdx3)%$0-+{XE1{qssAP
ze)*~hbFo@%n`h$pDs24PzGpl|#M5nS%A=IYzk;5UU#@xUd`j6RU!nXMSczHElUPkY
zj9I8*(iMM_j>J<$e139LVu!$z-%OqRZo9eUTzu8`@;9G+l<1Nl?J^hNr9FJ-L*vRG
zVdvm}v{~{IN>|a!Bt4}}{9=~)q#P2D<XghC9`T;DWXU<T;RaR0?{s%QKer&u`QeLj
z`IAaYCK*Ek&BkMzj>;}AE?sg}X}F<WRCVo9=8KDcRpLCSwAvSP@c0+`Ysu^d{t6xW
z1^!B1@t*3Ma;fk9qMG7xJ(pfp<1eZSSMUWzmD)(UinJ8*OWcY$B|g4N!Y^0ECGn`4
zrB^A!s5wPGe@zJv{ASja+Zc3N?60W}o1j-|No8pdi@APd%CD-_zUKICSmcv<B)o)C
z_*3{%xJwes5fK>`-7m)3KQ=BtVSp<!Y2cv2$tRqcGGyqm;Ui8O=^i!u<S}DU8JBwM
zY2#0yFmY1a8Iz}^pLy2V8B@>6oHqU3?__z-n~|L}^L%ga1sCS!UvzQ7tl4ws!scCY
z>1E$tc=;7q78YGqTvA%LXmR=XuC7>8Syg>aO|8#=?b2n-ue*N5${TJ}GpcHGmX-So
zYO0D$rFNIlmWrwS8d^cAnn+8k(0xmKP$ey=93Q2O7}Do!v_H2lM}m@dm$aWe`pz8w
z_4E^RmG+cNA3Ogzt}?D%OxyElUwy?eoAEDAP2r!!Ie~aQ<jRaAGM>2ks`x7-h~zV0
zr<eyOr7F>OWjg0ewBN;)s1~e<zY;>mGZ}AWY?OXjPN^4Rs?`0rT#s!%;}Z9B(k#cl
zg1^_<{-pQB>fUAI7k?$V7i)Lvv67~n)MQ+7<5J1r<>XOP6}M{sNsJ~$IWCpdha1XB
zDNU?Pu$7V0t$kii{!QL}^lB-+)M70$R%ky}sth}cPwF&OG8vz`=`=ypX$fh|m?~qA
zTct816l1DUr(!B2zDmqeX33M-NJ|iUN{No8RHe?Nv>-DFNcp6N^$eM<^CY9G<ZGg?
zU1?9D`koxF?@Gc-iA(V()LKMY-K0=WSecO|Rug*#(3DneC0^sQ1fQYYcehMQtvkIl
z!s+$hz9hDz>s`_a(R~K_o{L%PN9w@17)lGxB%c%iDeWUvo)F#A!sQ6%DMY`%N>CD}
zyP-yi9+O#zg!-G*ev$4ard-n7`ije~+n}`LP@cN!J6W9_jxUs-Z&#m7NvrP^`>s<%
zhslf@q5OaQ^rUA=pZ(9IcV;-fYTBr21J@E)4ROk<qXMcO+mk|lvzua}{HKTG`}X<2
zlAOz0X&LGI=)*#xkV#r(s200Z3)S}-YHB#WzUsS*T9x`TBcb%~Dm_}rs9DMwDWg`Y
zjv>^JLeP}wj9%?YawRd!_+Z8y8Na0M^fd>B;_7ZsXY^=KlHX(FTLRT(6ckD<*7Z@O
z$2K!YTz%YhLizpAw4b9>k~N;tyeGB0>D}E=rB-Cr@G<Vnc)OS|GF!;XIYe_af(xaN
zjx7{lT95ks_U%PtH*Hkfjm+~h;~$-Zp+{Pe`uq0r%gS8V_Mw<-d&S*dpJ}Rlyf35P
zsx<9nl##iz8nfUs3&`vyGo_)J%syszFkz%M9!(?JgUPQj(d@V6gi`-(Gwe?N+u$<p
zW>v!;$To90rGK3Rj5`;i^l!aw9%!4hZ1W)7+?HVcBZZ`Y)wX$vZFbw{p|*Kryz!63
znf_(j=Ha%vGtRi5WSj4|%_D7dTdZ+++vaN9JjyoLIgLA~1o~HKn?noeEZcmY?e4bC
zhix-Q7JA<b*IfU)VvIRo_kCFp$e2*3>*x~fq@K*EH$#o*pPLy{daCqDv!cuclbxEh
z5|fKqdrc_`Ow|8)XN|g+*cWM^vgVN4$iyJ=U9DTdQvRN+^VK_*9KxA(>nLK6WpCRv
zwsVNj{8EWQMvMyjp!`xR{S_6U{p7zxaYz~2PxXsPjLON$iI(4)X~ZQS-5CW7Vw~#i
zw6ysJuwUJ7-Nc-QiwpTFwXAv>KPNtTNyg~}IQb{WfBm3<`<Q>JjDzOiv2MrOc&V9h
z`q!Y2{dctgRjT`+Lw&n{J!4p{y8lJM^Z7RaLgC&2Y6HjAzs!LD!!5wED*VrARsZ{c
zLp3OHwWIrAgyY-&3xz+nMgOBVf3F8fN`v_qN>NPRc%rRG{_mIA_~`Bb+m*K4SEB01
z4d!5U?f%uRT3z3;=BDqjZCn?)x#{12u>Oa)+<M!Oe*BZ$e|pEy?!4>gzu550yYIR8
zSNHw;{@*<C@4tQUcfa5G9}oTE;YS{QY}4i~kN@$BC!cEGx^4T8r+4mZdFI*Yc0a#o
zZ|lAnUVQ20S6<!!+Usxp>CHbMX#2}se|`I%cmHO!zt{2p2Ooaa`SB;8e)jpnLtS5d
z`PE@mas8JWG{<Mad@Bac|91KRx6}VG)Bo==$d2!>8D#(4<&Wn471@LEZv<wM$qM~`
z+{@gAx#wEq-+GyU(968Oml-+hqr%_P%Y17uvpmDwGd+2#x2IX8IAl%T%qK_d=a+_f
zjq}SZORAR6@fG>X;fG>BueP-2;;X(_TI|cMEUT(nq8;WFMt->G71jDY#lG@uOAD&1
z{ncT6V`rjM`EW6d7L}e?wakQ^2mddJwdNFd6cgbtqC&<5wEy<2tGlUgRUHeu$eZeJ
zT3t6dI+_*Tnl)=6d|FyvLET#ARH@@K3g*|bUSm;LP_UMu?$o-qb%atZ>lQCw>~zK~
ztFB&JU46`YPEKYn;*;~6G5DXUcQR%r+>?hY`x)Wl73o#6oL`8mtVhSPb`I@A2w&tY
zs&JRq)Kt~D%PZX#MgGd-#icdpxX0FNPc^Ke<u|jayrQ(k?W=NERhL$}OP7@v`+Y@M
zRcHn}?(-_eAns+<gS)8GT~v+762b^q9U@QE@pSvEDJ?2-m(^4)A%uzM<WX`q<e_9<
zXuJT3>INMOo_*C-<S$%}?rZ#|HOtE@7rD!H#*T5XE%o_&IICJ;3B@b%S67r5>xK{t
zXvdFxmEU)K54c05<Gb6@P%p=Fvx=d-a36#hA-hf4AqYQ1IK+mt9NLMFqjoB=9cR~+
z;O5s&|3#%f$Y1Vr7gv>(x~t0E)gfNH_?$?*%lJaSNz{KWDNdpuC6!6I$*w%~%UM=U
z2Qf8kYL0l9EGeQ6sXd_}WE(e;`W`1(?c&m_im<FGuPmjFRD`mpj)`aK;&NYUZFNy`
zsk^AmS6bs9H_2aHGwG`G%1Nb_*NzJX?rsk{_3m~hso}A_rmAvDX{9gZzdN1MnkD6x
zR3*8g>S%luuJKp-O5L=P9?kQ3nVxn`-?);Uz3|h{Rr+w%CeYj-$(Z<;mirb<Q>pb8
z)#%j!kz{-HBVAsbp2%7Ct_Mh_%V+v!PrB=z_4Hp-s+&SjKW=}m5N6)onG?*3Z%_X^
z<#8vEa~IjAkXF<)G$|bGf7CcgTTxN9R3etpy_$m|*fHUbuF+np^pQ?c%_6^4c&$6N
z^jb!m@-lbnl4{@bQ~!Q?SJBk$L8yp~($7o7jaeG3dr9e%D*H%pwB6H2>k(1<nOhxe
z2mfnM_MAY}2M--6S(|;=m!C#mdDZIG4vISCoP{#K)GoY)M!0+-=Up<<)Gn+oUs7FB
zdSz%FU070H>s#nMD}7>hi5W-@nU4Ec;!YamRD(+5)u8k^HE6c0HK94KI+bb^Uehg1
z*pKj~cbO=*fbZ#HP8u4ehE6`AI=OIgnuL+~HpA5Ut1x!#Fpk&=6+5|K+K>qeXO7(A
zQp0=$)QKetq!+JTQ(|lSwMDf?z<k(o4RaR39I;U<HXZIpO}}bKoI}M?635_JH8|a+
z22W1x9MBfu8r$rwjw$R{kTfJ#4cQT=hWLOb{nZfkeGHkM+#1TuCU_pANNK2@m!#p*
zYWR66%_hgNJM26!J58yx#&?&~F(O`#@WrVSC9!J6-2Q3=@s5~0r0vAk<mMz-lyarV
zDA!~|Cn>W`H&uKWh02@~t5Tq8%G@}WLRnH~4{jaUoLHSSxStwa;-oAwQWi~T37<S!
zsWE)v@cklGzu6JrSU#zrQ>U;t;ahB{y9fNQJ<Nud{e=G2edT-7nWzKg3#Hp%)4soo
zo!u{-x2Us}x`(fxGz2=(X%_EDQVw^#a+f42_uNF~P9LD$HN!iHwxzV5&^)->F+5%k
zFL9~ia|fv5)bsG!DV-;@*)(wVQ!eVt1x;PEyJ<LjI<o$-y?$wzWynP6Ua|w)Z&xE6
zPpSdU@zrs5J85Hm<KV5RD7%$AVj@(G<7c}42|e|f*iZ3vuu4n^PL6MO^p8;eCr76Z
zNsCh>)9+Iw9e1juTa#&ntt?Q7OzN*r@;#zXDtTC)l>P^Gl4GMvw9~F8?Ica77){qu
z8>*S5)H8g44CQ~MleF2J)^xX5Y2z8>@9(wS{qvM+xTHI-Bxw(mBf@=b#$`%f%J-_B
zmdTH)XUUJWjaY<a2lIVm`#BZ7fN$UzIPyyx6h$A5QG+JCbX`lBjZ8*w@`b{D1b)ip
z-C-O9qtw9k1U2xMxB`crCx`A2)G7TTX?U!uciO}7n(jIe(dZY2N<CPl)C4;ZLng$j
zVI{NFu(<_lSo+0knBxLvT8XKPEHdR79;b%;QfNyj(w0t8!yN-va@(NRq-NZt|NH3o
z^r<0pW9a|=)R4)^%?{oF=y&wp6xvzJ<Zo_!mETk9Exu6O)Ai$vCtk)D`Y&Tjr=%F7
z?P&;bRPxQT%keRnw!V*<=cV+|k?d5-KE9F|l}w(JCnq&K2Gj4Q?~~8L*h&AlX;_eS
ztpC;!%@$QE^(($RLvas_WeiP(Zj7bSdDtzwYz2;9{Yo;T`v^>Z$B9nH-2Upsxj^dt
z#L0uIwY&Hk-d_#BoAR|KwYr)Us^bge(qd`rNs<m@*f8dWVUthnG&DDDMfz9W4N5)4
zcjK256Y=Qu85b#=v;{{Bbf>&2ls5%C>Y!SellY)Vo0(~13q$36Frd@{zHoe+UIU<4
z0`!VkgKvRelE&Ov(qQ~x>@f9D9WhQ1p|0)mzd0$XpGu<Mk|xV+)}6-5KW8t-w<SbN
zod$CYVF#yEH?!?DsCO6PyVFP@4cY_axo!_Nv@tyfIQ1CNU&f;Iy62Pc|C%)T+DJ#B
zV@#|XlRiX^`DAEkO4|vogPR9dClw|Zn0{;Kx)2?n|GiS3d=WNXhm3NnfpcB-y8&uo
zjUELH!*iw7kv*plV@@3gooElHZ`MSlNj)*|=8W_Wq%M=F`$RQp#(-O5JDqL)TBDjn
z^R72se@T=(QMq1-tJd?i-Of%V?Lkup)btLQ77phk+yLczD6YF*4Tw+!CdY~wJs$Ul
zy=nHrPNhEPlROJdIx&_u%UXf)=ET{9IzufcM5i?^N)393TiQ0AOrPzs4w!6OY{>sX
z{QmJ-rOHEeJ&F0}mbkY5tuf8f)lr3!1rcdNSE0p_v*Og)^lKu=I?5vZnj_r9$e;At
z<Fw^xURCNVzEE2}UVHr6e%d@=s6Cpwsf4-dvOedg7RJMGO!pn7zUB+1Yx+xfpEUCh
z{lv$3$=GC%mu(>$-DmO80N?FL(R2WQY5%mXAvN7JmHFc7cBS6u`-APj0z9EZsTXat
zBbl*}_LTh4fa-+8_yRpHV`e?nIj}9U)wJf=g5#{WI%U1(h>lRv>6~N?lztFPKLAcP
zAszi4s{d8A8R>tkfqD$G`)&<w`1A-h)X`|xmNKtvbAN~KKTgc!W7JSzx?^bi6vt3U
znj^HnsP0c(@%>ahV?g|Dv(|Ksj8`LlNor(CBI}0%YGn8PX3E7F)MLJBll9(^vlG-Q
zzQgL2lCRV$>0hc-9G|K1tjHKE`B={}o6i4vj29E7^_ySX6u}*8nJtShw$<3(9?|W`
z`0W1sFZp&un}5l-8#?@7k#8UA=qbk8<bYo~!|;Xj*h$Y<<D=%33S+OJ$hUaDx&c#9
zE-TzR!+BNrs~Ir*e5JNPC`{CyIxc@r4V(Osn5Z*)eo?t^W>w7`m<tu9cGxBOtSqe|
z^o**?+Nz4u8NQl|9GC*g@SdPNwYBAoD(x8NR&^(-N*u%lyVvI3lIFXTrW9xfJhM=u
zYG?$u`Bf$Uiqe^|ATKIfLc!FpBWDS3u?Nq%JL>Yte1C<n{JiD9(z#Xh%S%dUEH0{1
zKeEdh_UBRRYKeP}ufz){O}Lv*F$>2zM_8@!HHBh5ie>!OsP|R2&7&-}gU(hnDynKj
zrVDdsUzC$KW%9(53RbrPCG?*STjN??ggG$t=BpgX9A6Fpb1BU^+6Pq!<4sC8$D23b
zQ;@5JzZ&5!EvlYbQ%e3`)VN33Ch8NFQwjTNMoqa7W@*J77#qS;SDBG{rA6149%El^
z%34F+&0StCsodPFy?E4~s1PTuoBnS_&8u9j=~I%ktQbLUQlTP9n)yrUb6n?$$lTiO
z(yRQ77M0c%)RfjrlQ<=6wy)xn@*1DNsA66vT&fbKMv7ftRn^u0>X|UMB>{>iET9x|
znNd`YbhflEU+FTR8Y^}tXwEX#5s_O70g5Whuj^f8Pi4uR>hj7NResX_5NZkkt)Qx0
zsHUD1+4LUfH#B9B?jK4$AT+xK29l=i%i53WDTs7v>J>-}RF#5zW-v3ID<Lk<$rn7H
z@?S#EN_2bXd_rC3m|0OPQ5IDo5&m5<k)$zQDkfdcbwbr1t?)UWlIe?c7Yj!|7pg4~
z|E4LZJV{l0jHjdoLf0yFlGvDDV_GQnogO`(#-f{`S|Mo|7egTRrKBP~Oj?Kfo`mO^
zhKj0|BF<MYK(UHadU>w~*Bmvcq7)hXNs)Oo@{6iz(X=p9+a5WaoJxdB`6M+#L*!SB
z98%PrZq~60S36(*Me@;?gBsFZCW%W%0{XB!I@HDIR)zb$`i&VM3QBAAX+&i)?T2<i
z&EFxh%q=gz+AjC59@Mo59mrd!%fGyqYYB79NvBp*22B0H9!JDtzVbxoRTY)wm0wlE
zH3Ulix^5%0OHIXW&~e+tA}!*f9%d>B%3Mw@`fC?UWas(I%4ljz-6quPF)EcHufL?a
zsHQYb+fwn-gGQGW)szcUb-pSxE+rS2NtEogr5tv#WE@fIPo|~QU${4IT7*5qk^STR
z>Z*;LSI9YJKI+syG30uDC~IFc!yeyHPZ#ko-@ktUqQJi>@SmqZsLxHl`@n>sj#ujW
z%iS-Oy(G#H%un1;;0yIPIlmX2t)EKai{?w<>&M3yk27&|uFqCbpYMxZJYOuIxW(~>
z+$3HJE6~L!@ybvkc1e7&+4Lv&qxi%g*1GoRvCT7VGef8jGuyVGV?!CaB>qeJByAR5
zI-Vs!Hy^{Eez1Whi_X84L;TnANuF2Pa5YfMQqL#u4SbTHAM%~b2MbJ_e+iWQ-peQH
z!K%{sj{&7jd-%ltRX%Y~fha;B`GhY2++X5xe<oe`aex2ZeEm<weth98lY`?6|NKwo
z@SmT~ahrfWOCPrhxc~Wi`(H@m|9F!q$T90LM?{n!KJI0JE?m8Q^(dQ^_Z=|EFMnm=
zs$aAn7A)(AIt}l~|JHk6zsGHykNLamh_TAD;UnMDzsL6fDE{}}{r25M)jM}vcXL?Q
z>lcpyhF|IsvzSn3y?({(Zgu7B-+O&>FW-#EFYf=doB^D1g9(Ysq2P=jzP$FmgKQgS
z*>IW-Gi;b{!!#SF+R$yo6dO8i*wxR_`F$I<+3-&`+;78|Y}jhU-8O8o;SL)%+whMz
z++@RtZMe~f_uKGx8{TZg1{;RrUtyblHmtB=p$!+<&}+jC8>ZRtbQ`*D=(J&1v?+Ig
zCVWQ^I(ORkmJQo%xZj4YHf*tBvkf=eaDxrk+i;l;3vF0n!wegy*)Y|HZX2f9Fwuri
z8!8)iMVb6}+R(CLn+^Bdu*HTOZMeaP>unf{zs@#S+py4vUK?iE&}~Df4G%|}e0*lZ
zHXClT;RYM_q;U^&|F@$J7nuAUFXI1gccH^K(V}y9-}x^bY}a>+fz?9|TyK}RAm5l7
zHuM^|<OE|5(LwCxS0{_Vf8wuq*?OCMC*9k<xA`CS|Br_MXUE?=KfTSp)Bl(G|0V_g
z-aV3tUcX5D7b<PnK+|6>8;1J(Rdzp4J!tgs{CB~LBrIQOylJz?on^%)AOBT&qy2l^
zj(3F}?>`EqzeqlN_Z!)3%1_ow@>3T^%NF;)@5ip8Ms^OIvm)A{-sS6@;7}IuVm7=B
zPj#pQ;136JR}(+C0ap%I>U8irU<Y3t{@({CCUZ`Xy})x%#0;JV%o_qv8(d(^aQ5ur
z0$<=0|D8Y=GL(rY6BhUZ-(c`g;Ea<9KhB{_fS>afVBZBib0oZH@C@K`KJl{xIKpjk
zH}I@caK?F!GXvPlCus@1X|yR9x}p?%pLAG(Kj9NUw*$Yj?GFPdj4^&T0q;3QsTHJq
zFYqJ2dnG@>q2rJh10N2Y14CgG_*~#ue68SzfkRG1h2>cM052F1&Bs6!;6r>;mWP40
zr<*+ZfTz(QQt@*-uz@cdT;R_qaZa9!&MDvrX~;Ta-w7OWhKWBBxQ%ZGes%!QWf@+F
zpDf^4d{U=}fk&p0XY5rv=Vg3C!wTTLe4W@^z>8qm90o4{?m7#e3;AyWzRoAK`V;V!
z4DyD($V`kqhj;`BMo%Yi;7;I`=TZjn#lSy&N2%X}KMZ__PvWtF^Rs9J)Yk&wwR}RW
zW?&ni_z}qU1dR)v$tQU(1UB&P$NzfZ{d{fU8-f49_qN0X+{$Nx?*RVjJmfUMZwKz>
zI}F|m+>sA&>=gU}hhAjT8V-DvPiV3Un0>LKt-$nI)Div#e#qwq?*!J(CN0V$@bkIw
zt+4L`zH$jqK7*s5Oq4X~vZO6g>NhaBq+WgtjJ(X0D+;)rZxjC40w3fPI&1`%vK8Bp
z{bJzze3CbTi3?3wfio_LF9m(Fflu=Zty+M0UBUhld;{<`KC%B3@Dm%4zmmSsC-w!v
zdcL{f4ZtV(B&}v(RiVMFfx#m7t@z2fN~tUOB<#(=_7dbdz~2W>;#@-Vp8>p@PyEP9
z#<`1?dKf$l_#|H|cr$QDxxur6&)E2G;N0&)Tl@$-!l!8GTohN!`GkfmfGvCyzrcqp
z@PeOaU^a}y#oz*;<C8w}Ht^X>@&>*em{?`XCGa4h^tCQv)-~jZ_yu0UC+)KkxSdbZ
z64{l%@JSip26}2ZlOb#!a1UQ6cq{O7AEMyk)xgXAq(__!fxo-f<bNaZ#g&YK*uMn)
z=my4H@J`?fH=6iUfWP3A@@@cr%vS;a8F0fozSFS>o)s{DGJq%EOuNKS3h-h+$#Vhl
zmwXcTUf{V+hPGM2J8n09;ZER=pVDXXBXGeTCJ#Q~)Sn@5jr}y>HFp~N_<&#V32hGp
zH{E6EDe(HA6F>e}0RO-zd3YH3IiJuCJ$)+i7X}yDw!y?BF!63a`jo%}_n5J<4fx8v
z45irb2k!or8S@23-DlDjIL*cde#Dn2eG}&HR=x$`JAf6x=j<0;;JF)Vx8Pa88a}D(
z4Zt9u<Wv0z_(QZU{HQ-bXFll{1;D2th7Q=b0+Syx<3I}VN*k{RraX#&{0Mw&lTx37
zzYV-@GyLrF&<FVX7U~`RPr%C_r`>~B1Mhv3HViKCmTlx4{5GK4Zsrkzu{(@?Ja7r0
z(76tn_B3V0e-<!iC+z{;4SbnzE%<)mS9~{v9|jKDWy+feyx|$z0QTrqR4?*LoG$_Y
z{4DJp`!?VqK3$JM^*rMb?NHzvKJmX6IDe197XWXU4|)o`dar4#6~Iqy{4?NOnC+>=
zBXG)o!h)v*<6fgI;PJrOd=md$U^}0T5AOpXf7|qhKLTgHW9n!w@a%VK(}c|c2KXfG
z&A_RDGwp2}@Lj%6{8+$+mdU3;M>}O>&2u_1y#tzp3+#HI^#r)U_zz5*5%>_Fj2jOF
zt3HP2_^AeV@X6W<fe&^2r+nZ7%RZxBfiDLBgiq54IPM_wn%JiUeSBgs@If2j2<(4|
zwD1!TT*W8jPXq8NzWvxY1K;A4uyP+o?t!ewk3hN8azAZY;6=8*K)FjHegw*$2k|3N
zWW&W?pvd?OE>L9f1s5oC^MVUZ_`={KZ!hxhVlPl+#swF++{Q(2T;#jOUZBW>3NG+P
z8y7yJ$OMbMK#_Zuya^PUR<Rc-vY&zr6gf`81&WNO-~#v9xX5XKXyerK|2MxVUD8Mu
z2~4Gl4ggjIQ-EuM0R1!mV)Q;`1NITvZURcUR-m}kMe3q~c&h6MNCCzG5x%Yi=%0zl
zp>Ilh`>>~Vs=_|(CGawFw11&^#JKi2_O~C${{G|GYaQ`@#NTop|ND<)Z}nj>eAq7R
zop&>?K)kn20aWL`teLS7nN#j_sQaDW=H}ng{~&6}J@sMS$99`rU&EZ(ZC>^s{)s!}
zzwJZJlqqEPe&j%AsoR{2o0~6-56NNv9{)FS;zV`+`RA+o^XIGb@^a<(`&FHIudCyK
zox1(@+tsgs{cE*(^JdlD+^k-G^;LD`$Pp#mSMjAiW9Sr9y!yfJI_|ygTDp{>9^>BN
zM~Ca;4=-K1Vug74D7gFZ-r(*-IPb#j#DK2zAm*h@#cb_G>9;mx8&ppId=xxfrrnpW
z=ybkM;NVW%ymYU#OTw3x5x@Ly6#u*TmX+-#eQnn9mzD9*K@dMTO8kd$mmhw#e+e(Y
zibI$Wlm6bF+Dsx6{{cx~{|=EpZ#(QIf5cW+Ciy$O_lpCV4vGhz|J8@r?LNHwpu{2O
zBeNIg;^A-w@nequ<1>R#y>s_oiclu>aqfR`)gU1NKZaE0{Cdsgq`cjG@o_WWiT^iu
zoRMKXXmi)|d+#0n+uho)xD)Pu&$M6{!Q-|6y}S3^Gk15_;k|XuVun7!ujf70byz!#
zf9TtOXID@=Yx+wRmT?yUTIu?J<E-P?d6UQ`zP0wRSsT^ik<B-@Mb>?%4&lHaUnIDL
zPdAO@Kyep;J;O;neSJ4#AFNXjzDT|pJ{RA}ptSQuJ~!XrYv<|d>FB>j<LI0@>bmQ$
z(|HTE@%8K1s|Ox<Kt25M!@7;X^2#gfop;^|xASTd57@{Uy793XY3bKjUmtw5>?w8Q
zQy)E5c6F7ykt!;CDj2-+sg5gY30L3v;pbOA3UcGm-{D2jugX?F^Ul0^^PVcpOaFJ^
zl~-SI&BejsBUc7*XdL&{cjsNHZVcY@)Fbo$UwdZ)US*N&{YFI=l|^(2xa1JFK!kvZ
ztRV>rO9D}F?l7o$W5CFwYzZKYvMJ-rAenI#MT8_SNCJWjq9~gi>Q&iPT!V^=D1r)z
zYu*2^bKY=>0VB@$J>T~{_LEMZcd72G>Z<DMs`tEy{+^gc|5MF&ef#ZF=cV{+`D)S8
zR;OCDxnsjsw2O5W*We!Rr`9gz6Ff@te3BtLLTTExsf&w?)B6?LxP*iRmz=Eky{4sk
z-u3U_-whZrz+HIZh3=9|E^$*X>*<CL9qLAm7~w{a9O-g$^d3>!kI9oKyZrHquIO(G
z?vW{7+;u~HxS3a^xZ6f2ySX_@ZsqjOZt=7<ch~g6?(sQe-1E2gaT^M+aIve*owd$f
z+vm+CK5MT1OXj-1YHrXg=2EsOT=urP{w3yeRsZs#xr;wFH)NZ+!C#o0K7G2o>86`p
zUS6KN<BmJrop;{p?!NnOw_w2nci(;Y`T1SCbg6snvB$hEd+MpD+~#MNx@*5O_t+kD
z&pr2?d-25=-7BxW;x=yF=(cRx;@*DyZTH@L@44L{Z*`l$Huu2?A9%U=?6c3@-rYOh
zN8g#-vuBU{_S<j0tiaY|;<Z=lr)O{^G}ULzcV8;uk+Rp?BRRE`U4pfB7h8Wf$;P@l
zmggR`Wp0aY4D6{pMes5Gw7!mUE@8HO*`<13M({)TXsxum?q<Q?E%+sZUnBTUg5Mqi
z-%RjH{j|pzBfoOCbF-Ez9wGR3d-Ppl!EY7(`-1;S@Sh2Ox8V0jz{fXJTrOF%ezE+i
zaf&I;QcUGR`Oeyh*rvM9wzhTlUVmrW6x+@`XM2`8+rP04|M*h`A0zlSg6}5y48g0f
zJ;Mb*sjjn|+d7-q-`PWBovqDNpUa$myzwBsoR5CT3I2G&*ARS7!OQ;akrQK~lbv;I
z>ugYeXMY>(?2bHV%a=LZvhg6itEKl|)R({0$j#Qf?3U{7qOVEv_vqccR`()jZO1t4
zf4wtpa4qj)XUo<*+gK6-9}@hzg6}K%!GfPC_*sI#SMZMrewE-~5WL3Bdspxu3w}=-
z{8@S{L?87qTs_>N9_~{Q&#H$H)We>-=Du!gZf}2c`^TF5HqYF5%gp_-(aPXY6MQSd
zCkp-o!4DDq1i{}Z_&e*Ge%ry^qy5dT8*A>hJag|ZGxzz%gYeY_4+l;a{Aq%3B=}~6
zKTGi4>Y5wa*4)_s=4OsnUwP(MFEjV{#)I&Onug5M5_vKurF(Ms<WzsEZ_C)GO=4o2
z^(wm|xqEtAT54)~N@8MiYG$k0=FOWn>D8-oX84BGG+owTnm(kaX2!MPhF-lw;p^!c
zDLv8?)qRhY<izgDnP+iB)21<v!q?L>l9JPtQ&Lj|4`!{;ii_(O#*tgnGtz_7^R%e?
znXPpLJv51F6lyFa)961vJuNXk^Ne~8qI6w1#D;HZmMQqeWI9Mm&pfSOy#}S%J&sLc
zLP9dFtpChYPpMb0PlE3t&QsY)*M)y7@X6`AeoDPF`h;=o+Y%H6pP87Pab9|QkMzuj
zbkHEGe*Hh4c;bnt_XS6;^V0SVjgr~$kQ*{#1J_e}WTd61XY|O3KI8^nZ{E`P-#sHW
zy+=lBM$a=Fo*EuPBV@LSZPi!w(|?K|BH&tP*C?UDk@)BPZ`&n9EY9eWp5ck`I0pO|
z{+X$5lRzOoBO|k6&z|+_)e{kA*E7#OJ~Ju4hlV&$*U#+P(^GkR+4Yp#Rcm*w)uu;!
zYKFMnGul&mM$fQ#Bz8_tKKt0(Rof(HW@Kih^~fm2QYNIdq@|qGJth9QDmBjwUw~I>
zsWMmL>zSS6>(n^DN|n03g&`<rq$f&{4qi|0(7sK(8pl>YIZYQ+x=WVNIVUCM;PuSR
z?#btOsa37&xf&rQlit%(500Oig4~_o<)mY(C2>6^QR12&fQx_dM*@~~Lfu;DXQpH%
zc9E==UDoxW^sZC4Q%17*m=<vv{-^pobiPBolrB=0$jiQe&2M_D1Tn2g`_APqNA$0W
zPD}25D75tB(2{XT=d!Q1X6k|3(-ODIxmcq*t+f6ge{QP!C||82Uv8R9Ea%T1*-r`l
zxeG41!22UpvU`>J9uG|H=58F`!_CP_agScx!!5mQitDgmK85UD?>Eg2kne!cFj4L8
zx8LsO&YkP#&70@)^Yh)k_ulJ$g-0HF#QTF!KKZ1>S9pER18%PTjivGxo_+RN_v)*!
zdf#CChb8XA4?lF<w{Lf!fBw1q;)^fb*I(`SzQMkI``k}I{p9k#HMdN@!p0vW>}-4^
zEp#2U&`B?6579z5NekVrTIlX~b?s5t)>gUxw%(1k%`VU0b<6Byt=|XN85gewv0s$n
zwb;%+OYr9kK1uNDg1=bsV+DVM;O7bcVZpyB_>!`9<_|wb?EAw{`Tx>SY3NEz!-fr|
zM2c%S;D5uYrt$IdE%_8`*f6SLqn6QiYSlVZ{&0hs*rrXJH;u1br*?~zblk8}<L1qE
zZ{0f4@p18S?(~?JvGHfrjIXO3YMpe_nWr~u8XJE?&Db-;CqkjvmhsiApBO8c7AMy_
zsbN(8mhmT4uU@l8)v719s9n3^amP1odBzFVYjPsKPV}kOs#J^7z47s9)Tm1Te~LP$
zo{mmvT(d@vIPC)(H9hUv({)uKXXset$DMvk^Tu)U@o~+Czs7GF7uO^%u2Gz)?{pQO
z1a8#GAG)cvl>@1!8|5qeT19O|h4aBZ+%Gs6?PG#Y?zy{EwTcVr|L-ct2wEPy|Js4P
zcHdT2%gFyX%HgO#(%9g8g6gT!(b0|6Qk$qYt5Ktdc0f*+0Zz$<R_admB-Mc9`uHCy
z@P~f2yQx%xw{=tz|IqyT^Z%-KXXWnQyFdBz%P&9G+VkPAUAsP3Te5fW-rd@lZh!aP
zcbC2J!V9<PIiI+$UAs#1Jxy9Pd_US<`FZ;-{9~?Jm``rjtXX5V@QUzqWlGe=7hjxs
zu8M9xO>x9qwU4&dt5@5npMGjuPfc+b0#sH~QexVF8`njHX%GJ1jvYHb6RjU?+O+AO
zwQJW-?cTk6JN3gnovvD6wXQ0-Ft0VkmCx{)YkyKbL$$tQ73~fjIH1gcwndf4zk&Gu
znso3S`smQ1Lo@IbULOCKUV6zCBQ@b?D^{%Vcq@ivpM3I(ZP>8E6jSi`0V5xQ^V<b8
zf7!BSlOKQl@yT-gdR%wib?1*6GbVM`tXci!SA$y%)wufg>$g*E<D#?AJ{#UerKYCF
z(yu=MCj7to<{OhQlh?R$<M!g=terb|nqs<Te17e<*X*sg-tu^Aemw5X&9-gZ?45Vs
z@yE~<RQWvqvt(}XS6_W~Kyvqk`rPsT_ut#sUw{40>#x85#77@}RHCuI14eZIOZwJc
zILrd}x8g5<$~0D41^=MJ*Pt>dK?Q$!MH_tPm>SSQ3qC;=&K6Y7xdk;i7qmx%|1-}#
zGgI>zBbk^1E$h~;^E4nIiZ>Z^pg5D47jQ%;q{F`5ym_-x(GBK<7X3hXfO+}lmpu*4
zq4eLF2gT|M;g%I0|Df|fa$P!nwrHrV{x;aZf4^xN^77xYW5;I5F_k$`+{{+4Txptf
zlh5pRm^olh6j$>V+}E#PZ|KU_ty}$PXut*_Z|Dhg1a8aq`=Qxyn<c(#cFv1t@z0sX
ztu<@C#_WQZ%ocrYwr~Ib&C(V0zcR(+ziQR0ye3VWw3iP*OZL(<AD#wm4s!rsp@+Eu
zcRn-!@4x@PuY88*@Ed%Q1!w_p_>YVhd|{UQhFQ`kvn~q3cTmot-FngRtXWIZ(Clfm
zm?zC<y{p{7k33aTsp9dMt+$|pe^7(D2->636Z8Oi`Rn^;y|(JR9IuQ2(4aXu_hqxQ
zMZ>5!mGAgb@oxP_bemOPtQ1+SRB50%DY87XUAuNMl7$)2p?UE11a#2COXLXtS40PV
zhv&=@a)bP1ceQ8p2%Rtd`@B<1Lw9|DvYT-2EE*I~wlSg${D*HgYw}d7T2u;qxsh5k
zEU^E`zt$t82J=A+{(+n$|I7z+g=_@0pyS9Ha*u8VEqX!uvwp?<JkgLY`R^%yLqmdo
zqPx>8r8KmWE+|fJv8(;<*wM-qkH2hjo?`s%H4n4UGi*ymbRh4Ma}vlEE&S&?>jJRY
znaDC=yL1#9-ZM)R4LwA|(p`~v9QN~9x^mZHh-vWMci)-TnL{cx1T~<eqB#j@iKOF)
zAAYcnPt3FXu1UAM#wObBqmw*h7ky&(mygW)Z!^n)hPT4{ESc#V=rcA+`ixC#COtr(
zTS=bK>7SKntAGZNzvg?UViz&8>ocGQdq^A5K#SZX*X8L5<O^9xmP-ETQG4L3u2wic
z!S2cJ=4pU{OFlEZFib<g60^R-skdk-(`RT1>vL;tl5A>I*`!9IA$morZB;kZ%hBNR
zkBNyXv;SJ-S?7N-ALuXZK`<Za1IK}$fWPdXt-0eeE1J~R?!PL*3Pi&^(Ll+P{Tw73
z2Fk|&*N0}%5a=^B1p16kYWsrt{)|}*Xb}HHPnexAJEih!Mfl6!d-<2H&B7l-=K?wc
zT9^aYgUC4vXrTpv?Brw9lWob>U2KtPxKA|Xk1NGLcemN4pNobaW`7k8=rcAcT{bDu
zXJ`oY85#n8#wNwC^!V$^o<m9l^o;dIepXq9hM<<GBhZydI`|9?l*gxbvWKtfY)k&u
z#U7j}8YU#zzCAnbO{p_9WQqpm*zB(n`ixCNpOd8v*rblKNvzL-O=`Z{tZ^y+<?WKk
zU;h2f_U+rp$VZt09oR)$WCl9$d1#@9bF8(2U&b}oTYLt}lhZoc@+qBcnP^xn8WxI%
zr|ukWdv{BCDp5WYog+0T9a*16L*QdHUsVcx2=`_Gu@`~-ckbM|8FLX-^cB3p4cr4-
zu>IJ3_BGf|)+*LE%BpKS+7qJTu_>Kx=`~%fSTvN^=YPv4<&8|XnOAhT8;7UZbwg8Z
z>Sd{R%lM1z{WmulG(`FsUY})?C>7x^d++66_{;)#@S+7L@J1itb1)~^_(=a4e+U|p
z|7ULOW>1TT6{6wM$)Z8JfIdS5`ixDwQ+5>^W<$e>?smg4(QtXHO}VUxrvW_iF<74i
zAEUk2H<e$=KQ@Ck7(ar#aN$BLDk?Jk(x3+OL3<=UQC!wG+>>Q%uj^n>O&1N)g-1lg
zLt%Z!CgqRsX7h5o*_<(ncH5{VyY<RsyG1lyFB+~D4U<I!rM!>v-_i}0U)Ue;mn?Ys
zmt4<)mg}#--inKhJv{*pw1=YunvgAEcWivb*3IZ(Yed6J(ctx2G+>hgeO@4&bazgo
z-7zM~{v{e_iH4g+!`~%G)3Z}OqS&P52p{7S>AlJ?>_7Mi^53OPmuBDqo_Z>zj0WZ<
zl8z(M^3zX0+6Qazvgc-|*y`&#+RCs#W0L}XzE?I08s>&+_^0G())mQi)9_LnK-Bvf
z^0)h{&Xc|R+3e+Vvd>`y=3MJ<o}Ob!A2n*!OW=w=q61T=Oz|{C%2#<>%FhYM*aURp
z*UFpEE-CXd(C2@I^|>6}5&a+VXYPCV?#(>dgAYFFeJ^|(#RqJ{gb8Id9Epx2%?bEm
zlODw;{hB_D21*6IuIN+)_@rlT*2;ET^XAPhGc(ilY=+_2<>uzvxN+lb=FFL1uNCs~
zb_ZXmB3j@*YXi0lUkHDc{Qw1he(nD8_T%^3Zxl}O>vN=!ac5YcXG<3-6(Jj(Q>>!4
zeEt8@vB$qvt5)ag(VkKIiS5tjNBemwC@8S=&p+SvY?1xrAOA4rl<c<KZu9uCzlYz@
zz*@jMfm~79!$1S}6ggxqgh$Wbl4_eC0RR2=(!CQ7`WVs$d<^s%n{?O24AB48{g+~Y
zHz^f59r=;0=V{;HUeCc4ONUL@Ouu<&(h1|ZPoF;C@6q!x-hP5RxH3o35LC{=Z)A^s
z4!#|8fj*$qUY|7&tj~cyW0NBF`F|dtj~_TU;PsK(PMtd4re}J59E7pMx@>wz(ezA`
zDW+vDTC_0v)*ct|z+Z~2&=Ays4qE!7B2z)%*w$C(4YsHLo}~4;)W=|bE}EQTkN<0^
zz4P*N+rMw$X3ck{;}3e4(q_z<@r|BQvTLuscHc!8U1V2Yd8OyO_LW|ipaH!g?gMVn
zQJxlJ5Uj(<Jw6h;LOf!%_LH2$M`E3TmI{hk@ZI~&*Kdvg(3f;~fnt;;S6_Yg&)})&
zMtw!60~%VkY-xIS&CdgC1~QND6VL&^;E&8hCwl{0^Z^|~AA&idMF#Org0+XeH~VMF
z%WsN*qFcznWGP?Ii)}$ql@YgVuDQm~12kY)6<fA}0|)x^%mFk66&iwlFMCRSY~&t1
zX^|ml3*?LQ_*D4ZvL*ji?CD%RXLu`nh@-(Dxu+sa#G9cB+=w~r**mYlDJdzIl$2z8
zI>pZe*MSLWpbg|In3F(H&<}7ATI7g519F8Q$lL|-4dG9^?L^he6mLI8_e`Y#V#LE4
z==0N0KkaFNKg12CAD)J+tSsx>x38Bi<>Wp7@EV>&3wWak*dNZbM?ik?wO30I&;fLU
zezC#A{b%(vBPuE?N%LNyxYG_HP0okBPGySs9|9S~{|WdCJ|!h39v{uE$+zICVy_RH
zZ<D-v8DNcq&)iSt7#gsn@D%(1@WT(=k|j(08u-vd4|zCZ1me>U*|tlxMqVS_*Xi61
zLYllsW%D-;z!(1q`!9W*#WDIu3ogt%c0qFLeF^1Byls`P`}GZ5gM1@%;Ex`lm&^%r
z!W<CK;(Ac{Oux(#^TB#9dhZk7*iG_;l`S6sKu&2RWf&TQ3U1Ja4514*+;D@*W*O^r
zWC6FJ0)w5w7EzEN_C!>0hpzea=M!UGps&UMR@|Y{;~)6{;`a<_2<&1&OF#oH{KhtE
z?e_ZwWQw&mlE2`}G59k#fe%4m2f0U<;5j-Zn=wat91ZSe_(#e=HX?F9Dw-4MBE~*w
z&>+)uxn8~lo=3Lahb$rMoM#OH_aHx_J(9k0c+|Li{23$I|7z`-g<P@*K?gbrpRga;
zI@Y7eIf1v!moK-w?z+p%GyD!JbR#?H4t^8I$PE3l7RY8kpjRgxE#JYN;^PmI>mv9E
z6&iwiq&a~mJrnKMD`X59XaiqlYqe}Av;?@zKfV7b<-HW^ga3W}NBZUWzgoX%Knwh*
z4d|c^=%9tC*cWtx%G_{{dBAp}r_33)h+G0WC}@H28sli}%t4F~{p9fv<X^r*Gx$V3
z(wyMm<NrVxc{wVwMf?2o&wINI571ZS9sJP)$>Y5m{`bmEBn1uNXAu9CohXa{Km%(h
z{tNaGIbc0v?S#kdIpIC?fG-ft1IO5WY%O+7dkUY|5Y7K-+@ZtEf23@bm-FB_(A&rs
zS?8F0m<wbcK0_n2E;;&HKEe*o73(U`Sp1f?3H*MooU9vo2I2o?WelEu;5m)oU2K{b
zm(^EY^`on1KPO&w)i!-UXHRLXPyYBn*B%@0uS&Spw_h}#%I|E0{(}A^@SaBZI$jfQ
zxBZ@WY8X!|ZL5UaW5aE=a9cavMu*$Pa62{JT4`H_HdgqARFhPX@;R;J1d4x4MV=4q
zD{7{vt11d^`&A<g$7EE>#{<<}g@v)Av=?lnH9tK&JG;O9{Zz&LlXbq0Dn9qAs%3IY
z-|rnTo1k1z?>9<wY{Y`eDV(j`&LG8x-}u_2bR-<0_4KM$t9H=dZme|r0QO8i=RVon
z&$JeNA-nXp{PP0E$wtTrPSyQwRb%9D>>jEd2YE7Lp-GD0lJh2CyyY9S*A$i0_mL=H
z>i)x(Gi1XHHRb{ACpMD(5;#zU97fpZ|5<kR8`<2=vYSuRF*#H6jpVt=uMiU_KlJ)u
zvkjuX61m=J?6l$vS&BUk00(?0_MWVd*mc$-Y&E_tehSz4Ou1OODsrCW+Q{+n`~o>D
z@;l`H$+1xmN4(BQvj@-~bd>fBBUpb~*VyMWE`BsT3DfU=r_vrv|C2AfNU>Y;edNj>
z-4l7W!p|hJBIUu4&wdaefeH>(>^l{nuzv0O_-%XOx&b~fK|Gu?c$e~BJ4^GXe-;kp
zeR&3g*giSmKpx5Wl4tCy_Vq($GMY6-``0Y_xdXr>z=iq82L>0`pOtrx^f7I6&cx({
z@xkH0g#&p{^5<S2g#)=Zay-Z*IVy6U<Owg7j;O2;&q*}vxZ*CO^!>XLtj*K_2Ye2A
zf^WTKN{Y|*k)I)sNMUR$xmWVX<oqJ#k!M-R(U9vS$Amn_J?%mF2jk-h1^GqRRs6KT
ze+zH{g19oVz(U0{$@%KLbT(Z&7KsD$IG~(7>iK=I6Ff_UJeJGTMKiwgDOrju42Z;o
zv5|9H3i&p2B;*UpQ!T$^%&+DQcYbe{Q=*)waNv0!bb_2MC7>U_V$!5Zqoz)sIszY*
z8sI_P1YS^xuaj#c$3d=)JQMj1@?_+g$Ze1#BfoUbkkWelwZjb@ygVxJ8sxs|FLHcr
z02SYc8i@zEF#l_BNHp?Y4+{rkn#9J*u^^A+xyY}OYxFs;@c5H2>&Z}FCjxm)5Fb>^
z<{#fod5A21?{WaPfc-xHIdp>yJfPiFINawA$ybrPC1*(Pd44!wh)$3nAy+s}IjVpM
z3>Iml$=#}y$v?WK@Ai(8{U3oYVt3dVu(yLJ*dF+?cgI`y(!cuoJOS}(<dGacvFSi3
z$TN}aBTqIpj01!9D=E$657OB0e#@CM8x)Oyi43BL`24isL4_Yw@PJRu!;#A7br1QR
zDY?2C!hw8gx$+D9$N0D0a!b}d_uMmp+z|dac))Y^)$FN>n}P?tz#egpLjIQL00Nz;
zNFKQ_ENc}t(fHVkSBz4;Wh8vK_10Ux-NWv({$c--1^9t1GB&tS(1|ZU++w>vd_y`>
zP9CKb$RnkqfdlzxKTe#3m@YhKe<fY?`z>@6oPzm@oEzrixx9Y1XZsf0{m~l-<xx68
z{u+6lJLN)#uW<dBZN=Y?W_;x$K1fW&tGmkQru9w*yZPpu{r(P|u#4ycc)$bZ2i|<M
z<86C2{|bBJx@7+>Kp>9=lX}|2{~lwXZ<lj&P}UA%L$_|-+9}>U2|AR=96fmO;1~4$
zZM))%D|{SS&q(^%MX>jQ=kNpmv%f<Y;0O4ZFZ8MVHc7T3*V;qI=RkR}zew->K9IGZ
zybQS|`B|ptzCGQ+{tG;)@B=)`&kgvoZecsvm#X`7Rq^kRRHE5~%Kz9&E|I*1zGrI0
zU%_GQ*s-4P*aOx<`VM4(v9Jq)u4<k5QF)o6lI2|aNIz>(o_YGUJykTk67OdZ8#e5D
zay-Q7^@V?9F37KGUH0SP55RZEr{a_0qXn(js_(_mtJT+h<tuh+Y_<ZwR=oV7gY<=O
z2fvBsB7?-z$!nk=;2FfOm;>wraNq(ju-n*7@Laum^{pDX)~^k&>t6qrzs=J3=ms!0
zeKODBp!Wor-Ya0|op+wc4IHT4gAQ;Xa)Y0Qz2Lb-#lrK|FMEZ`6mNgAKYEUS1pSpL
zCeNCW%^|m-cNX{@GkO7j6!;Ltc=4CXso=MZhPyRrWyc0TKYk$3@RbT4RK{aH(mN8o
zZQxl|Xh-IlFL({z*kr|C?*ENr`|%k^w#M84itq@0V14Jn^nFJkE5<J*=7c={j<Nmt
z&>O73$P)C@Cl#BA&Y|1TiH!054$ofbdjZ})93|b1O^Js7@_divKXX9E_G0^(XT1{w
z`P-#<*iGt#_{q^0zH3tFC@cE)YxeE1c>Nfy@9b77`@U}UH1R^UimIzb<-PzWS|HR!
zoeSzzeWu#93f{po?HAwM4Y|V=J*!3E6&A^3%KZ8BA61TKziiZ(dM@Oj_uqg2A$CVO
zfZgh2^rA(J{CVATTw!5hn&R237B61x=QCKtm}lAaHzEfkpQh)ZiL?HoKDJ5z_M(UE
zjgi+S+JpRAejU#>CTedrSNlMf$Adn&7n#O~3;dZtr?6$2+BdOhB8IR@Zp}G*u2UuO
zj~)2~#zNPyOH||)SW1?*C+vYAFLlZMx$wVzYL{c1&?9igcR;o`Jaw<-jV|>KhlKZU
z>>t^`vR7cQ(nfowJB1gyR`%rJj{Gz3gHzJHkMoW8U~`2teXtj2??o(veINVIj@ow;
zqsFHKZ|oL@Jq&xONB%w5=p(XxE)z>khd2UzHu%Rpu?FD>QC42x!~0w8KiGS)_rcd?
zzfpYmO-3K=!+Q%4=1=dQ@p*1+7<}0FY`!g@mf-i3`0n`a>>JoSP0sG+$M|!J*+T7W
z^*wK!I(4dlMufZ?bBVkJ{P#EO--fkIz284sd!KND*vH_X)&+03$jR~i0I-3~Et}HK
zc5d73`N<yY@5BB0djt7F_OSKX9p+NsUH3f2Rx_9HuPd;JukGcZ=bksQkG=Hd0}QV>
zOqLdXcg6c^*e~P;yN%Dqd|*!_ap5y-c>qhx{lWahyTI=%(K^ZatViq<=o`DNwSQ_P
zJa!tq=?7luy4NSxY~o44vd?DiRxaicSo)b#tvI=ksyjAZo!Z0I;2!R$*5=+S3S@>t
zb<`f`-?*mtht?@Q;(cq!=o<G__itM}R@X|8c-Pu-dZQ6XA^)bes^L3zq<fAJ-x>06
zS*zx{X65E)j~smEq|n5XSB}a}h#8+Vs&np;Vc8?Ia$AiYJ|t&!?&!<MwHh*dWaq5h
zk*z1RjR}p+8a4d#?A+j2C=+7Zwr&&C?WCHaP}gxe<8%G*xmL2bcBOEF%*`G$UO(eF
z$@ddd>6(*0cDzQ(zN}x)@Co|mz@gc>Wfvna_n0V9exb8(_Jr&!Ls#-YAtoy~ZPbL(
zS7hhJgvJj~9x_BfL75P9dDfM=*)iR^#+UVdC~#T-5qJDz^se!T;Mz65jA(&(jSu+Q
ztzUA#<kZx(^Lh;&82<3b@qdmV$Twf^-B7T#V4Hs7#}!sD>{mFj(ACj<Ky`lof~^a7
zEI6>BdVW-XY<|c5-uVObhviSqzcGJK{=)nf`Rnty=I_WqkYBwZs(?55ZxM`JP-nrk
z2WKyuvuMGhg^QLhTCr%&qV<b5EZVwg+oBzd_AENE$Q4yDs#6qI6e@}>YE#s)D5<D-
zQNN;rMVA&0D;iTYv1nS+jYYGI<`gX`T3EESXhqSQqV+`^inbPQD>_i*imMmbDUK=*
z6~`90DehRDRNT9`U-7`=ON)mUk13v5JgxY~;@QP>iWd|wEM8i?qIga5`r-}6TZ^|9
z?<n3=e4yAZuD-a=;;6-;#j%UqEbh2CX>sqxD;95Ed|+|Zl8#FzE}6Y#&XNU77A{%3
zWX%%M(ogSbS2LzyV!^b68w+L^%qdt<u&`ih!HR-41?vmo+m3=g1qVFm>J&y5h6-Z~
z+Z1*z?Ctq@Y2mQKF@+Ngrxn7OKgu5*_<xH7jT;T=JZOBbew}tu&S?Ec^`KFsb0>`&
za+!Xzd8B^TIeSp<=<zv2vPTcjy=u_7k>iF8($9ZS7?e9CXZV<Lxr4?`8aHh8sMgsN
zvumDIvtOTMk2}Rv*Z#hG{TqET<!8O0+ELl%WM+=c8a_(z-x@Qiai~?xRw4aHvwlvv
zb7=gy%UgBiOwHjV$BfPy7s|;FKIKlzt$BIQ=#in}xw_Dr4npCZ_*`@N<)O^XQTnmq
z%*;?iLa2E#M)S^EL_;Bgx6aBLI^p6rmxL13ZR_0egJW}=$F?d(e~?hQ>Y71d-y*R|
z^Rq(DRU=?ply#D=UoMYj#Ml-sL}ry^PVp~z(63NbK&a<{{!Np2aR}M{!av<nMJBhC
JE`7>%_rHC74U7N)
literal 0
HcmV?d00001
--
GitLab