diff --git a/requirements.txt b/requirements.txt
index fc5619a57fd98d4c23706010869fd7a47e14c787..5548b57661186f36e6c8ae9fc33bc75eb00c17cf 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -1,3 +1,28 @@
-crcmod>=1.7
-pyserial>=3.4
-PyQt5>=5.15.0
\ No newline at end of file
+aiohttp==3.6.2
+astroid==2.4.2
+async-timeout==3.0.1
+attrs==19.3.0
+chardet==3.0.4
+colorama==0.4.3
+cpplint==1.5.4
+crc==0.4.1
+crcmod==1.7
+docopt==0.6.2
+future==0.18.2
+idna==2.10
+iso8601==0.1.12
+isort==5.4.2
+lazy-object-proxy==1.5.1
+mccabe==0.6.1
+multidict==4.7.6
+pylint==2.5.3
+PyQt5==5.15.0
+PyQt5-sip==12.8.0
+pyserial==3.4
+PyYAML==5.3.1
+serial==0.0.97
+six==1.15.0
+toml==0.10.1
+typing-extensions==3.7.4.2
+wrapt==1.11.2
+yarl==1.5.0
diff --git a/venv/Lib/site-packages/isort-5.4.2.dist-info/INSTALLER b/venv/Lib/site-packages/isort-5.4.2.dist-info/INSTALLER
new file mode 100644
index 0000000000000000000000000000000000000000..a1b589e38a32041e49332e5e81c2d363dc418d68
--- /dev/null
+++ b/venv/Lib/site-packages/isort-5.4.2.dist-info/INSTALLER
@@ -0,0 +1 @@
+pip
diff --git a/venv/Lib/site-packages/isort-5.4.2.dist-info/LICENSE b/venv/Lib/site-packages/isort-5.4.2.dist-info/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..b5083a50d8cf8c6a404a0584416618915c58acf2
--- /dev/null
+++ b/venv/Lib/site-packages/isort-5.4.2.dist-info/LICENSE
@@ -0,0 +1,21 @@
+The MIT License (MIT)
+
+Copyright (c) 2013 Timothy Edmund Crosley
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in
+all copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
+THE SOFTWARE.
diff --git a/venv/Lib/site-packages/isort-5.4.2.dist-info/METADATA b/venv/Lib/site-packages/isort-5.4.2.dist-info/METADATA
new file mode 100644
index 0000000000000000000000000000000000000000..4301784b3896a5d392b451283596d9792a0ec203
--- /dev/null
+++ b/venv/Lib/site-packages/isort-5.4.2.dist-info/METADATA
@@ -0,0 +1,694 @@
+Metadata-Version: 2.1
+Name: isort
+Version: 5.4.2
+Summary: A Python utility / library to sort Python imports.
+Home-page: https://timothycrosley.github.io/isort/
+License: MIT
+Keywords: Refactor,Lint,Imports,Sort,Clean
+Author: Timothy Crosley
+Author-email: timothy.crosley@gmail.com
+Requires-Python: >=3.6,<4.0
+Classifier: Development Status :: 6 - Mature
+Classifier: Environment :: Console
+Classifier: Intended Audience :: Developers
+Classifier: License :: OSI Approved :: MIT License
+Classifier: Natural Language :: English
+Classifier: Programming Language :: Python
+Classifier: Programming Language :: Python :: 3
+Classifier: Programming Language :: Python :: 3 :: Only
+Classifier: Programming Language :: Python :: 3.6
+Classifier: Programming Language :: Python :: 3.7
+Classifier: Programming Language :: Python :: 3.8
+Classifier: Programming Language :: Python :: 3.9
+Classifier: Programming Language :: Python :: Implementation :: CPython
+Classifier: Programming Language :: Python :: Implementation :: PyPy
+Classifier: Topic :: Software Development :: Libraries
+Classifier: Topic :: Utilities
+Provides-Extra: colors
+Provides-Extra: pipfile_deprecated_finder
+Provides-Extra: requirements_deprecated_finder
+Requires-Dist: colorama (>=0.4.3,<0.5.0); extra == "colors"
+Requires-Dist: pip-api; extra == "requirements_deprecated_finder"
+Requires-Dist: pipreqs; extra == "pipfile_deprecated_finder" or extra == "requirements_deprecated_finder"
+Requires-Dist: requirementslib; extra == "pipfile_deprecated_finder"
+Requires-Dist: tomlkit (>=0.5.3); extra == "pipfile_deprecated_finder"
+Project-URL: Changelog, https://github.com/timothycrosley/isort/blob/master/CHANGELOG.md
+Project-URL: Documentation, https://timothycrosley.github.io/isort/
+Project-URL: Repository, https://github.com/timothycrosley/isort
+Description-Content-Type: text/markdown
+
+[](https://timothycrosley.github.io/isort/)
+
+------------------------------------------------------------------------
+
+[](https://badge.fury.io/py/isort)
+[](https://github.com/timothycrosley/isort/actions?query=workflow%3ATest)
+[](https://github.com/timothycrosley/isort/actions?query=workflow%3ALint)
+[](https://codecov.io/gh/timothycrosley/isort)
+[](https://codeclimate.com/github/timothycrosley/isort/maintainability)
+[](https://pypi.org/project/isort/)
+[](https://gitter.im/timothycrosley/isort?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
+[](https://pepy.tech/project/isort)
+[](https://github.com/psf/black)
+[](https://timothycrosley.github.io/isort/)
+[](https://deepsource.io/gh/timothycrosley/isort/?ref=repository-badge)
+_________________
+
+[Read Latest Documentation](https://timothycrosley.github.io/isort/) - [Browse GitHub Code Repository](https://github.com/timothycrosley/isort/)
+_________________
+
+isort your imports, so you don't have to.
+
+isort is a Python utility / library to sort imports alphabetically, and
+automatically separated into sections and by type. It provides a command line
+utility, Python library and [plugins for various
+editors](https://github.com/timothycrosley/isort/wiki/isort-Plugins) to
+quickly sort all your imports. It requires Python 3.6+ to run but
+supports formatting Python 2 code too.
+
+[Try isort now from your browser!](https://timothycrosley.github.io/isort/docs/quick_start/0.-try/)
+
+
+
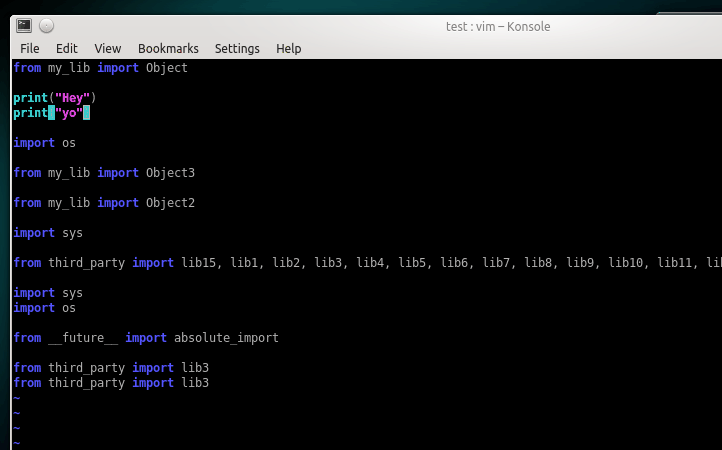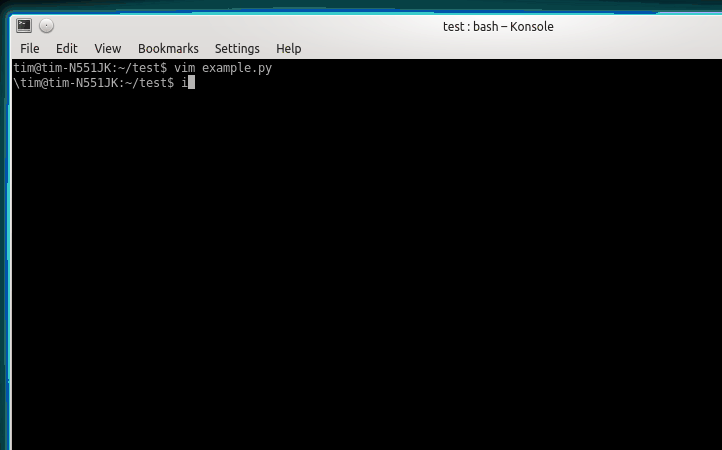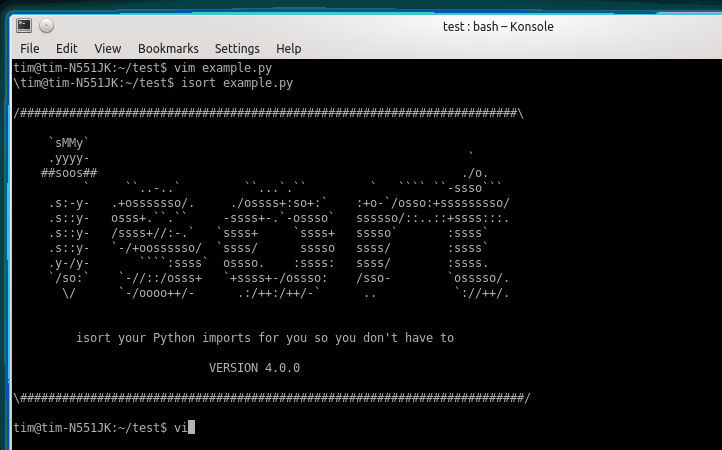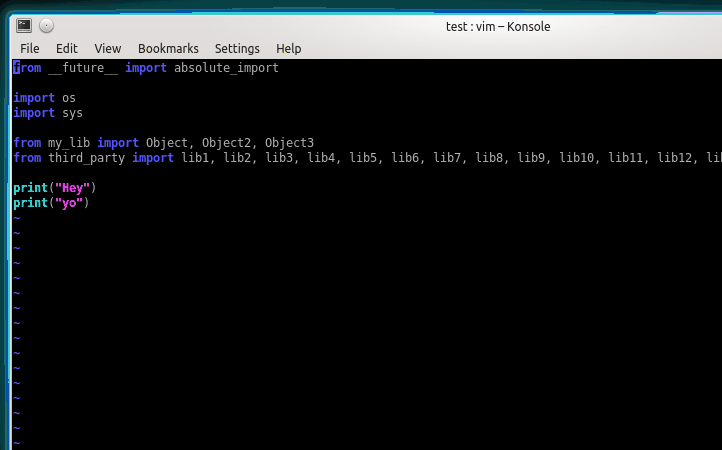
+Before isort:
+
+```python
+from my_lib import Object
+
+import os
+
+from my_lib import Object3
+
+from my_lib import Object2
+
+import sys
+
+from third_party import lib15, lib1, lib2, lib3, lib4, lib5, lib6, lib7, lib8, lib9, lib10, lib11, lib12, lib13, lib14
+
+import sys
+
+from __future__ import absolute_import
+
+from third_party import lib3
+
+print("Hey")
+print("yo")
+```
+
+After isort:
+
+```python
+from __future__ import absolute_import
+
+import os
+import sys
+
+from third_party import (lib1, lib2, lib3, lib4, lib5, lib6, lib7, lib8,
+ lib9, lib10, lib11, lib12, lib13, lib14, lib15)
+
+from my_lib import Object, Object2, Object3
+
+print("Hey")
+print("yo")
+```
+
+## Installing isort
+
+Installing isort is as simple as:
+
+```bash
+pip install isort
+```
+
+Install isort with requirements.txt support:
+
+```bash
+pip install isort[requirements_deprecated_finder]
+```
+
+Install isort with Pipfile support:
+
+```bash
+pip install isort[pipfile_deprecated_finder]
+```
+
+Install isort with both formats support:
+
+```bash
+pip install isort[requirements_deprecated_finder,pipfile_deprecated_finder]
+```
+
+## Using isort
+
+**From the command line**:
+
+```bash
+isort mypythonfile.py mypythonfile2.py
+```
+
+or recursively:
+
+```bash
+isort .
+```
+
+*which is equivalent to:*
+
+```bash
+isort **/*.py
+```
+
+or to see the proposed changes without applying them:
+
+```bash
+isort mypythonfile.py --diff
+```
+
+Finally, to atomically run isort against a project, only applying
+changes if they don't introduce syntax errors do:
+
+```bash
+isort --atomic .
+```
+
+(Note: this is disabled by default as it keeps isort from being able to
+run against code written using a different version of Python)
+
+**From within Python**:
+
+```bash
+import isort
+
+isort.file("pythonfile.py")
+```
+
+or:
+
+```bash
+import isort
+
+sorted_code = isort.code("import b\nimport a\n")
+```
+
+## Installing isort's for your preferred text editor
+
+Several plugins have been written that enable to use isort from within a
+variety of text-editors. You can find a full list of them [on the isort
+wiki](https://github.com/timothycrosley/isort/wiki/isort-Plugins).
+Additionally, I will enthusiastically accept pull requests that include
+plugins for other text editors and add documentation for them as I am
+notified.
+
+## Multi line output modes
+
+You will notice above the \"multi\_line\_output\" setting. This setting
+defines how from imports wrap when they extend past the line\_length
+limit and has 6 possible settings:
+
+**0 - Grid**
+
+```python
+from third_party import (lib1, lib2, lib3,
+ lib4, lib5, ...)
+```
+
+**1 - Vertical**
+
+```python
+from third_party import (lib1,
+ lib2,
+ lib3
+ lib4,
+ lib5,
+ ...)
+```
+
+**2 - Hanging Indent**
+
+```python
+from third_party import \
+ lib1, lib2, lib3, \
+ lib4, lib5, lib6
+```
+
+**3 - Vertical Hanging Indent**
+
+```python
+from third_party import (
+ lib1,
+ lib2,
+ lib3,
+ lib4,
+)
+```
+
+**4 - Hanging Grid**
+
+```python
+from third_party import (
+ lib1, lib2, lib3, lib4,
+ lib5, ...)
+```
+
+**5 - Hanging Grid Grouped**
+
+```python
+from third_party import (
+ lib1, lib2, lib3, lib4,
+ lib5, ...
+)
+```
+
+**6 - Hanging Grid Grouped, No Trailing Comma**
+
+In Mode 5 isort leaves a single extra space to maintain consistency of
+output when a comma is added at the end. Mode 6 is the same - except
+that no extra space is maintained leading to the possibility of lines
+one character longer. You can enforce a trailing comma by using this in
+conjunction with `-tc` or `include_trailing_comma: True`.
+
+```python
+from third_party import (
+ lib1, lib2, lib3, lib4,
+ lib5
+)
+```
+
+**7 - NOQA**
+
+```python
+from third_party import lib1, lib2, lib3, ... # NOQA
+```
+
+Alternatively, you can set `force_single_line` to `True` (`-sl` on the
+command line) and every import will appear on its own line:
+
+```python
+from third_party import lib1
+from third_party import lib2
+from third_party import lib3
+...
+```
+
+**8 - Vertical Hanging Indent Bracket**
+
+Same as Mode 3 - _Vertical Hanging Indent_ but the closing parentheses
+on the last line is indented.
+
+```python
+from third_party import (
+ lib1,
+ lib2,
+ lib3,
+ lib4,
+ )
+```
+
+**9 - Vertical Prefix From Module Import**
+
+Starts a new line with the same `from MODULE import ` prefix when lines are longer than the line length limit.
+
+```python
+from third_party import lib1, lib2, lib3
+from third_party import lib4, lib5, lib6
+```
+
+**10 - Hanging Indent With Parentheses**
+
+Same as Mode 2 - _Hanging Indent_ but uses parentheses instead of backslash
+for wrapping long lines.
+
+```python
+from third_party import (
+ lib1, lib2, lib3,
+ lib4, lib5, lib6)
+```
+
+Note: to change the how constant indents appear - simply change the
+indent property with the following accepted formats:
+
+- Number of spaces you would like. For example: 4 would cause standard
+ 4 space indentation.
+- Tab
+- A verbatim string with quotes around it.
+
+For example:
+
+```python
+" "
+```
+
+is equivalent to 4.
+
+For the import styles that use parentheses, you can control whether or
+not to include a trailing comma after the last import with the
+`include_trailing_comma` option (defaults to `False`).
+
+## Intelligently Balanced Multi-line Imports
+
+As of isort 3.1.0 support for balanced multi-line imports has been
+added. With this enabled isort will dynamically change the import length
+to the one that produces the most balanced grid, while staying below the
+maximum import length defined.
+
+Example:
+
+```python
+from __future__ import (absolute_import, division,
+ print_function, unicode_literals)
+```
+
+Will be produced instead of:
+
+```python
+from __future__ import (absolute_import, division, print_function,
+ unicode_literals)
+```
+
+To enable this set `balanced_wrapping` to `True` in your config or pass
+the `-e` option into the command line utility.
+
+## Custom Sections and Ordering
+
+You can change the section order with `sections` option from the default
+of:
+
+```ini
+FUTURE,STDLIB,THIRDPARTY,FIRSTPARTY,LOCALFOLDER
+```
+
+to your preference:
+
+```ini
+sections=FUTURE,STDLIB,FIRSTPARTY,THIRDPARTY,LOCALFOLDER
+```
+
+You also can define your own sections and their order.
+
+Example:
+
+```ini
+known_django=django
+known_pandas=pandas,numpy
+sections=FUTURE,STDLIB,DJANGO,THIRDPARTY,PANDAS,FIRSTPARTY,LOCALFOLDER
+```
+
+would create two new sections with the specified known modules.
+
+The `no_lines_before` option will prevent the listed sections from being
+split from the previous section by an empty line.
+
+Example:
+
+```ini
+sections=FUTURE,STDLIB,THIRDPARTY,FIRSTPARTY,LOCALFOLDER
+no_lines_before=LOCALFOLDER
+```
+
+would produce a section with both FIRSTPARTY and LOCALFOLDER modules
+combined.
+
+**IMPORTANT NOTE**: It is very important to know when setting `known` sections that the naming
+does not directly map for historical reasons. For custom settings, the only difference is
+capitalization (`known_custom=custom` VS `sections=CUSTOM,...`) for all others reference the
+following mapping:
+
+ - `known_standard_library` : `STANDARD_LIBRARY`
+ - `extra_standard_library` : `STANDARD_LIBRARY` # Like known standard library but appends instead of replacing
+ - `known_future_library` : `FUTURE`
+ - `known_first_party`: `FIRSTPARTY`
+ - `known_third_party`: `THIRDPARTY`
+ - `known_local_folder`: `LOCALFOLDER`
+
+This will likely be changed in isort 6.0.0+ in a backwards compatible way.
+
+## Auto-comment import sections
+
+Some projects prefer to have import sections uniquely titled to aid in
+identifying the sections quickly when visually scanning. isort can
+automate this as well. To do this simply set the
+`import_heading_{section_name}` setting for each section you wish to
+have auto commented - to the desired comment.
+
+For Example:
+
+```ini
+import_heading_stdlib=Standard Library
+import_heading_firstparty=My Stuff
+```
+
+Would lead to output looking like the following:
+
+```python
+# Standard Library
+import os
+import sys
+
+import django.settings
+
+# My Stuff
+import myproject.test
+```
+
+## Ordering by import length
+
+isort also makes it easy to sort your imports by length, simply by
+setting the `length_sort` option to `True`. This will result in the
+following output style:
+
+```python
+from evn.util import (
+ Pool,
+ Dict,
+ Options,
+ Constant,
+ DecayDict,
+ UnexpectedCodePath,
+)
+```
+
+It is also possible to opt-in to sorting imports by length for only
+specific sections by using `length_sort_` followed by the section name
+as a configuration item, e.g.:
+
+ length_sort_stdlib=1
+
+## Controlling how isort sections `from` imports
+
+By default isort places straight (`import y`) imports above from imports (`from x import y`):
+
+```python
+import b
+from a import a # This will always appear below because it is a from import.
+```
+
+However, if you prefer to keep strict alphabetical sorting you can set [force sort within sections](https://timothycrosley.github.io/isort/docs/configuration/options/#force-sort-within-sections) to true. Resulting in:
+
+
+```python
+from a import a # This will now appear at top because a appears in the alphabet before b
+import b
+```
+
+You can even tell isort to always place from imports on top, instead of the default of placing them on bottom, using [from first](https://timothycrosley.github.io/isort/docs/configuration/options/#from-first).
+
+```python
+from b import b # If from first is set to True, all from imports will be placed before non-from imports.
+import a
+```
+
+## Skip processing of imports (outside of configuration)
+
+To make isort ignore a single import simply add a comment at the end of
+the import line containing the text `isort:skip`:
+
+```python
+import module # isort:skip
+```
+
+or:
+
+```python
+from xyz import (abc, # isort:skip
+ yo,
+ hey)
+```
+
+To make isort skip an entire file simply add `isort:skip_file` to the
+module's doc string:
+
+```python
+""" my_module.py
+ Best module ever
+
+ isort:skip_file
+"""
+
+import b
+import a
+```
+
+## Adding an import to multiple files
+
+isort makes it easy to add an import statement across multiple files,
+while being assured it's correctly placed.
+
+To add an import to all files:
+
+```bash
+isort -a "from __future__ import print_function" *.py
+```
+
+To add an import only to files that already have imports:
+
+```bash
+isort -a "from __future__ import print_function" --append-only *.py
+```
+
+
+## Removing an import from multiple files
+
+isort also makes it easy to remove an import from multiple files,
+without having to be concerned with how it was originally formatted.
+
+From the command line:
+
+```bash
+isort --rm "os.system" *.py
+```
+
+## Using isort to verify code
+
+The `--check-only` option
+-------------------------
+
+isort can also be used to used to verify that code is correctly
+formatted by running it with `-c`. Any files that contain incorrectly
+sorted and/or formatted imports will be outputted to `stderr`.
+
+```bash
+isort **/*.py -c -v
+
+SUCCESS: /home/timothy/Projects/Open_Source/isort/isort_kate_plugin.py Everything Looks Good!
+ERROR: /home/timothy/Projects/Open_Source/isort/isort/isort.py Imports are incorrectly sorted.
+```
+
+One great place this can be used is with a pre-commit git hook, such as
+this one by \@acdha:
+
+<https://gist.github.com/acdha/8717683>
+
+This can help to ensure a certain level of code quality throughout a
+project.
+
+Git hook
+--------
+
+isort provides a hook function that can be integrated into your Git
+pre-commit script to check Python code before committing.
+
+To cause the commit to fail if there are isort errors (strict mode),
+include the following in `.git/hooks/pre-commit`:
+
+```python
+#!/usr/bin/env python
+import sys
+from isort.hooks import git_hook
+
+sys.exit(git_hook(strict=True, modify=True, lazy=True))
+```
+
+If you just want to display warnings, but allow the commit to happen
+anyway, call `git_hook` without the strict parameter. If you want to
+display warnings, but not also fix the code, call `git_hook` without the
+modify parameter.
+The `lazy` argument is to support users who are "lazy" to add files
+individually to the index and tend to use `git commit -a` instead.
+Set it to `True` to ensure all tracked files are properly isorted,
+leave it out or set it to `False` to check only files added to your
+index.
+
+## Setuptools integration
+
+Upon installation, isort enables a `setuptools` command that checks
+Python files declared by your project.
+
+Running `python setup.py isort` on the command line will check the files
+listed in your `py_modules` and `packages`. If any warning is found, the
+command will exit with an error code:
+
+```bash
+$ python setup.py isort
+```
+
+Also, to allow users to be able to use the command without having to
+install isort themselves, add isort to the setup\_requires of your
+`setup()` like so:
+
+```python
+setup(
+ name="project",
+ packages=["project"],
+
+ setup_requires=[
+ "isort"
+ ]
+)
+```
+
+## Spread the word
+
+[](https://timothycrosley.github.io/isort/)
+
+Place this badge at the top of your repository to let others know your project uses isort.
+
+For README.md:
+
+```markdown
+[](https://timothycrosley.github.io/isort/)
+```
+
+Or README.rst:
+
+```rst
+.. image:: https://img.shields.io/badge/%20imports-isort-%231674b1?style=flat&labelColor=ef8336
+ :target: https://timothycrosley.github.io/isort/
+```
+
+## Security contact information
+
+To report a security vulnerability, please use the [Tidelift security
+contact](https://tidelift.com/security). Tidelift will coordinate the
+fix and disclosure.
+
+## Why isort?
+
+isort simply stands for import sort. It was originally called
+"sortImports" however I got tired of typing the extra characters and
+came to the realization camelCase is not pythonic.
+
+I wrote isort because in an organization I used to work in the manager
+came in one day and decided all code must have alphabetically sorted
+imports. The code base was huge - and he meant for us to do it by hand.
+However, being a programmer - I\'m too lazy to spend 8 hours mindlessly
+performing a function, but not too lazy to spend 16 hours automating it.
+I was given permission to open source sortImports and here we are :)
+
+------------------------------------------------------------------------
+
+[Get professionally supported isort with the Tidelift
+Subscription](https://tidelift.com/subscription/pkg/pypi-isort?utm_source=pypi-isort&utm_medium=referral&utm_campaign=readme)
+
+Professional support for isort is available as part of the [Tidelift
+Subscription](https://tidelift.com/subscription/pkg/pypi-isort?utm_source=pypi-isort&utm_medium=referral&utm_campaign=readme).
+Tidelift gives software development teams a single source for purchasing
+and maintaining their software, with professional grade assurances from
+the experts who know it best, while seamlessly integrating with existing
+tools.
+
+------------------------------------------------------------------------
+
+Thanks and I hope you find isort useful!
+
+~Timothy Crosley
+
diff --git a/venv/Lib/site-packages/isort-5.4.2.dist-info/RECORD b/venv/Lib/site-packages/isort-5.4.2.dist-info/RECORD
new file mode 100644
index 0000000000000000000000000000000000000000..c181141d8672bb16e9d5bd0540c9f8e0eec4c1c3
--- /dev/null
+++ b/venv/Lib/site-packages/isort-5.4.2.dist-info/RECORD
@@ -0,0 +1,97 @@
+../../Scripts/isort.exe,sha256=Zpw9tE87YuoOS4aV4XGw1vUS_DjIrOR-3hBSasbB2Do,106369
+isort-5.4.2.dist-info/INSTALLER,sha256=zuuue4knoyJ-UwPPXg8fezS7VCrXJQrAP7zeNuwvFQg,4
+isort-5.4.2.dist-info/LICENSE,sha256=BjKUABw9Uj26y6ud1UrCKZgnVsyvWSylMkCysM3YIGU,1089
+isort-5.4.2.dist-info/METADATA,sha256=DeBAWU6fk135MZXZzo4U9F8Wh3fQZjFm4X6abQDsDxI,19579
+isort-5.4.2.dist-info/RECORD,,
+isort-5.4.2.dist-info/REQUESTED,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+isort-5.4.2.dist-info/WHEEL,sha256=xSvaL1DM8LOHfdyo0cCcwjZu1tC6CnCsRGWUgazvlbM,83
+isort-5.4.2.dist-info/entry_points.txt,sha256=_Iy7m5GNm89oXcjsXzVEFav4wXWsTqKXiZUARWjFI7M,148
+isort/__init__.py,sha256=u8zdFTPFro_l9J7JzdeNSlu6CU6BboY3fRTuloxbl7c,374
+isort/__main__.py,sha256=iK0trzN9CCXpQX-XPZDZ9JVkm2Lc0q0oiAgsa6FkJb4,36
+isort/__pycache__/__init__.cpython-38.pyc,,
+isort/__pycache__/__main__.cpython-38.pyc,,
+isort/__pycache__/_version.cpython-38.pyc,,
+isort/__pycache__/api.cpython-38.pyc,,
+isort/__pycache__/comments.cpython-38.pyc,,
+isort/__pycache__/core.cpython-38.pyc,,
+isort/__pycache__/exceptions.cpython-38.pyc,,
+isort/__pycache__/format.cpython-38.pyc,,
+isort/__pycache__/hooks.cpython-38.pyc,,
+isort/__pycache__/io.cpython-38.pyc,,
+isort/__pycache__/literal.cpython-38.pyc,,
+isort/__pycache__/logo.cpython-38.pyc,,
+isort/__pycache__/main.cpython-38.pyc,,
+isort/__pycache__/output.cpython-38.pyc,,
+isort/__pycache__/parse.cpython-38.pyc,,
+isort/__pycache__/place.cpython-38.pyc,,
+isort/__pycache__/profiles.cpython-38.pyc,,
+isort/__pycache__/pylama_isort.cpython-38.pyc,,
+isort/__pycache__/sections.cpython-38.pyc,,
+isort/__pycache__/settings.cpython-38.pyc,,
+isort/__pycache__/setuptools_commands.cpython-38.pyc,,
+isort/__pycache__/sorting.cpython-38.pyc,,
+isort/__pycache__/utils.cpython-38.pyc,,
+isort/__pycache__/wrap.cpython-38.pyc,,
+isort/__pycache__/wrap_modes.cpython-38.pyc,,
+isort/_future/__init__.py,sha256=wn-Aa4CVe0zZfA_YBTkJqb6LA9HR9NgpAp0uatzNRNs,326
+isort/_future/__pycache__/__init__.cpython-38.pyc,,
+isort/_future/__pycache__/_dataclasses.cpython-38.pyc,,
+isort/_future/_dataclasses.py,sha256=sjuvr80ZnihMsZ5HBTNplgPfhQ-L5xHIh1aOzEtOscQ,44066
+isort/_vendored/toml/LICENSE,sha256=LZKUgj32yJNXyL5JJ_znk2HWVh5e51MtWSbmOTmqpTY,1252
+isort/_vendored/toml/__init__.py,sha256=gKOk-Amczi2juJsOs1D6UEToaPSIIgNh95Yo5N5gneE,703
+isort/_vendored/toml/__pycache__/__init__.cpython-38.pyc,,
+isort/_vendored/toml/__pycache__/decoder.cpython-38.pyc,,
+isort/_vendored/toml/__pycache__/encoder.cpython-38.pyc,,
+isort/_vendored/toml/__pycache__/ordered.cpython-38.pyc,,
+isort/_vendored/toml/__pycache__/tz.cpython-38.pyc,,
+isort/_vendored/toml/decoder.py,sha256=5etBKNvVLFAR0rhLCJ9fnRTlqkebI4ZQeoJi_myFbd4,37713
+isort/_vendored/toml/encoder.py,sha256=gQOXYnAWo27Jc_przA1FqLX5AgwbdgN-qDHQtKRx300,9668
+isort/_vendored/toml/ordered.py,sha256=aW5woa5xOqR4BjIz9t10_lghxyhF54KQ7FqUNVv7WJ0,334
+isort/_vendored/toml/tz.py,sha256=8TAiXrTqU08sE0ruz2TXH_pFY2rlwNKE47MSE4rDo8Y,618
+isort/_version.py,sha256=FeLZIE8encwqUtsr94yKhYavIqQmfviy9Ah69YgUhLU,22
+isort/api.py,sha256=QJegKmNa6fo5FABTDK9j16b3OgmNIT9ziIsApeTjYDQ,15705
+isort/comments.py,sha256=23uMZZbUn8y3glMW6_WftnEhECvc-4LW4ysEghpYUUU,962
+isort/core.py,sha256=rKmnMA7nsW9yNLInT-GE2pLtbPOea8U0MyyT3tUSnaA,16417
+isort/deprecated/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+isort/deprecated/__pycache__/__init__.cpython-38.pyc,,
+isort/deprecated/__pycache__/finders.cpython-38.pyc,,
+isort/deprecated/finders.py,sha256=N-ujofD6auS5ZPjtaeIB5S2lZk-7Dmx17w57DeU0Q_U,14488
+isort/exceptions.py,sha256=Jxk4rfvI4TcaBcmVT2VD5LcEzwCbVQh6BXPfjP_Gmvc,4635
+isort/format.py,sha256=c5jt_mbYBG5uCXRVCTk51YR-BNjtbDVOXJpZQ2XLZR8,4112
+isort/hooks.py,sha256=iO3Pj-rW9GrMTD-znGYUMOr8TA0A8VVhujn6F8d6ILM,2716
+isort/io.py,sha256=30v6ZH7ntl6hAZGAArB5G1uol1FiQ8qb97s1G71Hwt4,1757
+isort/literal.py,sha256=PQRMWSkbbP3pEhj88pFhSjX6Q3IH-_Pn_XdLf4D7a2M,3548
+isort/logo.py,sha256=cL3al79O7O0G2viqRMRfBPp0qtRZmJw2nHSCZw8XWdQ,388
+isort/main.py,sha256=VtJ6tHYe_rfAI0ZGE6RLtfcuqo3DKM2wT3SnAqJVhtY,31757
+isort/output.py,sha256=8x59vLumT2qtgcZ4tGSO3x0Jw7-bTXUjZtQPn2fqocw,22505
+isort/parse.py,sha256=kPr-ekBkrff8FWgUnuQnGMyiwKSV89HuoZWqsgt6-fM,19244
+isort/place.py,sha256=S3eRp3EVsIq7LDgb4QN1jb7-dvtfXXr48EqJsMP54-Y,3289
+isort/profiles.py,sha256=CyCEpF1iOgrfxvC2nnRAjuKxxuojVN5NViyE-OlFciU,1502
+isort/pylama_isort.py,sha256=Qk8XqicFOn7EhVVQl-gmlybh4WVWbKaDYM8koDB8Dg8,897
+isort/sections.py,sha256=xG5bwU4tOIKUmeBBhZ45EIfjP8HgDOx796bPvD5zWCw,297
+isort/settings.py,sha256=foh76t6eWssSJXMIFXm0VCbUas2Oj7wcY2NKrTyRcAU,26573
+isort/setuptools_commands.py,sha256=2EIVYwUYAurcihzYSIDXV6zKHM-DxqxHBW-x7UnI3No,2223
+isort/sorting.py,sha256=DwRFS02vzRv-ZPTwenhYQQ0vV6owTcHQVK6q_nzqtio,2803
+isort/stdlibs/__init__.py,sha256=MgiO4yPeJZ6ieWz5qSw2LuY7pVmRjZUaCqyUaLH5qJQ,64
+isort/stdlibs/__pycache__/__init__.cpython-38.pyc,,
+isort/stdlibs/__pycache__/all.cpython-38.pyc,,
+isort/stdlibs/__pycache__/py2.cpython-38.pyc,,
+isort/stdlibs/__pycache__/py27.cpython-38.pyc,,
+isort/stdlibs/__pycache__/py3.cpython-38.pyc,,
+isort/stdlibs/__pycache__/py35.cpython-38.pyc,,
+isort/stdlibs/__pycache__/py36.cpython-38.pyc,,
+isort/stdlibs/__pycache__/py37.cpython-38.pyc,,
+isort/stdlibs/__pycache__/py38.cpython-38.pyc,,
+isort/stdlibs/__pycache__/py39.cpython-38.pyc,,
+isort/stdlibs/all.py,sha256=n8Es1WK6UlupYyVvf1PDjGbionqix-afC3LkY8nzTcw,57
+isort/stdlibs/py2.py,sha256=dTgWTa7ggz1cwN8fuI9eIs9-5nTmkRxG_uO61CGwfXI,41
+isort/stdlibs/py27.py,sha256=-Id4l2pjAOMXUfwDNnIBR2o8I_mW_Ghmuek2b82Bczk,4492
+isort/stdlibs/py3.py,sha256=4NpsSHXy9mU4pc3nazM6GTB9RD7iqN2JV9n6SUA672w,101
+isort/stdlibs/py35.py,sha256=SVZp9jaCVq4kSjbKcVgF8dJttyFCqcl20ydodsmHrqE,3283
+isort/stdlibs/py36.py,sha256=tCGWDZXWlJJI4_845yOhTpIvnU0-a3TouD_xsMEIZ3s,3298
+isort/stdlibs/py37.py,sha256=nYZmN-s3qMmAHHddegQv6U0j4cnAH0e5SmqTiG6mmhQ,3322
+isort/stdlibs/py38.py,sha256=KE_65iAHg7icOv2xSGScdJWjwBZGuSQYfYcTSIoo_d8,3307
+isort/stdlibs/py39.py,sha256=gHmC2xbsvrqqxybV9G7vrKRv7UmZpgt9NybAhR1LANk,3295
+isort/utils.py,sha256=D_NmQoPoQSTmLzy5HLcZF1hMK9DIj7vzlGDkMWR0c5E,980
+isort/wrap.py,sha256=W73QcVU_4d_LZ19Fh-Oh3eRCcjNeWqHvGSioqqRSsqo,5353
+isort/wrap_modes.py,sha256=EOkrjlWnL_m0SI7f0UtLUwsrWjv6lPaUsTnKevxAQLw,10948
diff --git a/venv/Lib/site-packages/isort-5.4.2.dist-info/REQUESTED b/venv/Lib/site-packages/isort-5.4.2.dist-info/REQUESTED
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/venv/Lib/site-packages/isort-5.4.2.dist-info/WHEEL b/venv/Lib/site-packages/isort-5.4.2.dist-info/WHEEL
new file mode 100644
index 0000000000000000000000000000000000000000..bbb34895a316f8b7d20c0cd19f5929b092b845d6
--- /dev/null
+++ b/venv/Lib/site-packages/isort-5.4.2.dist-info/WHEEL
@@ -0,0 +1,4 @@
+Wheel-Version: 1.0
+Generator: poetry 1.0.5
+Root-Is-Purelib: true
+Tag: py3-none-any
diff --git a/venv/Lib/site-packages/isort-5.4.2.dist-info/entry_points.txt b/venv/Lib/site-packages/isort-5.4.2.dist-info/entry_points.txt
new file mode 100644
index 0000000000000000000000000000000000000000..ff609bb5694903c663c5bb73097b5e8279e3a51d
--- /dev/null
+++ b/venv/Lib/site-packages/isort-5.4.2.dist-info/entry_points.txt
@@ -0,0 +1,9 @@
+[console_scripts]
+isort=isort.main:main
+
+[distutils.commands]
+isort=isort.main:ISortCommand
+
+[pylama.linter]
+isort=isort=isort.pylama_isort:Linter
+
diff --git a/venv/Lib/site-packages/isort/__init__.py b/venv/Lib/site-packages/isort/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..236255dd853da7cff00c241077b9220b77f17d46
--- /dev/null
+++ b/venv/Lib/site-packages/isort/__init__.py
@@ -0,0 +1,9 @@
+"""Defines the public isort interface"""
+from . import settings
+from ._version import __version__
+from .api import check_code_string as check_code
+from .api import check_file, check_stream, place_module, place_module_with_reason
+from .api import sort_code_string as code
+from .api import sort_file as file
+from .api import sort_stream as stream
+from .settings import Config
diff --git a/venv/Lib/site-packages/isort/__main__.py b/venv/Lib/site-packages/isort/__main__.py
new file mode 100644
index 0000000000000000000000000000000000000000..94b1d057bb0c56e009182d3aea87a48b9b59b7bf
--- /dev/null
+++ b/venv/Lib/site-packages/isort/__main__.py
@@ -0,0 +1,3 @@
+from isort.main import main
+
+main()
diff --git a/venv/Lib/site-packages/isort/_future/__init__.py b/venv/Lib/site-packages/isort/_future/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..4d9ef4b7669e1620e181ab0f8501d8d26e91af7d
--- /dev/null
+++ b/venv/Lib/site-packages/isort/_future/__init__.py
@@ -0,0 +1,12 @@
+import sys
+
+if sys.version_info.major <= 3 and sys.version_info.minor <= 6:
+ from . import _dataclasses as dataclasses # type: ignore
+
+else:
+ import dataclasses # type: ignore
+
+dataclass = dataclasses.dataclass # type: ignore
+field = dataclasses.field # type: ignore
+
+__all__ = ["dataclasses", "dataclass", "field"]
diff --git a/venv/Lib/site-packages/isort/_future/_dataclasses.py b/venv/Lib/site-packages/isort/_future/_dataclasses.py
new file mode 100644
index 0000000000000000000000000000000000000000..a7b113fe2990b548ebf2cbc492dc5bb710a78bd3
--- /dev/null
+++ b/venv/Lib/site-packages/isort/_future/_dataclasses.py
@@ -0,0 +1,1206 @@
+# type: ignore
+# flake8: noqa
+# flake8: noqa
+"""Backport of Python3.7 dataclasses Library
+
+Taken directly from here: https://github.com/ericvsmith/dataclasses
+Licensed under the Apache License: https://github.com/ericvsmith/dataclasses/blob/master/LICENSE.txt
+
+Needed due to isorts strict no non-optional requirements stance.
+
+TODO: Remove once isort only supports 3.7+
+"""
+import copy
+import inspect
+import keyword
+import re
+import sys
+import types
+
+__all__ = [
+ "dataclass",
+ "field",
+ "Field",
+ "FrozenInstanceError",
+ "InitVar",
+ "MISSING",
+ # Helper functions.
+ "fields",
+ "asdict",
+ "astuple",
+ "make_dataclass",
+ "replace",
+ "is_dataclass",
+]
+
+# Conditions for adding methods. The boxes indicate what action the
+# dataclass decorator takes. For all of these tables, when I talk
+# about init=, repr=, eq=, order=, unsafe_hash=, or frozen=, I'm
+# referring to the arguments to the @dataclass decorator. When
+# checking if a dunder method already exists, I mean check for an
+# entry in the class's __dict__. I never check to see if an attribute
+# is defined in a base class.
+
+# Key:
+# +=========+=========================================+
+# + Value | Meaning |
+# +=========+=========================================+
+# | <blank> | No action: no method is added. |
+# +---------+-----------------------------------------+
+# | add | Generated method is added. |
+# +---------+-----------------------------------------+
+# | raise | TypeError is raised. |
+# +---------+-----------------------------------------+
+# | None | Attribute is set to None. |
+# +=========+=========================================+
+
+# __init__
+#
+# +--- init= parameter
+# |
+# v | | |
+# | no | yes | <--- class has __init__ in __dict__?
+# +=======+=======+=======+
+# | False | | |
+# +-------+-------+-------+
+# | True | add | | <- the default
+# +=======+=======+=======+
+
+# __repr__
+#
+# +--- repr= parameter
+# |
+# v | | |
+# | no | yes | <--- class has __repr__ in __dict__?
+# +=======+=======+=======+
+# | False | | |
+# +-------+-------+-------+
+# | True | add | | <- the default
+# +=======+=======+=======+
+
+
+# __setattr__
+# __delattr__
+#
+# +--- frozen= parameter
+# |
+# v | | |
+# | no | yes | <--- class has __setattr__ or __delattr__ in __dict__?
+# +=======+=======+=======+
+# | False | | | <- the default
+# +-------+-------+-------+
+# | True | add | raise |
+# +=======+=======+=======+
+# Raise because not adding these methods would break the "frozen-ness"
+# of the class.
+
+# __eq__
+#
+# +--- eq= parameter
+# |
+# v | | |
+# | no | yes | <--- class has __eq__ in __dict__?
+# +=======+=======+=======+
+# | False | | |
+# +-------+-------+-------+
+# | True | add | | <- the default
+# +=======+=======+=======+
+
+# __lt__
+# __le__
+# __gt__
+# __ge__
+#
+# +--- order= parameter
+# |
+# v | | |
+# | no | yes | <--- class has any comparison method in __dict__?
+# +=======+=======+=======+
+# | False | | | <- the default
+# +-------+-------+-------+
+# | True | add | raise |
+# +=======+=======+=======+
+# Raise because to allow this case would interfere with using
+# functools.total_ordering.
+
+# __hash__
+
+# +------------------- unsafe_hash= parameter
+# | +----------- eq= parameter
+# | | +--- frozen= parameter
+# | | |
+# v v v | | |
+# | no | yes | <--- class has explicitly defined __hash__
+# +=======+=======+=======+========+========+
+# | False | False | False | | | No __eq__, use the base class __hash__
+# +-------+-------+-------+--------+--------+
+# | False | False | True | | | No __eq__, use the base class __hash__
+# +-------+-------+-------+--------+--------+
+# | False | True | False | None | | <-- the default, not hashable
+# +-------+-------+-------+--------+--------+
+# | False | True | True | add | | Frozen, so hashable, allows override
+# +-------+-------+-------+--------+--------+
+# | True | False | False | add | raise | Has no __eq__, but hashable
+# +-------+-------+-------+--------+--------+
+# | True | False | True | add | raise | Has no __eq__, but hashable
+# +-------+-------+-------+--------+--------+
+# | True | True | False | add | raise | Not frozen, but hashable
+# +-------+-------+-------+--------+--------+
+# | True | True | True | add | raise | Frozen, so hashable
+# +=======+=======+=======+========+========+
+# For boxes that are blank, __hash__ is untouched and therefore
+# inherited from the base class. If the base is object, then
+# id-based hashing is used.
+#
+# Note that a class may already have __hash__=None if it specified an
+# __eq__ method in the class body (not one that was created by
+# @dataclass).
+#
+# See _hash_action (below) for a coded version of this table.
+
+
+# Raised when an attempt is made to modify a frozen class.
+class FrozenInstanceError(AttributeError):
+ pass
+
+
+# A sentinel object for default values to signal that a default
+# factory will be used. This is given a nice repr() which will appear
+# in the function signature of dataclasses' constructors.
+class _HAS_DEFAULT_FACTORY_CLASS:
+ def __repr__(self):
+ return "<factory>"
+
+
+_HAS_DEFAULT_FACTORY = _HAS_DEFAULT_FACTORY_CLASS()
+
+# A sentinel object to detect if a parameter is supplied or not. Use
+# a class to give it a better repr.
+class _MISSING_TYPE:
+ pass
+
+
+MISSING = _MISSING_TYPE()
+
+# Since most per-field metadata will be unused, create an empty
+# read-only proxy that can be shared among all fields.
+_EMPTY_METADATA = types.MappingProxyType({})
+
+# Markers for the various kinds of fields and pseudo-fields.
+class _FIELD_BASE:
+ def __init__(self, name):
+ self.name = name
+
+ def __repr__(self):
+ return self.name
+
+
+_FIELD = _FIELD_BASE("_FIELD")
+_FIELD_CLASSVAR = _FIELD_BASE("_FIELD_CLASSVAR")
+_FIELD_INITVAR = _FIELD_BASE("_FIELD_INITVAR")
+
+# The name of an attribute on the class where we store the Field
+# objects. Also used to check if a class is a Data Class.
+_FIELDS = "__dataclass_fields__"
+
+# The name of an attribute on the class that stores the parameters to
+# @dataclass.
+_PARAMS = "__dataclass_params__"
+
+# The name of the function, that if it exists, is called at the end of
+# __init__.
+_POST_INIT_NAME = "__post_init__"
+
+# String regex that string annotations for ClassVar or InitVar must match.
+# Allows "identifier.identifier[" or "identifier[".
+# https://bugs.python.org/issue33453 for details.
+_MODULE_IDENTIFIER_RE = re.compile(r"^(?:\s*(\w+)\s*\.)?\s*(\w+)")
+
+
+class _InitVarMeta(type):
+ def __getitem__(self, params):
+ return self
+
+
+class InitVar(metaclass=_InitVarMeta):
+ pass
+
+
+# Instances of Field are only ever created from within this module,
+# and only from the field() function, although Field instances are
+# exposed externally as (conceptually) read-only objects.
+#
+# name and type are filled in after the fact, not in __init__.
+# They're not known at the time this class is instantiated, but it's
+# convenient if they're available later.
+#
+# When cls._FIELDS is filled in with a list of Field objects, the name
+# and type fields will have been populated.
+class Field:
+ __slots__ = (
+ "name",
+ "type",
+ "default",
+ "default_factory",
+ "repr",
+ "hash",
+ "init",
+ "compare",
+ "metadata",
+ "_field_type", # Private: not to be used by user code.
+ )
+
+ def __init__(self, default, default_factory, init, repr, hash, compare, metadata):
+ self.name = None
+ self.type = None
+ self.default = default
+ self.default_factory = default_factory
+ self.init = init
+ self.repr = repr
+ self.hash = hash
+ self.compare = compare
+ self.metadata = (
+ _EMPTY_METADATA
+ if metadata is None or len(metadata) == 0
+ else types.MappingProxyType(metadata)
+ )
+ self._field_type = None
+
+ def __repr__(self):
+ return (
+ "Field("
+ f"name={self.name!r},"
+ f"type={self.type!r},"
+ f"default={self.default!r},"
+ f"default_factory={self.default_factory!r},"
+ f"init={self.init!r},"
+ f"repr={self.repr!r},"
+ f"hash={self.hash!r},"
+ f"compare={self.compare!r},"
+ f"metadata={self.metadata!r},"
+ f"_field_type={self._field_type}"
+ ")"
+ )
+
+ # This is used to support the PEP 487 __set_name__ protocol in the
+ # case where we're using a field that contains a descriptor as a
+ # defaul value. For details on __set_name__, see
+ # https://www.python.org/dev/peps/pep-0487/#implementation-details.
+ #
+ # Note that in _process_class, this Field object is overwritten
+ # with the default value, so the end result is a descriptor that
+ # had __set_name__ called on it at the right time.
+ def __set_name__(self, owner, name):
+ func = getattr(type(self.default), "__set_name__", None)
+ if func:
+ # There is a __set_name__ method on the descriptor, call
+ # it.
+ func(self.default, owner, name)
+
+
+class _DataclassParams:
+ __slots__ = ("init", "repr", "eq", "order", "unsafe_hash", "frozen")
+
+ def __init__(self, init, repr, eq, order, unsafe_hash, frozen):
+ self.init = init
+ self.repr = repr
+ self.eq = eq
+ self.order = order
+ self.unsafe_hash = unsafe_hash
+ self.frozen = frozen
+
+ def __repr__(self):
+ return (
+ "_DataclassParams("
+ f"init={self.init!r},"
+ f"repr={self.repr!r},"
+ f"eq={self.eq!r},"
+ f"order={self.order!r},"
+ f"unsafe_hash={self.unsafe_hash!r},"
+ f"frozen={self.frozen!r}"
+ ")"
+ )
+
+
+# This function is used instead of exposing Field creation directly,
+# so that a type checker can be told (via overloads) that this is a
+# function whose type depends on its parameters.
+def field(
+ *,
+ default=MISSING,
+ default_factory=MISSING,
+ init=True,
+ repr=True,
+ hash=None,
+ compare=True,
+ metadata=None,
+):
+ """Return an object to identify dataclass fields.
+ default is the default value of the field. default_factory is a
+ 0-argument function called to initialize a field's value. If init
+ is True, the field will be a parameter to the class's __init__()
+ function. If repr is True, the field will be included in the
+ object's repr(). If hash is True, the field will be included in
+ the object's hash(). If compare is True, the field will be used
+ in comparison functions. metadata, if specified, must be a
+ mapping which is stored but not otherwise examined by dataclass.
+ It is an error to specify both default and default_factory.
+ """
+
+ if default is not MISSING and default_factory is not MISSING:
+ raise ValueError("cannot specify both default and default_factory")
+ return Field(default, default_factory, init, repr, hash, compare, metadata)
+
+
+def _tuple_str(obj_name, fields):
+ # Return a string representing each field of obj_name as a tuple
+ # member. So, if fields is ['x', 'y'] and obj_name is "self",
+ # return "(self.x,self.y)".
+
+ # Special case for the 0-tuple.
+ if not fields:
+ return "()"
+ # Note the trailing comma, needed if this turns out to be a 1-tuple.
+ return f'({",".join(f"{obj_name}.{f.name}" for f in fields)},)'
+
+
+def _create_fn(name, args, body, *, globals=None, locals=None, return_type=MISSING):
+ # Note that we mutate locals when exec() is called. Caller
+ # beware! The only callers are internal to this module, so no
+ # worries about external callers.
+ if locals is None:
+ locals = {}
+ return_annotation = ""
+ if return_type is not MISSING:
+ locals["_return_type"] = return_type
+ return_annotation = "->_return_type"
+ args = ",".join(args)
+ body = "\n".join(f" {b}" for b in body)
+
+ # Compute the text of the entire function.
+ txt = f"def {name}({args}){return_annotation}:\n{body}"
+
+ exec(txt, globals, locals) # nosec
+ return locals[name]
+
+
+def _field_assign(frozen, name, value, self_name):
+ # If we're a frozen class, then assign to our fields in __init__
+ # via object.__setattr__. Otherwise, just use a simple
+ # assignment.
+ #
+ # self_name is what "self" is called in this function: don't
+ # hard-code "self", since that might be a field name.
+ if frozen:
+ return f"object.__setattr__({self_name},{name!r},{value})"
+ return f"{self_name}.{name}={value}"
+
+
+def _field_init(f, frozen, globals, self_name):
+ # Return the text of the line in the body of __init__ that will
+ # initialize this field.
+
+ default_name = f"_dflt_{f.name}"
+ if f.default_factory is not MISSING:
+ if f.init:
+ # This field has a default factory. If a parameter is
+ # given, use it. If not, call the factory.
+ globals[default_name] = f.default_factory
+ value = f"{default_name}() " f"if {f.name} is _HAS_DEFAULT_FACTORY " f"else {f.name}"
+ else:
+ # This is a field that's not in the __init__ params, but
+ # has a default factory function. It needs to be
+ # initialized here by calling the factory function,
+ # because there's no other way to initialize it.
+
+ # For a field initialized with a default=defaultvalue, the
+ # class dict just has the default value
+ # (cls.fieldname=defaultvalue). But that won't work for a
+ # default factory, the factory must be called in __init__
+ # and we must assign that to self.fieldname. We can't
+ # fall back to the class dict's value, both because it's
+ # not set, and because it might be different per-class
+ # (which, after all, is why we have a factory function!).
+
+ globals[default_name] = f.default_factory
+ value = f"{default_name}()"
+ else:
+ # No default factory.
+ if f.init:
+ if f.default is MISSING:
+ # There's no default, just do an assignment.
+ value = f.name
+ elif f.default is not MISSING:
+ globals[default_name] = f.default
+ value = f.name
+ else:
+ # This field does not need initialization. Signify that
+ # to the caller by returning None.
+ return None
+
+ # Only test this now, so that we can create variables for the
+ # default. However, return None to signify that we're not going
+ # to actually do the assignment statement for InitVars.
+ if f._field_type == _FIELD_INITVAR:
+ return None
+
+ # Now, actually generate the field assignment.
+ return _field_assign(frozen, f.name, value, self_name)
+
+
+def _init_param(f):
+ # Return the __init__ parameter string for this field. For
+ # example, the equivalent of 'x:int=3' (except instead of 'int',
+ # reference a variable set to int, and instead of '3', reference a
+ # variable set to 3).
+ if f.default is MISSING and f.default_factory is MISSING:
+ # There's no default, and no default_factory, just output the
+ # variable name and type.
+ default = ""
+ elif f.default is not MISSING:
+ # There's a default, this will be the name that's used to look
+ # it up.
+ default = f"=_dflt_{f.name}"
+ elif f.default_factory is not MISSING:
+ # There's a factory function. Set a marker.
+ default = "=_HAS_DEFAULT_FACTORY"
+ return f"{f.name}:_type_{f.name}{default}"
+
+
+def _init_fn(fields, frozen, has_post_init, self_name):
+ # fields contains both real fields and InitVar pseudo-fields.
+
+ # Make sure we don't have fields without defaults following fields
+ # with defaults. This actually would be caught when exec-ing the
+ # function source code, but catching it here gives a better error
+ # message, and future-proofs us in case we build up the function
+ # using ast.
+ seen_default = False
+ for f in fields:
+ # Only consider fields in the __init__ call.
+ if f.init:
+ if not (f.default is MISSING and f.default_factory is MISSING):
+ seen_default = True
+ elif seen_default:
+ raise TypeError(f"non-default argument {f.name!r} " "follows default argument")
+
+ globals = {"MISSING": MISSING, "_HAS_DEFAULT_FACTORY": _HAS_DEFAULT_FACTORY}
+
+ body_lines = []
+ for f in fields:
+ line = _field_init(f, frozen, globals, self_name)
+ # line is None means that this field doesn't require
+ # initialization (it's a pseudo-field). Just skip it.
+ if line:
+ body_lines.append(line)
+
+ # Does this class have a post-init function?
+ if has_post_init:
+ params_str = ",".join(f.name for f in fields if f._field_type is _FIELD_INITVAR)
+ body_lines.append(f"{self_name}.{_POST_INIT_NAME}({params_str})")
+
+ # If no body lines, use 'pass'.
+ if not body_lines:
+ body_lines = ["pass"]
+
+ locals = {f"_type_{f.name}": f.type for f in fields}
+ return _create_fn(
+ "__init__",
+ [self_name] + [_init_param(f) for f in fields if f.init],
+ body_lines,
+ locals=locals,
+ globals=globals,
+ return_type=None,
+ )
+
+
+def _repr_fn(fields):
+ return _create_fn(
+ "__repr__",
+ ("self",),
+ [
+ 'return self.__class__.__qualname__ + f"('
+ + ", ".join(f"{f.name}={{self.{f.name}!r}}" for f in fields)
+ + ')"'
+ ],
+ )
+
+
+def _frozen_get_del_attr(cls, fields):
+ # XXX: globals is modified on the first call to _create_fn, then
+ # the modified version is used in the second call. Is this okay?
+ globals = {"cls": cls, "FrozenInstanceError": FrozenInstanceError}
+ if fields:
+ fields_str = "(" + ",".join(repr(f.name) for f in fields) + ",)"
+ else:
+ # Special case for the zero-length tuple.
+ fields_str = "()"
+ return (
+ _create_fn(
+ "__setattr__",
+ ("self", "name", "value"),
+ (
+ f"if type(self) is cls or name in {fields_str}:",
+ ' raise FrozenInstanceError(f"cannot assign to field {name!r}")',
+ f"super(cls, self).__setattr__(name, value)",
+ ),
+ globals=globals,
+ ),
+ _create_fn(
+ "__delattr__",
+ ("self", "name"),
+ (
+ f"if type(self) is cls or name in {fields_str}:",
+ ' raise FrozenInstanceError(f"cannot delete field {name!r}")',
+ f"super(cls, self).__delattr__(name)",
+ ),
+ globals=globals,
+ ),
+ )
+
+
+def _cmp_fn(name, op, self_tuple, other_tuple):
+ # Create a comparison function. If the fields in the object are
+ # named 'x' and 'y', then self_tuple is the string
+ # '(self.x,self.y)' and other_tuple is the string
+ # '(other.x,other.y)'.
+
+ return _create_fn(
+ name,
+ ("self", "other"),
+ [
+ "if other.__class__ is self.__class__:",
+ f" return {self_tuple}{op}{other_tuple}",
+ "return NotImplemented",
+ ],
+ )
+
+
+def _hash_fn(fields):
+ self_tuple = _tuple_str("self", fields)
+ return _create_fn("__hash__", ("self",), [f"return hash({self_tuple})"])
+
+
+def _is_classvar(a_type, typing):
+ # This test uses a typing internal class, but it's the best way to
+ # test if this is a ClassVar.
+ return type(a_type) is typing._ClassVar
+
+
+def _is_initvar(a_type, dataclasses):
+ # The module we're checking against is the module we're
+ # currently in (dataclasses.py).
+ return a_type is dataclasses.InitVar
+
+
+def _is_type(annotation, cls, a_module, a_type, is_type_predicate):
+ # Given a type annotation string, does it refer to a_type in
+ # a_module? For example, when checking that annotation denotes a
+ # ClassVar, then a_module is typing, and a_type is
+ # typing.ClassVar.
+
+ # It's possible to look up a_module given a_type, but it involves
+ # looking in sys.modules (again!), and seems like a waste since
+ # the caller already knows a_module.
+
+ # - annotation is a string type annotation
+ # - cls is the class that this annotation was found in
+ # - a_module is the module we want to match
+ # - a_type is the type in that module we want to match
+ # - is_type_predicate is a function called with (obj, a_module)
+ # that determines if obj is of the desired type.
+
+ # Since this test does not do a local namespace lookup (and
+ # instead only a module (global) lookup), there are some things it
+ # gets wrong.
+
+ # With string annotations, cv0 will be detected as a ClassVar:
+ # CV = ClassVar
+ # @dataclass
+ # class C0:
+ # cv0: CV
+
+ # But in this example cv1 will not be detected as a ClassVar:
+ # @dataclass
+ # class C1:
+ # CV = ClassVar
+ # cv1: CV
+
+ # In C1, the code in this function (_is_type) will look up "CV" in
+ # the module and not find it, so it will not consider cv1 as a
+ # ClassVar. This is a fairly obscure corner case, and the best
+ # way to fix it would be to eval() the string "CV" with the
+ # correct global and local namespaces. However that would involve
+ # a eval() penalty for every single field of every dataclass
+ # that's defined. It was judged not worth it.
+
+ match = _MODULE_IDENTIFIER_RE.match(annotation)
+ if match:
+ ns = None
+ module_name = match.group(1)
+ if not module_name:
+ # No module name, assume the class's module did
+ # "from dataclasses import InitVar".
+ ns = sys.modules.get(cls.__module__).__dict__
+ else:
+ # Look up module_name in the class's module.
+ module = sys.modules.get(cls.__module__)
+ if module and module.__dict__.get(module_name) is a_module:
+ ns = sys.modules.get(a_type.__module__).__dict__
+ if ns and is_type_predicate(ns.get(match.group(2)), a_module):
+ return True
+ return False
+
+
+def _get_field(cls, a_name, a_type):
+ # Return a Field object for this field name and type. ClassVars
+ # and InitVars are also returned, but marked as such (see
+ # f._field_type).
+
+ # If the default value isn't derived from Field, then it's only a
+ # normal default value. Convert it to a Field().
+ default = getattr(cls, a_name, MISSING)
+ if isinstance(default, Field):
+ f = default
+ else:
+ if isinstance(default, types.MemberDescriptorType):
+ # This is a field in __slots__, so it has no default value.
+ default = MISSING
+ f = field(default=default)
+
+ # Only at this point do we know the name and the type. Set them.
+ f.name = a_name
+ f.type = a_type
+
+ # Assume it's a normal field until proven otherwise. We're next
+ # going to decide if it's a ClassVar or InitVar, everything else
+ # is just a normal field.
+ f._field_type = _FIELD
+
+ # In addition to checking for actual types here, also check for
+ # string annotations. get_type_hints() won't always work for us
+ # (see https://github.com/python/typing/issues/508 for example),
+ # plus it's expensive and would require an eval for every stirng
+ # annotation. So, make a best effort to see if this is a ClassVar
+ # or InitVar using regex's and checking that the thing referenced
+ # is actually of the correct type.
+
+ # For the complete discussion, see https://bugs.python.org/issue33453
+
+ # If typing has not been imported, then it's impossible for any
+ # annotation to be a ClassVar. So, only look for ClassVar if
+ # typing has been imported by any module (not necessarily cls's
+ # module).
+ typing = sys.modules.get("typing")
+ if typing:
+ if _is_classvar(a_type, typing) or (
+ isinstance(f.type, str) and _is_type(f.type, cls, typing, typing.ClassVar, _is_classvar)
+ ):
+ f._field_type = _FIELD_CLASSVAR
+
+ # If the type is InitVar, or if it's a matching string annotation,
+ # then it's an InitVar.
+ if f._field_type is _FIELD:
+ # The module we're checking against is the module we're
+ # currently in (dataclasses.py).
+ dataclasses = sys.modules[__name__]
+ if _is_initvar(a_type, dataclasses) or (
+ isinstance(f.type, str)
+ and _is_type(f.type, cls, dataclasses, dataclasses.InitVar, _is_initvar)
+ ):
+ f._field_type = _FIELD_INITVAR
+
+ # Validations for individual fields. This is delayed until now,
+ # instead of in the Field() constructor, since only here do we
+ # know the field name, which allows for better error reporting.
+
+ # Special restrictions for ClassVar and InitVar.
+ if f._field_type in (_FIELD_CLASSVAR, _FIELD_INITVAR):
+ if f.default_factory is not MISSING:
+ raise TypeError(f"field {f.name} cannot have a " "default factory")
+ # Should I check for other field settings? default_factory
+ # seems the most serious to check for. Maybe add others. For
+ # example, how about init=False (or really,
+ # init=<not-the-default-init-value>)? It makes no sense for
+ # ClassVar and InitVar to specify init=<anything>.
+
+ # For real fields, disallow mutable defaults for known types.
+ if f._field_type is _FIELD and isinstance(f.default, (list, dict, set)):
+ raise ValueError(
+ f"mutable default {type(f.default)} for field "
+ f"{f.name} is not allowed: use default_factory"
+ )
+
+ return f
+
+
+def _set_new_attribute(cls, name, value):
+ # Never overwrites an existing attribute. Returns True if the
+ # attribute already exists.
+ if name in cls.__dict__:
+ return True
+ setattr(cls, name, value)
+ return False
+
+
+# Decide if/how we're going to create a hash function. Key is
+# (unsafe_hash, eq, frozen, does-hash-exist). Value is the action to
+# take. The common case is to do nothing, so instead of providing a
+# function that is a no-op, use None to signify that.
+
+
+def _hash_set_none(cls, fields):
+ return None
+
+
+def _hash_add(cls, fields):
+ flds = [f for f in fields if (f.compare if f.hash is None else f.hash)]
+ return _hash_fn(flds)
+
+
+def _hash_exception(cls, fields):
+ # Raise an exception.
+ raise TypeError(f"Cannot overwrite attribute __hash__ " f"in class {cls.__name__}")
+
+
+#
+# +-------------------------------------- unsafe_hash?
+# | +------------------------------- eq?
+# | | +------------------------ frozen?
+# | | | +---------------- has-explicit-hash?
+# | | | |
+# | | | | +------- action
+# | | | | |
+# v v v v v
+_hash_action = {
+ (False, False, False, False): None,
+ (False, False, False, True): None,
+ (False, False, True, False): None,
+ (False, False, True, True): None,
+ (False, True, False, False): _hash_set_none,
+ (False, True, False, True): None,
+ (False, True, True, False): _hash_add,
+ (False, True, True, True): None,
+ (True, False, False, False): _hash_add,
+ (True, False, False, True): _hash_exception,
+ (True, False, True, False): _hash_add,
+ (True, False, True, True): _hash_exception,
+ (True, True, False, False): _hash_add,
+ (True, True, False, True): _hash_exception,
+ (True, True, True, False): _hash_add,
+ (True, True, True, True): _hash_exception,
+}
+# See https://bugs.python.org/issue32929#msg312829 for an if-statement
+# version of this table.
+
+
+def _process_class(cls, init, repr, eq, order, unsafe_hash, frozen):
+ # Now that dicts retain insertion order, there's no reason to use
+ # an ordered dict. I am leveraging that ordering here, because
+ # derived class fields overwrite base class fields, but the order
+ # is defined by the base class, which is found first.
+ fields = {}
+
+ setattr(cls, _PARAMS, _DataclassParams(init, repr, eq, order, unsafe_hash, frozen))
+
+ # Find our base classes in reverse MRO order, and exclude
+ # ourselves. In reversed order so that more derived classes
+ # override earlier field definitions in base classes. As long as
+ # we're iterating over them, see if any are frozen.
+ any_frozen_base = False
+ has_dataclass_bases = False
+ for b in cls.__mro__[-1:0:-1]:
+ # Only process classes that have been processed by our
+ # decorator. That is, they have a _FIELDS attribute.
+ base_fields = getattr(b, _FIELDS, None)
+ if base_fields:
+ has_dataclass_bases = True
+ for f in base_fields.values():
+ fields[f.name] = f
+ if getattr(b, _PARAMS).frozen:
+ any_frozen_base = True
+
+ # Annotations that are defined in this class (not in base
+ # classes). If __annotations__ isn't present, then this class
+ # adds no new annotations. We use this to compute fields that are
+ # added by this class.
+ #
+ # Fields are found from cls_annotations, which is guaranteed to be
+ # ordered. Default values are from class attributes, if a field
+ # has a default. If the default value is a Field(), then it
+ # contains additional info beyond (and possibly including) the
+ # actual default value. Pseudo-fields ClassVars and InitVars are
+ # included, despite the fact that they're not real fields. That's
+ # dealt with later.
+ cls_annotations = cls.__dict__.get("__annotations__", {})
+
+ # Now find fields in our class. While doing so, validate some
+ # things, and set the default values (as class attributes) where
+ # we can.
+ cls_fields = [_get_field(cls, name, type) for name, type in cls_annotations.items()]
+ for f in cls_fields:
+ fields[f.name] = f
+
+ # If the class attribute (which is the default value for this
+ # field) exists and is of type 'Field', replace it with the
+ # real default. This is so that normal class introspection
+ # sees a real default value, not a Field.
+ if isinstance(getattr(cls, f.name, None), Field):
+ if f.default is MISSING:
+ # If there's no default, delete the class attribute.
+ # This happens if we specify field(repr=False), for
+ # example (that is, we specified a field object, but
+ # no default value). Also if we're using a default
+ # factory. The class attribute should not be set at
+ # all in the post-processed class.
+ delattr(cls, f.name)
+ else:
+ setattr(cls, f.name, f.default)
+
+ # Do we have any Field members that don't also have annotations?
+ for name, value in cls.__dict__.items():
+ if isinstance(value, Field) and not name in cls_annotations:
+ raise TypeError(f"{name!r} is a field but has no type annotation")
+
+ # Check rules that apply if we are derived from any dataclasses.
+ if has_dataclass_bases:
+ # Raise an exception if any of our bases are frozen, but we're not.
+ if any_frozen_base and not frozen:
+ raise TypeError("cannot inherit non-frozen dataclass from a " "frozen one")
+
+ # Raise an exception if we're frozen, but none of our bases are.
+ if not any_frozen_base and frozen:
+ raise TypeError("cannot inherit frozen dataclass from a " "non-frozen one")
+
+ # Remember all of the fields on our class (including bases). This
+ # also marks this class as being a dataclass.
+ setattr(cls, _FIELDS, fields)
+
+ # Was this class defined with an explicit __hash__? Note that if
+ # __eq__ is defined in this class, then python will automatically
+ # set __hash__ to None. This is a heuristic, as it's possible
+ # that such a __hash__ == None was not auto-generated, but it
+ # close enough.
+ class_hash = cls.__dict__.get("__hash__", MISSING)
+ has_explicit_hash = not (
+ class_hash is MISSING or (class_hash is None and "__eq__" in cls.__dict__)
+ )
+
+ # If we're generating ordering methods, we must be generating the
+ # eq methods.
+ if order and not eq:
+ raise ValueError("eq must be true if order is true")
+
+ if init:
+ # Does this class have a post-init function?
+ has_post_init = hasattr(cls, _POST_INIT_NAME)
+
+ # Include InitVars and regular fields (so, not ClassVars).
+ flds = [f for f in fields.values() if f._field_type in (_FIELD, _FIELD_INITVAR)]
+ _set_new_attribute(
+ cls,
+ "__init__",
+ _init_fn(
+ flds,
+ frozen,
+ has_post_init,
+ # The name to use for the "self"
+ # param in __init__. Use "self"
+ # if possible.
+ "__dataclass_self__" if "self" in fields else "self",
+ ),
+ )
+
+ # Get the fields as a list, and include only real fields. This is
+ # used in all of the following methods.
+ field_list = [f for f in fields.values() if f._field_type is _FIELD]
+
+ if repr:
+ flds = [f for f in field_list if f.repr]
+ _set_new_attribute(cls, "__repr__", _repr_fn(flds))
+
+ if eq:
+ # Create _eq__ method. There's no need for a __ne__ method,
+ # since python will call __eq__ and negate it.
+ flds = [f for f in field_list if f.compare]
+ self_tuple = _tuple_str("self", flds)
+ other_tuple = _tuple_str("other", flds)
+ _set_new_attribute(cls, "__eq__", _cmp_fn("__eq__", "==", self_tuple, other_tuple))
+
+ if order:
+ # Create and set the ordering methods.
+ flds = [f for f in field_list if f.compare]
+ self_tuple = _tuple_str("self", flds)
+ other_tuple = _tuple_str("other", flds)
+ for name, op in [("__lt__", "<"), ("__le__", "<="), ("__gt__", ">"), ("__ge__", ">=")]:
+ if _set_new_attribute(cls, name, _cmp_fn(name, op, self_tuple, other_tuple)):
+ raise TypeError(
+ f"Cannot overwrite attribute {name} "
+ f"in class {cls.__name__}. Consider using "
+ "functools.total_ordering"
+ )
+
+ if frozen:
+ for fn in _frozen_get_del_attr(cls, field_list):
+ if _set_new_attribute(cls, fn.__name__, fn):
+ raise TypeError(
+ f"Cannot overwrite attribute {fn.__name__} " f"in class {cls.__name__}"
+ )
+
+ # Decide if/how we're going to create a hash function.
+ hash_action = _hash_action[bool(unsafe_hash), bool(eq), bool(frozen), has_explicit_hash]
+ if hash_action:
+ # No need to call _set_new_attribute here, since by the time
+ # we're here the overwriting is unconditional.
+ cls.__hash__ = hash_action(cls, field_list)
+
+ if not getattr(cls, "__doc__"):
+ # Create a class doc-string.
+ cls.__doc__ = cls.__name__ + str(inspect.signature(cls)).replace(" -> None", "")
+
+ return cls
+
+
+# _cls should never be specified by keyword, so start it with an
+# underscore. The presence of _cls is used to detect if this
+# decorator is being called with parameters or not.
+def dataclass(
+ _cls=None, *, init=True, repr=True, eq=True, order=False, unsafe_hash=False, frozen=False
+):
+ """Returns the same class as was passed in, with dunder methods
+ added based on the fields defined in the class.
+ Examines PEP 526 __annotations__ to determine fields.
+ If init is true, an __init__() method is added to the class. If
+ repr is true, a __repr__() method is added. If order is true, rich
+ comparison dunder methods are added. If unsafe_hash is true, a
+ __hash__() method function is added. If frozen is true, fields may
+ not be assigned to after instance creation.
+ """
+
+ def wrap(cls):
+ return _process_class(cls, init, repr, eq, order, unsafe_hash, frozen)
+
+ # See if we're being called as @dataclass or @dataclass().
+ if _cls is None:
+ # We're called with parens.
+ return wrap
+
+ # We're called as @dataclass without parens.
+ return wrap(_cls)
+
+
+def fields(class_or_instance):
+ """Return a tuple describing the fields of this dataclass.
+ Accepts a dataclass or an instance of one. Tuple elements are of
+ type Field.
+ """
+
+ # Might it be worth caching this, per class?
+ try:
+ fields = getattr(class_or_instance, _FIELDS)
+ except AttributeError:
+ raise TypeError("must be called with a dataclass type or instance")
+
+ # Exclude pseudo-fields. Note that fields is sorted by insertion
+ # order, so the order of the tuple is as the fields were defined.
+ return tuple(f for f in fields.values() if f._field_type is _FIELD)
+
+
+def _is_dataclass_instance(obj):
+ """Returns True if obj is an instance of a dataclass."""
+ return not isinstance(obj, type) and hasattr(obj, _FIELDS)
+
+
+def is_dataclass(obj):
+ """Returns True if obj is a dataclass or an instance of a
+ dataclass."""
+ return hasattr(obj, _FIELDS)
+
+
+def asdict(obj, *, dict_factory=dict):
+ """Return the fields of a dataclass instance as a new dictionary mapping
+ field names to field values.
+ Example usage:
+ @dataclass
+ class C:
+ x: int
+ y: int
+ c = C(1, 2)
+ assert asdict(c) == {'x': 1, 'y': 2}
+ If given, 'dict_factory' will be used instead of built-in dict.
+ The function applies recursively to field values that are
+ dataclass instances. This will also look into built-in containers:
+ tuples, lists, and dicts.
+ """
+ if not _is_dataclass_instance(obj):
+ raise TypeError("asdict() should be called on dataclass instances")
+ return _asdict_inner(obj, dict_factory)
+
+
+def _asdict_inner(obj, dict_factory):
+ if _is_dataclass_instance(obj):
+ result = []
+ for f in fields(obj):
+ value = _asdict_inner(getattr(obj, f.name), dict_factory)
+ result.append((f.name, value))
+ return dict_factory(result)
+ elif isinstance(obj, (list, tuple)):
+ return type(obj)(_asdict_inner(v, dict_factory) for v in obj)
+ elif isinstance(obj, dict):
+ return type(obj)(
+ (_asdict_inner(k, dict_factory), _asdict_inner(v, dict_factory)) for k, v in obj.items()
+ )
+ else:
+ return copy.deepcopy(obj)
+
+
+def astuple(obj, *, tuple_factory=tuple):
+ """Return the fields of a dataclass instance as a new tuple of field values.
+ Example usage::
+ @dataclass
+ class C:
+ x: int
+ y: int
+ c = C(1, 2)
+ assert astuple(c) == (1, 2)
+ If given, 'tuple_factory' will be used instead of built-in tuple.
+ The function applies recursively to field values that are
+ dataclass instances. This will also look into built-in containers:
+ tuples, lists, and dicts.
+ """
+
+ if not _is_dataclass_instance(obj):
+ raise TypeError("astuple() should be called on dataclass instances")
+ return _astuple_inner(obj, tuple_factory)
+
+
+def _astuple_inner(obj, tuple_factory):
+ if _is_dataclass_instance(obj):
+ result = []
+ for f in fields(obj):
+ value = _astuple_inner(getattr(obj, f.name), tuple_factory)
+ result.append(value)
+ return tuple_factory(result)
+ elif isinstance(obj, (list, tuple)):
+ return type(obj)(_astuple_inner(v, tuple_factory) for v in obj)
+ elif isinstance(obj, dict):
+ return type(obj)(
+ (_astuple_inner(k, tuple_factory), _astuple_inner(v, tuple_factory))
+ for k, v in obj.items()
+ )
+ else:
+ return copy.deepcopy(obj)
+
+
+def make_dataclass(
+ cls_name,
+ fields,
+ *,
+ bases=(),
+ namespace=None,
+ init=True,
+ repr=True,
+ eq=True,
+ order=False,
+ unsafe_hash=False,
+ frozen=False,
+):
+ """Return a new dynamically created dataclass.
+ The dataclass name will be 'cls_name'. 'fields' is an iterable
+ of either (name), (name, type) or (name, type, Field) objects. If type is
+ omitted, use the string 'typing.Any'. Field objects are created by
+ the equivalent of calling 'field(name, type [, Field-info])'.
+ C = make_dataclass('C', ['x', ('y', int), ('z', int, field(init=False))], bases=(Base,))
+ is equivalent to:
+ @dataclass
+ class C(Base):
+ x: 'typing.Any'
+ y: int
+ z: int = field(init=False)
+ For the bases and namespace parameters, see the builtin type() function.
+ The parameters init, repr, eq, order, unsafe_hash, and frozen are passed to
+ dataclass().
+ """
+
+ if namespace is None:
+ namespace = {}
+ else:
+ # Copy namespace since we're going to mutate it.
+ namespace = namespace.copy()
+
+ # While we're looking through the field names, validate that they
+ # are identifiers, are not keywords, and not duplicates.
+ seen = set()
+ anns = {}
+ for item in fields:
+ if isinstance(item, str):
+ name = item
+ tp = "typing.Any"
+ elif len(item) == 2:
+ name, tp, = item
+ elif len(item) == 3:
+ name, tp, spec = item
+ namespace[name] = spec
+ else:
+ raise TypeError(f"Invalid field: {item!r}")
+
+ if not isinstance(name, str) or not name.isidentifier():
+ raise TypeError(f"Field names must be valid identifers: {name!r}")
+ if keyword.iskeyword(name):
+ raise TypeError(f"Field names must not be keywords: {name!r}")
+ if name in seen:
+ raise TypeError(f"Field name duplicated: {name!r}")
+
+ seen.add(name)
+ anns[name] = tp
+
+ namespace["__annotations__"] = anns
+ # We use `types.new_class()` instead of simply `type()` to allow dynamic creation
+ # of generic dataclassses.
+ cls = types.new_class(cls_name, bases, {}, lambda ns: ns.update(namespace))
+ return dataclass(
+ cls, init=init, repr=repr, eq=eq, order=order, unsafe_hash=unsafe_hash, frozen=frozen
+ )
+
+
+def replace(obj, **changes):
+ """Return a new object replacing specified fields with new values.
+ This is especially useful for frozen classes. Example usage:
+ @dataclass(frozen=True)
+ class C:
+ x: int
+ y: int
+ c = C(1, 2)
+ c1 = replace(c, x=3)
+ assert c1.x == 3 and c1.y == 2
+ """
+
+ # We're going to mutate 'changes', but that's okay because it's a
+ # new dict, even if called with 'replace(obj, **my_changes)'.
+
+ if not _is_dataclass_instance(obj):
+ raise TypeError("replace() should be called on dataclass instances")
+
+ # It's an error to have init=False fields in 'changes'.
+ # If a field is not in 'changes', read its value from the provided obj.
+
+ for f in getattr(obj, _FIELDS).values():
+ if not f.init:
+ # Error if this field is specified in changes.
+ if f.name in changes:
+ raise ValueError(
+ f"field {f.name} is declared with "
+ "init=False, it cannot be specified with "
+ "replace()"
+ )
+ continue
+
+ if f.name not in changes:
+ changes[f.name] = getattr(obj, f.name)
+
+ # Create the new object, which calls __init__() and
+ # __post_init__() (if defined), using all of the init fields we've
+ # added and/or left in 'changes'. If there are values supplied in
+ # changes that aren't fields, this will correctly raise a
+ # TypeError.
+ return obj.__class__(**changes)
diff --git a/venv/Lib/site-packages/isort/_vendored/toml/LICENSE b/venv/Lib/site-packages/isort/_vendored/toml/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..5010e3075e6b150fdfc0042ca4adb3d41335e08d
--- /dev/null
+++ b/venv/Lib/site-packages/isort/_vendored/toml/LICENSE
@@ -0,0 +1,27 @@
+The MIT License
+
+Copyright 2013-2019 William Pearson
+Copyright 2015-2016 Julien Enselme
+Copyright 2016 Google Inc.
+Copyright 2017 Samuel Vasko
+Copyright 2017 Nate Prewitt
+Copyright 2017 Jack Evans
+Copyright 2019 Filippo Broggini
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in
+all copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
+THE SOFTWARE.
\ No newline at end of file
diff --git a/venv/Lib/site-packages/isort/_vendored/toml/__init__.py b/venv/Lib/site-packages/isort/_vendored/toml/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..8cefeffade5490b0b205945ee5ae217c410d4096
--- /dev/null
+++ b/venv/Lib/site-packages/isort/_vendored/toml/__init__.py
@@ -0,0 +1,23 @@
+"""Python module which parses and emits TOML.
+
+Released under the MIT license.
+"""
+from . import decoder, encoder
+
+__version__ = "0.10.1"
+_spec_ = "0.5.0"
+
+load = decoder.load
+loads = decoder.loads
+TomlDecoder = decoder.TomlDecoder
+TomlDecodeError = decoder.TomlDecodeError
+TomlPreserveCommentDecoder = decoder.TomlPreserveCommentDecoder
+
+dump = encoder.dump
+dumps = encoder.dumps
+TomlEncoder = encoder.TomlEncoder
+TomlArraySeparatorEncoder = encoder.TomlArraySeparatorEncoder
+TomlPreserveInlineDictEncoder = encoder.TomlPreserveInlineDictEncoder
+TomlNumpyEncoder = encoder.TomlNumpyEncoder
+TomlPreserveCommentEncoder = encoder.TomlPreserveCommentEncoder
+TomlPathlibEncoder = encoder.TomlPathlibEncoder
diff --git a/venv/Lib/site-packages/isort/_vendored/toml/decoder.py b/venv/Lib/site-packages/isort/_vendored/toml/decoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..b90b6933e917a5ae6147d148e98c880354a3cc07
--- /dev/null
+++ b/venv/Lib/site-packages/isort/_vendored/toml/decoder.py
@@ -0,0 +1,1053 @@
+import datetime
+import io
+import re
+import sys
+from os import linesep
+
+from .tz import TomlTz
+
+if sys.version_info < (3,):
+ _range = xrange # noqa: F821
+else:
+ unicode = str
+ _range = range
+ basestring = str
+ unichr = chr
+
+
+def _detect_pathlib_path(p):
+ if (3, 4) <= sys.version_info:
+ import pathlib
+
+ if isinstance(p, pathlib.PurePath):
+ return True
+ return False
+
+
+def _ispath(p):
+ if isinstance(p, (bytes, basestring)):
+ return True
+ return _detect_pathlib_path(p)
+
+
+def _getpath(p):
+ if (3, 6) <= sys.version_info:
+ import os
+
+ return os.fspath(p)
+ if _detect_pathlib_path(p):
+ return str(p)
+ return p
+
+
+try:
+ FNFError = FileNotFoundError
+except NameError:
+ FNFError = IOError
+
+
+TIME_RE = re.compile(r"([0-9]{2}):([0-9]{2}):([0-9]{2})(\.([0-9]{3,6}))?")
+
+
+class TomlDecodeError(ValueError):
+ """Base toml Exception / Error."""
+
+ def __init__(self, msg, doc, pos):
+ lineno = doc.count("\n", 0, pos) + 1
+ colno = pos - doc.rfind("\n", 0, pos)
+ emsg = "{} (line {} column {} char {})".format(msg, lineno, colno, pos)
+ ValueError.__init__(self, emsg)
+ self.msg = msg
+ self.doc = doc
+ self.pos = pos
+ self.lineno = lineno
+ self.colno = colno
+
+
+# Matches a TOML number, which allows underscores for readability
+_number_with_underscores = re.compile("([0-9])(_([0-9]))*")
+
+
+class CommentValue(object):
+ def __init__(self, val, comment, beginline, _dict):
+ self.val = val
+ separator = "\n" if beginline else " "
+ self.comment = separator + comment
+ self._dict = _dict
+
+ def __getitem__(self, key):
+ return self.val[key]
+
+ def __setitem__(self, key, value):
+ self.val[key] = value
+
+ def dump(self, dump_value_func):
+ retstr = dump_value_func(self.val)
+ if isinstance(self.val, self._dict):
+ return self.comment + "\n" + unicode(retstr)
+ else:
+ return unicode(retstr) + self.comment
+
+
+def _strictly_valid_num(n):
+ n = n.strip()
+ if not n:
+ return False
+ if n[0] == "_":
+ return False
+ if n[-1] == "_":
+ return False
+ if "_." in n or "._" in n:
+ return False
+ if len(n) == 1:
+ return True
+ if n[0] == "0" and n[1] not in [".", "o", "b", "x"]:
+ return False
+ if n[0] == "+" or n[0] == "-":
+ n = n[1:]
+ if len(n) > 1 and n[0] == "0" and n[1] != ".":
+ return False
+ if "__" in n:
+ return False
+ return True
+
+
+def load(f, _dict=dict, decoder=None):
+ """Parses named file or files as toml and returns a dictionary
+
+ Args:
+ f: Path to the file to open, array of files to read into single dict
+ or a file descriptor
+ _dict: (optional) Specifies the class of the returned toml dictionary
+ decoder: The decoder to use
+
+ Returns:
+ Parsed toml file represented as a dictionary
+
+ Raises:
+ TypeError -- When f is invalid type
+ TomlDecodeError: Error while decoding toml
+ IOError / FileNotFoundError -- When an array with no valid (existing)
+ (Python 2 / Python 3) file paths is passed
+ """
+
+ if _ispath(f):
+ with io.open(_getpath(f), encoding="utf-8") as ffile:
+ return loads(ffile.read(), _dict, decoder)
+ elif isinstance(f, list):
+ from os import path as op
+ from warnings import warn
+
+ if not [path for path in f if op.exists(path)]:
+ error_msg = "Load expects a list to contain filenames only."
+ error_msg += linesep
+ error_msg += "The list needs to contain the path of at least one " "existing file."
+ raise FNFError(error_msg)
+ if decoder is None:
+ decoder = TomlDecoder(_dict)
+ d = decoder.get_empty_table()
+ for l in f: # noqa: E741
+ if op.exists(l):
+ d.update(load(l, _dict, decoder))
+ else:
+ warn("Non-existent filename in list with at least one valid " "filename")
+ return d
+ else:
+ try:
+ return loads(f.read(), _dict, decoder)
+ except AttributeError:
+ raise TypeError("You can only load a file descriptor, filename or " "list")
+
+
+_groupname_re = re.compile(r"^[A-Za-z0-9_-]+$")
+
+
+def loads(s, _dict=dict, decoder=None):
+ """Parses string as toml
+
+ Args:
+ s: String to be parsed
+ _dict: (optional) Specifies the class of the returned toml dictionary
+
+ Returns:
+ Parsed toml file represented as a dictionary
+
+ Raises:
+ TypeError: When a non-string is passed
+ TomlDecodeError: Error while decoding toml
+ """
+
+ implicitgroups = []
+ if decoder is None:
+ decoder = TomlDecoder(_dict)
+ retval = decoder.get_empty_table()
+ currentlevel = retval
+ if not isinstance(s, basestring):
+ raise TypeError("Expecting something like a string")
+
+ if not isinstance(s, unicode):
+ s = s.decode("utf8")
+
+ original = s
+ sl = list(s)
+ openarr = 0
+ openstring = False
+ openstrchar = ""
+ multilinestr = False
+ arrayoftables = False
+ beginline = True
+ keygroup = False
+ dottedkey = False
+ keyname = 0
+ key = ""
+ prev_key = ""
+ line_no = 1
+
+ for i, item in enumerate(sl):
+ if item == "\r" and sl[i + 1] == "\n":
+ sl[i] = " "
+ continue
+ if keyname:
+ key += item
+ if item == "\n":
+ raise TomlDecodeError(
+ "Key name found without value." " Reached end of line.", original, i
+ )
+ if openstring:
+ if item == openstrchar:
+ oddbackslash = False
+ k = 1
+ while i >= k and sl[i - k] == "\\":
+ oddbackslash = not oddbackslash
+ k += 1
+ if not oddbackslash:
+ keyname = 2
+ openstring = False
+ openstrchar = ""
+ continue
+ elif keyname == 1:
+ if item.isspace():
+ keyname = 2
+ continue
+ elif item == ".":
+ dottedkey = True
+ continue
+ elif item.isalnum() or item == "_" or item == "-":
+ continue
+ elif dottedkey and sl[i - 1] == "." and (item == '"' or item == "'"):
+ openstring = True
+ openstrchar = item
+ continue
+ elif keyname == 2:
+ if item.isspace():
+ if dottedkey:
+ nextitem = sl[i + 1]
+ if not nextitem.isspace() and nextitem != ".":
+ keyname = 1
+ continue
+ if item == ".":
+ dottedkey = True
+ nextitem = sl[i + 1]
+ if not nextitem.isspace() and nextitem != ".":
+ keyname = 1
+ continue
+ if item == "=":
+ keyname = 0
+ prev_key = key[:-1].rstrip()
+ key = ""
+ dottedkey = False
+ else:
+ raise TomlDecodeError(
+ "Found invalid character in key name: '"
+ + item
+ + "'. Try quoting the key name.",
+ original,
+ i,
+ )
+ if item == "'" and openstrchar != '"':
+ k = 1
+ try:
+ while sl[i - k] == "'":
+ k += 1
+ if k == 3:
+ break
+ except IndexError:
+ pass
+ if k == 3:
+ multilinestr = not multilinestr
+ openstring = multilinestr
+ else:
+ openstring = not openstring
+ if openstring:
+ openstrchar = "'"
+ else:
+ openstrchar = ""
+ if item == '"' and openstrchar != "'":
+ oddbackslash = False
+ k = 1
+ tripquote = False
+ try:
+ while sl[i - k] == '"':
+ k += 1
+ if k == 3:
+ tripquote = True
+ break
+ if k == 1 or (k == 3 and tripquote):
+ while sl[i - k] == "\\":
+ oddbackslash = not oddbackslash
+ k += 1
+ except IndexError:
+ pass
+ if not oddbackslash:
+ if tripquote:
+ multilinestr = not multilinestr
+ openstring = multilinestr
+ else:
+ openstring = not openstring
+ if openstring:
+ openstrchar = '"'
+ else:
+ openstrchar = ""
+ if item == "#" and (not openstring and not keygroup and not arrayoftables):
+ j = i
+ comment = ""
+ try:
+ while sl[j] != "\n":
+ comment += s[j]
+ sl[j] = " "
+ j += 1
+ except IndexError:
+ break
+ if not openarr:
+ decoder.preserve_comment(line_no, prev_key, comment, beginline)
+ if item == "[" and (not openstring and not keygroup and not arrayoftables):
+ if beginline:
+ if len(sl) > i + 1 and sl[i + 1] == "[":
+ arrayoftables = True
+ else:
+ keygroup = True
+ else:
+ openarr += 1
+ if item == "]" and not openstring:
+ if keygroup:
+ keygroup = False
+ elif arrayoftables:
+ if sl[i - 1] == "]":
+ arrayoftables = False
+ else:
+ openarr -= 1
+ if item == "\n":
+ if openstring or multilinestr:
+ if not multilinestr:
+ raise TomlDecodeError("Unbalanced quotes", original, i)
+ if (sl[i - 1] == "'" or sl[i - 1] == '"') and (sl[i - 2] == sl[i - 1]):
+ sl[i] = sl[i - 1]
+ if sl[i - 3] == sl[i - 1]:
+ sl[i - 3] = " "
+ elif openarr:
+ sl[i] = " "
+ else:
+ beginline = True
+ line_no += 1
+ elif beginline and sl[i] != " " and sl[i] != "\t":
+ beginline = False
+ if not keygroup and not arrayoftables:
+ if sl[i] == "=":
+ raise TomlDecodeError("Found empty keyname. ", original, i)
+ keyname = 1
+ key += item
+ if keyname:
+ raise TomlDecodeError(
+ "Key name found without value." " Reached end of file.", original, len(s)
+ )
+ if openstring: # reached EOF and have an unterminated string
+ raise TomlDecodeError(
+ "Unterminated string found." " Reached end of file.", original, len(s)
+ )
+ s = "".join(sl)
+ s = s.split("\n")
+ multikey = None
+ multilinestr = ""
+ multibackslash = False
+ pos = 0
+ for idx, line in enumerate(s):
+ if idx > 0:
+ pos += len(s[idx - 1]) + 1
+
+ decoder.embed_comments(idx, currentlevel)
+
+ if not multilinestr or multibackslash or "\n" not in multilinestr:
+ line = line.strip()
+ if line == "" and (not multikey or multibackslash):
+ continue
+ if multikey:
+ if multibackslash:
+ multilinestr += line
+ else:
+ multilinestr += line
+ multibackslash = False
+ closed = False
+ if multilinestr[0] == "[":
+ closed = line[-1] == "]"
+ elif len(line) > 2:
+ closed = (
+ line[-1] == multilinestr[0]
+ and line[-2] == multilinestr[0]
+ and line[-3] == multilinestr[0]
+ )
+ if closed:
+ try:
+ value, vtype = decoder.load_value(multilinestr)
+ except ValueError as err:
+ raise TomlDecodeError(str(err), original, pos)
+ currentlevel[multikey] = value
+ multikey = None
+ multilinestr = ""
+ else:
+ k = len(multilinestr) - 1
+ while k > -1 and multilinestr[k] == "\\":
+ multibackslash = not multibackslash
+ k -= 1
+ if multibackslash:
+ multilinestr = multilinestr[:-1]
+ else:
+ multilinestr += "\n"
+ continue
+ if line[0] == "[":
+ arrayoftables = False
+ if len(line) == 1:
+ raise TomlDecodeError(
+ "Opening key group bracket on line by " "itself.", original, pos
+ )
+ if line[1] == "[":
+ arrayoftables = True
+ line = line[2:]
+ splitstr = "]]"
+ else:
+ line = line[1:]
+ splitstr = "]"
+ i = 1
+ quotesplits = decoder._get_split_on_quotes(line)
+ quoted = False
+ for quotesplit in quotesplits:
+ if not quoted and splitstr in quotesplit:
+ break
+ i += quotesplit.count(splitstr)
+ quoted = not quoted
+ line = line.split(splitstr, i)
+ if len(line) < i + 1 or line[-1].strip() != "":
+ raise TomlDecodeError("Key group not on a line by itself.", original, pos)
+ groups = splitstr.join(line[:-1]).split(".")
+ i = 0
+ while i < len(groups):
+ groups[i] = groups[i].strip()
+ if len(groups[i]) > 0 and (groups[i][0] == '"' or groups[i][0] == "'"):
+ groupstr = groups[i]
+ j = i + 1
+ while not groupstr[0] == groupstr[-1]:
+ j += 1
+ if j > len(groups) + 2:
+ raise TomlDecodeError(
+ "Invalid group name '" + groupstr + "' Something " + "went wrong.",
+ original,
+ pos,
+ )
+ groupstr = ".".join(groups[i:j]).strip()
+ groups[i] = groupstr[1:-1]
+ groups[i + 1 : j] = []
+ else:
+ if not _groupname_re.match(groups[i]):
+ raise TomlDecodeError(
+ "Invalid group name '" + groups[i] + "'. Try quoting it.", original, pos
+ )
+ i += 1
+ currentlevel = retval
+ for i in _range(len(groups)):
+ group = groups[i]
+ if group == "":
+ raise TomlDecodeError(
+ "Can't have a keygroup with an empty " "name", original, pos
+ )
+ try:
+ currentlevel[group]
+ if i == len(groups) - 1:
+ if group in implicitgroups:
+ implicitgroups.remove(group)
+ if arrayoftables:
+ raise TomlDecodeError(
+ "An implicitly defined " "table can't be an array",
+ original,
+ pos,
+ )
+ elif arrayoftables:
+ currentlevel[group].append(decoder.get_empty_table())
+ else:
+ raise TomlDecodeError(
+ "What? " + group + " already exists?" + str(currentlevel),
+ original,
+ pos,
+ )
+ except TypeError:
+ currentlevel = currentlevel[-1]
+ if group not in currentlevel:
+ currentlevel[group] = decoder.get_empty_table()
+ if i == len(groups) - 1 and arrayoftables:
+ currentlevel[group] = [decoder.get_empty_table()]
+ except KeyError:
+ if i != len(groups) - 1:
+ implicitgroups.append(group)
+ currentlevel[group] = decoder.get_empty_table()
+ if i == len(groups) - 1 and arrayoftables:
+ currentlevel[group] = [decoder.get_empty_table()]
+ currentlevel = currentlevel[group]
+ if arrayoftables:
+ try:
+ currentlevel = currentlevel[-1]
+ except KeyError:
+ pass
+ elif line[0] == "{":
+ if line[-1] != "}":
+ raise TomlDecodeError(
+ "Line breaks are not allowed in inline" "objects", original, pos
+ )
+ try:
+ decoder.load_inline_object(line, currentlevel, multikey, multibackslash)
+ except ValueError as err:
+ raise TomlDecodeError(str(err), original, pos)
+ elif "=" in line:
+ try:
+ ret = decoder.load_line(line, currentlevel, multikey, multibackslash)
+ except ValueError as err:
+ raise TomlDecodeError(str(err), original, pos)
+ if ret is not None:
+ multikey, multilinestr, multibackslash = ret
+ return retval
+
+
+def _load_date(val):
+ microsecond = 0
+ tz = None
+ try:
+ if len(val) > 19:
+ if val[19] == ".":
+ if val[-1].upper() == "Z":
+ subsecondval = val[20:-1]
+ tzval = "Z"
+ else:
+ subsecondvalandtz = val[20:]
+ if "+" in subsecondvalandtz:
+ splitpoint = subsecondvalandtz.index("+")
+ subsecondval = subsecondvalandtz[:splitpoint]
+ tzval = subsecondvalandtz[splitpoint:]
+ elif "-" in subsecondvalandtz:
+ splitpoint = subsecondvalandtz.index("-")
+ subsecondval = subsecondvalandtz[:splitpoint]
+ tzval = subsecondvalandtz[splitpoint:]
+ else:
+ tzval = None
+ subsecondval = subsecondvalandtz
+ if tzval is not None:
+ tz = TomlTz(tzval)
+ microsecond = int(int(subsecondval) * (10 ** (6 - len(subsecondval))))
+ else:
+ tz = TomlTz(val[19:])
+ except ValueError:
+ tz = None
+ if "-" not in val[1:]:
+ return None
+ try:
+ if len(val) == 10:
+ d = datetime.date(int(val[:4]), int(val[5:7]), int(val[8:10]))
+ else:
+ d = datetime.datetime(
+ int(val[:4]),
+ int(val[5:7]),
+ int(val[8:10]),
+ int(val[11:13]),
+ int(val[14:16]),
+ int(val[17:19]),
+ microsecond,
+ tz,
+ )
+ except ValueError:
+ return None
+ return d
+
+
+def _load_unicode_escapes(v, hexbytes, prefix):
+ skip = False
+ i = len(v) - 1
+ while i > -1 and v[i] == "\\":
+ skip = not skip
+ i -= 1
+ for hx in hexbytes:
+ if skip:
+ skip = False
+ i = len(hx) - 1
+ while i > -1 and hx[i] == "\\":
+ skip = not skip
+ i -= 1
+ v += prefix
+ v += hx
+ continue
+ hxb = ""
+ i = 0
+ hxblen = 4
+ if prefix == "\\U":
+ hxblen = 8
+ hxb = "".join(hx[i : i + hxblen]).lower()
+ if hxb.strip("0123456789abcdef"):
+ raise ValueError("Invalid escape sequence: " + hxb)
+ if hxb[0] == "d" and hxb[1].strip("01234567"):
+ raise ValueError(
+ "Invalid escape sequence: " + hxb + ". Only scalar unicode points are allowed."
+ )
+ v += unichr(int(hxb, 16))
+ v += unicode(hx[len(hxb) :])
+ return v
+
+
+# Unescape TOML string values.
+
+# content after the \
+_escapes = ["0", "b", "f", "n", "r", "t", '"']
+# What it should be replaced by
+_escapedchars = ["\0", "\b", "\f", "\n", "\r", "\t", '"']
+# Used for substitution
+_escape_to_escapedchars = dict(zip(_escapes, _escapedchars))
+
+
+def _unescape(v):
+ """Unescape characters in a TOML string."""
+ i = 0
+ backslash = False
+ while i < len(v):
+ if backslash:
+ backslash = False
+ if v[i] in _escapes:
+ v = v[: i - 1] + _escape_to_escapedchars[v[i]] + v[i + 1 :]
+ elif v[i] == "\\":
+ v = v[: i - 1] + v[i:]
+ elif v[i] == "u" or v[i] == "U":
+ i += 1
+ else:
+ raise ValueError("Reserved escape sequence used")
+ continue
+ elif v[i] == "\\":
+ backslash = True
+ i += 1
+ return v
+
+
+class InlineTableDict(object):
+ """Sentinel subclass of dict for inline tables."""
+
+
+class TomlDecoder(object):
+ def __init__(self, _dict=dict):
+ self._dict = _dict
+
+ def get_empty_table(self):
+ return self._dict()
+
+ def get_empty_inline_table(self):
+ class DynamicInlineTableDict(self._dict, InlineTableDict):
+ """Concrete sentinel subclass for inline tables.
+ It is a subclass of _dict which is passed in dynamically at load
+ time
+
+ It is also a subclass of InlineTableDict
+ """
+
+ return DynamicInlineTableDict()
+
+ def load_inline_object(self, line, currentlevel, multikey=False, multibackslash=False):
+ candidate_groups = line[1:-1].split(",")
+ groups = []
+ if len(candidate_groups) == 1 and not candidate_groups[0].strip():
+ candidate_groups.pop()
+ while len(candidate_groups) > 0:
+ candidate_group = candidate_groups.pop(0)
+ try:
+ _, value = candidate_group.split("=", 1)
+ except ValueError:
+ raise ValueError("Invalid inline table encountered")
+ value = value.strip()
+ if (value[0] == value[-1] and value[0] in ('"', "'")) or (
+ value[0] in "-0123456789"
+ or value in ("true", "false")
+ or (value[0] == "[" and value[-1] == "]")
+ or (value[0] == "{" and value[-1] == "}")
+ ):
+ groups.append(candidate_group)
+ elif len(candidate_groups) > 0:
+ candidate_groups[0] = candidate_group + "," + candidate_groups[0]
+ else:
+ raise ValueError("Invalid inline table value encountered")
+ for group in groups:
+ status = self.load_line(group, currentlevel, multikey, multibackslash)
+ if status is not None:
+ break
+
+ def _get_split_on_quotes(self, line):
+ doublequotesplits = line.split('"')
+ quoted = False
+ quotesplits = []
+ if len(doublequotesplits) > 1 and "'" in doublequotesplits[0]:
+ singlequotesplits = doublequotesplits[0].split("'")
+ doublequotesplits = doublequotesplits[1:]
+ while len(singlequotesplits) % 2 == 0 and len(doublequotesplits):
+ singlequotesplits[-1] += '"' + doublequotesplits[0]
+ doublequotesplits = doublequotesplits[1:]
+ if "'" in singlequotesplits[-1]:
+ singlequotesplits = singlequotesplits[:-1] + singlequotesplits[-1].split("'")
+ quotesplits += singlequotesplits
+ for doublequotesplit in doublequotesplits:
+ if quoted:
+ quotesplits.append(doublequotesplit)
+ else:
+ quotesplits += doublequotesplit.split("'")
+ quoted = not quoted
+ return quotesplits
+
+ def load_line(self, line, currentlevel, multikey, multibackslash):
+ i = 1
+ quotesplits = self._get_split_on_quotes(line)
+ quoted = False
+ for quotesplit in quotesplits:
+ if not quoted and "=" in quotesplit:
+ break
+ i += quotesplit.count("=")
+ quoted = not quoted
+ pair = line.split("=", i)
+ strictly_valid = _strictly_valid_num(pair[-1])
+ if _number_with_underscores.match(pair[-1]):
+ pair[-1] = pair[-1].replace("_", "")
+ while len(pair[-1]) and (
+ pair[-1][0] != " "
+ and pair[-1][0] != "\t"
+ and pair[-1][0] != "'"
+ and pair[-1][0] != '"'
+ and pair[-1][0] != "["
+ and pair[-1][0] != "{"
+ and pair[-1].strip() != "true"
+ and pair[-1].strip() != "false"
+ ):
+ try:
+ float(pair[-1])
+ break
+ except ValueError:
+ pass
+ if _load_date(pair[-1]) is not None:
+ break
+ if TIME_RE.match(pair[-1]):
+ break
+ i += 1
+ prev_val = pair[-1]
+ pair = line.split("=", i)
+ if prev_val == pair[-1]:
+ raise ValueError("Invalid date or number")
+ if strictly_valid:
+ strictly_valid = _strictly_valid_num(pair[-1])
+ pair = ["=".join(pair[:-1]).strip(), pair[-1].strip()]
+ if "." in pair[0]:
+ if '"' in pair[0] or "'" in pair[0]:
+ quotesplits = self._get_split_on_quotes(pair[0])
+ quoted = False
+ levels = []
+ for quotesplit in quotesplits:
+ if quoted:
+ levels.append(quotesplit)
+ else:
+ levels += [level.strip() for level in quotesplit.split(".")]
+ quoted = not quoted
+ else:
+ levels = pair[0].split(".")
+ while levels[-1] == "":
+ levels = levels[:-1]
+ for level in levels[:-1]:
+ if level == "":
+ continue
+ if level not in currentlevel:
+ currentlevel[level] = self.get_empty_table()
+ currentlevel = currentlevel[level]
+ pair[0] = levels[-1].strip()
+ elif (pair[0][0] == '"' or pair[0][0] == "'") and (pair[0][-1] == pair[0][0]):
+ pair[0] = _unescape(pair[0][1:-1])
+ k, koffset = self._load_line_multiline_str(pair[1])
+ if k > -1:
+ while k > -1 and pair[1][k + koffset] == "\\":
+ multibackslash = not multibackslash
+ k -= 1
+ if multibackslash:
+ multilinestr = pair[1][:-1]
+ else:
+ multilinestr = pair[1] + "\n"
+ multikey = pair[0]
+ else:
+ value, vtype = self.load_value(pair[1], strictly_valid)
+ try:
+ currentlevel[pair[0]]
+ raise ValueError("Duplicate keys!")
+ except TypeError:
+ raise ValueError("Duplicate keys!")
+ except KeyError:
+ if multikey:
+ return multikey, multilinestr, multibackslash
+ else:
+ currentlevel[pair[0]] = value
+
+ def _load_line_multiline_str(self, p):
+ poffset = 0
+ if len(p) < 3:
+ return -1, poffset
+ if p[0] == "[" and (p.strip()[-1] != "]" and self._load_array_isstrarray(p)):
+ newp = p[1:].strip().split(",")
+ while len(newp) > 1 and newp[-1][0] != '"' and newp[-1][0] != "'":
+ newp = newp[:-2] + [newp[-2] + "," + newp[-1]]
+ newp = newp[-1]
+ poffset = len(p) - len(newp)
+ p = newp
+ if p[0] != '"' and p[0] != "'":
+ return -1, poffset
+ if p[1] != p[0] or p[2] != p[0]:
+ return -1, poffset
+ if len(p) > 5 and p[-1] == p[0] and p[-2] == p[0] and p[-3] == p[0]:
+ return -1, poffset
+ return len(p) - 1, poffset
+
+ def load_value(self, v, strictly_valid=True):
+ if not v:
+ raise ValueError("Empty value is invalid")
+ if v == "true":
+ return (True, "bool")
+ elif v == "false":
+ return (False, "bool")
+ elif v[0] == '"' or v[0] == "'":
+ quotechar = v[0]
+ testv = v[1:].split(quotechar)
+ triplequote = False
+ triplequotecount = 0
+ if len(testv) > 1 and testv[0] == "" and testv[1] == "":
+ testv = testv[2:]
+ triplequote = True
+ closed = False
+ for tv in testv:
+ if tv == "":
+ if triplequote:
+ triplequotecount += 1
+ else:
+ closed = True
+ else:
+ oddbackslash = False
+ try:
+ i = -1
+ j = tv[i]
+ while j == "\\":
+ oddbackslash = not oddbackslash
+ i -= 1
+ j = tv[i]
+ except IndexError:
+ pass
+ if not oddbackslash:
+ if closed:
+ raise ValueError(
+ "Found tokens after a closed " + "string. Invalid TOML."
+ )
+ else:
+ if not triplequote or triplequotecount > 1:
+ closed = True
+ else:
+ triplequotecount = 0
+ if quotechar == '"':
+ escapeseqs = v.split("\\")[1:]
+ backslash = False
+ for i in escapeseqs:
+ if i == "":
+ backslash = not backslash
+ else:
+ if i[0] not in _escapes and (i[0] != "u" and i[0] != "U" and not backslash):
+ raise ValueError("Reserved escape sequence used")
+ if backslash:
+ backslash = False
+ for prefix in ["\\u", "\\U"]:
+ if prefix in v:
+ hexbytes = v.split(prefix)
+ v = _load_unicode_escapes(hexbytes[0], hexbytes[1:], prefix)
+ v = _unescape(v)
+ if len(v) > 1 and v[1] == quotechar and (len(v) < 3 or v[1] == v[2]):
+ v = v[2:-2]
+ return (v[1:-1], "str")
+ elif v[0] == "[":
+ return (self.load_array(v), "array")
+ elif v[0] == "{":
+ inline_object = self.get_empty_inline_table()
+ self.load_inline_object(v, inline_object)
+ return (inline_object, "inline_object")
+ elif TIME_RE.match(v):
+ h, m, s, _, ms = TIME_RE.match(v).groups()
+ time = datetime.time(int(h), int(m), int(s), int(ms) if ms else 0)
+ return (time, "time")
+ else:
+ parsed_date = _load_date(v)
+ if parsed_date is not None:
+ return (parsed_date, "date")
+ if not strictly_valid:
+ raise ValueError("Weirdness with leading zeroes or " "underscores in your number.")
+ itype = "int"
+ neg = False
+ if v[0] == "-":
+ neg = True
+ v = v[1:]
+ elif v[0] == "+":
+ v = v[1:]
+ v = v.replace("_", "")
+ lowerv = v.lower()
+ if "." in v or ("x" not in v and ("e" in v or "E" in v)):
+ if "." in v and v.split(".", 1)[1] == "":
+ raise ValueError("This float is missing digits after " "the point")
+ if v[0] not in "0123456789":
+ raise ValueError("This float doesn't have a leading " "digit")
+ v = float(v)
+ itype = "float"
+ elif len(lowerv) == 3 and (lowerv == "inf" or lowerv == "nan"):
+ v = float(v)
+ itype = "float"
+ if itype == "int":
+ v = int(v, 0)
+ if neg:
+ return (0 - v, itype)
+ return (v, itype)
+
+ def bounded_string(self, s):
+ if len(s) == 0:
+ return True
+ if s[-1] != s[0]:
+ return False
+ i = -2
+ backslash = False
+ while len(s) + i > 0:
+ if s[i] == "\\":
+ backslash = not backslash
+ i -= 1
+ else:
+ break
+ return not backslash
+
+ def _load_array_isstrarray(self, a):
+ a = a[1:-1].strip()
+ if a != "" and (a[0] == '"' or a[0] == "'"):
+ return True
+ return False
+
+ def load_array(self, a):
+ atype = None
+ retval = []
+ a = a.strip()
+ if "[" not in a[1:-1] or "" != a[1:-1].split("[")[0].strip():
+ strarray = self._load_array_isstrarray(a)
+ if not a[1:-1].strip().startswith("{"):
+ a = a[1:-1].split(",")
+ else:
+ # a is an inline object, we must find the matching parenthesis
+ # to define groups
+ new_a = []
+ start_group_index = 1
+ end_group_index = 2
+ open_bracket_count = 1 if a[start_group_index] == "{" else 0
+ in_str = False
+ while end_group_index < len(a[1:]):
+ if a[end_group_index] == '"' or a[end_group_index] == "'":
+ if in_str:
+ backslash_index = end_group_index - 1
+ while backslash_index > -1 and a[backslash_index] == "\\":
+ in_str = not in_str
+ backslash_index -= 1
+ in_str = not in_str
+ if not in_str and a[end_group_index] == "{":
+ open_bracket_count += 1
+ if in_str or a[end_group_index] != "}":
+ end_group_index += 1
+ continue
+ elif a[end_group_index] == "}" and open_bracket_count > 1:
+ open_bracket_count -= 1
+ end_group_index += 1
+ continue
+
+ # Increase end_group_index by 1 to get the closing bracket
+ end_group_index += 1
+
+ new_a.append(a[start_group_index:end_group_index])
+
+ # The next start index is at least after the closing
+ # bracket, a closing bracket can be followed by a comma
+ # since we are in an array.
+ start_group_index = end_group_index + 1
+ while start_group_index < len(a[1:]) and a[start_group_index] != "{":
+ start_group_index += 1
+ end_group_index = start_group_index + 1
+ a = new_a
+ b = 0
+ if strarray:
+ while b < len(a) - 1:
+ ab = a[b].strip()
+ while not self.bounded_string(ab) or (
+ len(ab) > 2
+ and ab[0] == ab[1] == ab[2]
+ and ab[-2] != ab[0]
+ and ab[-3] != ab[0]
+ ):
+ a[b] = a[b] + "," + a[b + 1]
+ ab = a[b].strip()
+ if b < len(a) - 2:
+ a = a[: b + 1] + a[b + 2 :]
+ else:
+ a = a[: b + 1]
+ b += 1
+ else:
+ al = list(a[1:-1])
+ a = []
+ openarr = 0
+ j = 0
+ for i in _range(len(al)):
+ if al[i] == "[":
+ openarr += 1
+ elif al[i] == "]":
+ openarr -= 1
+ elif al[i] == "," and not openarr:
+ a.append("".join(al[j:i]))
+ j = i + 1
+ a.append("".join(al[j:]))
+ for i in _range(len(a)):
+ a[i] = a[i].strip()
+ if a[i] != "":
+ nval, ntype = self.load_value(a[i])
+ if atype:
+ if ntype != atype:
+ raise ValueError("Not a homogeneous array")
+ else:
+ atype = ntype
+ retval.append(nval)
+ return retval
+
+ def preserve_comment(self, line_no, key, comment, beginline):
+ pass
+
+ def embed_comments(self, idx, currentlevel):
+ pass
+
+
+class TomlPreserveCommentDecoder(TomlDecoder):
+ def __init__(self, _dict=dict):
+ self.saved_comments = {}
+ super(TomlPreserveCommentDecoder, self).__init__(_dict)
+
+ def preserve_comment(self, line_no, key, comment, beginline):
+ self.saved_comments[line_no] = (key, comment, beginline)
+
+ def embed_comments(self, idx, currentlevel):
+ if idx not in self.saved_comments:
+ return
+
+ key, comment, beginline = self.saved_comments[idx]
+ currentlevel[key] = CommentValue(currentlevel[key], comment, beginline, self._dict)
diff --git a/venv/Lib/site-packages/isort/_vendored/toml/encoder.py b/venv/Lib/site-packages/isort/_vendored/toml/encoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..68ec60f9ffb73c53ed4b5faf1484c25c5b838e81
--- /dev/null
+++ b/venv/Lib/site-packages/isort/_vendored/toml/encoder.py
@@ -0,0 +1,295 @@
+import datetime
+import re
+import sys
+from decimal import Decimal
+
+from .decoder import InlineTableDict
+
+if sys.version_info >= (3,):
+ unicode = str
+
+
+def dump(o, f, encoder=None):
+ """Writes out dict as toml to a file
+
+ Args:
+ o: Object to dump into toml
+ f: File descriptor where the toml should be stored
+ encoder: The ``TomlEncoder`` to use for constructing the output string
+
+ Returns:
+ String containing the toml corresponding to dictionary
+
+ Raises:
+ TypeError: When anything other than file descriptor is passed
+ """
+
+ if not f.write:
+ raise TypeError("You can only dump an object to a file descriptor")
+ d = dumps(o, encoder=encoder)
+ f.write(d)
+ return d
+
+
+def dumps(o, encoder=None):
+ """Stringifies input dict as toml
+
+ Args:
+ o: Object to dump into toml
+ encoder: The ``TomlEncoder`` to use for constructing the output string
+
+ Returns:
+ String containing the toml corresponding to dict
+
+ Examples:
+ ```python
+ >>> import toml
+ >>> output = {
+ ... 'a': "I'm a string",
+ ... 'b': ["I'm", "a", "list"],
+ ... 'c': 2400
+ ... }
+ >>> toml.dumps(output)
+ 'a = "I\'m a string"\nb = [ "I\'m", "a", "list",]\nc = 2400\n'
+ ```
+ """
+
+ retval = ""
+ if encoder is None:
+ encoder = TomlEncoder(o.__class__)
+ addtoretval, sections = encoder.dump_sections(o, "")
+ retval += addtoretval
+ outer_objs = [id(o)]
+ while sections:
+ section_ids = [id(section) for section in sections]
+ for outer_obj in outer_objs:
+ if outer_obj in section_ids:
+ raise ValueError("Circular reference detected")
+ outer_objs += section_ids
+ newsections = encoder.get_empty_table()
+ for section in sections:
+ addtoretval, addtosections = encoder.dump_sections(sections[section], section)
+
+ if addtoretval or (not addtoretval and not addtosections):
+ if retval and retval[-2:] != "\n\n":
+ retval += "\n"
+ retval += "[" + section + "]\n"
+ if addtoretval:
+ retval += addtoretval
+ for s in addtosections:
+ newsections[section + "." + s] = addtosections[s]
+ sections = newsections
+ return retval
+
+
+def _dump_str(v):
+ if sys.version_info < (3,) and hasattr(v, "decode") and isinstance(v, str):
+ v = v.decode("utf-8")
+ v = "%r" % v
+ if v[0] == "u":
+ v = v[1:]
+ singlequote = v.startswith("'")
+ if singlequote or v.startswith('"'):
+ v = v[1:-1]
+ if singlequote:
+ v = v.replace("\\'", "'")
+ v = v.replace('"', '\\"')
+ v = v.split("\\x")
+ while len(v) > 1:
+ i = -1
+ if not v[0]:
+ v = v[1:]
+ v[0] = v[0].replace("\\\\", "\\")
+ # No, I don't know why != works and == breaks
+ joinx = v[0][i] != "\\"
+ while v[0][:i] and v[0][i] == "\\":
+ joinx = not joinx
+ i -= 1
+ if joinx:
+ joiner = "x"
+ else:
+ joiner = "u00"
+ v = [v[0] + joiner + v[1]] + v[2:]
+ return unicode('"' + v[0] + '"')
+
+
+def _dump_float(v):
+ return "{}".format(v).replace("e+0", "e+").replace("e-0", "e-")
+
+
+def _dump_time(v):
+ utcoffset = v.utcoffset()
+ if utcoffset is None:
+ return v.isoformat()
+ # The TOML norm specifies that it's local time thus we drop the offset
+ return v.isoformat()[:-6]
+
+
+class TomlEncoder(object):
+ def __init__(self, _dict=dict, preserve=False):
+ self._dict = _dict
+ self.preserve = preserve
+ self.dump_funcs = {
+ str: _dump_str,
+ unicode: _dump_str,
+ list: self.dump_list,
+ bool: lambda v: unicode(v).lower(),
+ int: lambda v: v,
+ float: _dump_float,
+ Decimal: _dump_float,
+ datetime.datetime: lambda v: v.isoformat().replace("+00:00", "Z"),
+ datetime.time: _dump_time,
+ datetime.date: lambda v: v.isoformat(),
+ }
+
+ def get_empty_table(self):
+ return self._dict()
+
+ def dump_list(self, v):
+ retval = "["
+ for u in v:
+ retval += " " + unicode(self.dump_value(u)) + ","
+ retval += "]"
+ return retval
+
+ def dump_inline_table(self, section):
+ """Preserve inline table in its compact syntax instead of expanding
+ into subsection.
+
+ https://github.com/toml-lang/toml#user-content-inline-table
+ """
+ retval = ""
+ if isinstance(section, dict):
+ val_list = []
+ for k, v in section.items():
+ val = self.dump_inline_table(v)
+ val_list.append(k + " = " + val)
+ retval += "{ " + ", ".join(val_list) + " }\n"
+ return retval
+ else:
+ return unicode(self.dump_value(section))
+
+ def dump_value(self, v):
+ # Lookup function corresponding to v's type
+ dump_fn = self.dump_funcs.get(type(v))
+ if dump_fn is None and hasattr(v, "__iter__"):
+ dump_fn = self.dump_funcs[list]
+ # Evaluate function (if it exists) else return v
+ return dump_fn(v) if dump_fn is not None else self.dump_funcs[str](v)
+
+ def dump_sections(self, o, sup):
+ retstr = ""
+ if sup != "" and sup[-1] != ".":
+ sup += "."
+ retdict = self._dict()
+ arraystr = ""
+ for section in o:
+ section = unicode(section)
+ qsection = section
+ if not re.match(r"^[A-Za-z0-9_-]+$", section):
+ qsection = _dump_str(section)
+ if not isinstance(o[section], dict):
+ arrayoftables = False
+ if isinstance(o[section], list):
+ for a in o[section]:
+ if isinstance(a, dict):
+ arrayoftables = True
+ if arrayoftables:
+ for a in o[section]:
+ arraytabstr = "\n"
+ arraystr += "[[" + sup + qsection + "]]\n"
+ s, d = self.dump_sections(a, sup + qsection)
+ if s:
+ if s[0] == "[":
+ arraytabstr += s
+ else:
+ arraystr += s
+ while d:
+ newd = self._dict()
+ for dsec in d:
+ s1, d1 = self.dump_sections(d[dsec], sup + qsection + "." + dsec)
+ if s1:
+ arraytabstr += "[" + sup + qsection + "." + dsec + "]\n"
+ arraytabstr += s1
+ for s1 in d1:
+ newd[dsec + "." + s1] = d1[s1]
+ d = newd
+ arraystr += arraytabstr
+ else:
+ if o[section] is not None:
+ retstr += qsection + " = " + unicode(self.dump_value(o[section])) + "\n"
+ elif self.preserve and isinstance(o[section], InlineTableDict):
+ retstr += qsection + " = " + self.dump_inline_table(o[section])
+ else:
+ retdict[qsection] = o[section]
+ retstr += arraystr
+ return (retstr, retdict)
+
+
+class TomlPreserveInlineDictEncoder(TomlEncoder):
+ def __init__(self, _dict=dict):
+ super(TomlPreserveInlineDictEncoder, self).__init__(_dict, True)
+
+
+class TomlArraySeparatorEncoder(TomlEncoder):
+ def __init__(self, _dict=dict, preserve=False, separator=","):
+ super(TomlArraySeparatorEncoder, self).__init__(_dict, preserve)
+ if separator.strip() == "":
+ separator = "," + separator
+ elif separator.strip(" \t\n\r,"):
+ raise ValueError("Invalid separator for arrays")
+ self.separator = separator
+
+ def dump_list(self, v):
+ t = []
+ retval = "["
+ for u in v:
+ t.append(self.dump_value(u))
+ while t != []:
+ s = []
+ for u in t:
+ if isinstance(u, list):
+ for r in u:
+ s.append(r)
+ else:
+ retval += " " + unicode(u) + self.separator
+ t = s
+ retval += "]"
+ return retval
+
+
+class TomlNumpyEncoder(TomlEncoder):
+ def __init__(self, _dict=dict, preserve=False):
+ import numpy as np
+
+ super(TomlNumpyEncoder, self).__init__(_dict, preserve)
+ self.dump_funcs[np.float16] = _dump_float
+ self.dump_funcs[np.float32] = _dump_float
+ self.dump_funcs[np.float64] = _dump_float
+ self.dump_funcs[np.int16] = self._dump_int
+ self.dump_funcs[np.int32] = self._dump_int
+ self.dump_funcs[np.int64] = self._dump_int
+
+ def _dump_int(self, v):
+ return "{}".format(int(v))
+
+
+class TomlPreserveCommentEncoder(TomlEncoder):
+ def __init__(self, _dict=dict, preserve=False):
+ from toml.decoder import CommentValue
+
+ super(TomlPreserveCommentEncoder, self).__init__(_dict, preserve)
+ self.dump_funcs[CommentValue] = lambda v: v.dump(self.dump_value)
+
+
+class TomlPathlibEncoder(TomlEncoder):
+ def _dump_pathlib_path(self, v):
+ return _dump_str(str(v))
+
+ def dump_value(self, v):
+ if (3, 4) <= sys.version_info:
+ import pathlib
+
+ if isinstance(v, pathlib.PurePath):
+ v = str(v)
+ return super(TomlPathlibEncoder, self).dump_value(v)
diff --git a/venv/Lib/site-packages/isort/_vendored/toml/ordered.py b/venv/Lib/site-packages/isort/_vendored/toml/ordered.py
new file mode 100644
index 0000000000000000000000000000000000000000..013b31e5c819c02793ecf5ec498d768be0ec7ea2
--- /dev/null
+++ b/venv/Lib/site-packages/isort/_vendored/toml/ordered.py
@@ -0,0 +1,13 @@
+from collections import OrderedDict
+
+from . import TomlDecoder, TomlEncoder
+
+
+class TomlOrderedDecoder(TomlDecoder):
+ def __init__(self):
+ super(self.__class__, self).__init__(_dict=OrderedDict)
+
+
+class TomlOrderedEncoder(TomlEncoder):
+ def __init__(self):
+ super(self.__class__, self).__init__(_dict=OrderedDict)
diff --git a/venv/Lib/site-packages/isort/_vendored/toml/tz.py b/venv/Lib/site-packages/isort/_vendored/toml/tz.py
new file mode 100644
index 0000000000000000000000000000000000000000..46214bd4d01ce71cbc9893b91615905ffe118c6d
--- /dev/null
+++ b/venv/Lib/site-packages/isort/_vendored/toml/tz.py
@@ -0,0 +1,21 @@
+from datetime import timedelta, tzinfo
+
+
+class TomlTz(tzinfo):
+ def __init__(self, toml_offset):
+ if toml_offset == "Z":
+ self._raw_offset = "+00:00"
+ else:
+ self._raw_offset = toml_offset
+ self._sign = -1 if self._raw_offset[0] == "-" else 1
+ self._hours = int(self._raw_offset[1:3])
+ self._minutes = int(self._raw_offset[4:6])
+
+ def tzname(self, dt):
+ return "UTC" + self._raw_offset
+
+ def utcoffset(self, dt):
+ return self._sign * timedelta(hours=self._hours, minutes=self._minutes)
+
+ def dst(self, dt):
+ return timedelta(0)
diff --git a/venv/Lib/site-packages/isort/_version.py b/venv/Lib/site-packages/isort/_version.py
new file mode 100644
index 0000000000000000000000000000000000000000..cfda0f8e3fe5cb4d7d7eb8ad65723700f13f87e1
--- /dev/null
+++ b/venv/Lib/site-packages/isort/_version.py
@@ -0,0 +1 @@
+__version__ = "5.4.2"
diff --git a/venv/Lib/site-packages/isort/api.py b/venv/Lib/site-packages/isort/api.py
new file mode 100644
index 0000000000000000000000000000000000000000..059bbf9e5d11b055de3956d733f09491257f8fde
--- /dev/null
+++ b/venv/Lib/site-packages/isort/api.py
@@ -0,0 +1,383 @@
+import shutil
+import sys
+from io import StringIO
+from pathlib import Path
+from typing import Optional, TextIO, Union, cast
+from warnings import warn
+
+from isort import core
+
+from . import io
+from .exceptions import (
+ ExistingSyntaxErrors,
+ FileSkipComment,
+ FileSkipSetting,
+ IntroducedSyntaxErrors,
+)
+from .format import ask_whether_to_apply_changes_to_file, create_terminal_printer, show_unified_diff
+from .io import Empty
+from .place import module as place_module # noqa: F401
+from .place import module_with_reason as place_module_with_reason # noqa: F401
+from .settings import DEFAULT_CONFIG, Config
+
+
+def sort_code_string(
+ code: str,
+ extension: Optional[str] = None,
+ config: Config = DEFAULT_CONFIG,
+ file_path: Optional[Path] = None,
+ disregard_skip: bool = False,
+ show_diff: Union[bool, TextIO] = False,
+ **config_kwargs,
+):
+ """Sorts any imports within the provided code string, returning a new string with them sorted.
+
+ - **code**: The string of code with imports that need to be sorted.
+ - **extension**: The file extension that contains imports. Defaults to filename extension or py.
+ - **config**: The config object to use when sorting imports.
+ - **file_path**: The disk location where the code string was pulled from.
+ - **disregard_skip**: set to `True` if you want to ignore a skip set in config for this file.
+ - **show_diff**: If `True` the changes that need to be done will be printed to stdout, if a
+ TextIO stream is provided results will be written to it, otherwise no diff will be computed.
+ - ****config_kwargs**: Any config modifications.
+ """
+ input_stream = StringIO(code)
+ output_stream = StringIO()
+ config = _config(path=file_path, config=config, **config_kwargs)
+ sort_stream(
+ input_stream,
+ output_stream,
+ extension=extension,
+ config=config,
+ file_path=file_path,
+ disregard_skip=disregard_skip,
+ show_diff=show_diff,
+ )
+ output_stream.seek(0)
+ return output_stream.read()
+
+
+def check_code_string(
+ code: str,
+ show_diff: Union[bool, TextIO] = False,
+ extension: Optional[str] = None,
+ config: Config = DEFAULT_CONFIG,
+ file_path: Optional[Path] = None,
+ disregard_skip: bool = False,
+ **config_kwargs,
+) -> bool:
+ """Checks the order, format, and categorization of imports within the provided code string.
+ Returns `True` if everything is correct, otherwise `False`.
+
+ - **code**: The string of code with imports that need to be sorted.
+ - **show_diff**: If `True` the changes that need to be done will be printed to stdout, if a
+ TextIO stream is provided results will be written to it, otherwise no diff will be computed.
+ - **extension**: The file extension that contains imports. Defaults to filename extension or py.
+ - **config**: The config object to use when sorting imports.
+ - **file_path**: The disk location where the code string was pulled from.
+ - **disregard_skip**: set to `True` if you want to ignore a skip set in config for this file.
+ - ****config_kwargs**: Any config modifications.
+ """
+ config = _config(path=file_path, config=config, **config_kwargs)
+ return check_stream(
+ StringIO(code),
+ show_diff=show_diff,
+ extension=extension,
+ config=config,
+ file_path=file_path,
+ disregard_skip=disregard_skip,
+ )
+
+
+def sort_stream(
+ input_stream: TextIO,
+ output_stream: TextIO,
+ extension: Optional[str] = None,
+ config: Config = DEFAULT_CONFIG,
+ file_path: Optional[Path] = None,
+ disregard_skip: bool = False,
+ show_diff: Union[bool, TextIO] = False,
+ **config_kwargs,
+) -> bool:
+ """Sorts any imports within the provided code stream, outputs to the provided output stream.
+ Returns `True` if anything is modified from the original input stream, otherwise `False`.
+
+ - **input_stream**: The stream of code with imports that need to be sorted.
+ - **output_stream**: The stream where sorted imports should be written to.
+ - **extension**: The file extension that contains imports. Defaults to filename extension or py.
+ - **config**: The config object to use when sorting imports.
+ - **file_path**: The disk location where the code string was pulled from.
+ - **disregard_skip**: set to `True` if you want to ignore a skip set in config for this file.
+ - **show_diff**: If `True` the changes that need to be done will be printed to stdout, if a
+ TextIO stream is provided results will be written to it, otherwise no diff will be computed.
+ - ****config_kwargs**: Any config modifications.
+ """
+ if show_diff:
+ _output_stream = StringIO()
+ _input_stream = StringIO(input_stream.read())
+ changed = sort_stream(
+ input_stream=_input_stream,
+ output_stream=_output_stream,
+ extension=extension,
+ config=config,
+ file_path=file_path,
+ disregard_skip=disregard_skip,
+ **config_kwargs,
+ )
+ _output_stream.seek(0)
+ _input_stream.seek(0)
+ show_unified_diff(
+ file_input=_input_stream.read(),
+ file_output=_output_stream.read(),
+ file_path=file_path,
+ output=output_stream if show_diff is True else cast(TextIO, show_diff),
+ )
+ return changed
+
+ config = _config(path=file_path, config=config, **config_kwargs)
+ content_source = str(file_path or "Passed in content")
+ if not disregard_skip:
+ if file_path and config.is_skipped(file_path):
+ raise FileSkipSetting(content_source)
+
+ _internal_output = output_stream
+
+ if config.atomic:
+ try:
+ file_content = input_stream.read()
+ compile(file_content, content_source, "exec", 0, 1)
+ input_stream = StringIO(file_content)
+ except SyntaxError:
+ raise ExistingSyntaxErrors(content_source)
+
+ if not output_stream.readable():
+ _internal_output = StringIO()
+
+ try:
+ changed = core.process(
+ input_stream,
+ _internal_output,
+ extension=extension or (file_path and file_path.suffix.lstrip(".")) or "py",
+ config=config,
+ )
+ except FileSkipComment:
+ raise FileSkipComment(content_source)
+
+ if config.atomic:
+ _internal_output.seek(0)
+ try:
+ compile(_internal_output.read(), content_source, "exec", 0, 1)
+ _internal_output.seek(0)
+ if _internal_output != output_stream:
+ output_stream.write(_internal_output.read())
+ except SyntaxError: # pragma: no cover
+ raise IntroducedSyntaxErrors(content_source)
+
+ return changed
+
+
+def check_stream(
+ input_stream: TextIO,
+ show_diff: Union[bool, TextIO] = False,
+ extension: Optional[str] = None,
+ config: Config = DEFAULT_CONFIG,
+ file_path: Optional[Path] = None,
+ disregard_skip: bool = False,
+ **config_kwargs,
+) -> bool:
+ """Checks any imports within the provided code stream, returning `False` if any unsorted or
+ incorrectly imports are found or `True` if no problems are identified.
+
+ - **input_stream**: The stream of code with imports that need to be sorted.
+ - **show_diff**: If `True` the changes that need to be done will be printed to stdout, if a
+ TextIO stream is provided results will be written to it, otherwise no diff will be computed.
+ - **extension**: The file extension that contains imports. Defaults to filename extension or py.
+ - **config**: The config object to use when sorting imports.
+ - **file_path**: The disk location where the code string was pulled from.
+ - **disregard_skip**: set to `True` if you want to ignore a skip set in config for this file.
+ - ****config_kwargs**: Any config modifications.
+ """
+ config = _config(path=file_path, config=config, **config_kwargs)
+
+ changed: bool = sort_stream(
+ input_stream=input_stream,
+ output_stream=Empty,
+ extension=extension,
+ config=config,
+ file_path=file_path,
+ disregard_skip=disregard_skip,
+ )
+ printer = create_terminal_printer(color=config.color_output)
+ if not changed:
+ if config.verbose:
+ printer.success(f"{file_path or ''} Everything Looks Good!")
+ return True
+ else:
+ printer.error(f"{file_path or ''} Imports are incorrectly sorted and/or formatted.")
+ if show_diff:
+ output_stream = StringIO()
+ input_stream.seek(0)
+ file_contents = input_stream.read()
+ sort_stream(
+ input_stream=StringIO(file_contents),
+ output_stream=output_stream,
+ extension=extension,
+ config=config,
+ file_path=file_path,
+ disregard_skip=disregard_skip,
+ )
+ output_stream.seek(0)
+
+ show_unified_diff(
+ file_input=file_contents,
+ file_output=output_stream.read(),
+ file_path=file_path,
+ output=None if show_diff is True else cast(TextIO, show_diff),
+ )
+ return False
+
+
+def check_file(
+ filename: Union[str, Path],
+ show_diff: Union[bool, TextIO] = False,
+ config: Config = DEFAULT_CONFIG,
+ file_path: Optional[Path] = None,
+ disregard_skip: bool = True,
+ extension: Optional[str] = None,
+ **config_kwargs,
+) -> bool:
+ """Checks any imports within the provided file, returning `False` if any unsorted or
+ incorrectly imports are found or `True` if no problems are identified.
+
+ - **filename**: The name or Path of the file to check.
+ - **show_diff**: If `True` the changes that need to be done will be printed to stdout, if a
+ TextIO stream is provided results will be written to it, otherwise no diff will be computed.
+ - **config**: The config object to use when sorting imports.
+ - **file_path**: The disk location where the code string was pulled from.
+ - **disregard_skip**: set to `True` if you want to ignore a skip set in config for this file.
+ - **extension**: The file extension that contains imports. Defaults to filename extension or py.
+ - ****config_kwargs**: Any config modifications.
+ """
+ with io.File.read(filename) as source_file:
+ return check_stream(
+ source_file.stream,
+ show_diff=show_diff,
+ extension=extension,
+ config=config,
+ file_path=file_path or source_file.path,
+ disregard_skip=disregard_skip,
+ **config_kwargs,
+ )
+
+
+def sort_file(
+ filename: Union[str, Path],
+ extension: Optional[str] = None,
+ config: Config = DEFAULT_CONFIG,
+ file_path: Optional[Path] = None,
+ disregard_skip: bool = True,
+ ask_to_apply: bool = False,
+ show_diff: Union[bool, TextIO] = False,
+ write_to_stdout: bool = False,
+ **config_kwargs,
+) -> bool:
+ """Sorts and formats any groups of imports imports within the provided file or Path.
+ Returns `True` if the file has been changed, otherwise `False`.
+
+ - **filename**: The name or Path of the file to format.
+ - **extension**: The file extension that contains imports. Defaults to filename extension or py.
+ - **config**: The config object to use when sorting imports.
+ - **file_path**: The disk location where the code string was pulled from.
+ - **disregard_skip**: set to `True` if you want to ignore a skip set in config for this file.
+ - **ask_to_apply**: If `True`, prompt before applying any changes.
+ - **show_diff**: If `True` the changes that need to be done will be printed to stdout, if a
+ TextIO stream is provided results will be written to it, otherwise no diff will be computed.
+ - **write_to_stdout**: If `True`, write to stdout instead of the input file.
+ - ****config_kwargs**: Any config modifications.
+ """
+ with io.File.read(filename) as source_file:
+ changed: bool = False
+ try:
+ if write_to_stdout:
+ changed = sort_stream(
+ input_stream=source_file.stream,
+ output_stream=sys.stdout,
+ config=config,
+ file_path=file_path or source_file.path,
+ disregard_skip=disregard_skip,
+ extension=extension,
+ **config_kwargs,
+ )
+ else:
+ tmp_file = source_file.path.with_suffix(source_file.path.suffix + ".isorted")
+ try:
+ with tmp_file.open(
+ "w", encoding=source_file.encoding, newline=""
+ ) as output_stream:
+ shutil.copymode(filename, tmp_file)
+ changed = sort_stream(
+ input_stream=source_file.stream,
+ output_stream=output_stream,
+ config=config,
+ file_path=file_path or source_file.path,
+ disregard_skip=disregard_skip,
+ extension=extension,
+ **config_kwargs,
+ )
+ if changed:
+ if show_diff or ask_to_apply:
+ source_file.stream.seek(0)
+ with tmp_file.open(
+ encoding=source_file.encoding, newline=""
+ ) as tmp_out:
+ show_unified_diff(
+ file_input=source_file.stream.read(),
+ file_output=tmp_out.read(),
+ file_path=file_path or source_file.path,
+ output=None if show_diff is True else cast(TextIO, show_diff),
+ )
+ if show_diff or (
+ ask_to_apply
+ and not ask_whether_to_apply_changes_to_file(
+ str(source_file.path)
+ )
+ ):
+ return False
+ source_file.stream.close()
+ tmp_file.replace(source_file.path)
+ if not config.quiet:
+ print(f"Fixing {source_file.path}")
+ finally:
+ try: # Python 3.8+: use `missing_ok=True` instead of try except.
+ tmp_file.unlink()
+ except FileNotFoundError:
+ pass
+ except ExistingSyntaxErrors:
+ warn(f"{file_path} unable to sort due to existing syntax errors")
+ except IntroducedSyntaxErrors: # pragma: no cover
+ warn(f"{file_path} unable to sort as isort introduces new syntax errors")
+
+ return changed
+
+
+def _config(
+ path: Optional[Path] = None, config: Config = DEFAULT_CONFIG, **config_kwargs
+) -> Config:
+ if path:
+ if (
+ config is DEFAULT_CONFIG
+ and "settings_path" not in config_kwargs
+ and "settings_file" not in config_kwargs
+ ):
+ config_kwargs["settings_path"] = path
+
+ if config_kwargs:
+ if config is not DEFAULT_CONFIG:
+ raise ValueError(
+ "You can either specify custom configuration options using kwargs or "
+ "passing in a Config object. Not Both!"
+ )
+
+ config = Config(**config_kwargs)
+
+ return config
diff --git a/venv/Lib/site-packages/isort/comments.py b/venv/Lib/site-packages/isort/comments.py
new file mode 100644
index 0000000000000000000000000000000000000000..b865b32813e6d945fed9a903065c0788803a3d55
--- /dev/null
+++ b/venv/Lib/site-packages/isort/comments.py
@@ -0,0 +1,32 @@
+from typing import List, Optional, Tuple
+
+
+def parse(line: str) -> Tuple[str, str]:
+ """Parses import lines for comments and returns back the
+ import statement and the associated comment.
+ """
+ comment_start = line.find("#")
+ if comment_start != -1:
+ return (line[:comment_start], line[comment_start + 1 :].strip())
+
+ return (line, "")
+
+
+def add_to_line(
+ comments: Optional[List[str]],
+ original_string: str = "",
+ removed: bool = False,
+ comment_prefix: str = "",
+) -> str:
+ """Returns a string with comments added if removed is not set."""
+ if removed:
+ return parse(original_string)[0]
+
+ if not comments:
+ return original_string
+ else:
+ unique_comments: List[str] = []
+ for comment in comments:
+ if comment not in unique_comments:
+ unique_comments.append(comment)
+ return f"{parse(original_string)[0]}{comment_prefix} {'; '.join(unique_comments)}"
diff --git a/venv/Lib/site-packages/isort/core.py b/venv/Lib/site-packages/isort/core.py
new file mode 100644
index 0000000000000000000000000000000000000000..010aa7f6b5fc4c157a5fc8a30df56eb81d1f719a
--- /dev/null
+++ b/venv/Lib/site-packages/isort/core.py
@@ -0,0 +1,386 @@
+import textwrap
+from io import StringIO
+from itertools import chain
+from typing import List, TextIO, Union
+
+import isort.literal
+from isort.settings import DEFAULT_CONFIG, Config
+
+from . import output, parse
+from .exceptions import FileSkipComment
+from .format import format_natural, remove_whitespace
+from .settings import FILE_SKIP_COMMENTS
+
+CIMPORT_IDENTIFIERS = ("cimport ", "cimport*", "from.cimport")
+IMPORT_START_IDENTIFIERS = ("from ", "from.import", "import ", "import*") + CIMPORT_IDENTIFIERS
+COMMENT_INDICATORS = ('"""', "'''", "'", '"', "#")
+CODE_SORT_COMMENTS = (
+ "# isort: list",
+ "# isort: dict",
+ "# isort: set",
+ "# isort: unique-list",
+ "# isort: tuple",
+ "# isort: unique-tuple",
+ "# isort: assignments",
+)
+
+
+def process(
+ input_stream: TextIO,
+ output_stream: TextIO,
+ extension: str = "py",
+ config: Config = DEFAULT_CONFIG,
+) -> bool:
+ """Parses stream identifying sections of contiguous imports and sorting them
+
+ Code with unsorted imports is read from the provided `input_stream`, sorted and then
+ outputted to the specified `output_stream`.
+
+ - `input_stream`: Text stream with unsorted import sections.
+ - `output_stream`: Text stream to output sorted inputs into.
+ - `config`: Config settings to use when sorting imports. Defaults settings.
+ - *Default*: `isort.settings.DEFAULT_CONFIG`.
+ - `extension`: The file extension or file extension rules that should be used.
+ - *Default*: `"py"`.
+ - *Choices*: `["py", "pyi", "pyx"]`.
+
+ Returns `True` if there were changes that needed to be made (errors present) from what
+ was provided in the input_stream, otherwise `False`.
+ """
+ line_separator: str = config.line_ending
+ add_imports: List[str] = [format_natural(addition) for addition in config.add_imports]
+ import_section: str = ""
+ next_import_section: str = ""
+ next_cimports: bool = False
+ in_quote: str = ""
+ first_comment_index_start: int = -1
+ first_comment_index_end: int = -1
+ contains_imports: bool = False
+ in_top_comment: bool = False
+ first_import_section: bool = True
+ section_comments = [f"# {heading}" for heading in config.import_headings.values()]
+ indent: str = ""
+ isort_off: bool = False
+ code_sorting: Union[bool, str] = False
+ code_sorting_section: str = ""
+ code_sorting_indent: str = ""
+ cimports: bool = False
+ made_changes: bool = False
+
+ if config.float_to_top:
+ new_input = ""
+ current = ""
+ isort_off = False
+ for line in chain(input_stream, (None,)):
+ if isort_off and line is not None:
+ if line == "# isort: on\n":
+ isort_off = False
+ new_input += line
+ elif line in ("# isort: split\n", "# isort: off\n", None) or str(line).endswith(
+ "# isort: split\n"
+ ):
+ if line == "# isort: off\n":
+ isort_off = True
+ if current:
+ parsed = parse.file_contents(current, config=config)
+ extra_space = ""
+ while current[-1] == "\n":
+ extra_space += "\n"
+ current = current[:-1]
+ extra_space = extra_space.replace("\n", "", 1)
+ sorted_output = output.sorted_imports(
+ parsed, config, extension, import_type="import"
+ )
+ made_changes = made_changes or _has_changed(
+ before=current,
+ after=sorted_output,
+ line_separator=parsed.line_separator,
+ ignore_whitespace=config.ignore_whitespace,
+ )
+ new_input += sorted_output
+ new_input += extra_space
+ current = ""
+ new_input += line or ""
+ else:
+ current += line or ""
+
+ input_stream = StringIO(new_input)
+
+ for index, line in enumerate(chain(input_stream, (None,))):
+ if line is None:
+ if index == 0 and not config.force_adds:
+ return False
+
+ not_imports = True
+ line = ""
+ if not line_separator:
+ line_separator = "\n"
+
+ if code_sorting and code_sorting_section:
+ output_stream.write(
+ textwrap.indent(
+ isort.literal.assignment(
+ code_sorting_section,
+ str(code_sorting),
+ extension,
+ config=_indented_config(config, indent),
+ ),
+ code_sorting_indent,
+ )
+ )
+ else:
+ stripped_line = line.strip()
+ if stripped_line and not line_separator:
+ line_separator = line[len(line.rstrip()) :].replace(" ", "").replace("\t", "")
+
+ for file_skip_comment in FILE_SKIP_COMMENTS:
+ if file_skip_comment in line:
+ raise FileSkipComment("Passed in content")
+
+ if (
+ (index == 0 or (index in (1, 2) and not contains_imports))
+ and stripped_line.startswith("#")
+ and stripped_line not in section_comments
+ ):
+ in_top_comment = True
+ elif in_top_comment:
+ if not line.startswith("#") or stripped_line in section_comments:
+ in_top_comment = False
+ first_comment_index_end = index - 1
+
+ if (not stripped_line.startswith("#") or in_quote) and '"' in line or "'" in line:
+ char_index = 0
+ if first_comment_index_start == -1 and (
+ line.startswith('"') or line.startswith("'")
+ ):
+ first_comment_index_start = index
+ while char_index < len(line):
+ if line[char_index] == "\\":
+ char_index += 1
+ elif in_quote:
+ if line[char_index : char_index + len(in_quote)] == in_quote:
+ in_quote = ""
+ if first_comment_index_end < first_comment_index_start:
+ first_comment_index_end = index
+ elif line[char_index] in ("'", '"'):
+ long_quote = line[char_index : char_index + 3]
+ if long_quote in ('"""', "'''"):
+ in_quote = long_quote
+ char_index += 2
+ else:
+ in_quote = line[char_index]
+ elif line[char_index] == "#":
+ break
+ char_index += 1
+
+ not_imports = bool(in_quote) or in_top_comment or isort_off
+ if not (in_quote or in_top_comment):
+ stripped_line = line.strip()
+ if isort_off:
+ if stripped_line == "# isort: on":
+ isort_off = False
+ elif stripped_line == "# isort: off":
+ not_imports = True
+ isort_off = True
+ elif stripped_line.endswith("# isort: split"):
+ not_imports = True
+ elif stripped_line in CODE_SORT_COMMENTS:
+ code_sorting = stripped_line.split("isort: ")[1].strip()
+ code_sorting_indent = line[: -len(line.lstrip())]
+ not_imports = True
+ elif code_sorting:
+ if not stripped_line:
+ output_stream.write(
+ textwrap.indent(
+ isort.literal.assignment(
+ code_sorting_section,
+ str(code_sorting),
+ extension,
+ config=_indented_config(config, indent),
+ ),
+ code_sorting_indent,
+ )
+ )
+ not_imports = True
+ code_sorting = False
+ code_sorting_section = ""
+ code_sorting_indent = ""
+ else:
+ code_sorting_section += line
+ line = ""
+ elif stripped_line in config.section_comments and not import_section:
+ import_section += line
+ indent = line[: -len(line.lstrip())]
+ elif not (stripped_line or contains_imports):
+ if add_imports and not indent and not config.append_only:
+ if not import_section:
+ output_stream.write(line)
+ line = ""
+ import_section += line_separator.join(add_imports) + line_separator
+ contains_imports = True
+ add_imports = []
+ else:
+ not_imports = True
+ elif (
+ not stripped_line
+ or stripped_line.startswith("#")
+ and (not indent or indent + line.lstrip() == line)
+ and not config.treat_all_comments_as_code
+ and stripped_line not in config.treat_comments_as_code
+ ):
+ import_section += line
+ elif stripped_line.startswith(IMPORT_START_IDENTIFIERS):
+ contains_imports = True
+
+ new_indent = line[: -len(line.lstrip())]
+ import_statement = line
+ stripped_line = line.strip().split("#")[0]
+ while stripped_line.endswith("\\") or (
+ "(" in stripped_line and ")" not in stripped_line
+ ):
+ if stripped_line.endswith("\\"):
+ while stripped_line and stripped_line.endswith("\\"):
+ line = input_stream.readline()
+ stripped_line = line.strip().split("#")[0]
+ import_statement += line
+ else:
+ while ")" not in stripped_line:
+ line = input_stream.readline()
+ stripped_line = line.strip().split("#")[0]
+ import_statement += line
+
+ cimport_statement: bool = False
+ if (
+ import_statement.lstrip().startswith(CIMPORT_IDENTIFIERS)
+ or " cimport " in import_statement
+ or " cimport*" in import_statement
+ or " cimport(" in import_statement
+ or ".cimport" in import_statement
+ ):
+ cimport_statement = True
+
+ if cimport_statement != cimports or (new_indent != indent and import_section):
+ if import_section:
+ next_cimports = cimport_statement
+ next_import_section = import_statement
+ import_statement = ""
+ not_imports = True
+ line = ""
+ else:
+ cimports = cimport_statement
+
+ indent = new_indent
+ import_section += import_statement
+ else:
+ not_imports = True
+
+ if not_imports:
+ raw_import_section: str = import_section
+ if (
+ add_imports
+ and not config.append_only
+ and not in_top_comment
+ and not in_quote
+ and not import_section
+ and not line.lstrip().startswith(COMMENT_INDICATORS)
+ ):
+ import_section = line_separator.join(add_imports) + line_separator
+ contains_imports = True
+ add_imports = []
+
+ if next_import_section and not import_section: # pragma: no cover
+ raw_import_section = import_section = next_import_section
+ next_import_section = ""
+
+ if import_section:
+ if add_imports and not indent:
+ import_section = (
+ line_separator.join(add_imports) + line_separator + import_section
+ )
+ contains_imports = True
+ add_imports = []
+
+ if not indent:
+ import_section += line
+ raw_import_section += line
+ if not contains_imports:
+ output_stream.write(import_section)
+ else:
+ leading_whitespace = import_section[: -len(import_section.lstrip())]
+ trailing_whitespace = import_section[len(import_section.rstrip()) :]
+ if first_import_section and not import_section.lstrip(
+ line_separator
+ ).startswith(COMMENT_INDICATORS):
+ import_section = import_section.lstrip(line_separator)
+ raw_import_section = raw_import_section.lstrip(line_separator)
+ first_import_section = False
+
+ if indent:
+ import_section = "".join(
+ line[len(indent) :] for line in import_section.splitlines(keepends=True)
+ )
+
+ sorted_import_section = output.sorted_imports(
+ parse.file_contents(import_section, config=config),
+ _indented_config(config, indent),
+ extension,
+ import_type="cimport" if cimports else "import",
+ )
+ if not (import_section.strip() and not sorted_import_section):
+ if indent:
+ sorted_import_section = (
+ leading_whitespace
+ + textwrap.indent(sorted_import_section, indent).strip()
+ + trailing_whitespace
+ )
+
+ made_changes = made_changes or _has_changed(
+ before=raw_import_section,
+ after=sorted_import_section,
+ line_separator=line_separator,
+ ignore_whitespace=config.ignore_whitespace,
+ )
+
+ output_stream.write(sorted_import_section)
+ if not line and not indent and next_import_section:
+ output_stream.write(line_separator)
+
+ if indent:
+ output_stream.write(line)
+ if not next_import_section:
+ indent = ""
+
+ if next_import_section:
+ cimports = next_cimports
+ contains_imports = True
+ else:
+ contains_imports = False
+ import_section = next_import_section
+ next_import_section = ""
+ else:
+ output_stream.write(line)
+ not_imports = False
+
+ return made_changes
+
+
+def _indented_config(config: Config, indent: str):
+ if not indent:
+ return config
+
+ return Config(
+ config=config,
+ line_length=max(config.line_length - len(indent), 0),
+ wrap_length=max(config.wrap_length - len(indent), 0),
+ lines_after_imports=1,
+ )
+
+
+def _has_changed(before: str, after: str, line_separator: str, ignore_whitespace: bool) -> bool:
+ if ignore_whitespace:
+ return (
+ remove_whitespace(before, line_separator=line_separator).strip()
+ != remove_whitespace(after, line_separator=line_separator).strip()
+ )
+ else:
+ return before.strip() != after.strip()
diff --git a/venv/Lib/site-packages/isort/deprecated/__init__.py b/venv/Lib/site-packages/isort/deprecated/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/venv/Lib/site-packages/isort/deprecated/finders.py b/venv/Lib/site-packages/isort/deprecated/finders.py
new file mode 100644
index 0000000000000000000000000000000000000000..77eb23fa43340de525b56a66d75a8c78c0c60b20
--- /dev/null
+++ b/venv/Lib/site-packages/isort/deprecated/finders.py
@@ -0,0 +1,403 @@
+"""Finders try to find right section for passed module name"""
+import importlib.machinery
+import inspect
+import os
+import os.path
+import re
+import sys
+import sysconfig
+from abc import ABCMeta, abstractmethod
+from fnmatch import fnmatch
+from functools import lru_cache
+from glob import glob
+from pathlib import Path
+from typing import Dict, Iterable, Iterator, List, Optional, Pattern, Sequence, Tuple, Type
+
+from isort import sections
+from isort.settings import KNOWN_SECTION_MAPPING, Config
+from isort.utils import chdir, exists_case_sensitive
+
+try:
+ from pipreqs import pipreqs
+
+except ImportError:
+ pipreqs = None
+
+try:
+ from pip_api import parse_requirements
+
+except ImportError:
+ parse_requirements = None
+
+try:
+ from requirementslib import Pipfile
+
+except ImportError:
+ Pipfile = None
+
+
+class BaseFinder(metaclass=ABCMeta):
+ def __init__(self, config: Config) -> None:
+ self.config = config
+
+ @abstractmethod
+ def find(self, module_name: str) -> Optional[str]:
+ raise NotImplementedError
+
+
+class ForcedSeparateFinder(BaseFinder):
+ def find(self, module_name: str) -> Optional[str]:
+ for forced_separate in self.config.forced_separate:
+ # Ensure all forced_separate patterns will match to end of string
+ path_glob = forced_separate
+ if not forced_separate.endswith("*"):
+ path_glob = "%s*" % forced_separate
+
+ if fnmatch(module_name, path_glob) or fnmatch(module_name, "." + path_glob):
+ return forced_separate
+ return None
+
+
+class LocalFinder(BaseFinder):
+ def find(self, module_name: str) -> Optional[str]:
+ if module_name.startswith("."):
+ return "LOCALFOLDER"
+ return None
+
+
+class KnownPatternFinder(BaseFinder):
+ def __init__(self, config: Config) -> None:
+ super().__init__(config)
+
+ self.known_patterns: List[Tuple[Pattern[str], str]] = []
+ for placement in reversed(config.sections):
+ known_placement = KNOWN_SECTION_MAPPING.get(placement, placement).lower()
+ config_key = f"known_{known_placement}"
+ known_patterns = list(
+ getattr(self.config, config_key, self.config.known_other.get(known_placement, []))
+ )
+ known_patterns = [
+ pattern
+ for known_pattern in known_patterns
+ for pattern in self._parse_known_pattern(known_pattern)
+ ]
+ for known_pattern in known_patterns:
+ regexp = "^" + known_pattern.replace("*", ".*").replace("?", ".?") + "$"
+ self.known_patterns.append((re.compile(regexp), placement))
+
+ def _parse_known_pattern(self, pattern: str) -> List[str]:
+ """Expand pattern if identified as a directory and return found sub packages"""
+ if pattern.endswith(os.path.sep):
+ patterns = [
+ filename
+ for filename in os.listdir(os.path.join(self.config.directory, pattern))
+ if os.path.isdir(os.path.join(self.config.directory, pattern, filename))
+ ]
+ else:
+ patterns = [pattern]
+
+ return patterns
+
+ def find(self, module_name: str) -> Optional[str]:
+ # Try to find most specific placement instruction match (if any)
+ parts = module_name.split(".")
+ module_names_to_check = (".".join(parts[:first_k]) for first_k in range(len(parts), 0, -1))
+ for module_name_to_check in module_names_to_check:
+ for pattern, placement in self.known_patterns:
+ if pattern.match(module_name_to_check):
+ return placement
+ return None
+
+
+class PathFinder(BaseFinder):
+ def __init__(self, config: Config, path: str = ".") -> None:
+ super().__init__(config)
+
+ # restore the original import path (i.e. not the path to bin/isort)
+ root_dir = os.path.abspath(path)
+ src_dir = f"{root_dir}/src"
+ self.paths = [root_dir, src_dir]
+
+ # virtual env
+ self.virtual_env = self.config.virtual_env or os.environ.get("VIRTUAL_ENV")
+ if self.virtual_env:
+ self.virtual_env = os.path.realpath(self.virtual_env)
+ self.virtual_env_src = ""
+ if self.virtual_env:
+ self.virtual_env_src = f"{self.virtual_env}/src/"
+ for venv_path in glob(f"{self.virtual_env}/lib/python*/site-packages"):
+ if venv_path not in self.paths:
+ self.paths.append(venv_path)
+ for nested_venv_path in glob(f"{self.virtual_env}/lib/python*/*/site-packages"):
+ if nested_venv_path not in self.paths:
+ self.paths.append(nested_venv_path)
+ for venv_src_path in glob(f"{self.virtual_env}/src/*"):
+ if os.path.isdir(venv_src_path):
+ self.paths.append(venv_src_path)
+
+ # conda
+ self.conda_env = self.config.conda_env or os.environ.get("CONDA_PREFIX") or ""
+ if self.conda_env:
+ self.conda_env = os.path.realpath(self.conda_env)
+ for conda_path in glob(f"{self.conda_env}/lib/python*/site-packages"):
+ if conda_path not in self.paths:
+ self.paths.append(conda_path)
+ for nested_conda_path in glob(f"{self.conda_env}/lib/python*/*/site-packages"):
+ if nested_conda_path not in self.paths:
+ self.paths.append(nested_conda_path)
+
+ # handle case-insensitive paths on windows
+ self.stdlib_lib_prefix = os.path.normcase(sysconfig.get_paths()["stdlib"])
+ if self.stdlib_lib_prefix not in self.paths:
+ self.paths.append(self.stdlib_lib_prefix)
+
+ # add system paths
+ for system_path in sys.path[1:]:
+ if system_path not in self.paths:
+ self.paths.append(system_path)
+
+ def find(self, module_name: str) -> Optional[str]:
+ for prefix in self.paths:
+ package_path = "/".join((prefix, module_name.split(".")[0]))
+ path_obj = Path(package_path).resolve()
+ is_module = (
+ exists_case_sensitive(package_path + ".py")
+ or any(
+ exists_case_sensitive(package_path + ext_suffix)
+ for ext_suffix in importlib.machinery.EXTENSION_SUFFIXES
+ )
+ or exists_case_sensitive(package_path + "/__init__.py")
+ )
+ is_package = exists_case_sensitive(package_path) and os.path.isdir(package_path)
+ if is_module or is_package:
+ if (
+ "site-packages" in prefix
+ or "dist-packages" in prefix
+ or (self.virtual_env and self.virtual_env_src in prefix)
+ ):
+ return sections.THIRDPARTY
+ elif os.path.normcase(prefix) == self.stdlib_lib_prefix:
+ return sections.STDLIB
+ elif self.conda_env and self.conda_env in prefix:
+ return sections.THIRDPARTY
+ for src_path in self.config.src_paths:
+ if src_path in path_obj.parents and not self.config.is_skipped(path_obj):
+ return sections.FIRSTPARTY
+
+ if os.path.normcase(prefix).startswith(self.stdlib_lib_prefix):
+ return sections.STDLIB # pragma: no cover - edge case for one OS. Hard to test.
+
+ return self.config.default_section
+ return None
+
+
+class ReqsBaseFinder(BaseFinder):
+ enabled = False
+
+ def __init__(self, config: Config, path: str = ".") -> None:
+ super().__init__(config)
+ self.path = path
+ if self.enabled:
+ self.mapping = self._load_mapping()
+ self.names = self._load_names()
+
+ @abstractmethod
+ def _get_names(self, path: str) -> Iterator[str]:
+ raise NotImplementedError
+
+ @abstractmethod
+ def _get_files_from_dir(self, path: str) -> Iterator[str]:
+ raise NotImplementedError
+
+ @staticmethod
+ def _load_mapping() -> Optional[Dict[str, str]]:
+ """Return list of mappings `package_name -> module_name`
+
+ Example:
+ django-haystack -> haystack
+ """
+ if not pipreqs:
+ return None
+ path = os.path.dirname(inspect.getfile(pipreqs))
+ path = os.path.join(path, "mapping")
+ with open(path) as f:
+ mappings: Dict[str, str] = {} # pypi_name: import_name
+ for line in f:
+ import_name, _, pypi_name = line.strip().partition(":")
+ mappings[pypi_name] = import_name
+ return mappings
+ # return dict(tuple(line.strip().split(":")[::-1]) for line in f)
+
+ def _load_names(self) -> List[str]:
+ """Return list of thirdparty modules from requirements"""
+ names = []
+ for path in self._get_files():
+ for name in self._get_names(path):
+ names.append(self._normalize_name(name))
+ return names
+
+ @staticmethod
+ def _get_parents(path: str) -> Iterator[str]:
+ prev = ""
+ while path != prev:
+ prev = path
+ yield path
+ path = os.path.dirname(path)
+
+ def _get_files(self) -> Iterator[str]:
+ """Return paths to all requirements files"""
+ path = os.path.abspath(self.path)
+ if os.path.isfile(path):
+ path = os.path.dirname(path)
+
+ for path in self._get_parents(path):
+ yield from self._get_files_from_dir(path)
+
+ def _normalize_name(self, name: str) -> str:
+ """Convert package name to module name
+
+ Examples:
+ Django -> django
+ django-haystack -> django_haystack
+ Flask-RESTFul -> flask_restful
+ """
+ if self.mapping:
+ name = self.mapping.get(name.replace("-", "_"), name)
+ return name.lower().replace("-", "_")
+
+ def find(self, module_name: str) -> Optional[str]:
+ # required lib not installed yet
+ if not self.enabled:
+ return None
+
+ module_name, _sep, _submodules = module_name.partition(".")
+ module_name = module_name.lower()
+ if not module_name:
+ return None
+
+ for name in self.names:
+ if module_name == name:
+ return sections.THIRDPARTY
+ return None
+
+
+class RequirementsFinder(ReqsBaseFinder):
+ exts = (".txt", ".in")
+ enabled = bool(parse_requirements)
+
+ def _get_files_from_dir(self, path: str) -> Iterator[str]:
+ """Return paths to requirements files from passed dir."""
+ yield from self._get_files_from_dir_cached(path)
+
+ @classmethod
+ @lru_cache(maxsize=16)
+ def _get_files_from_dir_cached(cls, path: str) -> List[str]:
+ results = []
+
+ for fname in os.listdir(path):
+ if "requirements" not in fname:
+ continue
+ full_path = os.path.join(path, fname)
+
+ # *requirements*/*.{txt,in}
+ if os.path.isdir(full_path):
+ for subfile_name in os.listdir(full_path):
+ for ext in cls.exts:
+ if subfile_name.endswith(ext):
+ results.append(os.path.join(full_path, subfile_name))
+ continue
+
+ # *requirements*.{txt,in}
+ if os.path.isfile(full_path):
+ for ext in cls.exts:
+ if fname.endswith(ext):
+ results.append(full_path)
+ break
+
+ return results
+
+ def _get_names(self, path: str) -> Iterator[str]:
+ """Load required packages from path to requirements file"""
+ yield from self._get_names_cached(path)
+
+ @classmethod
+ @lru_cache(maxsize=16)
+ def _get_names_cached(cls, path: str) -> List[str]:
+ result = []
+
+ with chdir(os.path.dirname(path)):
+ requirements = parse_requirements(path)
+ for req in requirements.values():
+ if req.name:
+ result.append(req.name)
+
+ return result
+
+
+class PipfileFinder(ReqsBaseFinder):
+ enabled = bool(Pipfile)
+
+ def _get_names(self, path: str) -> Iterator[str]:
+ with chdir(path):
+ project = Pipfile.load(path)
+ for req in project.packages:
+ yield req.name
+
+ def _get_files_from_dir(self, path: str) -> Iterator[str]:
+ if "Pipfile" in os.listdir(path):
+ yield path
+
+
+class DefaultFinder(BaseFinder):
+ def find(self, module_name: str) -> Optional[str]:
+ return self.config.default_section
+
+
+class FindersManager:
+ _default_finders_classes: Sequence[Type[BaseFinder]] = (
+ ForcedSeparateFinder,
+ LocalFinder,
+ KnownPatternFinder,
+ PathFinder,
+ PipfileFinder,
+ RequirementsFinder,
+ DefaultFinder,
+ )
+
+ def __init__(
+ self, config: Config, finder_classes: Optional[Iterable[Type[BaseFinder]]] = None
+ ) -> None:
+ self.verbose: bool = config.verbose
+
+ if finder_classes is None:
+ finder_classes = self._default_finders_classes
+ finders: List[BaseFinder] = []
+ for finder_cls in finder_classes:
+ try:
+ finders.append(finder_cls(config))
+ except Exception as exception:
+ # if one finder fails to instantiate isort can continue using the rest
+ if self.verbose:
+ print(
+ (
+ f"{finder_cls.__name__} encountered an error ({exception}) during "
+ "instantiation and cannot be used"
+ )
+ )
+ self.finders: Tuple[BaseFinder, ...] = tuple(finders)
+
+ def find(self, module_name: str) -> Optional[str]:
+ for finder in self.finders:
+ try:
+ section = finder.find(module_name)
+ if section is not None:
+ return section
+ except Exception as exception:
+ # isort has to be able to keep trying to identify the correct
+ # import section even if one approach fails
+ if self.verbose:
+ print(
+ f"{finder.__class__.__name__} encountered an error ({exception}) while "
+ f"trying to identify the {module_name} module"
+ )
+ return None
diff --git a/venv/Lib/site-packages/isort/exceptions.py b/venv/Lib/site-packages/isort/exceptions.py
new file mode 100644
index 0000000000000000000000000000000000000000..9f45744c7e5fb4359d9066df693e214596669122
--- /dev/null
+++ b/venv/Lib/site-packages/isort/exceptions.py
@@ -0,0 +1,134 @@
+"""All isort specific exception classes should be defined here"""
+from .profiles import profiles
+
+
+class ISortError(Exception):
+ """Base isort exception object from which all isort sourced exceptions should inherit"""
+
+
+class InvalidSettingsPath(ISortError):
+ """Raised when a settings path is provided that is neither a valid file or directory"""
+
+ def __init__(self, settings_path: str):
+ super().__init__(
+ f"isort was told to use the settings_path: {settings_path} as the base directory or "
+ "file that represents the starting point of config file discovery, but it does not "
+ "exist."
+ )
+ self.settings_path = settings_path
+
+
+class ExistingSyntaxErrors(ISortError):
+ """Raised when isort is told to sort imports within code that has existing syntax errors"""
+
+ def __init__(self, file_path: str):
+ super().__init__(
+ f"isort was told to sort imports within code that contains syntax errors: "
+ f"{file_path}."
+ )
+ self.file_path = file_path
+
+
+class IntroducedSyntaxErrors(ISortError):
+ """Raised when isort has introduced a syntax error in the process of sorting imports"""
+
+ def __init__(self, file_path: str):
+ super().__init__(
+ f"isort introduced syntax errors when attempting to sort the imports contained within "
+ f"{file_path}."
+ )
+ self.file_path = file_path
+
+
+class FileSkipped(ISortError):
+ """Should be raised when a file is skipped for any reason"""
+
+ def __init__(self, message: str, file_path: str):
+ super().__init__(message)
+ self.file_path = file_path
+
+
+class FileSkipComment(FileSkipped):
+ """Raised when an entire file is skipped due to a isort skip file comment"""
+
+ def __init__(self, file_path: str):
+ super().__init__(
+ f"{file_path} contains an file skip comment and was skipped.", file_path=file_path
+ )
+
+
+class FileSkipSetting(FileSkipped):
+ """Raised when an entire file is skipped due to provided isort settings"""
+
+ def __init__(self, file_path: str):
+ super().__init__(
+ f"{file_path} was skipped as it's listed in 'skip' setting"
+ " or matches a glob in 'skip_glob' setting",
+ file_path=file_path,
+ )
+
+
+class ProfileDoesNotExist(ISortError):
+ """Raised when a profile is set by the user that doesn't exist"""
+
+ def __init__(self, profile: str):
+ super().__init__(
+ f"Specified profile of {profile} does not exist. "
+ f"Available profiles: {','.join(profiles)}."
+ )
+ self.profile = profile
+
+
+class FormattingPluginDoesNotExist(ISortError):
+ """Raised when a formatting plugin is set by the user that doesn't exist"""
+
+ def __init__(self, formatter: str):
+ super().__init__(f"Specified formatting plugin of {formatter} does not exist. ")
+ self.formatter = formatter
+
+
+class LiteralParsingFailure(ISortError):
+ """Raised when one of isorts literal sorting comments is used but isort can't parse the
+ the given data structure.
+ """
+
+ def __init__(self, code: str, original_error: Exception):
+ super().__init__(
+ f"isort failed to parse the given literal {code}. It's important to note "
+ "that isort literal sorting only supports simple literals parsable by "
+ f"ast.literal_eval which gave the exception of {original_error}."
+ )
+ self.code = code
+ self.original_error = original_error
+
+
+class LiteralSortTypeMismatch(ISortError):
+ """Raised when an isort literal sorting comment is used, with a type that doesn't match the
+ supplied data structure's type.
+ """
+
+ def __init__(self, kind: type, expected_kind: type):
+ super().__init__(
+ f"isort was told to sort a literal of type {expected_kind} but was given "
+ f"a literal of type {kind}."
+ )
+ self.kind = kind
+ self.expected_kind = expected_kind
+
+
+class AssignmentsFormatMismatch(ISortError):
+ """Raised when isort is told to sort assignments but the format of the assignment section
+ doesn't match isort's expectation.
+ """
+
+ def __init__(self, code: str):
+ super().__init__(
+ "isort was told to sort a section of assignments, however the given code:\n\n"
+ f"{code}\n\n"
+ "Does not match isort's strict single line formatting requirement for assignment "
+ "sorting:\n\n"
+ "{variable_name} = {value}\n"
+ "{variable_name2} = {value2}\n"
+ "...\n\n"
+ )
+ self.code = code
diff --git a/venv/Lib/site-packages/isort/format.py b/venv/Lib/site-packages/isort/format.py
new file mode 100644
index 0000000000000000000000000000000000000000..3dbb19570825a9d0356ef628ad4636397694199b
--- /dev/null
+++ b/venv/Lib/site-packages/isort/format.py
@@ -0,0 +1,121 @@
+import sys
+from datetime import datetime
+from difflib import unified_diff
+from pathlib import Path
+from typing import Optional, TextIO
+
+try:
+ import colorama
+except ImportError:
+ colorama_unavailable = True
+else:
+ colorama_unavailable = False
+ colorama.init()
+
+
+def format_simplified(import_line: str) -> str:
+ import_line = import_line.strip()
+ if import_line.startswith("from "):
+ import_line = import_line.replace("from ", "")
+ import_line = import_line.replace(" import ", ".")
+ elif import_line.startswith("import "):
+ import_line = import_line.replace("import ", "")
+
+ return import_line
+
+
+def format_natural(import_line: str) -> str:
+ import_line = import_line.strip()
+ if not import_line.startswith("from ") and not import_line.startswith("import "):
+ if "." not in import_line:
+ return f"import {import_line}"
+ parts = import_line.split(".")
+ end = parts.pop(-1)
+ return f"from {'.'.join(parts)} import {end}"
+
+ return import_line
+
+
+def show_unified_diff(
+ *, file_input: str, file_output: str, file_path: Optional[Path], output: Optional[TextIO] = None
+):
+ """Shows a unified_diff for the provided input and output against the provided file path.
+
+ - **file_input**: A string that represents the contents of a file before changes.
+ - **file_output**: A string that represents the contents of a file after changes.
+ - **file_path**: A Path object that represents the file path of the file being changed.
+ - **output**: A stream to output the diff to. If non is provided uses sys.stdout.
+ """
+ output = sys.stdout if output is None else output
+ file_name = "" if file_path is None else str(file_path)
+ file_mtime = str(
+ datetime.now() if file_path is None else datetime.fromtimestamp(file_path.stat().st_mtime)
+ )
+ unified_diff_lines = unified_diff(
+ file_input.splitlines(keepends=True),
+ file_output.splitlines(keepends=True),
+ fromfile=file_name + ":before",
+ tofile=file_name + ":after",
+ fromfiledate=file_mtime,
+ tofiledate=str(datetime.now()),
+ )
+ for line in unified_diff_lines:
+ output.write(line)
+
+
+def ask_whether_to_apply_changes_to_file(file_path: str) -> bool:
+ answer = None
+ while answer not in ("yes", "y", "no", "n", "quit", "q"):
+ answer = input(f"Apply suggested changes to '{file_path}' [y/n/q]? ") # nosec
+ answer = answer.lower()
+ if answer in ("no", "n"):
+ return False
+ if answer in ("quit", "q"):
+ sys.exit(1)
+ return True
+
+
+def remove_whitespace(content: str, line_separator: str = "\n") -> str:
+ content = content.replace(line_separator, "").replace(" ", "").replace("\x0c", "")
+ return content
+
+
+class BasicPrinter:
+ ERROR = "ERROR"
+ SUCCESS = "SUCCESS"
+
+ def success(self, message: str) -> None:
+ print(f"{self.SUCCESS}: {message}")
+
+ def error(self, message: str) -> None:
+ print(
+ f"{self.ERROR}: {message}",
+ # TODO this should print to stderr, but don't want to make it backward incompatible now
+ # file=sys.stderr
+ )
+
+
+class ColoramaPrinter(BasicPrinter):
+ def __init__(self):
+ self.ERROR = self.style_text("ERROR", colorama.Fore.RED)
+ self.SUCCESS = self.style_text("SUCCESS", colorama.Fore.GREEN)
+
+ @staticmethod
+ def style_text(text: str, style: str) -> str:
+ return style + text + colorama.Style.RESET_ALL
+
+
+def create_terminal_printer(color: bool):
+ if color and colorama_unavailable:
+ no_colorama_message = (
+ "\n"
+ "Sorry, but to use --color (color_output) the colorama python package is required.\n\n"
+ "Reference: https://pypi.org/project/colorama/\n\n"
+ "You can either install it separately on your system or as the colors extra "
+ "for isort. Ex: \n\n"
+ "$ pip install isort[colors]\n"
+ )
+ print(no_colorama_message, file=sys.stderr)
+ sys.exit(1)
+
+ return ColoramaPrinter() if color else BasicPrinter()
diff --git a/venv/Lib/site-packages/isort/hooks.py b/venv/Lib/site-packages/isort/hooks.py
new file mode 100644
index 0000000000000000000000000000000000000000..3198a1d097bb98fdf04650a71f952076a49ca761
--- /dev/null
+++ b/venv/Lib/site-packages/isort/hooks.py
@@ -0,0 +1,80 @@
+"""Defines a git hook to allow pre-commit warnings and errors about import order.
+
+usage:
+ exit_code = git_hook(strict=True|False, modify=True|False)
+"""
+import os
+import subprocess # nosec - Needed for hook
+from pathlib import Path
+from typing import List
+
+from isort import Config, api, exceptions
+
+
+def get_output(command: List[str]) -> str:
+ """
+ Run a command and return raw output
+
+ :param str command: the command to run
+ :returns: the stdout output of the command
+ """
+ result = subprocess.run(command, stdout=subprocess.PIPE, check=True) # nosec - trusted input
+ return result.stdout.decode()
+
+
+def get_lines(command: List[str]) -> List[str]:
+ """
+ Run a command and return lines of output
+
+ :param str command: the command to run
+ :returns: list of whitespace-stripped lines output by command
+ """
+ stdout = get_output(command)
+ return [line.strip() for line in stdout.splitlines()]
+
+
+def git_hook(strict: bool = False, modify: bool = False, lazy: bool = False) -> int:
+ """
+ Git pre-commit hook to check staged files for isort errors
+
+ :param bool strict - if True, return number of errors on exit,
+ causing the hook to fail. If False, return zero so it will
+ just act as a warning.
+ :param bool modify - if True, fix the sources if they are not
+ sorted properly. If False, only report result without
+ modifying anything.
+ :param bool lazy - if True, also check/fix unstaged files.
+ This is useful if you frequently use ``git commit -a`` for example.
+ If False, ony check/fix the staged files for isort errors.
+
+ :return number of errors if in strict mode, 0 otherwise.
+ """
+
+ # Get list of files modified and staged
+ diff_cmd = ["git", "diff-index", "--cached", "--name-only", "--diff-filter=ACMRTUXB", "HEAD"]
+ if lazy:
+ diff_cmd.remove("--cached")
+
+ files_modified = get_lines(diff_cmd)
+ if not files_modified:
+ return 0
+
+ errors = 0
+ config = Config(settings_path=os.path.dirname(os.path.abspath(files_modified[0])))
+ for filename in files_modified:
+ if filename.endswith(".py"):
+ # Get the staged contents of the file
+ staged_cmd = ["git", "show", f":{filename}"]
+ staged_contents = get_output(staged_cmd)
+
+ try:
+ if not api.check_code_string(
+ staged_contents, file_path=Path(filename), config=config
+ ):
+ errors += 1
+ if modify:
+ api.sort_file(filename, config=config)
+ except exceptions.FileSkipped: # pragma: no cover
+ pass
+
+ return errors if strict else 0
diff --git a/venv/Lib/site-packages/isort/io.py b/venv/Lib/site-packages/isort/io.py
new file mode 100644
index 0000000000000000000000000000000000000000..a0357347bc4030254580742f1fc81b3733c18066
--- /dev/null
+++ b/venv/Lib/site-packages/isort/io.py
@@ -0,0 +1,60 @@
+"""Defines any IO utilities used by isort"""
+import re
+import tokenize
+from contextlib import contextmanager
+from io import BytesIO, StringIO, TextIOWrapper
+from pathlib import Path
+from typing import Iterator, NamedTuple, TextIO, Union
+
+_ENCODING_PATTERN = re.compile(br"^[ \t\f]*#.*?coding[:=][ \t]*([-_.a-zA-Z0-9]+)")
+
+
+class File(NamedTuple):
+ stream: TextIO
+ path: Path
+ encoding: str
+
+ @staticmethod
+ def from_contents(contents: str, filename: str) -> "File":
+ encoding, _ = tokenize.detect_encoding(BytesIO(contents.encode("utf-8")).readline)
+ return File(StringIO(contents), path=Path(filename).resolve(), encoding=encoding)
+
+ @property
+ def extension(self):
+ return self.path.suffix.lstrip(".")
+
+ @staticmethod
+ def _open(filename):
+ """Open a file in read only mode using the encoding detected by
+ detect_encoding().
+ """
+ buffer = open(filename, "rb")
+ try:
+ encoding, _ = tokenize.detect_encoding(buffer.readline)
+ buffer.seek(0)
+ text = TextIOWrapper(buffer, encoding, line_buffering=True, newline="")
+ text.mode = "r" # type: ignore
+ return text
+ except Exception:
+ buffer.close()
+ raise
+
+ @staticmethod
+ @contextmanager
+ def read(filename: Union[str, Path]) -> Iterator["File"]:
+ file_path = Path(filename).resolve()
+ stream = None
+ try:
+ stream = File._open(file_path)
+ yield File(stream=stream, path=file_path, encoding=stream.encoding)
+ finally:
+ if stream is not None:
+ stream.close()
+
+
+class _EmptyIO(StringIO):
+ def write(self, *args, **kwargs):
+ pass
+
+
+Empty = _EmptyIO()
diff --git a/venv/Lib/site-packages/isort/literal.py b/venv/Lib/site-packages/isort/literal.py
new file mode 100644
index 0000000000000000000000000000000000000000..28e0855c3a69d0e964a47db1e2d5dcf2ab8348bc
--- /dev/null
+++ b/venv/Lib/site-packages/isort/literal.py
@@ -0,0 +1,108 @@
+import ast
+from pprint import PrettyPrinter
+from typing import Any, Callable, Dict, List, Set, Tuple
+
+from isort.exceptions import (
+ AssignmentsFormatMismatch,
+ LiteralParsingFailure,
+ LiteralSortTypeMismatch,
+)
+from isort.settings import DEFAULT_CONFIG, Config
+
+
+class ISortPrettyPrinter(PrettyPrinter):
+ """an isort customized pretty printer for sorted literals"""
+
+ def __init__(self, config: Config):
+ super().__init__(width=config.line_length, compact=True)
+
+
+type_mapping: Dict[str, Tuple[type, Callable[[Any, ISortPrettyPrinter], str]]] = {}
+
+
+def assignments(code: str) -> str:
+ sort_assignments = {}
+ for line in code.splitlines(keepends=True):
+ if line:
+ if " = " not in line:
+ raise AssignmentsFormatMismatch(code)
+ else:
+ variable_name, value = line.split(" = ", 1)
+ sort_assignments[variable_name] = value
+
+ sorted_assignments = dict(sorted(sort_assignments.items(), key=lambda item: item[1]))
+ return "".join(f"{key} = {value}" for key, value in sorted_assignments.items())
+
+
+def assignment(code: str, sort_type: str, extension: str, config: Config = DEFAULT_CONFIG) -> str:
+ """Sorts the literal present within the provided code against the provided sort type,
+ returning the sorted representation of the source code.
+ """
+ if sort_type == "assignments":
+ return assignments(code)
+ elif sort_type not in type_mapping:
+ raise ValueError(
+ "Trying to sort using an undefined sort_type. "
+ f"Defined sort types are {', '.join(type_mapping.keys())}."
+ )
+
+ variable_name, literal = code.split(" = ")
+ variable_name = variable_name.lstrip()
+ try:
+ value = ast.literal_eval(literal)
+ except Exception as error:
+ raise LiteralParsingFailure(code, error)
+
+ expected_type, sort_function = type_mapping[sort_type]
+ if type(value) != expected_type:
+ raise LiteralSortTypeMismatch(type(value), expected_type)
+
+ printer = ISortPrettyPrinter(config)
+ sorted_value_code = f"{variable_name} = {sort_function(value, printer)}"
+ if config.formatting_function:
+ sorted_value_code = config.formatting_function(
+ sorted_value_code, extension, config
+ ).rstrip()
+
+ sorted_value_code += code[len(code.rstrip()) :]
+ return sorted_value_code
+
+
+def register_type(name: str, kind: type):
+ """Registers a new literal sort type."""
+
+ def wrap(function):
+ type_mapping[name] = (kind, function)
+ return function
+
+ return wrap
+
+
+@register_type("dict", dict)
+def _dict(value: Dict[Any, Any], printer: ISortPrettyPrinter) -> str:
+ return printer.pformat(dict(sorted(value.items(), key=lambda item: item[1])))
+
+
+@register_type("list", list)
+def _list(value: List[Any], printer: ISortPrettyPrinter) -> str:
+ return printer.pformat(sorted(value))
+
+
+@register_type("unique-list", list)
+def _unique_list(value: List[Any], printer: ISortPrettyPrinter) -> str:
+ return printer.pformat(list(sorted(set(value))))
+
+
+@register_type("set", set)
+def _set(value: Set[Any], printer: ISortPrettyPrinter) -> str:
+ return "{" + printer.pformat(tuple(sorted(value)))[1:-1] + "}"
+
+
+@register_type("tuple", tuple)
+def _tuple(value: Tuple[Any, ...], printer: ISortPrettyPrinter) -> str:
+ return printer.pformat(tuple(sorted(value)))
+
+
+@register_type("unique-tuple", tuple)
+def _unique_tuple(value: Tuple[Any, ...], printer: ISortPrettyPrinter) -> str:
+ return printer.pformat(tuple(sorted(set(value))))
diff --git a/venv/Lib/site-packages/isort/logo.py b/venv/Lib/site-packages/isort/logo.py
new file mode 100644
index 0000000000000000000000000000000000000000..6377d8686ae49da731d108dc86095c560dfa36e5
--- /dev/null
+++ b/venv/Lib/site-packages/isort/logo.py
@@ -0,0 +1,19 @@
+from ._version import __version__
+
+ASCII_ART = rf"""
+ _ _
+ (_) ___ ___ _ __| |_
+ | |/ _/ / _ \/ '__ _/
+ | |\__ \/\_\/| | | |_
+ |_|\___/\___/\_/ \_/
+
+ isort your imports, so you don't have to.
+
+ VERSION {__version__}
+"""
+
+__doc__ = f"""
+```python
+{ASCII_ART}
+```
+"""
diff --git a/venv/Lib/site-packages/isort/main.py b/venv/Lib/site-packages/isort/main.py
new file mode 100644
index 0000000000000000000000000000000000000000..58c4e101589c4817ab9bcdd542ef542f6ed7c772
--- /dev/null
+++ b/venv/Lib/site-packages/isort/main.py
@@ -0,0 +1,920 @@
+"""Tool for sorting imports alphabetically, and automatically separated into sections."""
+import argparse
+import functools
+import json
+import os
+import sys
+from io import TextIOWrapper
+from pathlib import Path
+from typing import Any, Dict, Iterable, Iterator, List, Optional, Sequence, Set
+from warnings import warn
+
+from . import __version__, api, sections
+from .exceptions import FileSkipped
+from .logo import ASCII_ART
+from .profiles import profiles
+from .settings import VALID_PY_TARGETS, Config, WrapModes
+
+try:
+ from .setuptools_commands import ISortCommand # noqa: F401
+except ImportError:
+ pass
+
+DEPRECATED_SINGLE_DASH_ARGS = {
+ "-ac",
+ "-af",
+ "-ca",
+ "-cs",
+ "-df",
+ "-ds",
+ "-dt",
+ "-fas",
+ "-fass",
+ "-ff",
+ "-fgw",
+ "-fss",
+ "-lai",
+ "-lbt",
+ "-le",
+ "-ls",
+ "-nis",
+ "-nlb",
+ "-ot",
+ "-rr",
+ "-sd",
+ "-sg",
+ "-sl",
+ "-sp",
+ "-tc",
+ "-wl",
+ "-ws",
+}
+QUICK_GUIDE = f"""
+{ASCII_ART}
+
+Nothing to do: no files or paths have have been passed in!
+
+Try one of the following:
+
+ `isort .` - sort all Python files, starting from the current directory, recursively.
+ `isort . --interactive` - Do the same, but ask before making any changes.
+ `isort . --check --diff` - Check to see if imports are correctly sorted within this project.
+ `isort --help` - In-depth information about isort's available command-line options.
+
+Visit https://timothycrosley.github.io/isort/ for complete information about how to use isort.
+"""
+
+
+class SortAttempt:
+ def __init__(self, incorrectly_sorted: bool, skipped: bool) -> None:
+ self.incorrectly_sorted = incorrectly_sorted
+ self.skipped = skipped
+
+
+def sort_imports(
+ file_name: str,
+ config: Config,
+ check: bool = False,
+ ask_to_apply: bool = False,
+ write_to_stdout: bool = False,
+ **kwargs: Any,
+) -> Optional[SortAttempt]:
+ try:
+ incorrectly_sorted: bool = False
+ skipped: bool = False
+ if check:
+ try:
+ incorrectly_sorted = not api.check_file(file_name, config=config, **kwargs)
+ except FileSkipped:
+ skipped = True
+ return SortAttempt(incorrectly_sorted, skipped)
+ else:
+ try:
+ incorrectly_sorted = not api.sort_file(
+ file_name,
+ config=config,
+ ask_to_apply=ask_to_apply,
+ write_to_stdout=write_to_stdout,
+ **kwargs,
+ )
+ except FileSkipped:
+ skipped = True
+ return SortAttempt(incorrectly_sorted, skipped)
+ except (OSError, ValueError) as error:
+ warn(f"Unable to parse file {file_name} due to {error}")
+ return None
+
+
+def iter_source_code(paths: Iterable[str], config: Config, skipped: List[str]) -> Iterator[str]:
+ """Iterate over all Python source files defined in paths."""
+ visited_dirs: Set[Path] = set()
+
+ for path in paths:
+ if os.path.isdir(path):
+ for dirpath, dirnames, filenames in os.walk(path, topdown=True, followlinks=True):
+ base_path = Path(dirpath)
+ for dirname in list(dirnames):
+ full_path = base_path / dirname
+ if config.is_skipped(full_path):
+ skipped.append(dirname)
+ dirnames.remove(dirname)
+
+ resolved_path = full_path.resolve()
+ if resolved_path in visited_dirs: # pragma: no cover
+ if not config.quiet:
+ warn(f"Likely recursive symlink detected to {resolved_path}")
+ dirnames.remove(dirname)
+ else:
+ visited_dirs.add(resolved_path)
+
+ for filename in filenames:
+ filepath = os.path.join(dirpath, filename)
+ if config.is_supported_filetype(filepath):
+ if config.is_skipped(Path(filepath)):
+ skipped.append(filename)
+ else:
+ yield filepath
+ else:
+ yield path
+
+
+def _build_arg_parser() -> argparse.ArgumentParser:
+ parser = argparse.ArgumentParser(
+ description="Sort Python import definitions alphabetically "
+ "within logical sections. Run with no arguments to see a quick "
+ "start guide, otherwise, one or more files/directories/stdin must be provided. "
+ "Use `-` as the first argument to represent stdin. Use --interactive to use the pre 5.0.0 "
+ "interactive behavior."
+ ""
+ "If you've used isort 4 but are new to isort 5, see the upgrading guide:"
+ "https://timothycrosley.github.io/isort/docs/upgrade_guides/5.0.0/."
+ )
+ inline_args_group = parser.add_mutually_exclusive_group()
+ parser.add_argument(
+ "--src",
+ "--src-path",
+ dest="src_paths",
+ action="append",
+ help="Add an explicitly defined source path "
+ "(modules within src paths have their imports automatically catorgorized as first_party).",
+ )
+ parser.add_argument(
+ "-a",
+ "--add-import",
+ dest="add_imports",
+ action="append",
+ help="Adds the specified import line to all files, "
+ "automatically determining correct placement.",
+ )
+ parser.add_argument(
+ "--append",
+ "--append-only",
+ dest="append_only",
+ action="store_true",
+ help="Only adds the imports specified in --add-imports if the file"
+ " contains existing imports.",
+ )
+ parser.add_argument(
+ "--ac",
+ "--atomic",
+ dest="atomic",
+ action="store_true",
+ help="Ensures the output doesn't save if the resulting file contains syntax errors.",
+ )
+ parser.add_argument(
+ "--af",
+ "--force-adds",
+ dest="force_adds",
+ action="store_true",
+ help="Forces import adds even if the original file is empty.",
+ )
+ parser.add_argument(
+ "-b",
+ "--builtin",
+ dest="known_standard_library",
+ action="append",
+ help="Force isort to recognize a module as part of Python's standard library.",
+ )
+ parser.add_argument(
+ "--extra-builtin",
+ dest="extra_standard_library",
+ action="append",
+ help="Extra modules to be included in the list of ones in Python's standard library.",
+ )
+ parser.add_argument(
+ "-c",
+ "--check-only",
+ "--check",
+ action="store_true",
+ dest="check",
+ help="Checks the file for unsorted / unformatted imports and prints them to the "
+ "command line without modifying the file.",
+ )
+ parser.add_argument(
+ "--ca",
+ "--combine-as",
+ dest="combine_as_imports",
+ action="store_true",
+ help="Combines as imports on the same line.",
+ )
+ parser.add_argument(
+ "--cs",
+ "--combine-star",
+ dest="combine_star",
+ action="store_true",
+ help="Ensures that if a star import is present, "
+ "nothing else is imported from that namespace.",
+ )
+ parser.add_argument(
+ "-d",
+ "--stdout",
+ help="Force resulting output to stdout, instead of in-place.",
+ dest="write_to_stdout",
+ action="store_true",
+ )
+ parser.add_argument(
+ "--df",
+ "--diff",
+ dest="show_diff",
+ action="store_true",
+ help="Prints a diff of all the changes isort would make to a file, instead of "
+ "changing it in place",
+ )
+ parser.add_argument(
+ "--ds",
+ "--no-sections",
+ help="Put all imports into the same section bucket",
+ dest="no_sections",
+ action="store_true",
+ )
+ parser.add_argument(
+ "-e",
+ "--balanced",
+ dest="balanced_wrapping",
+ action="store_true",
+ help="Balances wrapping to produce the most consistent line length possible",
+ )
+ parser.add_argument(
+ "-f",
+ "--future",
+ dest="known_future_library",
+ action="append",
+ help="Force isort to recognize a module as part of the future compatibility libraries.",
+ )
+ parser.add_argument(
+ "--fas",
+ "--force-alphabetical-sort",
+ action="store_true",
+ dest="force_alphabetical_sort",
+ help="Force all imports to be sorted as a single section",
+ )
+ parser.add_argument(
+ "--fass",
+ "--force-alphabetical-sort-within-sections",
+ action="store_true",
+ dest="force_alphabetical_sort_within_sections",
+ help="Force all imports to be sorted alphabetically within a section",
+ )
+ parser.add_argument(
+ "--ff",
+ "--from-first",
+ dest="from_first",
+ help="Switches the typical ordering preference, "
+ "showing from imports first then straight ones.",
+ )
+ parser.add_argument(
+ "--fgw",
+ "--force-grid-wrap",
+ nargs="?",
+ const=2,
+ type=int,
+ dest="force_grid_wrap",
+ help="Force number of from imports (defaults to 2) to be grid wrapped regardless of line "
+ "length",
+ )
+ parser.add_argument(
+ "--fss",
+ "--force-sort-within-sections",
+ action="store_true",
+ dest="force_sort_within_sections",
+ help="Don't sort straight-style imports (like import sys) before from-style imports "
+ "(like from itertools import groupby). Instead, sort the imports by module, "
+ "independent of import style.",
+ )
+ parser.add_argument(
+ "-i",
+ "--indent",
+ help='String to place for indents defaults to " " (4 spaces).',
+ dest="indent",
+ type=str,
+ )
+ parser.add_argument(
+ "-j", "--jobs", help="Number of files to process in parallel.", dest="jobs", type=int
+ )
+ parser.add_argument("--lai", "--lines-after-imports", dest="lines_after_imports", type=int)
+ parser.add_argument("--lbt", "--lines-between-types", dest="lines_between_types", type=int)
+ parser.add_argument(
+ "--le",
+ "--line-ending",
+ dest="line_ending",
+ help="Forces line endings to the specified value. "
+ "If not set, values will be guessed per-file.",
+ )
+ parser.add_argument(
+ "--ls",
+ "--length-sort",
+ help="Sort imports by their string length.",
+ dest="length_sort",
+ action="store_true",
+ )
+ parser.add_argument(
+ "--lss",
+ "--length-sort-straight",
+ help="Sort straight imports by their string length.",
+ dest="length_sort_straight",
+ action="store_true",
+ )
+ parser.add_argument(
+ "-m",
+ "--multi-line",
+ dest="multi_line_output",
+ choices=list(WrapModes.__members__.keys())
+ + [str(mode.value) for mode in WrapModes.__members__.values()],
+ type=str,
+ help="Multi line output (0-grid, 1-vertical, 2-hanging, 3-vert-hanging, 4-vert-grid, "
+ "5-vert-grid-grouped, 6-vert-grid-grouped-no-comma, 7-noqa, "
+ "8-vertical-hanging-indent-bracket, 9-vertical-prefix-from-module-import, "
+ "10-hanging-indent-with-parentheses).",
+ )
+ parser.add_argument(
+ "-n",
+ "--ensure-newline-before-comments",
+ dest="ensure_newline_before_comments",
+ action="store_true",
+ help="Inserts a blank line before a comment following an import.",
+ )
+ inline_args_group.add_argument(
+ "--nis",
+ "--no-inline-sort",
+ dest="no_inline_sort",
+ action="store_true",
+ help="Leaves `from` imports with multiple imports 'as-is' "
+ "(e.g. `from foo import a, c ,b`).",
+ )
+ parser.add_argument(
+ "--nlb",
+ "--no-lines-before",
+ help="Sections which should not be split with previous by empty lines",
+ dest="no_lines_before",
+ action="append",
+ )
+ parser.add_argument(
+ "-o",
+ "--thirdparty",
+ dest="known_third_party",
+ action="append",
+ help="Force isort to recognize a module as being part of a third party library.",
+ )
+ parser.add_argument(
+ "--ot",
+ "--order-by-type",
+ dest="order_by_type",
+ action="store_true",
+ help="Order imports by type, which is determined by case, in addition to alphabetically.\n"
+ "\n**NOTE**: type here refers to the implied type from the import name capitalization.\n"
+ ' isort does not do type introspection for the imports. These "types" are simply: '
+ "CONSTANT_VARIABLE, CamelCaseClass, variable_or_function. If your project follows PEP8"
+ " or a related coding standard and has many imports this is a good default, otherwise you "
+ "likely will want to turn it off. From the CLI the `--dont-order-by-type` option will turn "
+ "this off.",
+ )
+ parser.add_argument(
+ "--dt",
+ "--dont-order-by-type",
+ dest="dont_order_by_type",
+ action="store_true",
+ help="Don't order imports by type, which is determined by case, in addition to "
+ "alphabetically.\n\n"
+ "**NOTE**: type here refers to the implied type from the import name capitalization.\n"
+ ' isort does not do type introspection for the imports. These "types" are simply: '
+ "CONSTANT_VARIABLE, CamelCaseClass, variable_or_function. If your project follows PEP8"
+ " or a related coding standard and has many imports this is a good default. You can turn "
+ "this on from the CLI using `--order-by-type`.",
+ )
+ parser.add_argument(
+ "-p",
+ "--project",
+ dest="known_first_party",
+ action="append",
+ help="Force isort to recognize a module as being part of the current python project.",
+ )
+ parser.add_argument(
+ "--known-local-folder",
+ dest="known_local_folder",
+ action="append",
+ help="Force isort to recognize a module as being a local folder. "
+ "Generally, this is reserved for relative imports (from . import module).",
+ )
+ parser.add_argument(
+ "-q",
+ "--quiet",
+ action="store_true",
+ dest="quiet",
+ help="Shows extra quiet output, only errors are outputted.",
+ )
+ parser.add_argument(
+ "--rm",
+ "--remove-import",
+ dest="remove_imports",
+ action="append",
+ help="Removes the specified import from all files.",
+ )
+ parser.add_argument(
+ "--rr",
+ "--reverse-relative",
+ dest="reverse_relative",
+ action="store_true",
+ help="Reverse order of relative imports.",
+ )
+ parser.add_argument(
+ "-s",
+ "--skip",
+ help="Files that sort imports should skip over. If you want to skip multiple "
+ "files you should specify twice: --skip file1 --skip file2.",
+ dest="skip",
+ action="append",
+ )
+ parser.add_argument(
+ "--sd",
+ "--section-default",
+ dest="default_section",
+ help="Sets the default section for import options: " + str(sections.DEFAULT),
+ )
+ parser.add_argument(
+ "--sg",
+ "--skip-glob",
+ help="Files that sort imports should skip over.",
+ dest="skip_glob",
+ action="append",
+ )
+ parser.add_argument(
+ "--gitignore",
+ "--skip-gitignore",
+ action="store_true",
+ dest="skip_gitignore",
+ help="Treat project as a git repository and ignore files listed in .gitignore",
+ )
+ inline_args_group.add_argument(
+ "--sl",
+ "--force-single-line-imports",
+ dest="force_single_line",
+ action="store_true",
+ help="Forces all from imports to appear on their own line",
+ )
+ parser.add_argument(
+ "--nsl",
+ "--single-line-exclusions",
+ help="One or more modules to exclude from the single line rule.",
+ dest="single_line_exclusions",
+ action="append",
+ )
+ parser.add_argument(
+ "--sp",
+ "--settings-path",
+ "--settings-file",
+ "--settings",
+ dest="settings_path",
+ help="Explicitly set the settings path or file instead of auto determining "
+ "based on file location.",
+ )
+ parser.add_argument(
+ "-t",
+ "--top",
+ help="Force specific imports to the top of their appropriate section.",
+ dest="force_to_top",
+ action="append",
+ )
+ parser.add_argument(
+ "--tc",
+ "--trailing-comma",
+ dest="include_trailing_comma",
+ action="store_true",
+ help="Includes a trailing comma on multi line imports that include parentheses.",
+ )
+ parser.add_argument(
+ "--up",
+ "--use-parentheses",
+ dest="use_parentheses",
+ action="store_true",
+ help="Use parentheses for line continuation on length limit instead of slashes."
+ " **NOTE**: This is separate from wrap modes, and only affects how individual lines that "
+ " are too long get continued, not sections of multiple imports.",
+ )
+ parser.add_argument(
+ "-V",
+ "--version",
+ action="store_true",
+ dest="show_version",
+ help="Displays the currently installed version of isort.",
+ )
+ parser.add_argument(
+ "-v",
+ "--verbose",
+ action="store_true",
+ dest="verbose",
+ help="Shows verbose output, such as when files are skipped or when a check is successful.",
+ )
+ parser.add_argument(
+ "--virtual-env",
+ dest="virtual_env",
+ help="Virtual environment to use for determining whether a package is third-party",
+ )
+ parser.add_argument(
+ "--conda-env",
+ dest="conda_env",
+ help="Conda environment to use for determining whether a package is third-party",
+ )
+ parser.add_argument(
+ "--vn",
+ "--version-number",
+ action="version",
+ version=__version__,
+ help="Returns just the current version number without the logo",
+ )
+ parser.add_argument(
+ "-l",
+ "-w",
+ "--line-length",
+ "--line-width",
+ help="The max length of an import line (used for wrapping long imports).",
+ dest="line_length",
+ type=int,
+ )
+ parser.add_argument(
+ "--wl",
+ "--wrap-length",
+ dest="wrap_length",
+ type=int,
+ help="Specifies how long lines that are wrapped should be, if not set line_length is used."
+ "\nNOTE: wrap_length must be LOWER than or equal to line_length.",
+ )
+ parser.add_argument(
+ "--ws",
+ "--ignore-whitespace",
+ action="store_true",
+ dest="ignore_whitespace",
+ help="Tells isort to ignore whitespace differences when --check-only is being used.",
+ )
+ parser.add_argument(
+ "--case-sensitive",
+ dest="case_sensitive",
+ action="store_true",
+ help="Tells isort to include casing when sorting module names",
+ )
+ parser.add_argument(
+ "--filter-files",
+ dest="filter_files",
+ action="store_true",
+ help="Tells isort to filter files even when they are explicitly passed in as "
+ "part of the CLI command.",
+ )
+ parser.add_argument(
+ "files", nargs="*", help="One or more Python source files that need their imports sorted."
+ )
+ parser.add_argument(
+ "--py",
+ "--python-version",
+ action="store",
+ dest="py_version",
+ choices=tuple(VALID_PY_TARGETS) + ("auto",),
+ help="Tells isort to set the known standard library based on the the specified Python "
+ "version. Default is to assume any Python 3 version could be the target, and use a union "
+ "off all stdlib modules across versions. If auto is specified, the version of the "
+ "interpreter used to run isort "
+ f"(currently: {sys.version_info.major}{sys.version_info.minor}) will be used.",
+ )
+ parser.add_argument(
+ "--profile",
+ dest="profile",
+ type=str,
+ help="Base profile type to use for configuration. "
+ f"Profiles include: {', '.join(profiles.keys())}. As well as any shared profiles.",
+ )
+ parser.add_argument(
+ "--interactive",
+ dest="ask_to_apply",
+ action="store_true",
+ help="Tells isort to apply changes interactively.",
+ )
+ parser.add_argument(
+ "--old-finders",
+ "--magic-placement",
+ dest="old_finders",
+ action="store_true",
+ help="Use the old deprecated finder logic that relies on environment introspection magic.",
+ )
+ parser.add_argument(
+ "--show-config",
+ dest="show_config",
+ action="store_true",
+ help="See isort's determined config, as well as sources of config options.",
+ )
+ parser.add_argument(
+ "--honor-noqa",
+ dest="honor_noqa",
+ action="store_true",
+ help="Tells isort to honor noqa comments to enforce skipping those comments.",
+ )
+ parser.add_argument(
+ "--remove-redundant-aliases",
+ dest="remove_redundant_aliases",
+ action="store_true",
+ help=(
+ "Tells isort to remove redundant aliases from imports, such as `import os as os`."
+ " This defaults to `False` simply because some projects use these seemingly useless "
+ " aliases to signify intent and change behaviour."
+ ),
+ )
+ parser.add_argument(
+ "--color",
+ dest="color_output",
+ action="store_true",
+ help="Tells isort to use color in terminal output.",
+ )
+ parser.add_argument(
+ "--float-to-top",
+ dest="float_to_top",
+ action="store_true",
+ help="Causes all non-indented imports to float to the top of the file having its imports "
+ "sorted. It can be an excellent shortcut for collecting imports every once in a while "
+ "when you place them in the middle of a file to avoid context switching.\n\n"
+ "*NOTE*: It currently doesn't work with cimports and introduces some extra over-head "
+ "and a performance penalty.",
+ )
+ parser.add_argument(
+ "--treat-comment-as-code",
+ dest="treat_comments_as_code",
+ action="append",
+ help="Tells isort to treat the specified single line comment(s) as if they are code.",
+ )
+ parser.add_argument(
+ "--treat-all-comment-as-code",
+ dest="treat_all_comments_as_code",
+ action="store_true",
+ help="Tells isort to treat all single line comments as if they are code.",
+ )
+ parser.add_argument(
+ "--formatter",
+ dest="formatter",
+ type=str,
+ help="Specifies the name of a formatting plugin to use when producing output.",
+ )
+ parser.add_argument(
+ "--ext",
+ "--extension",
+ "--supported-extension",
+ dest="supported_extensions",
+ action="append",
+ help="Specifies what extensions isort can be ran against.",
+ )
+ parser.add_argument(
+ "--blocked-extension",
+ dest="blocked_extensions",
+ action="append",
+ help="Specifies what extensions isort can never be ran against.",
+ )
+ parser.add_argument(
+ "--dedup-headings",
+ dest="dedup_headings",
+ action="store_true",
+ help="Tells isort to only show an identical custom import heading comment once, even if"
+ " there are multiple sections with the comment set.",
+ )
+
+ # deprecated options
+ parser.add_argument(
+ "--recursive",
+ dest="deprecated_flags",
+ action="append_const",
+ const="--recursive",
+ help=argparse.SUPPRESS,
+ )
+ parser.add_argument(
+ "-rc", dest="deprecated_flags", action="append_const", const="-rc", help=argparse.SUPPRESS
+ )
+ parser.add_argument(
+ "--dont-skip",
+ dest="deprecated_flags",
+ action="append_const",
+ const="--dont-skip",
+ help=argparse.SUPPRESS,
+ )
+ parser.add_argument(
+ "-ns", dest="deprecated_flags", action="append_const", const="-ns", help=argparse.SUPPRESS
+ )
+ parser.add_argument(
+ "--apply",
+ dest="deprecated_flags",
+ action="append_const",
+ const="--apply",
+ help=argparse.SUPPRESS,
+ )
+ parser.add_argument(
+ "-k",
+ "--keep-direct-and-as",
+ dest="deprecated_flags",
+ action="append_const",
+ const="--keep-direct-and-as",
+ help=argparse.SUPPRESS,
+ )
+
+ return parser
+
+
+def parse_args(argv: Optional[Sequence[str]] = None) -> Dict[str, Any]:
+ argv = sys.argv[1:] if argv is None else list(argv)
+ remapped_deprecated_args = []
+ for index, arg in enumerate(argv):
+ if arg in DEPRECATED_SINGLE_DASH_ARGS:
+ remapped_deprecated_args.append(arg)
+ argv[index] = f"-{arg}"
+
+ parser = _build_arg_parser()
+ arguments = {key: value for key, value in vars(parser.parse_args(argv)).items() if value}
+ if remapped_deprecated_args:
+ arguments["remapped_deprecated_args"] = remapped_deprecated_args
+ if "dont_order_by_type" in arguments:
+ arguments["order_by_type"] = False
+ del arguments["dont_order_by_type"]
+ multi_line_output = arguments.get("multi_line_output", None)
+ if multi_line_output:
+ if multi_line_output.isdigit():
+ arguments["multi_line_output"] = WrapModes(int(multi_line_output))
+ else:
+ arguments["multi_line_output"] = WrapModes[multi_line_output]
+ return arguments
+
+
+def _preconvert(item):
+ """Preconverts objects from native types into JSONifyiable types"""
+ if isinstance(item, (set, frozenset)):
+ return list(item)
+ elif isinstance(item, WrapModes):
+ return item.name
+ elif isinstance(item, Path):
+ return str(item)
+ elif callable(item) and hasattr(item, "__name__"):
+ return item.__name__
+ else:
+ raise TypeError("Unserializable object {} of type {}".format(item, type(item)))
+
+
+def main(argv: Optional[Sequence[str]] = None, stdin: Optional[TextIOWrapper] = None) -> None:
+ arguments = parse_args(argv)
+ if arguments.get("show_version"):
+ print(ASCII_ART)
+ return
+
+ show_config: bool = arguments.pop("show_config", False)
+
+ if "settings_path" in arguments:
+ if os.path.isfile(arguments["settings_path"]):
+ arguments["settings_file"] = os.path.abspath(arguments["settings_path"])
+ arguments["settings_path"] = os.path.dirname(arguments["settings_file"])
+ else:
+ arguments["settings_path"] = os.path.abspath(arguments["settings_path"])
+
+ if "virtual_env" in arguments:
+ venv = arguments["virtual_env"]
+ arguments["virtual_env"] = os.path.abspath(venv)
+ if not os.path.isdir(arguments["virtual_env"]):
+ warn(f"virtual_env dir does not exist: {arguments['virtual_env']}")
+
+ file_names = arguments.pop("files", [])
+ if not file_names and not show_config:
+ print(QUICK_GUIDE)
+ if arguments:
+ sys.exit("Error: arguments passed in without any paths or content.")
+ else:
+ return
+ if "settings_path" not in arguments:
+ arguments["settings_path"] = (
+ os.path.abspath(file_names[0] if file_names else ".") or os.getcwd()
+ )
+ if not os.path.isdir(arguments["settings_path"]):
+ arguments["settings_path"] = os.path.dirname(arguments["settings_path"])
+
+ config_dict = arguments.copy()
+ ask_to_apply = config_dict.pop("ask_to_apply", False)
+ jobs = config_dict.pop("jobs", ())
+ check = config_dict.pop("check", False)
+ show_diff = config_dict.pop("show_diff", False)
+ write_to_stdout = config_dict.pop("write_to_stdout", False)
+ deprecated_flags = config_dict.pop("deprecated_flags", False)
+ remapped_deprecated_args = config_dict.pop("remapped_deprecated_args", False)
+ wrong_sorted_files = False
+
+ if "src_paths" in config_dict:
+ config_dict["src_paths"] = {
+ Path(src_path).resolve() for src_path in config_dict.get("src_paths", ())
+ }
+
+ config = Config(**config_dict)
+ if show_config:
+ print(json.dumps(config.__dict__, indent=4, separators=(",", ": "), default=_preconvert))
+ return
+ elif file_names == ["-"]:
+ arguments.setdefault("settings_path", os.getcwd())
+ api.sort_stream(
+ input_stream=sys.stdin if stdin is None else stdin,
+ output_stream=sys.stdout,
+ **arguments,
+ )
+ else:
+ skipped: List[str] = []
+
+ if config.filter_files:
+ filtered_files = []
+ for file_name in file_names:
+ if config.is_skipped(Path(file_name)):
+ skipped.append(file_name)
+ else:
+ filtered_files.append(file_name)
+ file_names = filtered_files
+
+ file_names = iter_source_code(file_names, config, skipped)
+ num_skipped = 0
+ if config.verbose:
+ print(ASCII_ART)
+
+ if jobs:
+ import multiprocessing
+
+ executor = multiprocessing.Pool(jobs)
+ attempt_iterator = executor.imap(
+ functools.partial(
+ sort_imports,
+ config=config,
+ check=check,
+ ask_to_apply=ask_to_apply,
+ write_to_stdout=write_to_stdout,
+ ),
+ file_names,
+ )
+ else:
+ # https://github.com/python/typeshed/pull/2814
+ attempt_iterator = (
+ sort_imports( # type: ignore
+ file_name,
+ config=config,
+ check=check,
+ ask_to_apply=ask_to_apply,
+ show_diff=show_diff,
+ write_to_stdout=write_to_stdout,
+ )
+ for file_name in file_names
+ )
+
+ for sort_attempt in attempt_iterator:
+ if not sort_attempt:
+ continue # pragma: no cover - shouldn't happen, satisfies type constraint
+ incorrectly_sorted = sort_attempt.incorrectly_sorted
+ if arguments.get("check", False) and incorrectly_sorted:
+ wrong_sorted_files = True
+ if sort_attempt.skipped:
+ num_skipped += (
+ 1 # pragma: no cover - shouldn't happen, due to skip in iter_source_code
+ )
+
+ num_skipped += len(skipped)
+ if num_skipped and not arguments.get("quiet", False):
+ if config.verbose:
+ for was_skipped in skipped:
+ warn(
+ f"{was_skipped} was skipped as it's listed in 'skip' setting"
+ " or matches a glob in 'skip_glob' setting"
+ )
+ print(f"Skipped {num_skipped} files")
+
+ if not config.quiet and (remapped_deprecated_args or deprecated_flags):
+ if remapped_deprecated_args:
+ warn(
+ "W0502: The following deprecated single dash CLI flags were used and translated: "
+ f"{', '.join(remapped_deprecated_args)}!"
+ )
+ if deprecated_flags:
+ warn(
+ "W0501: The following deprecated CLI flags were used and ignored: "
+ f"{', '.join(deprecated_flags)}!"
+ )
+ warn(
+ "W0500: Please see the 5.0.0 Upgrade guide: "
+ "https://timothycrosley.github.io/isort/docs/upgrade_guides/5.0.0/"
+ )
+
+ if wrong_sorted_files:
+ sys.exit(1)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/venv/Lib/site-packages/isort/output.py b/venv/Lib/site-packages/isort/output.py
new file mode 100644
index 0000000000000000000000000000000000000000..6a21c131527db518edd564c2aa9d85d194392516
--- /dev/null
+++ b/venv/Lib/site-packages/isort/output.py
@@ -0,0 +1,552 @@
+import copy
+import itertools
+from functools import partial
+from typing import Iterable, List, Set, Tuple
+
+from isort.format import format_simplified
+
+from . import parse, sorting, wrap
+from .comments import add_to_line as with_comments
+from .settings import DEFAULT_CONFIG, Config
+
+STATEMENT_DECLERATIONS: Tuple[str, ...] = ("def ", "cdef ", "cpdef ", "class ", "@", "async def")
+
+
+def sorted_imports(
+ parsed: parse.ParsedContent,
+ config: Config = DEFAULT_CONFIG,
+ extension: str = "py",
+ import_type: str = "import",
+) -> str:
+ """Adds the imports back to the file.
+
+ (at the index of the first import) sorted alphabetically and split between groups
+
+ """
+ if parsed.import_index == -1:
+ return _output_as_string(parsed.lines_without_imports, parsed.line_separator)
+
+ formatted_output: List[str] = parsed.lines_without_imports.copy()
+ remove_imports = [format_simplified(removal) for removal in config.remove_imports]
+
+ sort_ignore_case = config.force_alphabetical_sort_within_sections
+ sections: Iterable[str] = itertools.chain(parsed.sections, config.forced_separate)
+
+ if config.no_sections:
+ parsed.imports["no_sections"] = {"straight": {}, "from": {}}
+ base_sections: Tuple[str, ...] = ()
+ for section in sections:
+ if section == "FUTURE":
+ base_sections = ("FUTURE",)
+ continue
+ parsed.imports["no_sections"]["straight"].update(
+ parsed.imports[section].get("straight", {})
+ )
+ parsed.imports["no_sections"]["from"].update(parsed.imports[section].get("from", {}))
+ sections = base_sections + ("no_sections",)
+
+ output: List[str] = []
+ seen_headings: Set[str] = set()
+ pending_lines_before = False
+ for section in sections:
+ straight_modules = parsed.imports[section]["straight"]
+ straight_modules = sorting.naturally(
+ straight_modules,
+ key=lambda key: sorting.module_key(
+ key, config, section_name=section, straight_import=True
+ ),
+ )
+ from_modules = parsed.imports[section]["from"]
+ from_modules = sorting.naturally(
+ from_modules, key=lambda key: sorting.module_key(key, config, section_name=section)
+ )
+
+ section_output: List[str] = []
+ if config.from_first:
+ section_output = _with_from_imports(
+ parsed,
+ config,
+ from_modules,
+ section,
+ section_output,
+ sort_ignore_case,
+ remove_imports,
+ import_type,
+ )
+ if config.lines_between_types and from_modules and straight_modules:
+ section_output.extend([""] * config.lines_between_types)
+ section_output = _with_straight_imports(
+ parsed,
+ config,
+ straight_modules,
+ section,
+ section_output,
+ remove_imports,
+ import_type,
+ )
+ else:
+ section_output = _with_straight_imports(
+ parsed,
+ config,
+ straight_modules,
+ section,
+ section_output,
+ remove_imports,
+ import_type,
+ )
+ if config.lines_between_types and from_modules and straight_modules:
+ section_output.extend([""] * config.lines_between_types)
+ section_output = _with_from_imports(
+ parsed,
+ config,
+ from_modules,
+ section,
+ section_output,
+ sort_ignore_case,
+ remove_imports,
+ import_type,
+ )
+
+ if config.force_sort_within_sections:
+ # collapse comments
+ comments_above = []
+ new_section_output: List[str] = []
+ for line in section_output:
+ if not line:
+ continue
+ if line.startswith("#"):
+ comments_above.append(line)
+ elif comments_above:
+ new_section_output.append(_LineWithComments(line, comments_above))
+ comments_above = []
+ else:
+ new_section_output.append(line)
+
+ new_section_output = sorting.naturally(
+ new_section_output,
+ key=partial(
+ sorting.section_key,
+ order_by_type=config.order_by_type,
+ force_to_top=config.force_to_top,
+ lexicographical=config.lexicographical,
+ length_sort=config.length_sort,
+ ),
+ )
+
+ # uncollapse comments
+ section_output = []
+ for line in new_section_output:
+ comments = getattr(line, "comments", ())
+ if comments:
+ if (
+ config.ensure_newline_before_comments
+ and section_output
+ and section_output[-1]
+ ):
+ section_output.append("")
+ section_output.extend(comments)
+ section_output.append(str(line))
+
+ section_name = section
+ no_lines_before = section_name in config.no_lines_before
+
+ if section_output:
+ if section_name in parsed.place_imports:
+ parsed.place_imports[section_name] = section_output
+ continue
+
+ section_title = config.import_headings.get(section_name.lower(), "")
+ if section_title and section_title not in seen_headings:
+ if config.dedup_headings:
+ seen_headings.add(section_title)
+ section_comment = f"# {section_title}"
+ if section_comment not in parsed.lines_without_imports[0:1]:
+ section_output.insert(0, section_comment)
+
+ if pending_lines_before or not no_lines_before:
+ output += [""] * config.lines_between_sections
+
+ output += section_output
+
+ pending_lines_before = False
+ else:
+ pending_lines_before = pending_lines_before or not no_lines_before
+
+ while output and output[-1].strip() == "":
+ output.pop() # pragma: no cover
+ while output and output[0].strip() == "":
+ output.pop(0)
+
+ if config.formatting_function:
+ output = config.formatting_function(
+ parsed.line_separator.join(output), extension, config
+ ).splitlines()
+
+ output_at = 0
+ if parsed.import_index < parsed.original_line_count:
+ output_at = parsed.import_index
+ formatted_output[output_at:0] = output
+
+ imports_tail = output_at + len(output)
+ while [
+ character.strip() for character in formatted_output[imports_tail : imports_tail + 1]
+ ] == [""]:
+ formatted_output.pop(imports_tail)
+
+ if len(formatted_output) > imports_tail:
+ next_construct = ""
+ tail = formatted_output[imports_tail:]
+
+ for index, line in enumerate(tail):
+ should_skip, in_quote, *_ = parse.skip_line(
+ line,
+ in_quote="",
+ index=len(formatted_output),
+ section_comments=config.section_comments,
+ needs_import=False,
+ )
+ if not should_skip and line.strip():
+ if (
+ line.strip().startswith("#")
+ and len(tail) > (index + 1)
+ and tail[index + 1].strip()
+ ):
+ continue
+ next_construct = line
+ break
+ elif in_quote:
+ next_construct = line
+ break
+
+ if config.lines_after_imports != -1:
+ formatted_output[imports_tail:0] = ["" for line in range(config.lines_after_imports)]
+ elif extension != "pyi" and next_construct.startswith(STATEMENT_DECLERATIONS):
+ formatted_output[imports_tail:0] = ["", ""]
+ else:
+ formatted_output[imports_tail:0] = [""]
+
+ if parsed.place_imports:
+ new_out_lines = []
+ for index, line in enumerate(formatted_output):
+ new_out_lines.append(line)
+ if line in parsed.import_placements:
+ new_out_lines.extend(parsed.place_imports[parsed.import_placements[line]])
+ if (
+ len(formatted_output) <= (index + 1)
+ or formatted_output[index + 1].strip() != ""
+ ):
+ new_out_lines.append("")
+ formatted_output = new_out_lines
+
+ return _output_as_string(formatted_output, parsed.line_separator)
+
+
+def _with_from_imports(
+ parsed: parse.ParsedContent,
+ config: Config,
+ from_modules: Iterable[str],
+ section: str,
+ section_output: List[str],
+ ignore_case: bool,
+ remove_imports: List[str],
+ import_type: str,
+) -> List[str]:
+ new_section_output = section_output.copy()
+ for module in from_modules:
+ if module in remove_imports:
+ continue
+
+ import_start = f"from {module} {import_type} "
+ from_imports = list(parsed.imports[section]["from"][module])
+ if not config.no_inline_sort or (
+ config.force_single_line and module not in config.single_line_exclusions
+ ):
+ from_imports = sorting.naturally(
+ from_imports,
+ key=lambda key: sorting.module_key(
+ key, config, True, ignore_case, section_name=section
+ ),
+ )
+ if remove_imports:
+ from_imports = [
+ line for line in from_imports if f"{module}.{line}" not in remove_imports
+ ]
+
+ sub_modules = [f"{module}.{from_import}" for from_import in from_imports]
+ as_imports = {
+ from_import: [
+ f"{from_import} as {as_module}" for as_module in parsed.as_map["from"][sub_module]
+ ]
+ for from_import, sub_module in zip(from_imports, sub_modules)
+ if sub_module in parsed.as_map["from"]
+ }
+ if config.combine_as_imports and not ("*" in from_imports and config.combine_star):
+ if not config.no_inline_sort:
+ for as_import in as_imports:
+ as_imports[as_import] = sorting.naturally(as_imports[as_import])
+ for from_import in copy.copy(from_imports):
+ if from_import in as_imports:
+ idx = from_imports.index(from_import)
+ if parsed.imports[section]["from"][module][from_import]:
+ from_imports[(idx + 1) : (idx + 1)] = as_imports.pop(from_import)
+ else:
+ from_imports[idx : (idx + 1)] = as_imports.pop(from_import)
+
+ while from_imports:
+ comments = parsed.categorized_comments["from"].pop(module, ())
+ above_comments = parsed.categorized_comments["above"]["from"].pop(module, None)
+ if above_comments:
+ if new_section_output and config.ensure_newline_before_comments:
+ new_section_output.append("")
+ new_section_output.extend(above_comments)
+
+ if "*" in from_imports and config.combine_star:
+ if config.combine_as_imports:
+ comments = list(comments or ())
+ comments += parsed.categorized_comments["from"].pop(
+ f"{module}.__combined_as__", []
+ )
+ import_statement = wrap.line(
+ with_comments(
+ comments,
+ f"{import_start}*",
+ removed=config.ignore_comments,
+ comment_prefix=config.comment_prefix,
+ ),
+ parsed.line_separator,
+ config,
+ )
+ from_imports = []
+ elif config.force_single_line and module not in config.single_line_exclusions:
+ import_statement = ""
+ while from_imports:
+ from_import = from_imports.pop(0)
+ single_import_line = with_comments(
+ comments,
+ import_start + from_import,
+ removed=config.ignore_comments,
+ comment_prefix=config.comment_prefix,
+ )
+ comment = (
+ parsed.categorized_comments["nested"].get(module, {}).pop(from_import, None)
+ )
+ if comment:
+ single_import_line += (
+ f"{comments and ';' or config.comment_prefix} " f"{comment}"
+ )
+ if from_import in as_imports:
+ if parsed.imports[section]["from"][module][from_import]:
+ new_section_output.append(
+ wrap.line(single_import_line, parsed.line_separator, config)
+ )
+ from_comments = parsed.categorized_comments["straight"].get(
+ f"{module}.{from_import}"
+ )
+ new_section_output.extend(
+ with_comments(
+ from_comments,
+ wrap.line(import_start + as_import, parsed.line_separator, config),
+ removed=config.ignore_comments,
+ comment_prefix=config.comment_prefix,
+ )
+ for as_import in sorting.naturally(as_imports[from_import])
+ )
+ else:
+ new_section_output.append(
+ wrap.line(single_import_line, parsed.line_separator, config)
+ )
+ comments = None
+ else:
+ while from_imports and from_imports[0] in as_imports:
+ from_import = from_imports.pop(0)
+ as_imports[from_import] = sorting.naturally(as_imports[from_import])
+ from_comments = parsed.categorized_comments["straight"].get(
+ f"{module}.{from_import}"
+ )
+ if parsed.imports[section]["from"][module][from_import]:
+ new_section_output.append(
+ wrap.line(
+ with_comments(
+ from_comments,
+ import_start + from_import,
+ removed=config.ignore_comments,
+ comment_prefix=config.comment_prefix,
+ ),
+ parsed.line_separator,
+ config,
+ )
+ )
+ new_section_output.extend(
+ wrap.line(
+ with_comments(
+ from_comments,
+ import_start + as_import,
+ removed=config.ignore_comments,
+ comment_prefix=config.comment_prefix,
+ ),
+ parsed.line_separator,
+ config,
+ )
+ for as_import in as_imports[from_import]
+ )
+
+ if "*" in from_imports:
+ new_section_output.append(
+ with_comments(
+ comments,
+ f"{import_start}*",
+ removed=config.ignore_comments,
+ comment_prefix=config.comment_prefix,
+ )
+ )
+ from_imports.remove("*")
+ comments = None
+
+ for from_import in copy.copy(from_imports):
+ comment = (
+ parsed.categorized_comments["nested"].get(module, {}).pop(from_import, None)
+ )
+ if comment:
+ single_import_line = with_comments(
+ comments,
+ import_start + from_import,
+ removed=config.ignore_comments,
+ comment_prefix=config.comment_prefix,
+ )
+ single_import_line += (
+ f"{comments and ';' or config.comment_prefix} " f"{comment}"
+ )
+ new_section_output.append(
+ wrap.line(single_import_line, parsed.line_separator, config)
+ )
+ from_imports.remove(from_import)
+ comments = None
+
+ from_import_section = []
+ while from_imports and (
+ from_imports[0] not in as_imports
+ or (
+ config.combine_as_imports
+ and parsed.imports[section]["from"][module][from_import]
+ )
+ ):
+ from_import_section.append(from_imports.pop(0))
+ if config.combine_as_imports:
+ comments = (comments or []) + list(
+ parsed.categorized_comments["from"].pop(f"{module}.__combined_as__", ())
+ )
+ import_statement = with_comments(
+ comments,
+ import_start + (", ").join(from_import_section),
+ removed=config.ignore_comments,
+ comment_prefix=config.comment_prefix,
+ )
+ if not from_import_section:
+ import_statement = ""
+
+ do_multiline_reformat = False
+
+ force_grid_wrap = config.force_grid_wrap
+ if force_grid_wrap and len(from_import_section) >= force_grid_wrap:
+ do_multiline_reformat = True
+
+ if len(import_statement) > config.line_length and len(from_import_section) > 1:
+ do_multiline_reformat = True
+
+ # If line too long AND have imports AND we are
+ # NOT using GRID or VERTICAL wrap modes
+ if (
+ len(import_statement) > config.line_length
+ and len(from_import_section) > 0
+ and config.multi_line_output
+ not in (wrap.Modes.GRID, wrap.Modes.VERTICAL) # type: ignore
+ ):
+ do_multiline_reformat = True
+
+ if do_multiline_reformat:
+ import_statement = wrap.import_statement(
+ import_start=import_start,
+ from_imports=from_import_section,
+ comments=comments,
+ line_separator=parsed.line_separator,
+ config=config,
+ )
+ if config.multi_line_output == wrap.Modes.GRID: # type: ignore
+ other_import_statement = wrap.import_statement(
+ import_start=import_start,
+ from_imports=from_import_section,
+ comments=comments,
+ line_separator=parsed.line_separator,
+ config=config,
+ multi_line_output=wrap.Modes.VERTICAL_GRID, # type: ignore
+ )
+ if max(len(x) for x in import_statement.split("\n")) > config.line_length:
+ import_statement = other_import_statement
+ if not do_multiline_reformat and len(import_statement) > config.line_length:
+ import_statement = wrap.line(import_statement, parsed.line_separator, config)
+
+ if import_statement:
+ new_section_output.append(import_statement)
+ return new_section_output
+
+
+def _with_straight_imports(
+ parsed: parse.ParsedContent,
+ config: Config,
+ straight_modules: Iterable[str],
+ section: str,
+ section_output: List[str],
+ remove_imports: List[str],
+ import_type: str,
+) -> List[str]:
+ new_section_output = section_output.copy()
+ for module in straight_modules:
+ if module in remove_imports:
+ continue
+
+ import_definition = []
+ if module in parsed.as_map["straight"]:
+ if parsed.imports[section]["straight"][module]:
+ import_definition.append(f"{import_type} {module}")
+ import_definition.extend(
+ f"{import_type} {module} as {as_import}"
+ for as_import in parsed.as_map["straight"][module]
+ )
+ else:
+ import_definition.append(f"{import_type} {module}")
+
+ comments_above = parsed.categorized_comments["above"]["straight"].pop(module, None)
+ if comments_above:
+ if new_section_output and config.ensure_newline_before_comments:
+ new_section_output.append("")
+ new_section_output.extend(comments_above)
+ new_section_output.extend(
+ with_comments(
+ parsed.categorized_comments["straight"].get(module),
+ idef,
+ removed=config.ignore_comments,
+ comment_prefix=config.comment_prefix,
+ )
+ for idef in import_definition
+ )
+
+ return new_section_output
+
+
+def _output_as_string(lines: List[str], line_separator: str) -> str:
+ return line_separator.join(_normalize_empty_lines(lines))
+
+
+def _normalize_empty_lines(lines: List[str]) -> List[str]:
+ while lines and lines[-1].strip() == "":
+ lines.pop(-1)
+
+ lines.append("")
+ return lines
+
+
+class _LineWithComments(str):
+ def __new__(cls, value, comments):
+ instance = super().__new__(cls, value) # type: ignore
+ instance.comments = comments
+ return instance
diff --git a/venv/Lib/site-packages/isort/parse.py b/venv/Lib/site-packages/isort/parse.py
new file mode 100644
index 0000000000000000000000000000000000000000..2ab43acfc33e526a64feeb9d097c43e62184a798
--- /dev/null
+++ b/venv/Lib/site-packages/isort/parse.py
@@ -0,0 +1,463 @@
+"""Defines parsing functions used by isort for parsing import definitions"""
+from collections import OrderedDict, defaultdict
+from functools import partial
+from itertools import chain
+from typing import TYPE_CHECKING, Any, Dict, List, NamedTuple, Optional, Tuple
+from warnings import warn
+
+from . import place
+from .comments import parse as parse_comments
+from .deprecated.finders import FindersManager
+from .settings import DEFAULT_CONFIG, Config
+
+if TYPE_CHECKING:
+ from mypy_extensions import TypedDict
+
+ CommentsAboveDict = TypedDict(
+ "CommentsAboveDict", {"straight": Dict[str, Any], "from": Dict[str, Any]}
+ )
+
+ CommentsDict = TypedDict(
+ "CommentsDict",
+ {
+ "from": Dict[str, Any],
+ "straight": Dict[str, Any],
+ "nested": Dict[str, Any],
+ "above": CommentsAboveDict,
+ },
+ )
+
+
+def _infer_line_separator(contents: str) -> str:
+ if "\r\n" in contents:
+ return "\r\n"
+ elif "\r" in contents:
+ return "\r"
+ else:
+ return "\n"
+
+
+def _normalize_line(raw_line: str) -> Tuple[str, str]:
+ """Normalizes import related statements in the provided line.
+
+ Returns (normalized_line: str, raw_line: str)
+ """
+ line = raw_line.replace("from.import ", "from . import ")
+ line = line.replace("from.cimport ", "from . cimport ")
+ line = line.replace("import*", "import *")
+ line = line.replace(" .import ", " . import ")
+ line = line.replace(" .cimport ", " . cimport ")
+ line = line.replace("\t", " ")
+ return (line, raw_line)
+
+
+def import_type(line: str, config: Config = DEFAULT_CONFIG) -> Optional[str]:
+ """If the current line is an import line it will return its type (from or straight)"""
+ if config.honor_noqa and line.lower().rstrip().endswith("noqa"):
+ return None
+ elif "isort:skip" in line or "isort: skip" in line or "isort: split" in line:
+ return None
+ elif line.startswith(("import ", "cimport ")):
+ return "straight"
+ elif line.startswith("from "):
+ return "from"
+ return None
+
+
+def _strip_syntax(import_string: str) -> str:
+ import_string = import_string.replace("_import", "[[i]]")
+ import_string = import_string.replace("_cimport", "[[ci]]")
+ for remove_syntax in ["\\", "(", ")", ","]:
+ import_string = import_string.replace(remove_syntax, " ")
+ import_list = import_string.split()
+ for key in ("from", "import", "cimport"):
+ if key in import_list:
+ import_list.remove(key)
+ import_string = " ".join(import_list)
+ import_string = import_string.replace("[[i]]", "_import")
+ import_string = import_string.replace("[[ci]]", "_cimport")
+ return import_string.replace("{ ", "{|").replace(" }", "|}")
+
+
+def skip_line(
+ line: str,
+ in_quote: str,
+ index: int,
+ section_comments: Tuple[str, ...],
+ needs_import: bool = True,
+) -> Tuple[bool, str]:
+ """Determine if a given line should be skipped.
+
+ Returns back a tuple containing:
+
+ (skip_line: bool,
+ in_quote: str,)
+ """
+ should_skip = bool(in_quote)
+ if '"' in line or "'" in line:
+ char_index = 0
+ while char_index < len(line):
+ if line[char_index] == "\\":
+ char_index += 1
+ elif in_quote:
+ if line[char_index : char_index + len(in_quote)] == in_quote:
+ in_quote = ""
+ elif line[char_index] in ("'", '"'):
+ long_quote = line[char_index : char_index + 3]
+ if long_quote in ('"""', "'''"):
+ in_quote = long_quote
+ char_index += 2
+ else:
+ in_quote = line[char_index]
+ elif line[char_index] == "#":
+ break
+ char_index += 1
+
+ if ";" in line and needs_import:
+ for part in (part.strip() for part in line.split(";")):
+ if (
+ part
+ and not part.startswith("from ")
+ and not part.startswith(("import ", "cimport "))
+ ):
+ should_skip = True
+
+ return (bool(should_skip or in_quote), in_quote)
+
+
+class ParsedContent(NamedTuple):
+ in_lines: List[str]
+ lines_without_imports: List[str]
+ import_index: int
+ place_imports: Dict[str, List[str]]
+ import_placements: Dict[str, str]
+ as_map: Dict[str, Dict[str, List[str]]]
+ imports: Dict[str, Dict[str, Any]]
+ categorized_comments: "CommentsDict"
+ change_count: int
+ original_line_count: int
+ line_separator: str
+ sections: Any
+
+
+def file_contents(contents: str, config: Config = DEFAULT_CONFIG) -> ParsedContent:
+ """Parses a python file taking out and categorizing imports."""
+ line_separator: str = config.line_ending or _infer_line_separator(contents)
+ in_lines = contents.splitlines()
+ if contents and contents[-1] in ("\n", "\r"):
+ in_lines.append("")
+
+ out_lines = []
+ original_line_count = len(in_lines)
+ if config.old_finders:
+ finder = FindersManager(config=config).find
+ else:
+ finder = partial(place.module, config=config)
+
+ line_count = len(in_lines)
+
+ place_imports: Dict[str, List[str]] = {}
+ import_placements: Dict[str, str] = {}
+ as_map: Dict[str, Dict[str, List[str]]] = {
+ "straight": defaultdict(list),
+ "from": defaultdict(list),
+ }
+ imports: OrderedDict[str, Dict[str, Any]] = OrderedDict()
+ for section in chain(config.sections, config.forced_separate):
+ imports[section] = {"straight": OrderedDict(), "from": OrderedDict()}
+ categorized_comments: CommentsDict = {
+ "from": {},
+ "straight": {},
+ "nested": {},
+ "above": {"straight": {}, "from": {}},
+ }
+
+ index = 0
+ import_index = -1
+ in_quote = ""
+ while index < line_count:
+ line = in_lines[index]
+ index += 1
+ statement_index = index
+ (skipping_line, in_quote) = skip_line(
+ line, in_quote=in_quote, index=index, section_comments=config.section_comments
+ )
+
+ if line in config.section_comments and not skipping_line:
+ if import_index == -1:
+ import_index = index - 1
+ continue
+
+ if "isort:imports-" in line and line.startswith("#"):
+ section = line.split("isort:imports-")[-1].split()[0].upper()
+ place_imports[section] = []
+ import_placements[line] = section
+ elif "isort: imports-" in line and line.startswith("#"):
+ section = line.split("isort: imports-")[-1].split()[0].upper()
+ place_imports[section] = []
+ import_placements[line] = section
+
+ if skipping_line:
+ out_lines.append(line)
+ continue
+
+ for line in (
+ (line.strip() for line in line.split(";")) if ";" in line else (line,) # type: ignore
+ ):
+ line, raw_line = _normalize_line(line)
+ type_of_import = import_type(line, config) or ""
+ if not type_of_import:
+ out_lines.append(raw_line)
+ continue
+
+ if import_index == -1:
+ import_index = index - 1
+ nested_comments = {}
+ import_string, comment = parse_comments(line)
+ comments = [comment] if comment else []
+ line_parts = [part for part in _strip_syntax(import_string).strip().split(" ") if part]
+ if (
+ type_of_import == "from"
+ and len(line_parts) == 2
+ and line_parts[1] != "*"
+ and comments
+ ):
+ nested_comments[line_parts[-1]] = comments[0]
+
+ if "(" in line.split("#")[0] and index < line_count:
+ while not line.split("#")[0].strip().endswith(")") and index < line_count:
+ line, new_comment = parse_comments(in_lines[index])
+ index += 1
+ if new_comment:
+ comments.append(new_comment)
+ stripped_line = _strip_syntax(line).strip()
+ if (
+ type_of_import == "from"
+ and stripped_line
+ and " " not in stripped_line
+ and new_comment
+ ):
+ nested_comments[stripped_line] = comments[-1]
+ import_string += line_separator + line
+ else:
+ while line.strip().endswith("\\"):
+ line, new_comment = parse_comments(in_lines[index])
+ index += 1
+ if new_comment:
+ comments.append(new_comment)
+
+ # Still need to check for parentheses after an escaped line
+ if (
+ "(" in line.split("#")[0]
+ and ")" not in line.split("#")[0]
+ and index < line_count
+ ):
+ stripped_line = _strip_syntax(line).strip()
+ if (
+ type_of_import == "from"
+ and stripped_line
+ and " " not in stripped_line
+ and new_comment
+ ):
+ nested_comments[stripped_line] = comments[-1]
+ import_string += line_separator + line
+
+ while not line.split("#")[0].strip().endswith(")") and index < line_count:
+ line, new_comment = parse_comments(in_lines[index])
+ index += 1
+ if new_comment:
+ comments.append(new_comment)
+ stripped_line = _strip_syntax(line).strip()
+ if (
+ type_of_import == "from"
+ and stripped_line
+ and " " not in stripped_line
+ and new_comment
+ ):
+ nested_comments[stripped_line] = comments[-1]
+ import_string += line_separator + line
+
+ stripped_line = _strip_syntax(line).strip()
+ if (
+ type_of_import == "from"
+ and stripped_line
+ and " " not in stripped_line
+ and new_comment
+ ):
+ nested_comments[stripped_line] = comments[-1]
+ if import_string.strip().endswith(
+ (" import", " cimport")
+ ) or line.strip().startswith(("import ", "cimport ")):
+ import_string += line_separator + line
+ else:
+ import_string = import_string.rstrip().rstrip("\\") + " " + line.lstrip()
+
+ if type_of_import == "from":
+ cimports: bool
+ import_string = (
+ import_string.replace("import(", "import (")
+ .replace("\\", " ")
+ .replace("\n", " ")
+ )
+ if " cimport " in import_string:
+ parts = import_string.split(" cimport ")
+ cimports = True
+
+ else:
+ parts = import_string.split(" import ")
+ cimports = False
+
+ from_import = parts[0].split(" ")
+ import_string = (" cimport " if cimports else " import ").join(
+ [from_import[0] + " " + "".join(from_import[1:])] + parts[1:]
+ )
+
+ just_imports = [
+ item.replace("{|", "{ ").replace("|}", " }")
+ for item in _strip_syntax(import_string).split()
+ ]
+ straight_import = True
+ if "as" in just_imports and (just_imports.index("as") + 1) < len(just_imports):
+ straight_import = False
+ while "as" in just_imports:
+ nested_module = None
+ as_index = just_imports.index("as")
+ if type_of_import == "from":
+ nested_module = just_imports[as_index - 1]
+ top_level_module = just_imports[0]
+ module = top_level_module + "." + nested_module
+ as_name = just_imports[as_index + 1]
+ if nested_module == as_name and config.remove_redundant_aliases:
+ pass
+ elif as_name not in as_map["from"][module]:
+ as_map["from"][module].append(as_name)
+ else:
+ module = just_imports[as_index - 1]
+ as_name = just_imports[as_index + 1]
+ if module == as_name and config.remove_redundant_aliases:
+ pass
+ elif as_name not in as_map["straight"][module]:
+ as_map["straight"][module].append(as_name)
+
+ if config.combine_as_imports and nested_module:
+ categorized_comments["from"].setdefault(
+ f"{top_level_module}.__combined_as__", []
+ ).extend(comments)
+ comments = []
+ else:
+ categorized_comments["straight"][module] = comments
+ comments = []
+ del just_imports[as_index : as_index + 2]
+ if type_of_import == "from":
+ import_from = just_imports.pop(0)
+ placed_module = finder(import_from)
+ if config.verbose:
+ print(f"from-type place_module for {import_from} returned {placed_module}")
+ if placed_module == "":
+ warn(
+ f"could not place module {import_from} of line {line} --"
+ " Do you need to define a default section?"
+ )
+ root = imports[placed_module][type_of_import] # type: ignore
+ for import_name in just_imports:
+ associated_comment = nested_comments.get(import_name)
+ if associated_comment:
+ categorized_comments["nested"].setdefault(import_from, {})[
+ import_name
+ ] = associated_comment
+ if associated_comment in comments:
+ comments.pop(comments.index(associated_comment))
+ if comments:
+ categorized_comments["from"].setdefault(import_from, []).extend(comments)
+
+ if len(out_lines) > max(import_index, 1) - 1:
+ last = out_lines and out_lines[-1].rstrip() or ""
+ while (
+ last.startswith("#")
+ and not last.endswith('"""')
+ and not last.endswith("'''")
+ and "isort:imports-" not in last
+ and "isort: imports-" not in last
+ and not config.treat_all_comments_as_code
+ and not last.strip() in config.treat_comments_as_code
+ ):
+ categorized_comments["above"]["from"].setdefault(import_from, []).insert(
+ 0, out_lines.pop(-1)
+ )
+ if out_lines:
+ last = out_lines[-1].rstrip()
+ else:
+ last = ""
+ if statement_index - 1 == import_index: # pragma: no cover
+ import_index -= len(
+ categorized_comments["above"]["from"].get(import_from, [])
+ )
+
+ if import_from not in root:
+ root[import_from] = OrderedDict(
+ (module, straight_import) for module in just_imports
+ )
+ else:
+ root[import_from].update(
+ (module, straight_import | root[import_from].get(module, False))
+ for module in just_imports
+ )
+ else:
+ for module in just_imports:
+ if comments:
+ categorized_comments["straight"][module] = comments
+ comments = []
+
+ if len(out_lines) > max(import_index, +1, 1) - 1:
+
+ last = out_lines and out_lines[-1].rstrip() or ""
+ while (
+ last.startswith("#")
+ and not last.endswith('"""')
+ and not last.endswith("'''")
+ and "isort:imports-" not in last
+ and "isort: imports-" not in last
+ and not config.treat_all_comments_as_code
+ and not last.strip() in config.treat_comments_as_code
+ ):
+ categorized_comments["above"]["straight"].setdefault(module, []).insert(
+ 0, out_lines.pop(-1)
+ )
+ if out_lines:
+ last = out_lines[-1].rstrip()
+ else:
+ last = ""
+ if index - 1 == import_index:
+ import_index -= len(
+ categorized_comments["above"]["straight"].get(module, [])
+ )
+ placed_module = finder(module)
+ if config.verbose:
+ print(f"else-type place_module for {module} returned {placed_module}")
+ if placed_module == "":
+ warn(
+ f"could not place module {module} of line {line} --"
+ " Do you need to define a default section?"
+ )
+ imports.setdefault("", {"straight": OrderedDict(), "from": OrderedDict()})
+ straight_import |= imports[placed_module][type_of_import].get( # type: ignore
+ module, False
+ )
+ imports[placed_module][type_of_import][module] = straight_import # type: ignore
+
+ change_count = len(out_lines) - original_line_count
+
+ return ParsedContent(
+ in_lines=in_lines,
+ lines_without_imports=out_lines,
+ import_index=import_index,
+ place_imports=place_imports,
+ import_placements=import_placements,
+ as_map=as_map,
+ imports=imports,
+ categorized_comments=categorized_comments,
+ change_count=change_count,
+ original_line_count=original_line_count,
+ line_separator=line_separator,
+ sections=config.sections,
+ )
diff --git a/venv/Lib/site-packages/isort/place.py b/venv/Lib/site-packages/isort/place.py
new file mode 100644
index 0000000000000000000000000000000000000000..34b2eeb86476766c68519f72b8e86842b66aa9ad
--- /dev/null
+++ b/venv/Lib/site-packages/isort/place.py
@@ -0,0 +1,95 @@
+"""Contains all logic related to placing an import within a certain section."""
+import importlib
+from fnmatch import fnmatch
+from functools import lru_cache
+from pathlib import Path
+from typing import Optional, Tuple
+
+from isort import sections
+from isort.settings import DEFAULT_CONFIG, Config
+from isort.utils import exists_case_sensitive
+
+LOCAL = "LOCALFOLDER"
+
+
+def module(name: str, config: Config = DEFAULT_CONFIG) -> str:
+ """Returns the section placement for the given module name."""
+ return module_with_reason(name, config)[0]
+
+
+@lru_cache(maxsize=1000)
+def module_with_reason(name: str, config: Config = DEFAULT_CONFIG) -> Tuple[str, str]:
+ """Returns the section placement for the given module name alongside the reasoning."""
+ return (
+ _forced_separate(name, config)
+ or _local(name, config)
+ or _known_pattern(name, config)
+ or _src_path(name, config)
+ or (config.default_section, "Default option in Config or universal default.")
+ )
+
+
+def _forced_separate(name: str, config: Config) -> Optional[Tuple[str, str]]:
+ for forced_separate in config.forced_separate:
+ # Ensure all forced_separate patterns will match to end of string
+ path_glob = forced_separate
+ if not forced_separate.endswith("*"):
+ path_glob = "%s*" % forced_separate
+
+ if fnmatch(name, path_glob) or fnmatch(name, "." + path_glob):
+ return (forced_separate, f"Matched forced_separate ({forced_separate}) config value.")
+
+ return None
+
+
+def _local(name: str, config: Config) -> Optional[Tuple[str, str]]:
+ if name.startswith("."):
+ return (LOCAL, "Module name started with a dot.")
+
+ return None
+
+
+def _known_pattern(name: str, config: Config) -> Optional[Tuple[str, str]]:
+ parts = name.split(".")
+ module_names_to_check = (".".join(parts[:first_k]) for first_k in range(len(parts), 0, -1))
+ for module_name_to_check in module_names_to_check:
+ for pattern, placement in config.known_patterns:
+ if pattern.match(module_name_to_check):
+ return (placement, f"Matched configured known pattern {pattern}")
+
+ return None
+
+
+def _src_path(name: str, config: Config) -> Optional[Tuple[str, str]]:
+ for src_path in config.src_paths:
+ root_module_name = name.split(".")[0]
+ module_path = (src_path / root_module_name).resolve()
+ if (
+ _is_module(module_path)
+ or _is_package(module_path)
+ or _src_path_is_module(src_path, root_module_name)
+ ):
+ return (sections.FIRSTPARTY, f"Found in one of the configured src_paths: {src_path}.")
+
+ return None
+
+
+def _is_module(path: Path) -> bool:
+ return (
+ exists_case_sensitive(str(path.with_suffix(".py")))
+ or any(
+ exists_case_sensitive(str(path.with_suffix(ext_suffix)))
+ for ext_suffix in importlib.machinery.EXTENSION_SUFFIXES
+ )
+ or exists_case_sensitive(str(path / "__init__.py"))
+ )
+
+
+def _is_package(path: Path) -> bool:
+ return exists_case_sensitive(str(path)) and path.is_dir()
+
+
+def _src_path_is_module(src_path: Path, module_name: str) -> bool:
+ return (
+ module_name == src_path.name and src_path.is_dir() and exists_case_sensitive(str(src_path))
+ )
diff --git a/venv/Lib/site-packages/isort/profiles.py b/venv/Lib/site-packages/isort/profiles.py
new file mode 100644
index 0000000000000000000000000000000000000000..cd976cd2963c16dbbdbf03af4c4e135562a7920e
--- /dev/null
+++ b/venv/Lib/site-packages/isort/profiles.py
@@ -0,0 +1,62 @@
+"""Common profiles are defined here to be easily used within a project using --profile {name}"""
+from typing import Any, Dict
+
+black = {
+ "multi_line_output": 3,
+ "include_trailing_comma": True,
+ "force_grid_wrap": 0,
+ "use_parentheses": True,
+ "ensure_newline_before_comments": True,
+ "line_length": 88,
+}
+django = {
+ "combine_as_imports": True,
+ "include_trailing_comma": True,
+ "multi_line_output": 5,
+ "line_length": 79,
+}
+pycharm = {"multi_line_output": 3, "force_grid_wrap": 2}
+google = {
+ "force_single_line": True,
+ "force_sort_within_sections": True,
+ "lexicographical": True,
+ "single_line_exclusions": ("typing",),
+}
+open_stack = {
+ "force_single_line": True,
+ "force_sort_within_sections": True,
+ "lexicographical": True,
+}
+plone = {
+ "force_alphabetical_sort": True,
+ "force_single_line": True,
+ "lines_after_imports": 2,
+ "line_length": 200,
+}
+attrs = {
+ "atomic": True,
+ "force_grid_wrap": 0,
+ "include_trailing_comma": True,
+ "lines_after_imports": 2,
+ "lines_between_types": 1,
+ "multi_line_output": 3,
+ "use_parentheses": True,
+}
+hug = {
+ "multi_line_output": 3,
+ "include_trailing_comma": True,
+ "force_grid_wrap": 0,
+ "use_parentheses": True,
+ "line_length": 100,
+}
+
+profiles: Dict[str, Dict[str, Any]] = {
+ "black": black,
+ "django": django,
+ "pycharm": pycharm,
+ "google": google,
+ "open_stack": open_stack,
+ "plone": plone,
+ "attrs": attrs,
+ "hug": hug,
+}
diff --git a/venv/Lib/site-packages/isort/pylama_isort.py b/venv/Lib/site-packages/isort/pylama_isort.py
new file mode 100644
index 0000000000000000000000000000000000000000..0e14d5696c4e552d70dab05b8cf55983e498f794
--- /dev/null
+++ b/venv/Lib/site-packages/isort/pylama_isort.py
@@ -0,0 +1,33 @@
+import os
+import sys
+from contextlib import contextmanager
+from typing import Any, Dict, List
+
+from pylama.lint import Linter as BaseLinter
+
+from . import api
+
+
+@contextmanager
+def supress_stdout():
+ stdout = sys.stdout
+ with open(os.devnull, "w") as devnull:
+ sys.stdout = devnull
+ yield
+ sys.stdout = stdout
+
+
+class Linter(BaseLinter):
+ def allow(self, path: str) -> bool:
+ """Determine if this path should be linted."""
+ return path.endswith(".py")
+
+ def run(self, path: str, **meta: Any) -> List[Dict[str, Any]]:
+ """Lint the file. Return an array of error dicts if appropriate."""
+ with supress_stdout():
+ if not api.check_file(path):
+ return [
+ {"lnum": 0, "col": 0, "text": "Incorrectly sorted imports.", "type": "ISORT"}
+ ]
+ else:
+ return []
diff --git a/venv/Lib/site-packages/isort/sections.py b/venv/Lib/site-packages/isort/sections.py
new file mode 100644
index 0000000000000000000000000000000000000000..f59db692611df0c6649c346a4f6d38dc6fdbc09d
--- /dev/null
+++ b/venv/Lib/site-packages/isort/sections.py
@@ -0,0 +1,9 @@
+"""Defines all sections isort uses by default"""
+from typing import Tuple
+
+FUTURE: str = "FUTURE"
+STDLIB: str = "STDLIB"
+THIRDPARTY: str = "THIRDPARTY"
+FIRSTPARTY: str = "FIRSTPARTY"
+LOCALFOLDER: str = "LOCALFOLDER"
+DEFAULT: Tuple[str, ...] = (FUTURE, STDLIB, THIRDPARTY, FIRSTPARTY, LOCALFOLDER)
diff --git a/venv/Lib/site-packages/isort/settings.py b/venv/Lib/site-packages/isort/settings.py
new file mode 100644
index 0000000000000000000000000000000000000000..500790bef875bd2d81d5017849c518d89aacfbb0
--- /dev/null
+++ b/venv/Lib/site-packages/isort/settings.py
@@ -0,0 +1,698 @@
+"""isort/settings.py.
+
+Defines how the default settings for isort should be loaded
+"""
+import configparser
+import fnmatch
+import os
+import posixpath
+import re
+import stat
+import subprocess # nosec: Needed for gitignore support.
+import sys
+from functools import lru_cache
+from pathlib import Path
+from typing import Any, Callable, Dict, FrozenSet, Iterable, List, Optional, Pattern, Set, Tuple
+from warnings import warn
+
+from . import stdlibs
+from ._future import dataclass, field
+from ._vendored import toml
+from .exceptions import FormattingPluginDoesNotExist, InvalidSettingsPath, ProfileDoesNotExist
+from .profiles import profiles
+from .sections import DEFAULT as SECTION_DEFAULTS
+from .sections import FIRSTPARTY, FUTURE, LOCALFOLDER, STDLIB, THIRDPARTY
+from .wrap_modes import WrapModes
+from .wrap_modes import from_string as wrap_mode_from_string
+
+_SHEBANG_RE = re.compile(br"^#!.*\bpython[23w]?\b")
+SUPPORTED_EXTENSIONS = frozenset({"py", "pyi", "pyx"})
+BLOCKED_EXTENSIONS = frozenset({"pex"})
+FILE_SKIP_COMMENTS: Tuple[str, ...] = (
+ "isort:" + "skip_file",
+ "isort: " + "skip_file",
+) # Concatenated to avoid this file being skipped
+MAX_CONFIG_SEARCH_DEPTH: int = 25 # The number of parent directories to for a config file within
+STOP_CONFIG_SEARCH_ON_DIRS: Tuple[str, ...] = (".git", ".hg")
+VALID_PY_TARGETS: Tuple[str, ...] = tuple(
+ target.replace("py", "") for target in dir(stdlibs) if not target.startswith("_")
+)
+CONFIG_SOURCES: Tuple[str, ...] = (
+ ".isort.cfg",
+ "pyproject.toml",
+ "setup.cfg",
+ "tox.ini",
+ ".editorconfig",
+)
+DEFAULT_SKIP: FrozenSet[str] = frozenset(
+ {
+ ".venv",
+ "venv",
+ ".tox",
+ ".eggs",
+ ".git",
+ ".hg",
+ ".mypy_cache",
+ ".nox",
+ "_build",
+ "buck-out",
+ "build",
+ "dist",
+ ".pants.d",
+ "node_modules",
+ }
+)
+
+CONFIG_SECTIONS: Dict[str, Tuple[str, ...]] = {
+ ".isort.cfg": ("settings", "isort"),
+ "pyproject.toml": ("tool.isort",),
+ "setup.cfg": ("isort", "tool:isort"),
+ "tox.ini": ("isort", "tool:isort"),
+ ".editorconfig": ("*", "*.py", "**.py", "*.{py}"),
+}
+FALLBACK_CONFIG_SECTIONS: Tuple[str, ...] = ("isort", "tool:isort", "tool.isort")
+
+IMPORT_HEADING_PREFIX = "import_heading_"
+KNOWN_PREFIX = "known_"
+KNOWN_SECTION_MAPPING: Dict[str, str] = {
+ STDLIB: "STANDARD_LIBRARY",
+ FUTURE: "FUTURE_LIBRARY",
+ FIRSTPARTY: "FIRST_PARTY",
+ THIRDPARTY: "THIRD_PARTY",
+ LOCALFOLDER: "LOCAL_FOLDER",
+}
+
+RUNTIME_SOURCE = "runtime"
+
+DEPRECATED_SETTINGS = ("not_skip", "keep_direct_and_as_imports")
+
+_STR_BOOLEAN_MAPPING = {
+ "y": True,
+ "yes": True,
+ "t": True,
+ "on": True,
+ "1": True,
+ "true": True,
+ "n": False,
+ "no": False,
+ "f": False,
+ "off": False,
+ "0": False,
+ "false": False,
+}
+
+
+@dataclass(frozen=True)
+class _Config:
+ """Defines the data schema and defaults used for isort configuration.
+
+ NOTE: known lists, such as known_standard_library, are intentionally not complete as they are
+ dynamically determined later on.
+ """
+
+ py_version: str = "3"
+ force_to_top: FrozenSet[str] = frozenset()
+ skip: FrozenSet[str] = DEFAULT_SKIP
+ skip_glob: FrozenSet[str] = frozenset()
+ skip_gitignore: bool = False
+ line_length: int = 79
+ wrap_length: int = 0
+ line_ending: str = ""
+ sections: Tuple[str, ...] = SECTION_DEFAULTS
+ no_sections: bool = False
+ known_future_library: FrozenSet[str] = frozenset(("__future__",))
+ known_third_party: FrozenSet[str] = frozenset()
+ known_first_party: FrozenSet[str] = frozenset()
+ known_local_folder: FrozenSet[str] = frozenset()
+ known_standard_library: FrozenSet[str] = frozenset()
+ extra_standard_library: FrozenSet[str] = frozenset()
+ known_other: Dict[str, FrozenSet[str]] = field(default_factory=dict)
+ multi_line_output: WrapModes = WrapModes.GRID # type: ignore
+ forced_separate: Tuple[str, ...] = ()
+ indent: str = " " * 4
+ comment_prefix: str = " #"
+ length_sort: bool = False
+ length_sort_straight: bool = False
+ length_sort_sections: FrozenSet[str] = frozenset()
+ add_imports: FrozenSet[str] = frozenset()
+ remove_imports: FrozenSet[str] = frozenset()
+ append_only: bool = False
+ reverse_relative: bool = False
+ force_single_line: bool = False
+ single_line_exclusions: Tuple[str, ...] = ()
+ default_section: str = THIRDPARTY
+ import_headings: Dict[str, str] = field(default_factory=dict)
+ balanced_wrapping: bool = False
+ use_parentheses: bool = False
+ order_by_type: bool = True
+ atomic: bool = False
+ lines_after_imports: int = -1
+ lines_between_sections: int = 1
+ lines_between_types: int = 0
+ combine_as_imports: bool = False
+ combine_star: bool = False
+ include_trailing_comma: bool = False
+ from_first: bool = False
+ verbose: bool = False
+ quiet: bool = False
+ force_adds: bool = False
+ force_alphabetical_sort_within_sections: bool = False
+ force_alphabetical_sort: bool = False
+ force_grid_wrap: int = 0
+ force_sort_within_sections: bool = False
+ lexicographical: bool = False
+ ignore_whitespace: bool = False
+ no_lines_before: FrozenSet[str] = frozenset()
+ no_inline_sort: bool = False
+ ignore_comments: bool = False
+ case_sensitive: bool = False
+ sources: Tuple[Dict[str, Any], ...] = ()
+ virtual_env: str = ""
+ conda_env: str = ""
+ ensure_newline_before_comments: bool = False
+ directory: str = ""
+ profile: str = ""
+ honor_noqa: bool = False
+ src_paths: FrozenSet[Path] = frozenset()
+ old_finders: bool = False
+ remove_redundant_aliases: bool = False
+ float_to_top: bool = False
+ filter_files: bool = False
+ formatter: str = ""
+ formatting_function: Optional[Callable[[str, str, object], str]] = None
+ color_output: bool = False
+ treat_comments_as_code: FrozenSet[str] = frozenset()
+ treat_all_comments_as_code: bool = False
+ supported_extensions: FrozenSet[str] = SUPPORTED_EXTENSIONS
+ blocked_extensions: FrozenSet[str] = BLOCKED_EXTENSIONS
+ constants: FrozenSet[str] = frozenset()
+ classes: FrozenSet[str] = frozenset()
+ variables: FrozenSet[str] = frozenset()
+ dedup_headings: bool = False
+
+ def __post_init__(self):
+ py_version = self.py_version
+ if py_version == "auto": # pragma: no cover
+ if sys.version_info.major == 2 and sys.version_info.minor <= 6:
+ py_version = "2"
+ elif sys.version_info.major == 3 and (
+ sys.version_info.minor <= 5 or sys.version_info.minor >= 9
+ ):
+ py_version = "3"
+ else:
+ py_version = f"{sys.version_info.major}{sys.version_info.minor}"
+
+ if py_version not in VALID_PY_TARGETS:
+ raise ValueError(
+ f"The python version {py_version} is not supported. "
+ "You can set a python version with the -py or --python-version flag. "
+ f"The following versions are supported: {VALID_PY_TARGETS}"
+ )
+
+ if py_version != "all":
+ object.__setattr__(self, "py_version", f"py{py_version}")
+
+ if not self.known_standard_library:
+ object.__setattr__(
+ self, "known_standard_library", frozenset(getattr(stdlibs, self.py_version).stdlib)
+ )
+
+ if self.force_alphabetical_sort:
+ object.__setattr__(self, "force_alphabetical_sort_within_sections", True)
+ object.__setattr__(self, "no_sections", True)
+ object.__setattr__(self, "lines_between_types", 1)
+ object.__setattr__(self, "from_first", True)
+ if self.wrap_length > self.line_length:
+ raise ValueError(
+ "wrap_length must be set lower than or equal to line_length: "
+ f"{self.wrap_length} > {self.line_length}."
+ )
+
+ def __hash__(self):
+ return id(self)
+
+
+_DEFAULT_SETTINGS = {**vars(_Config()), "source": "defaults"}
+
+
+class Config(_Config):
+ def __init__(
+ self,
+ settings_file: str = "",
+ settings_path: str = "",
+ config: Optional[_Config] = None,
+ **config_overrides,
+ ):
+ self._known_patterns: Optional[List[Tuple[Pattern[str], str]]] = None
+ self._section_comments: Optional[Tuple[str, ...]] = None
+
+ if config:
+ config_vars = vars(config).copy()
+ config_vars.update(config_overrides)
+ config_vars["py_version"] = config_vars["py_version"].replace("py", "")
+ config_vars.pop("_known_patterns")
+ config_vars.pop("_section_comments")
+ super().__init__(**config_vars) # type: ignore
+ return
+
+ sources: List[Dict[str, Any]] = [_DEFAULT_SETTINGS]
+
+ config_settings: Dict[str, Any]
+ project_root: str
+ if settings_file:
+ config_settings = _get_config_data(
+ settings_file,
+ CONFIG_SECTIONS.get(os.path.basename(settings_file), FALLBACK_CONFIG_SECTIONS),
+ )
+ project_root = os.path.dirname(settings_file)
+ elif settings_path:
+ if not os.path.exists(settings_path):
+ raise InvalidSettingsPath(settings_path)
+
+ settings_path = os.path.abspath(settings_path)
+ project_root, config_settings = _find_config(settings_path)
+ else:
+ config_settings = {}
+ project_root = os.getcwd()
+
+ profile_name = config_overrides.get("profile", config_settings.get("profile", ""))
+ profile: Dict[str, Any] = {}
+ if profile_name:
+ if profile_name not in profiles:
+ import pkg_resources
+
+ for plugin in pkg_resources.iter_entry_points("isort.profiles"):
+ profiles.setdefault(plugin.name, plugin.load())
+
+ if profile_name not in profiles:
+ raise ProfileDoesNotExist(profile_name)
+
+ profile = profiles[profile_name].copy()
+ profile["source"] = f"{profile_name} profile"
+ sources.append(profile)
+
+ if config_settings:
+ sources.append(config_settings)
+ if config_overrides:
+ config_overrides["source"] = RUNTIME_SOURCE
+ sources.append(config_overrides)
+
+ combined_config = {**profile, **config_settings, **config_overrides}
+ if "indent" in combined_config:
+ indent = str(combined_config["indent"])
+ if indent.isdigit():
+ indent = " " * int(indent)
+ else:
+ indent = indent.strip("'").strip('"')
+ if indent.lower() == "tab":
+ indent = "\t"
+ combined_config["indent"] = indent
+
+ known_other = {}
+ import_headings = {}
+ for key, value in tuple(combined_config.items()):
+ # Collect all known sections beyond those that have direct entries
+ if key.startswith(KNOWN_PREFIX) and key not in (
+ "known_standard_library",
+ "known_future_library",
+ "known_third_party",
+ "known_first_party",
+ "known_local_folder",
+ ):
+ import_heading = key[len(KNOWN_PREFIX) :].lower()
+ maps_to_section = import_heading.upper()
+ combined_config.pop(key)
+ if maps_to_section in KNOWN_SECTION_MAPPING:
+ section_name = f"known_{KNOWN_SECTION_MAPPING[maps_to_section].lower()}"
+ if section_name in combined_config and not self.quiet:
+ warn(
+ f"Can't set both {key} and {section_name} in the same config file.\n"
+ f"Default to {section_name} if unsure."
+ "\n\n"
+ "See: https://timothycrosley.github.io/isort/"
+ "#custom-sections-and-ordering."
+ )
+ else:
+ combined_config[section_name] = frozenset(value)
+ else:
+ known_other[import_heading] = frozenset(value)
+ if (
+ maps_to_section not in combined_config.get("sections", ())
+ and not self.quiet
+ ):
+ warn(
+ f"`{key}` setting is defined, but {maps_to_section} is not"
+ " included in `sections` config option:"
+ f" {combined_config.get('sections', SECTION_DEFAULTS)}.\n\n"
+ "See: https://timothycrosley.github.io/isort/"
+ "#custom-sections-and-ordering."
+ )
+ if key.startswith(IMPORT_HEADING_PREFIX):
+ import_headings[key[len(IMPORT_HEADING_PREFIX) :].lower()] = str(value)
+
+ # Coerce all provided config values into their correct type
+ default_value = _DEFAULT_SETTINGS.get(key, None)
+ if default_value is None:
+ continue
+
+ combined_config[key] = type(default_value)(value)
+
+ for section in combined_config.get("sections", ()):
+ if section in SECTION_DEFAULTS:
+ continue
+ elif not section.lower() in known_other:
+ config_keys = ", ".join(known_other.keys())
+ warn(
+ f"`sections` setting includes {section}, but no known_{section.lower()} "
+ "is defined. "
+ f"The following known_SECTION config options are defined: {config_keys}."
+ )
+
+ if "directory" not in combined_config:
+ combined_config["directory"] = (
+ os.path.dirname(config_settings["source"])
+ if config_settings.get("source", None)
+ else os.getcwd()
+ )
+
+ path_root = Path(combined_config.get("directory", project_root)).resolve()
+ path_root = path_root if path_root.is_dir() else path_root.parent
+ if "src_paths" not in combined_config:
+ combined_config["src_paths"] = frozenset((path_root, path_root / "src"))
+ else:
+ combined_config["src_paths"] = frozenset(
+ path_root / path for path in combined_config.get("src_paths", ())
+ )
+
+ if "formatter" in combined_config:
+ import pkg_resources
+
+ for plugin in pkg_resources.iter_entry_points("isort.formatters"):
+ if plugin.name == combined_config["formatter"]:
+ combined_config["formatting_function"] = plugin.load()
+ break
+ else:
+ raise FormattingPluginDoesNotExist(combined_config["formatter"])
+
+ # Remove any config values that are used for creating config object but
+ # aren't defined in dataclass
+ combined_config.pop("source", None)
+ combined_config.pop("sources", None)
+ combined_config.pop("runtime_src_paths", None)
+
+ deprecated_options_used = [
+ option for option in combined_config if option in DEPRECATED_SETTINGS
+ ]
+ if deprecated_options_used:
+ for deprecated_option in deprecated_options_used:
+ combined_config.pop(deprecated_option)
+ if not self.quiet:
+ warn(
+ "W0503: Deprecated config options were used: "
+ f"{', '.join(deprecated_options_used)}."
+ "Please see the 5.0.0 upgrade guide: bit.ly/isortv5."
+ )
+
+ if known_other:
+ combined_config["known_other"] = known_other
+ if import_headings:
+ for import_heading_key in import_headings:
+ combined_config.pop(f"{IMPORT_HEADING_PREFIX}{import_heading_key}")
+ combined_config["import_headings"] = import_headings
+
+ super().__init__(sources=tuple(sources), **combined_config) # type: ignore
+
+ def is_supported_filetype(self, file_name: str):
+ _root, ext = os.path.splitext(file_name)
+ ext = ext.lstrip(".")
+ if ext in self.supported_extensions:
+ return True
+ elif ext in self.blocked_extensions:
+ return False
+
+ # Skip editor backup files.
+ if file_name.endswith("~"):
+ return False
+
+ try:
+ if stat.S_ISFIFO(os.stat(file_name).st_mode):
+ return False
+ except OSError:
+ pass
+
+ try:
+ with open(file_name, "rb") as fp:
+ line = fp.readline(100)
+ except OSError:
+ return False
+ else:
+ return bool(_SHEBANG_RE.match(line))
+
+ def is_skipped(self, file_path: Path) -> bool:
+ """Returns True if the file and/or folder should be skipped based on current settings."""
+ if self.directory and Path(self.directory) in file_path.resolve().parents:
+ file_name = os.path.relpath(file_path.resolve(), self.directory)
+ else:
+ file_name = str(file_path)
+
+ os_path = str(file_path)
+
+ if self.skip_gitignore:
+ if file_path.name == ".git": # pragma: no cover
+ return True
+
+ result = subprocess.run( # nosec
+ ["git", "-C", str(file_path.parent), "check-ignore", "--quiet", os_path]
+ )
+ if result.returncode == 0:
+ return True
+
+ normalized_path = os_path.replace("\\", "/")
+ if normalized_path[1:2] == ":":
+ normalized_path = normalized_path[2:]
+
+ for skip_path in self.skip:
+ if posixpath.abspath(normalized_path) == posixpath.abspath(
+ skip_path.replace("\\", "/")
+ ):
+ return True
+
+ position = os.path.split(file_name)
+ while position[1]:
+ if position[1] in self.skip:
+ return True
+ position = os.path.split(position[0])
+
+ for glob in self.skip_glob:
+ if fnmatch.fnmatch(file_name, glob) or fnmatch.fnmatch("/" + file_name, glob):
+ return True
+
+ if not (os.path.isfile(os_path) or os.path.isdir(os_path) or os.path.islink(os_path)):
+ return True
+
+ return False
+
+ @property
+ def known_patterns(self):
+ if self._known_patterns is not None:
+ return self._known_patterns
+
+ self._known_patterns = []
+ for placement in reversed(self.sections):
+ known_placement = KNOWN_SECTION_MAPPING.get(placement, placement).lower()
+ config_key = f"{KNOWN_PREFIX}{known_placement}"
+ known_modules = getattr(self, config_key, self.known_other.get(known_placement, ()))
+ extra_modules = getattr(self, f"extra_{known_placement}", ())
+ all_modules = set(known_modules).union(extra_modules)
+ known_patterns = [
+ pattern
+ for known_pattern in all_modules
+ for pattern in self._parse_known_pattern(known_pattern)
+ ]
+ for known_pattern in known_patterns:
+ regexp = "^" + known_pattern.replace("*", ".*").replace("?", ".?") + "$"
+ self._known_patterns.append((re.compile(regexp), placement))
+
+ return self._known_patterns
+
+ @property
+ def section_comments(self) -> Tuple[str, ...]:
+ if self._section_comments is not None:
+ return self._section_comments
+
+ self._section_comments = tuple(f"# {heading}" for heading in self.import_headings.values())
+ return self._section_comments
+
+ def _parse_known_pattern(self, pattern: str) -> List[str]:
+ """Expand pattern if identified as a directory and return found sub packages"""
+ if pattern.endswith(os.path.sep):
+ patterns = [
+ filename
+ for filename in os.listdir(os.path.join(self.directory, pattern))
+ if os.path.isdir(os.path.join(self.directory, pattern, filename))
+ ]
+ else:
+ patterns = [pattern]
+
+ return patterns
+
+
+def _get_str_to_type_converter(setting_name: str) -> Callable[[str], Any]:
+ type_converter: Callable[[str], Any] = type(_DEFAULT_SETTINGS.get(setting_name, ""))
+ if type_converter == WrapModes:
+ type_converter = wrap_mode_from_string
+ return type_converter
+
+
+def _as_list(value: str) -> List[str]:
+ if isinstance(value, list):
+ return [item.strip() for item in value]
+ filtered = [item.strip() for item in value.replace("\n", ",").split(",") if item.strip()]
+ return filtered
+
+
+def _abspaths(cwd: str, values: Iterable[str]) -> Set[str]:
+ paths = {
+ os.path.join(cwd, value)
+ if not value.startswith(os.path.sep) and value.endswith(os.path.sep)
+ else value
+ for value in values
+ }
+ return paths
+
+
+@lru_cache()
+def _find_config(path: str) -> Tuple[str, Dict[str, Any]]:
+ current_directory = path
+ tries = 0
+ while current_directory and tries < MAX_CONFIG_SEARCH_DEPTH:
+ for config_file_name in CONFIG_SOURCES:
+ potential_config_file = os.path.join(current_directory, config_file_name)
+ if os.path.isfile(potential_config_file):
+ config_data: Dict[str, Any]
+ try:
+ config_data = _get_config_data(
+ potential_config_file, CONFIG_SECTIONS[config_file_name]
+ )
+ except Exception:
+ warn(f"Failed to pull configuration information from {potential_config_file}")
+ config_data = {}
+ if config_data:
+ return (current_directory, config_data)
+
+ for stop_dir in STOP_CONFIG_SEARCH_ON_DIRS:
+ if os.path.isdir(os.path.join(current_directory, stop_dir)):
+ return (current_directory, {})
+
+ new_directory = os.path.split(current_directory)[0]
+ if new_directory == current_directory:
+ break
+
+ current_directory = new_directory
+ tries += 1
+
+ return (path, {})
+
+
+@lru_cache()
+def _get_config_data(file_path: str, sections: Tuple[str]) -> Dict[str, Any]:
+ settings: Dict[str, Any] = {}
+
+ with open(file_path) as config_file:
+ if file_path.endswith(".toml"):
+ config = toml.load(config_file)
+ for section in sections:
+ config_section = config
+ for key in section.split("."):
+ config_section = config_section.get(key, {})
+ settings.update(config_section)
+ else:
+ if file_path.endswith(".editorconfig"):
+ line = "\n"
+ last_position = config_file.tell()
+ while line:
+ line = config_file.readline()
+ if "[" in line:
+ config_file.seek(last_position)
+ break
+ last_position = config_file.tell()
+
+ config = configparser.ConfigParser(strict=False)
+ config.read_file(config_file)
+ for section in sections:
+ if section.startswith("*.{") and section.endswith("}"):
+ extension = section[len("*.{") : -1]
+ for config_key in config.keys():
+ if config_key.startswith("*.{") and config_key.endswith("}"):
+ if extension in map(
+ lambda text: text.strip(), config_key[len("*.{") : -1].split(",")
+ ):
+ settings.update(config.items(config_key))
+
+ elif config.has_section(section):
+ settings.update(config.items(section))
+
+ if settings:
+ settings["source"] = file_path
+
+ if file_path.endswith(".editorconfig"):
+ indent_style = settings.pop("indent_style", "").strip()
+ indent_size = settings.pop("indent_size", "").strip()
+ if indent_size == "tab":
+ indent_size = settings.pop("tab_width", "").strip()
+
+ if indent_style == "space":
+ settings["indent"] = " " * (indent_size and int(indent_size) or 4)
+
+ elif indent_style == "tab":
+ settings["indent"] = "\t" * (indent_size and int(indent_size) or 1)
+
+ max_line_length = settings.pop("max_line_length", "").strip()
+ if max_line_length and (max_line_length == "off" or max_line_length.isdigit()):
+ settings["line_length"] = (
+ float("inf") if max_line_length == "off" else int(max_line_length)
+ )
+ settings = {
+ key: value
+ for key, value in settings.items()
+ if key in _DEFAULT_SETTINGS.keys() or key.startswith(KNOWN_PREFIX)
+ }
+
+ for key, value in settings.items():
+ existing_value_type = _get_str_to_type_converter(key)
+ if existing_value_type == tuple:
+ settings[key] = tuple(_as_list(value))
+ elif existing_value_type == frozenset:
+ settings[key] = frozenset(_as_list(settings.get(key))) # type: ignore
+ elif existing_value_type == bool:
+ # Only some configuration formats support native boolean values.
+ if not isinstance(value, bool):
+ value = _as_bool(value)
+ settings[key] = value
+ elif key.startswith(KNOWN_PREFIX):
+ settings[key] = _abspaths(os.path.dirname(file_path), _as_list(value))
+ elif key == "force_grid_wrap":
+ try:
+ result = existing_value_type(value)
+ except ValueError: # backwards compatibility for true / false force grid wrap
+ result = 0 if value.lower().strip() == "false" else 2
+ settings[key] = result
+ elif key == "comment_prefix":
+ settings[key] = str(value).strip("'").strip('"')
+ else:
+ settings[key] = existing_value_type(value)
+
+ return settings
+
+
+def _as_bool(value: str) -> bool:
+ """Given a string value that represents True or False, returns the Boolean equivalent.
+ Heavily inspired from distutils strtobool.
+ """
+ try:
+ return _STR_BOOLEAN_MAPPING[value.lower()]
+ except KeyError:
+ raise ValueError(f"invalid truth value {value}")
+
+
+DEFAULT_CONFIG = Config()
diff --git a/venv/Lib/site-packages/isort/setuptools_commands.py b/venv/Lib/site-packages/isort/setuptools_commands.py
new file mode 100644
index 0000000000000000000000000000000000000000..f67008877f0d5519fee15c4597d311605235ba09
--- /dev/null
+++ b/venv/Lib/site-packages/isort/setuptools_commands.py
@@ -0,0 +1,61 @@
+import glob
+import os
+import sys
+from typing import Any, Dict, Iterator, List
+from warnings import warn
+
+import setuptools
+
+from . import api
+from .settings import DEFAULT_CONFIG
+
+
+class ISortCommand(setuptools.Command):
+ """The :class:`ISortCommand` class is used by setuptools to perform
+ imports checks on registered modules.
+ """
+
+ description = "Run isort on modules registered in setuptools"
+ user_options: List[Any] = []
+
+ def initialize_options(self) -> None:
+ default_settings = vars(DEFAULT_CONFIG).copy()
+ for key, value in default_settings.items():
+ setattr(self, key, value)
+
+ def finalize_options(self) -> None:
+ "Get options from config files."
+ self.arguments: Dict[str, Any] = {} # skipcq: PYL-W0201
+ self.arguments["settings_path"] = os.getcwd()
+
+ def distribution_files(self) -> Iterator[str]:
+ """Find distribution packages."""
+ # This is verbatim from flake8
+ if self.distribution.packages:
+ package_dirs = self.distribution.package_dir or {}
+ for package in self.distribution.packages:
+ pkg_dir = package
+ if package in package_dirs:
+ pkg_dir = package_dirs[package]
+ elif "" in package_dirs:
+ pkg_dir = package_dirs[""] + os.path.sep + pkg_dir
+ yield pkg_dir.replace(".", os.path.sep)
+
+ if self.distribution.py_modules:
+ for filename in self.distribution.py_modules:
+ yield "%s.py" % filename
+ # Don't miss the setup.py file itself
+ yield "setup.py"
+
+ def run(self) -> None:
+ arguments = self.arguments
+ wrong_sorted_files = False
+ for path in self.distribution_files():
+ for python_file in glob.iglob(os.path.join(path, "*.py")):
+ try:
+ if not api.check_file(python_file, **arguments):
+ wrong_sorted_files = True # pragma: no cover
+ except OSError as error: # pragma: no cover
+ warn(f"Unable to parse file {python_file} due to {error}")
+ if wrong_sorted_files:
+ sys.exit(1) # pragma: no cover
diff --git a/venv/Lib/site-packages/isort/sorting.py b/venv/Lib/site-packages/isort/sorting.py
new file mode 100644
index 0000000000000000000000000000000000000000..1664a2f28e583d03c1c17e8269fbcce8e3407d7c
--- /dev/null
+++ b/venv/Lib/site-packages/isort/sorting.py
@@ -0,0 +1,93 @@
+import re
+from typing import Any, Callable, Iterable, List, Optional
+
+from .settings import Config
+
+_import_line_intro_re = re.compile("^(?:from|import) ")
+_import_line_midline_import_re = re.compile(" import ")
+
+
+def module_key(
+ module_name: str,
+ config: Config,
+ sub_imports: bool = False,
+ ignore_case: bool = False,
+ section_name: Optional[Any] = None,
+ straight_import: Optional[bool] = False,
+) -> str:
+ match = re.match(r"^(\.+)\s*(.*)", module_name)
+ if match:
+ sep = " " if config.reverse_relative else "_"
+ module_name = sep.join(match.groups())
+
+ prefix = ""
+ if ignore_case:
+ module_name = str(module_name).lower()
+ else:
+ module_name = str(module_name)
+
+ if sub_imports and config.order_by_type:
+ if module_name in config.constants:
+ prefix = "A"
+ elif module_name in config.classes:
+ prefix = "B"
+ elif module_name in config.variables:
+ prefix = "C"
+ elif module_name.isupper() and len(module_name) > 1: # see issue #376
+ prefix = "A"
+ elif module_name in config.classes or module_name[0:1].isupper():
+ prefix = "B"
+ else:
+ prefix = "C"
+ if not config.case_sensitive:
+ module_name = module_name.lower()
+
+ length_sort = (
+ config.length_sort
+ or (config.length_sort_straight and straight_import)
+ or str(section_name).lower() in config.length_sort_sections
+ )
+ _length_sort_maybe = length_sort and (str(len(module_name)) + ":" + module_name) or module_name
+ return f"{module_name in config.force_to_top and 'A' or 'B'}{prefix}{_length_sort_maybe}"
+
+
+def section_key(
+ line: str,
+ order_by_type: bool,
+ force_to_top: List[str],
+ lexicographical: bool = False,
+ length_sort: bool = False,
+) -> str:
+ section = "B"
+
+ if lexicographical:
+ line = _import_line_intro_re.sub("", _import_line_midline_import_re.sub(".", line))
+ else:
+ line = re.sub("^from ", "", line)
+ line = re.sub("^import ", "", line)
+ if line.split(" ")[0] in force_to_top:
+ section = "A"
+ if not order_by_type:
+ line = line.lower()
+
+ return f"{section}{len(line) if length_sort else ''}{line}"
+
+
+def naturally(to_sort: Iterable[str], key: Optional[Callable[[str], Any]] = None) -> List[str]:
+ """Returns a naturally sorted list"""
+ if key is None:
+ key_callback = _natural_keys
+ else:
+
+ def key_callback(text: str) -> List[Any]:
+ return _natural_keys(key(text)) # type: ignore
+
+ return sorted(to_sort, key=key_callback)
+
+
+def _atoi(text: str) -> Any:
+ return int(text) if text.isdigit() else text
+
+
+def _natural_keys(text: str) -> List[Any]:
+ return [_atoi(c) for c in re.split(r"(\d+)", text)]
diff --git a/venv/Lib/site-packages/isort/stdlibs/__init__.py b/venv/Lib/site-packages/isort/stdlibs/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..9021bc4557044f1dafdcaae2a77fe5eda3a71854
--- /dev/null
+++ b/venv/Lib/site-packages/isort/stdlibs/__init__.py
@@ -0,0 +1 @@
+from . import all, py2, py3, py27, py35, py36, py37, py38, py39
diff --git a/venv/Lib/site-packages/isort/stdlibs/all.py b/venv/Lib/site-packages/isort/stdlibs/all.py
new file mode 100644
index 0000000000000000000000000000000000000000..08a365e19e18d65cdcb42611ebb4824ffbfc9a7f
--- /dev/null
+++ b/venv/Lib/site-packages/isort/stdlibs/all.py
@@ -0,0 +1,3 @@
+from . import py2, py3
+
+stdlib = py2.stdlib | py3.stdlib
diff --git a/venv/Lib/site-packages/isort/stdlibs/py2.py b/venv/Lib/site-packages/isort/stdlibs/py2.py
new file mode 100644
index 0000000000000000000000000000000000000000..74af019e4910b5243a38939e3cd620b3f1d843e6
--- /dev/null
+++ b/venv/Lib/site-packages/isort/stdlibs/py2.py
@@ -0,0 +1,3 @@
+from . import py27
+
+stdlib = py27.stdlib
diff --git a/venv/Lib/site-packages/isort/stdlibs/py27.py b/venv/Lib/site-packages/isort/stdlibs/py27.py
new file mode 100644
index 0000000000000000000000000000000000000000..87aa67f1ffb1adc78a0bd9ac1ba9aed032a8c62c
--- /dev/null
+++ b/venv/Lib/site-packages/isort/stdlibs/py27.py
@@ -0,0 +1,300 @@
+"""
+File contains the standard library of Python 2.7.
+
+DO NOT EDIT. If the standard library changes, a new list should be created
+using the mkstdlibs.py script.
+"""
+
+stdlib = {
+ "AL",
+ "BaseHTTPServer",
+ "Bastion",
+ "CGIHTTPServer",
+ "Carbon",
+ "ColorPicker",
+ "ConfigParser",
+ "Cookie",
+ "DEVICE",
+ "DocXMLRPCServer",
+ "EasyDialogs",
+ "FL",
+ "FrameWork",
+ "GL",
+ "HTMLParser",
+ "MacOS",
+ "MimeWriter",
+ "MiniAEFrame",
+ "Nav",
+ "PixMapWrapper",
+ "Queue",
+ "SUNAUDIODEV",
+ "ScrolledText",
+ "SimpleHTTPServer",
+ "SimpleXMLRPCServer",
+ "SocketServer",
+ "StringIO",
+ "Tix",
+ "Tkinter",
+ "UserDict",
+ "UserList",
+ "UserString",
+ "W",
+ "__builtin__",
+ "_winreg",
+ "abc",
+ "aepack",
+ "aetools",
+ "aetypes",
+ "aifc",
+ "al",
+ "anydbm",
+ "applesingle",
+ "argparse",
+ "array",
+ "ast",
+ "asynchat",
+ "asyncore",
+ "atexit",
+ "audioop",
+ "autoGIL",
+ "base64",
+ "bdb",
+ "binascii",
+ "binhex",
+ "bisect",
+ "bsddb",
+ "buildtools",
+ "bz2",
+ "cPickle",
+ "cProfile",
+ "cStringIO",
+ "calendar",
+ "cd",
+ "cfmfile",
+ "cgi",
+ "cgitb",
+ "chunk",
+ "cmath",
+ "cmd",
+ "code",
+ "codecs",
+ "codeop",
+ "collections",
+ "colorsys",
+ "commands",
+ "compileall",
+ "compiler",
+ "contextlib",
+ "cookielib",
+ "copy",
+ "copy_reg",
+ "crypt",
+ "csv",
+ "ctypes",
+ "curses",
+ "datetime",
+ "dbhash",
+ "dbm",
+ "decimal",
+ "difflib",
+ "dircache",
+ "dis",
+ "distutils",
+ "dl",
+ "doctest",
+ "dumbdbm",
+ "dummy_thread",
+ "dummy_threading",
+ "email",
+ "encodings",
+ "ensurepip",
+ "errno",
+ "exceptions",
+ "fcntl",
+ "filecmp",
+ "fileinput",
+ "findertools",
+ "fl",
+ "flp",
+ "fm",
+ "fnmatch",
+ "formatter",
+ "fpectl",
+ "fpformat",
+ "fractions",
+ "ftplib",
+ "functools",
+ "future_builtins",
+ "gc",
+ "gdbm",
+ "gensuitemodule",
+ "getopt",
+ "getpass",
+ "gettext",
+ "gl",
+ "glob",
+ "grp",
+ "gzip",
+ "hashlib",
+ "heapq",
+ "hmac",
+ "hotshot",
+ "htmlentitydefs",
+ "htmllib",
+ "httplib",
+ "ic",
+ "icopen",
+ "imageop",
+ "imaplib",
+ "imgfile",
+ "imghdr",
+ "imp",
+ "importlib",
+ "imputil",
+ "inspect",
+ "io",
+ "itertools",
+ "jpeg",
+ "json",
+ "keyword",
+ "lib2to3",
+ "linecache",
+ "locale",
+ "logging",
+ "macerrors",
+ "macostools",
+ "macpath",
+ "macresource",
+ "mailbox",
+ "mailcap",
+ "marshal",
+ "math",
+ "md5",
+ "mhlib",
+ "mimetools",
+ "mimetypes",
+ "mimify",
+ "mmap",
+ "modulefinder",
+ "msilib",
+ "msvcrt",
+ "multifile",
+ "multiprocessing",
+ "mutex",
+ "netrc",
+ "new",
+ "nis",
+ "nntplib",
+ "ntpath",
+ "numbers",
+ "operator",
+ "optparse",
+ "os",
+ "ossaudiodev",
+ "parser",
+ "pdb",
+ "pickle",
+ "pickletools",
+ "pipes",
+ "pkgutil",
+ "platform",
+ "plistlib",
+ "popen2",
+ "poplib",
+ "posix",
+ "posixfile",
+ "posixpath",
+ "pprint",
+ "profile",
+ "pstats",
+ "pty",
+ "pwd",
+ "py_compile",
+ "pyclbr",
+ "pydoc",
+ "quopri",
+ "random",
+ "re",
+ "readline",
+ "resource",
+ "rexec",
+ "rfc822",
+ "rlcompleter",
+ "robotparser",
+ "runpy",
+ "sched",
+ "select",
+ "sets",
+ "sgmllib",
+ "sha",
+ "shelve",
+ "shlex",
+ "shutil",
+ "signal",
+ "site",
+ "smtpd",
+ "smtplib",
+ "sndhdr",
+ "socket",
+ "spwd",
+ "sqlite3",
+ "sre",
+ "sre_compile",
+ "sre_constants",
+ "sre_parse",
+ "ssl",
+ "stat",
+ "statvfs",
+ "string",
+ "stringprep",
+ "struct",
+ "subprocess",
+ "sunau",
+ "sunaudiodev",
+ "symbol",
+ "symtable",
+ "sys",
+ "sysconfig",
+ "syslog",
+ "tabnanny",
+ "tarfile",
+ "telnetlib",
+ "tempfile",
+ "termios",
+ "test",
+ "textwrap",
+ "thread",
+ "threading",
+ "time",
+ "timeit",
+ "token",
+ "tokenize",
+ "trace",
+ "traceback",
+ "ttk",
+ "tty",
+ "turtle",
+ "types",
+ "unicodedata",
+ "unittest",
+ "urllib",
+ "urllib2",
+ "urlparse",
+ "user",
+ "uu",
+ "uuid",
+ "videoreader",
+ "warnings",
+ "wave",
+ "weakref",
+ "webbrowser",
+ "whichdb",
+ "winsound",
+ "wsgiref",
+ "xdrlib",
+ "xml",
+ "xmlrpclib",
+ "zipfile",
+ "zipimport",
+ "zlib",
+}
diff --git a/venv/Lib/site-packages/isort/stdlibs/py3.py b/venv/Lib/site-packages/isort/stdlibs/py3.py
new file mode 100644
index 0000000000000000000000000000000000000000..78e0984d5d788f8c90590a65a56eae17d754c9a9
--- /dev/null
+++ b/venv/Lib/site-packages/isort/stdlibs/py3.py
@@ -0,0 +1,3 @@
+from . import py35, py36, py37, py38
+
+stdlib = py35.stdlib | py36.stdlib | py37.stdlib | py38.stdlib
diff --git a/venv/Lib/site-packages/isort/stdlibs/py35.py b/venv/Lib/site-packages/isort/stdlibs/py35.py
new file mode 100644
index 0000000000000000000000000000000000000000..274d8a7d148a1a2f3e7c2d347b6459547698b2a5
--- /dev/null
+++ b/venv/Lib/site-packages/isort/stdlibs/py35.py
@@ -0,0 +1,222 @@
+"""
+File contains the standard library of Python 3.5.
+
+DO NOT EDIT. If the standard library changes, a new list should be created
+using the mkstdlibs.py script.
+"""
+
+stdlib = {
+ "_dummy_thread",
+ "_thread",
+ "abc",
+ "aifc",
+ "argparse",
+ "array",
+ "ast",
+ "asynchat",
+ "asyncio",
+ "asyncore",
+ "atexit",
+ "audioop",
+ "base64",
+ "bdb",
+ "binascii",
+ "binhex",
+ "bisect",
+ "builtins",
+ "bz2",
+ "cProfile",
+ "calendar",
+ "cgi",
+ "cgitb",
+ "chunk",
+ "cmath",
+ "cmd",
+ "code",
+ "codecs",
+ "codeop",
+ "collections",
+ "colorsys",
+ "compileall",
+ "concurrent",
+ "configparser",
+ "contextlib",
+ "copy",
+ "copyreg",
+ "crypt",
+ "csv",
+ "ctypes",
+ "curses",
+ "datetime",
+ "dbm",
+ "decimal",
+ "difflib",
+ "dis",
+ "distutils",
+ "doctest",
+ "dummy_threading",
+ "email",
+ "encodings",
+ "ensurepip",
+ "enum",
+ "errno",
+ "faulthandler",
+ "fcntl",
+ "filecmp",
+ "fileinput",
+ "fnmatch",
+ "formatter",
+ "fpectl",
+ "fractions",
+ "ftplib",
+ "functools",
+ "gc",
+ "getopt",
+ "getpass",
+ "gettext",
+ "glob",
+ "grp",
+ "gzip",
+ "hashlib",
+ "heapq",
+ "hmac",
+ "html",
+ "http",
+ "imaplib",
+ "imghdr",
+ "imp",
+ "importlib",
+ "inspect",
+ "io",
+ "ipaddress",
+ "itertools",
+ "json",
+ "keyword",
+ "lib2to3",
+ "linecache",
+ "locale",
+ "logging",
+ "lzma",
+ "macpath",
+ "mailbox",
+ "mailcap",
+ "marshal",
+ "math",
+ "mimetypes",
+ "mmap",
+ "modulefinder",
+ "msilib",
+ "msvcrt",
+ "multiprocessing",
+ "netrc",
+ "nis",
+ "nntplib",
+ "ntpath",
+ "numbers",
+ "operator",
+ "optparse",
+ "os",
+ "ossaudiodev",
+ "parser",
+ "pathlib",
+ "pdb",
+ "pickle",
+ "pickletools",
+ "pipes",
+ "pkgutil",
+ "platform",
+ "plistlib",
+ "poplib",
+ "posix",
+ "posixpath",
+ "pprint",
+ "profile",
+ "pstats",
+ "pty",
+ "pwd",
+ "py_compile",
+ "pyclbr",
+ "pydoc",
+ "queue",
+ "quopri",
+ "random",
+ "re",
+ "readline",
+ "reprlib",
+ "resource",
+ "rlcompleter",
+ "runpy",
+ "sched",
+ "select",
+ "selectors",
+ "shelve",
+ "shlex",
+ "shutil",
+ "signal",
+ "site",
+ "smtpd",
+ "smtplib",
+ "sndhdr",
+ "socket",
+ "socketserver",
+ "spwd",
+ "sqlite3",
+ "sre",
+ "sre_compile",
+ "sre_constants",
+ "sre_parse",
+ "ssl",
+ "stat",
+ "statistics",
+ "string",
+ "stringprep",
+ "struct",
+ "subprocess",
+ "sunau",
+ "symbol",
+ "symtable",
+ "sys",
+ "sysconfig",
+ "syslog",
+ "tabnanny",
+ "tarfile",
+ "telnetlib",
+ "tempfile",
+ "termios",
+ "test",
+ "textwrap",
+ "threading",
+ "time",
+ "timeit",
+ "tkinter",
+ "token",
+ "tokenize",
+ "trace",
+ "traceback",
+ "tracemalloc",
+ "tty",
+ "turtle",
+ "turtledemo",
+ "types",
+ "typing",
+ "unicodedata",
+ "unittest",
+ "urllib",
+ "uu",
+ "uuid",
+ "venv",
+ "warnings",
+ "wave",
+ "weakref",
+ "webbrowser",
+ "winreg",
+ "winsound",
+ "wsgiref",
+ "xdrlib",
+ "xml",
+ "xmlrpc",
+ "zipapp",
+ "zipfile",
+ "zipimport",
+ "zlib",
+}
diff --git a/venv/Lib/site-packages/isort/stdlibs/py36.py b/venv/Lib/site-packages/isort/stdlibs/py36.py
new file mode 100644
index 0000000000000000000000000000000000000000..8ae02a150cbea980604a06e7c9248d7acca53bb0
--- /dev/null
+++ b/venv/Lib/site-packages/isort/stdlibs/py36.py
@@ -0,0 +1,223 @@
+"""
+File contains the standard library of Python 3.6.
+
+DO NOT EDIT. If the standard library changes, a new list should be created
+using the mkstdlibs.py script.
+"""
+
+stdlib = {
+ "_dummy_thread",
+ "_thread",
+ "abc",
+ "aifc",
+ "argparse",
+ "array",
+ "ast",
+ "asynchat",
+ "asyncio",
+ "asyncore",
+ "atexit",
+ "audioop",
+ "base64",
+ "bdb",
+ "binascii",
+ "binhex",
+ "bisect",
+ "builtins",
+ "bz2",
+ "cProfile",
+ "calendar",
+ "cgi",
+ "cgitb",
+ "chunk",
+ "cmath",
+ "cmd",
+ "code",
+ "codecs",
+ "codeop",
+ "collections",
+ "colorsys",
+ "compileall",
+ "concurrent",
+ "configparser",
+ "contextlib",
+ "copy",
+ "copyreg",
+ "crypt",
+ "csv",
+ "ctypes",
+ "curses",
+ "datetime",
+ "dbm",
+ "decimal",
+ "difflib",
+ "dis",
+ "distutils",
+ "doctest",
+ "dummy_threading",
+ "email",
+ "encodings",
+ "ensurepip",
+ "enum",
+ "errno",
+ "faulthandler",
+ "fcntl",
+ "filecmp",
+ "fileinput",
+ "fnmatch",
+ "formatter",
+ "fpectl",
+ "fractions",
+ "ftplib",
+ "functools",
+ "gc",
+ "getopt",
+ "getpass",
+ "gettext",
+ "glob",
+ "grp",
+ "gzip",
+ "hashlib",
+ "heapq",
+ "hmac",
+ "html",
+ "http",
+ "imaplib",
+ "imghdr",
+ "imp",
+ "importlib",
+ "inspect",
+ "io",
+ "ipaddress",
+ "itertools",
+ "json",
+ "keyword",
+ "lib2to3",
+ "linecache",
+ "locale",
+ "logging",
+ "lzma",
+ "macpath",
+ "mailbox",
+ "mailcap",
+ "marshal",
+ "math",
+ "mimetypes",
+ "mmap",
+ "modulefinder",
+ "msilib",
+ "msvcrt",
+ "multiprocessing",
+ "netrc",
+ "nis",
+ "nntplib",
+ "ntpath",
+ "numbers",
+ "operator",
+ "optparse",
+ "os",
+ "ossaudiodev",
+ "parser",
+ "pathlib",
+ "pdb",
+ "pickle",
+ "pickletools",
+ "pipes",
+ "pkgutil",
+ "platform",
+ "plistlib",
+ "poplib",
+ "posix",
+ "posixpath",
+ "pprint",
+ "profile",
+ "pstats",
+ "pty",
+ "pwd",
+ "py_compile",
+ "pyclbr",
+ "pydoc",
+ "queue",
+ "quopri",
+ "random",
+ "re",
+ "readline",
+ "reprlib",
+ "resource",
+ "rlcompleter",
+ "runpy",
+ "sched",
+ "secrets",
+ "select",
+ "selectors",
+ "shelve",
+ "shlex",
+ "shutil",
+ "signal",
+ "site",
+ "smtpd",
+ "smtplib",
+ "sndhdr",
+ "socket",
+ "socketserver",
+ "spwd",
+ "sqlite3",
+ "sre",
+ "sre_compile",
+ "sre_constants",
+ "sre_parse",
+ "ssl",
+ "stat",
+ "statistics",
+ "string",
+ "stringprep",
+ "struct",
+ "subprocess",
+ "sunau",
+ "symbol",
+ "symtable",
+ "sys",
+ "sysconfig",
+ "syslog",
+ "tabnanny",
+ "tarfile",
+ "telnetlib",
+ "tempfile",
+ "termios",
+ "test",
+ "textwrap",
+ "threading",
+ "time",
+ "timeit",
+ "tkinter",
+ "token",
+ "tokenize",
+ "trace",
+ "traceback",
+ "tracemalloc",
+ "tty",
+ "turtle",
+ "turtledemo",
+ "types",
+ "typing",
+ "unicodedata",
+ "unittest",
+ "urllib",
+ "uu",
+ "uuid",
+ "venv",
+ "warnings",
+ "wave",
+ "weakref",
+ "webbrowser",
+ "winreg",
+ "winsound",
+ "wsgiref",
+ "xdrlib",
+ "xml",
+ "xmlrpc",
+ "zipapp",
+ "zipfile",
+ "zipimport",
+ "zlib",
+}
diff --git a/venv/Lib/site-packages/isort/stdlibs/py37.py b/venv/Lib/site-packages/isort/stdlibs/py37.py
new file mode 100644
index 0000000000000000000000000000000000000000..0eb1dd6fa99e776242268bae863bcd60a4c43e5d
--- /dev/null
+++ b/venv/Lib/site-packages/isort/stdlibs/py37.py
@@ -0,0 +1,224 @@
+"""
+File contains the standard library of Python 3.7.
+
+DO NOT EDIT. If the standard library changes, a new list should be created
+using the mkstdlibs.py script.
+"""
+
+stdlib = {
+ "_dummy_thread",
+ "_thread",
+ "abc",
+ "aifc",
+ "argparse",
+ "array",
+ "ast",
+ "asynchat",
+ "asyncio",
+ "asyncore",
+ "atexit",
+ "audioop",
+ "base64",
+ "bdb",
+ "binascii",
+ "binhex",
+ "bisect",
+ "builtins",
+ "bz2",
+ "cProfile",
+ "calendar",
+ "cgi",
+ "cgitb",
+ "chunk",
+ "cmath",
+ "cmd",
+ "code",
+ "codecs",
+ "codeop",
+ "collections",
+ "colorsys",
+ "compileall",
+ "concurrent",
+ "configparser",
+ "contextlib",
+ "contextvars",
+ "copy",
+ "copyreg",
+ "crypt",
+ "csv",
+ "ctypes",
+ "curses",
+ "dataclasses",
+ "datetime",
+ "dbm",
+ "decimal",
+ "difflib",
+ "dis",
+ "distutils",
+ "doctest",
+ "dummy_threading",
+ "email",
+ "encodings",
+ "ensurepip",
+ "enum",
+ "errno",
+ "faulthandler",
+ "fcntl",
+ "filecmp",
+ "fileinput",
+ "fnmatch",
+ "formatter",
+ "fractions",
+ "ftplib",
+ "functools",
+ "gc",
+ "getopt",
+ "getpass",
+ "gettext",
+ "glob",
+ "grp",
+ "gzip",
+ "hashlib",
+ "heapq",
+ "hmac",
+ "html",
+ "http",
+ "imaplib",
+ "imghdr",
+ "imp",
+ "importlib",
+ "inspect",
+ "io",
+ "ipaddress",
+ "itertools",
+ "json",
+ "keyword",
+ "lib2to3",
+ "linecache",
+ "locale",
+ "logging",
+ "lzma",
+ "macpath",
+ "mailbox",
+ "mailcap",
+ "marshal",
+ "math",
+ "mimetypes",
+ "mmap",
+ "modulefinder",
+ "msilib",
+ "msvcrt",
+ "multiprocessing",
+ "netrc",
+ "nis",
+ "nntplib",
+ "ntpath",
+ "numbers",
+ "operator",
+ "optparse",
+ "os",
+ "ossaudiodev",
+ "parser",
+ "pathlib",
+ "pdb",
+ "pickle",
+ "pickletools",
+ "pipes",
+ "pkgutil",
+ "platform",
+ "plistlib",
+ "poplib",
+ "posix",
+ "posixpath",
+ "pprint",
+ "profile",
+ "pstats",
+ "pty",
+ "pwd",
+ "py_compile",
+ "pyclbr",
+ "pydoc",
+ "queue",
+ "quopri",
+ "random",
+ "re",
+ "readline",
+ "reprlib",
+ "resource",
+ "rlcompleter",
+ "runpy",
+ "sched",
+ "secrets",
+ "select",
+ "selectors",
+ "shelve",
+ "shlex",
+ "shutil",
+ "signal",
+ "site",
+ "smtpd",
+ "smtplib",
+ "sndhdr",
+ "socket",
+ "socketserver",
+ "spwd",
+ "sqlite3",
+ "sre",
+ "sre_compile",
+ "sre_constants",
+ "sre_parse",
+ "ssl",
+ "stat",
+ "statistics",
+ "string",
+ "stringprep",
+ "struct",
+ "subprocess",
+ "sunau",
+ "symbol",
+ "symtable",
+ "sys",
+ "sysconfig",
+ "syslog",
+ "tabnanny",
+ "tarfile",
+ "telnetlib",
+ "tempfile",
+ "termios",
+ "test",
+ "textwrap",
+ "threading",
+ "time",
+ "timeit",
+ "tkinter",
+ "token",
+ "tokenize",
+ "trace",
+ "traceback",
+ "tracemalloc",
+ "tty",
+ "turtle",
+ "turtledemo",
+ "types",
+ "typing",
+ "unicodedata",
+ "unittest",
+ "urllib",
+ "uu",
+ "uuid",
+ "venv",
+ "warnings",
+ "wave",
+ "weakref",
+ "webbrowser",
+ "winreg",
+ "winsound",
+ "wsgiref",
+ "xdrlib",
+ "xml",
+ "xmlrpc",
+ "zipapp",
+ "zipfile",
+ "zipimport",
+ "zlib",
+}
diff --git a/venv/Lib/site-packages/isort/stdlibs/py38.py b/venv/Lib/site-packages/isort/stdlibs/py38.py
new file mode 100644
index 0000000000000000000000000000000000000000..9bcea9a16fd51c55d5829d0a3c2f85ad48e45ddc
--- /dev/null
+++ b/venv/Lib/site-packages/isort/stdlibs/py38.py
@@ -0,0 +1,223 @@
+"""
+File contains the standard library of Python 3.8.
+
+DO NOT EDIT. If the standard library changes, a new list should be created
+using the mkstdlibs.py script.
+"""
+
+stdlib = {
+ "_dummy_thread",
+ "_thread",
+ "abc",
+ "aifc",
+ "argparse",
+ "array",
+ "ast",
+ "asynchat",
+ "asyncio",
+ "asyncore",
+ "atexit",
+ "audioop",
+ "base64",
+ "bdb",
+ "binascii",
+ "binhex",
+ "bisect",
+ "builtins",
+ "bz2",
+ "cProfile",
+ "calendar",
+ "cgi",
+ "cgitb",
+ "chunk",
+ "cmath",
+ "cmd",
+ "code",
+ "codecs",
+ "codeop",
+ "collections",
+ "colorsys",
+ "compileall",
+ "concurrent",
+ "configparser",
+ "contextlib",
+ "contextvars",
+ "copy",
+ "copyreg",
+ "crypt",
+ "csv",
+ "ctypes",
+ "curses",
+ "dataclasses",
+ "datetime",
+ "dbm",
+ "decimal",
+ "difflib",
+ "dis",
+ "distutils",
+ "doctest",
+ "dummy_threading",
+ "email",
+ "encodings",
+ "ensurepip",
+ "enum",
+ "errno",
+ "faulthandler",
+ "fcntl",
+ "filecmp",
+ "fileinput",
+ "fnmatch",
+ "formatter",
+ "fractions",
+ "ftplib",
+ "functools",
+ "gc",
+ "getopt",
+ "getpass",
+ "gettext",
+ "glob",
+ "grp",
+ "gzip",
+ "hashlib",
+ "heapq",
+ "hmac",
+ "html",
+ "http",
+ "imaplib",
+ "imghdr",
+ "imp",
+ "importlib",
+ "inspect",
+ "io",
+ "ipaddress",
+ "itertools",
+ "json",
+ "keyword",
+ "lib2to3",
+ "linecache",
+ "locale",
+ "logging",
+ "lzma",
+ "mailbox",
+ "mailcap",
+ "marshal",
+ "math",
+ "mimetypes",
+ "mmap",
+ "modulefinder",
+ "msilib",
+ "msvcrt",
+ "multiprocessing",
+ "netrc",
+ "nis",
+ "nntplib",
+ "ntpath",
+ "numbers",
+ "operator",
+ "optparse",
+ "os",
+ "ossaudiodev",
+ "parser",
+ "pathlib",
+ "pdb",
+ "pickle",
+ "pickletools",
+ "pipes",
+ "pkgutil",
+ "platform",
+ "plistlib",
+ "poplib",
+ "posix",
+ "posixpath",
+ "pprint",
+ "profile",
+ "pstats",
+ "pty",
+ "pwd",
+ "py_compile",
+ "pyclbr",
+ "pydoc",
+ "queue",
+ "quopri",
+ "random",
+ "re",
+ "readline",
+ "reprlib",
+ "resource",
+ "rlcompleter",
+ "runpy",
+ "sched",
+ "secrets",
+ "select",
+ "selectors",
+ "shelve",
+ "shlex",
+ "shutil",
+ "signal",
+ "site",
+ "smtpd",
+ "smtplib",
+ "sndhdr",
+ "socket",
+ "socketserver",
+ "spwd",
+ "sqlite3",
+ "sre",
+ "sre_compile",
+ "sre_constants",
+ "sre_parse",
+ "ssl",
+ "stat",
+ "statistics",
+ "string",
+ "stringprep",
+ "struct",
+ "subprocess",
+ "sunau",
+ "symbol",
+ "symtable",
+ "sys",
+ "sysconfig",
+ "syslog",
+ "tabnanny",
+ "tarfile",
+ "telnetlib",
+ "tempfile",
+ "termios",
+ "test",
+ "textwrap",
+ "threading",
+ "time",
+ "timeit",
+ "tkinter",
+ "token",
+ "tokenize",
+ "trace",
+ "traceback",
+ "tracemalloc",
+ "tty",
+ "turtle",
+ "turtledemo",
+ "types",
+ "typing",
+ "unicodedata",
+ "unittest",
+ "urllib",
+ "uu",
+ "uuid",
+ "venv",
+ "warnings",
+ "wave",
+ "weakref",
+ "webbrowser",
+ "winreg",
+ "winsound",
+ "wsgiref",
+ "xdrlib",
+ "xml",
+ "xmlrpc",
+ "zipapp",
+ "zipfile",
+ "zipimport",
+ "zlib",
+}
diff --git a/venv/Lib/site-packages/isort/stdlibs/py39.py b/venv/Lib/site-packages/isort/stdlibs/py39.py
new file mode 100644
index 0000000000000000000000000000000000000000..7bcb8f2b709134da2606c422d92fbca745ce019a
--- /dev/null
+++ b/venv/Lib/site-packages/isort/stdlibs/py39.py
@@ -0,0 +1,223 @@
+"""
+File contains the standard library of Python 3.9.
+
+DO NOT EDIT. If the standard library changes, a new list should be created
+using the mkstdlibs.py script.
+"""
+
+stdlib = {
+ "_thread",
+ "abc",
+ "aifc",
+ "argparse",
+ "array",
+ "ast",
+ "asynchat",
+ "asyncio",
+ "asyncore",
+ "atexit",
+ "audioop",
+ "base64",
+ "bdb",
+ "binascii",
+ "binhex",
+ "bisect",
+ "builtins",
+ "bz2",
+ "cProfile",
+ "calendar",
+ "cgi",
+ "cgitb",
+ "chunk",
+ "cmath",
+ "cmd",
+ "code",
+ "codecs",
+ "codeop",
+ "collections",
+ "colorsys",
+ "compileall",
+ "concurrent",
+ "configparser",
+ "contextlib",
+ "contextvars",
+ "copy",
+ "copyreg",
+ "crypt",
+ "csv",
+ "ctypes",
+ "curses",
+ "dataclasses",
+ "datetime",
+ "dbm",
+ "decimal",
+ "difflib",
+ "dis",
+ "distutils",
+ "doctest",
+ "email",
+ "encodings",
+ "ensurepip",
+ "enum",
+ "errno",
+ "faulthandler",
+ "fcntl",
+ "filecmp",
+ "fileinput",
+ "fnmatch",
+ "formatter",
+ "fractions",
+ "ftplib",
+ "functools",
+ "gc",
+ "getopt",
+ "getpass",
+ "gettext",
+ "glob",
+ "graphlib",
+ "grp",
+ "gzip",
+ "hashlib",
+ "heapq",
+ "hmac",
+ "html",
+ "http",
+ "imaplib",
+ "imghdr",
+ "imp",
+ "importlib",
+ "inspect",
+ "io",
+ "ipaddress",
+ "itertools",
+ "json",
+ "keyword",
+ "lib2to3",
+ "linecache",
+ "locale",
+ "logging",
+ "lzma",
+ "mailbox",
+ "mailcap",
+ "marshal",
+ "math",
+ "mimetypes",
+ "mmap",
+ "modulefinder",
+ "msilib",
+ "msvcrt",
+ "multiprocessing",
+ "netrc",
+ "nis",
+ "nntplib",
+ "ntpath",
+ "numbers",
+ "operator",
+ "optparse",
+ "os",
+ "ossaudiodev",
+ "parser",
+ "pathlib",
+ "pdb",
+ "pickle",
+ "pickletools",
+ "pipes",
+ "pkgutil",
+ "platform",
+ "plistlib",
+ "poplib",
+ "posix",
+ "posixpath",
+ "pprint",
+ "profile",
+ "pstats",
+ "pty",
+ "pwd",
+ "py_compile",
+ "pyclbr",
+ "pydoc",
+ "queue",
+ "quopri",
+ "random",
+ "re",
+ "readline",
+ "reprlib",
+ "resource",
+ "rlcompleter",
+ "runpy",
+ "sched",
+ "secrets",
+ "select",
+ "selectors",
+ "shelve",
+ "shlex",
+ "shutil",
+ "signal",
+ "site",
+ "smtpd",
+ "smtplib",
+ "sndhdr",
+ "socket",
+ "socketserver",
+ "spwd",
+ "sqlite3",
+ "sre",
+ "sre_compile",
+ "sre_constants",
+ "sre_parse",
+ "ssl",
+ "stat",
+ "statistics",
+ "string",
+ "stringprep",
+ "struct",
+ "subprocess",
+ "sunau",
+ "symbol",
+ "symtable",
+ "sys",
+ "sysconfig",
+ "syslog",
+ "tabnanny",
+ "tarfile",
+ "telnetlib",
+ "tempfile",
+ "termios",
+ "test",
+ "textwrap",
+ "threading",
+ "time",
+ "timeit",
+ "tkinter",
+ "token",
+ "tokenize",
+ "trace",
+ "traceback",
+ "tracemalloc",
+ "tty",
+ "turtle",
+ "turtledemo",
+ "types",
+ "typing",
+ "unicodedata",
+ "unittest",
+ "urllib",
+ "uu",
+ "uuid",
+ "venv",
+ "warnings",
+ "wave",
+ "weakref",
+ "webbrowser",
+ "winreg",
+ "winsound",
+ "wsgiref",
+ "xdrlib",
+ "xml",
+ "xmlrpc",
+ "zipapp",
+ "zipfile",
+ "zipimport",
+ "zlib",
+ "zoneinfo",
+}
diff --git a/venv/Lib/site-packages/isort/utils.py b/venv/Lib/site-packages/isort/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..27f17b4a5d8b5c93768f83ec836524d523397da9
--- /dev/null
+++ b/venv/Lib/site-packages/isort/utils.py
@@ -0,0 +1,29 @@
+import os
+import sys
+from contextlib import contextmanager
+from typing import Iterator
+
+
+def exists_case_sensitive(path: str) -> bool:
+ """Returns if the given path exists and also matches the case on Windows.
+
+ When finding files that can be imported, it is important for the cases to match because while
+ file os.path.exists("module.py") and os.path.exists("MODULE.py") both return True on Windows,
+ Python can only import using the case of the real file.
+ """
+ result = os.path.exists(path)
+ if (sys.platform.startswith("win") or sys.platform == "darwin") and result: # pragma: no cover
+ directory, basename = os.path.split(path)
+ result = basename in os.listdir(directory)
+ return result
+
+
+@contextmanager
+def chdir(path: str) -> Iterator[None]:
+ """Context manager for changing dir and restoring previous workdir after exit."""
+ curdir = os.getcwd()
+ os.chdir(path)
+ try:
+ yield
+ finally:
+ os.chdir(curdir)
diff --git a/venv/Lib/site-packages/isort/wrap.py b/venv/Lib/site-packages/isort/wrap.py
new file mode 100644
index 0000000000000000000000000000000000000000..872b096e7985b43f1ac53a7f482243b66c01bfdc
--- /dev/null
+++ b/venv/Lib/site-packages/isort/wrap.py
@@ -0,0 +1,123 @@
+import copy
+import re
+from typing import List, Optional, Sequence
+
+from .settings import DEFAULT_CONFIG, Config
+from .wrap_modes import WrapModes as Modes
+from .wrap_modes import formatter_from_string
+
+
+def import_statement(
+ import_start: str,
+ from_imports: List[str],
+ comments: Sequence[str] = (),
+ line_separator: str = "\n",
+ config: Config = DEFAULT_CONFIG,
+ multi_line_output: Optional[Modes] = None,
+) -> str:
+ """Returns a multi-line wrapped form of the provided from import statement."""
+ formatter = formatter_from_string((multi_line_output or config.multi_line_output).name)
+ dynamic_indent = " " * (len(import_start) + 1)
+ indent = config.indent
+ line_length = config.wrap_length or config.line_length
+ statement = formatter(
+ statement=import_start,
+ imports=copy.copy(from_imports),
+ white_space=dynamic_indent,
+ indent=indent,
+ line_length=line_length,
+ comments=comments,
+ line_separator=line_separator,
+ comment_prefix=config.comment_prefix,
+ include_trailing_comma=config.include_trailing_comma,
+ remove_comments=config.ignore_comments,
+ )
+ if config.balanced_wrapping:
+ lines = statement.split(line_separator)
+ line_count = len(lines)
+ if len(lines) > 1:
+ minimum_length = min(len(line) for line in lines[:-1])
+ else:
+ minimum_length = 0
+ new_import_statement = statement
+ while len(lines[-1]) < minimum_length and len(lines) == line_count and line_length > 10:
+ statement = new_import_statement
+ line_length -= 1
+ new_import_statement = formatter(
+ statement=import_start,
+ imports=copy.copy(from_imports),
+ white_space=dynamic_indent,
+ indent=indent,
+ line_length=line_length,
+ comments=comments,
+ line_separator=line_separator,
+ comment_prefix=config.comment_prefix,
+ include_trailing_comma=config.include_trailing_comma,
+ remove_comments=config.ignore_comments,
+ )
+ lines = new_import_statement.split(line_separator)
+ if statement.count(line_separator) == 0:
+ return _wrap_line(statement, line_separator, config)
+ return statement
+
+
+def line(content: str, line_separator: str, config: Config = DEFAULT_CONFIG) -> str:
+ """Returns a line wrapped to the specified line-length, if possible."""
+ wrap_mode = config.multi_line_output
+ if len(content) > config.line_length and wrap_mode != Modes.NOQA: # type: ignore
+ line_without_comment = content
+ comment = None
+ if "#" in content:
+ line_without_comment, comment = content.split("#", 1)
+ for splitter in ("import ", ".", "as "):
+ exp = r"\b" + re.escape(splitter) + r"\b"
+ if re.search(exp, line_without_comment) and not line_without_comment.strip().startswith(
+ splitter
+ ):
+ line_parts = re.split(exp, line_without_comment)
+ if comment:
+ _comma_maybe = (
+ "," if (config.include_trailing_comma and config.use_parentheses) else ""
+ )
+ line_parts[-1] = f"{line_parts[-1].strip()}{_comma_maybe} #{comment}"
+ next_line = []
+ while (len(content) + 2) > (
+ config.wrap_length or config.line_length
+ ) and line_parts:
+ next_line.append(line_parts.pop())
+ content = splitter.join(line_parts)
+ if not content:
+ content = next_line.pop()
+
+ cont_line = _wrap_line(
+ config.indent + splitter.join(next_line).lstrip(), line_separator, config
+ )
+ if config.use_parentheses:
+ if splitter == "as ":
+ output = f"{content}{splitter}{cont_line.lstrip()}"
+ else:
+ _comma = "," if config.include_trailing_comma and not comment else ""
+ if wrap_mode in (
+ Modes.VERTICAL_HANGING_INDENT, # type: ignore
+ Modes.VERTICAL_GRID_GROUPED, # type: ignore
+ ):
+ _separator = line_separator
+ else:
+ _separator = ""
+ output = (
+ f"{content}{splitter}({line_separator}{cont_line}{_comma}{_separator})"
+ )
+ lines = output.split(line_separator)
+ if config.comment_prefix in lines[-1] and lines[-1].endswith(")"):
+ content, comment = lines[-1].split(config.comment_prefix, 1)
+ lines[-1] = content + ")" + config.comment_prefix + comment[:-1]
+ return line_separator.join(lines)
+ return f"{content}{splitter}\\{line_separator}{cont_line}"
+ elif len(content) > config.line_length and wrap_mode == Modes.NOQA: # type: ignore
+ if "# NOQA" not in content:
+ return f"{content}{config.comment_prefix} NOQA"
+
+ return content
+
+
+_wrap_line = line
diff --git a/venv/Lib/site-packages/isort/wrap_modes.py b/venv/Lib/site-packages/isort/wrap_modes.py
new file mode 100644
index 0000000000000000000000000000000000000000..92a63c3f772ec823ace99f2b7a455d2101ecd40e
--- /dev/null
+++ b/venv/Lib/site-packages/isort/wrap_modes.py
@@ -0,0 +1,311 @@
+"""Defines all wrap modes that can be used when outputting formatted imports"""
+import enum
+from inspect import signature
+from typing import Any, Callable, Dict, List
+
+import isort.comments
+
+_wrap_modes: Dict[str, Callable[[Any], str]] = {}
+
+
+def from_string(value: str) -> "WrapModes":
+ return getattr(WrapModes, str(value), None) or WrapModes(int(value))
+
+
+def formatter_from_string(name: str):
+ return _wrap_modes.get(name.upper(), grid)
+
+
+def _wrap_mode_interface(
+ statement: str,
+ imports: List[str],
+ white_space: str,
+ indent: str,
+ line_length: int,
+ comments: List[str],
+ line_separator: str,
+ comment_prefix: str,
+ include_trailing_comma: bool,
+ remove_comments: bool,
+) -> str:
+ """Defines the common interface used by all wrap mode functions"""
+ return ""
+
+
+def _wrap_mode(function):
+ """Registers an individual wrap mode. Function name and order are significant and used for
+ creating enum.
+ """
+ _wrap_modes[function.__name__.upper()] = function
+ function.__signature__ = signature(_wrap_mode_interface)
+ function.__annotations__ = _wrap_mode_interface.__annotations__
+ return function
+
+
+@_wrap_mode
+def grid(**interface):
+ if not interface["imports"]:
+ return ""
+
+ interface["statement"] += "(" + interface["imports"].pop(0)
+ while interface["imports"]:
+ next_import = interface["imports"].pop(0)
+ next_statement = isort.comments.add_to_line(
+ interface["comments"],
+ interface["statement"] + ", " + next_import,
+ removed=interface["remove_comments"],
+ comment_prefix=interface["comment_prefix"],
+ )
+ if (
+ len(next_statement.split(interface["line_separator"])[-1]) + 1
+ > interface["line_length"]
+ ):
+ lines = [f"{interface['white_space']}{next_import.split(' ')[0]}"]
+ for part in next_import.split(" ")[1:]:
+ new_line = f"{lines[-1]} {part}"
+ if len(new_line) + 1 > interface["line_length"]:
+ lines.append(f"{interface['white_space']}{part}")
+ else:
+ lines[-1] = new_line
+ next_import = interface["line_separator"].join(lines)
+ interface["statement"] = (
+ isort.comments.add_to_line(
+ interface["comments"],
+ f"{interface['statement']},",
+ removed=interface["remove_comments"],
+ comment_prefix=interface["comment_prefix"],
+ )
+ + f"{interface['line_separator']}{next_import}"
+ )
+ interface["comments"] = []
+ else:
+ interface["statement"] += ", " + next_import
+ return interface["statement"] + ("," if interface["include_trailing_comma"] else "") + ")"
+
+
+@_wrap_mode
+def vertical(**interface):
+ if not interface["imports"]:
+ return ""
+
+ first_import = (
+ isort.comments.add_to_line(
+ interface["comments"],
+ interface["imports"].pop(0) + ",",
+ removed=interface["remove_comments"],
+ comment_prefix=interface["comment_prefix"],
+ )
+ + interface["line_separator"]
+ + interface["white_space"]
+ )
+
+ _imports = ("," + interface["line_separator"] + interface["white_space"]).join(
+ interface["imports"]
+ )
+ _comma_maybe = "," if interface["include_trailing_comma"] else ""
+ return f"{interface['statement']}({first_import}{_imports}{_comma_maybe})"
+
+
+def _hanging_indent_common(use_parentheses=False, **interface):
+ if not interface["imports"]:
+ return ""
+ line_length_limit = interface["line_length"] - (1 if use_parentheses else 3)
+
+ def end_line(line):
+ if use_parentheses:
+ return line
+ if not line.endswith(" "):
+ line += " "
+ return line + "\\"
+
+ if use_parentheses:
+ interface["statement"] += "("
+ next_import = interface["imports"].pop(0)
+ next_statement = interface["statement"] + next_import
+ # Check for first import
+ if len(next_statement) > line_length_limit:
+ next_statement = (
+ isort.comments.add_to_line(
+ interface["comments"],
+ end_line(interface["statement"]),
+ removed=interface["remove_comments"],
+ comment_prefix=interface["comment_prefix"],
+ )
+ + f"{interface['line_separator']}{interface['indent']}{next_import}"
+ )
+ interface["comments"] = []
+ interface["statement"] = next_statement
+ while interface["imports"]:
+ next_import = interface["imports"].pop(0)
+ next_statement = isort.comments.add_to_line(
+ interface["comments"],
+ interface["statement"] + ", " + next_import,
+ removed=interface["remove_comments"],
+ comment_prefix=interface["comment_prefix"],
+ )
+ current_line = next_statement.split(interface["line_separator"])[-1]
+ if len(current_line) > line_length_limit:
+ next_statement = (
+ isort.comments.add_to_line(
+ interface["comments"],
+ end_line(interface["statement"] + ","),
+ removed=interface["remove_comments"],
+ comment_prefix=interface["comment_prefix"],
+ )
+ + f"{interface['line_separator']}{interface['indent']}{next_import}"
+ )
+ interface["comments"] = []
+ interface["statement"] = next_statement
+ _comma_maybe = "," if interface["include_trailing_comma"] else ""
+ _close_parentheses_maybe = ")" if use_parentheses else ""
+ return interface["statement"] + _comma_maybe + _close_parentheses_maybe
+
+
+@_wrap_mode
+def hanging_indent(**interface):
+ return _hanging_indent_common(use_parentheses=False, **interface)
+
+
+@_wrap_mode
+def vertical_hanging_indent(**interface):
+ _line_with_comments = isort.comments.add_to_line(
+ interface["comments"],
+ "",
+ removed=interface["remove_comments"],
+ comment_prefix=interface["comment_prefix"],
+ )
+ _imports = ("," + interface["line_separator"] + interface["indent"]).join(interface["imports"])
+ _comma_maybe = "," if interface["include_trailing_comma"] else ""
+ return (
+ f"{interface['statement']}({_line_with_comments}{interface['line_separator']}"
+ f"{interface['indent']}{_imports}{_comma_maybe}{interface['line_separator']})"
+ )
+
+
+def _vertical_grid_common(need_trailing_char: bool, **interface):
+ if not interface["imports"]:
+ return ""
+
+ interface["statement"] += (
+ isort.comments.add_to_line(
+ interface["comments"],
+ "(",
+ removed=interface["remove_comments"],
+ comment_prefix=interface["comment_prefix"],
+ )
+ + interface["line_separator"]
+ + interface["indent"]
+ + interface["imports"].pop(0)
+ )
+ while interface["imports"]:
+ next_import = interface["imports"].pop(0)
+ next_statement = f"{interface['statement']}, {next_import}"
+ current_line_length = len(next_statement.split(interface["line_separator"])[-1])
+ if interface["imports"] or need_trailing_char:
+ # If we have more interface["imports"] we need to account for a comma after this import
+ # We might also need to account for a closing ) we're going to add.
+ current_line_length += 1
+ if current_line_length > interface["line_length"]:
+ next_statement = (
+ f"{interface['statement']},{interface['line_separator']}"
+ f"{interface['indent']}{next_import}"
+ )
+ interface["statement"] = next_statement
+ if interface["include_trailing_comma"]:
+ interface["statement"] += ","
+ return interface["statement"]
+
+
+@_wrap_mode
+def vertical_grid(**interface) -> str:
+ return _vertical_grid_common(need_trailing_char=True, **interface) + ")"
+
+
+@_wrap_mode
+def vertical_grid_grouped(**interface):
+ return (
+ _vertical_grid_common(need_trailing_char=True, **interface)
+ + interface["line_separator"]
+ + ")"
+ )
+
+
+@_wrap_mode
+def vertical_grid_grouped_no_comma(**interface):
+ return (
+ _vertical_grid_common(need_trailing_char=False, **interface)
+ + interface["line_separator"]
+ + ")"
+ )
+
+
+@_wrap_mode
+def noqa(**interface):
+ _imports = ", ".join(interface["imports"])
+ retval = f"{interface['statement']}{_imports}"
+ comment_str = " ".join(interface["comments"])
+ if interface["comments"]:
+ if (
+ len(retval) + len(interface["comment_prefix"]) + 1 + len(comment_str)
+ <= interface["line_length"]
+ ):
+ return f"{retval}{interface['comment_prefix']} {comment_str}"
+ elif "NOQA" in interface["comments"]:
+ return f"{retval}{interface['comment_prefix']} {comment_str}"
+ else:
+ return f"{retval}{interface['comment_prefix']} NOQA {comment_str}"
+ else:
+ if len(retval) <= interface["line_length"]:
+ return retval
+ else:
+ return f"{retval}{interface['comment_prefix']} NOQA"
+
+
+@_wrap_mode
+def vertical_hanging_indent_bracket(**interface):
+ if not interface["imports"]:
+ return ""
+ statement = vertical_hanging_indent(**interface)
+ return f'{statement[:-1]}{interface["indent"]})'
+
+
+@_wrap_mode
+def vertical_prefix_from_module_import(**interface):
+ if not interface["imports"]:
+ return ""
+ prefix_statement = interface["statement"]
+ interface["statement"] += interface["imports"].pop(0)
+ while interface["imports"]:
+ next_import = interface["imports"].pop(0)
+ next_statement = isort.comments.add_to_line(
+ interface["comments"],
+ interface["statement"] + ", " + next_import,
+ removed=interface["remove_comments"],
+ comment_prefix=interface["comment_prefix"],
+ )
+ if (
+ len(next_statement.split(interface["line_separator"])[-1]) + 1
+ > interface["line_length"]
+ ):
+ next_statement = (
+ isort.comments.add_to_line(
+ interface["comments"],
+ f"{interface['statement']}",
+ removed=interface["remove_comments"],
+ comment_prefix=interface["comment_prefix"],
+ )
+ + f"{interface['line_separator']}{prefix_statement}{next_import}"
+ )
+ interface["comments"] = []
+ interface["statement"] = next_statement
+ return interface["statement"]
+
+
+@_wrap_mode
+def hanging_indent_with_parentheses(**interface):
+ return _hanging_indent_common(use_parentheses=True, **interface)
+
+
+WrapModes = enum.Enum( # type: ignore
+ "WrapModes", {wrap_mode: index for index, wrap_mode in enumerate(_wrap_modes.keys())}
+)
diff --git a/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/AUTHORS.rst b/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/AUTHORS.rst
new file mode 100644
index 0000000000000000000000000000000000000000..dbc03246c610647e83eb51e19d90dac978da65a2
--- /dev/null
+++ b/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/AUTHORS.rst
@@ -0,0 +1,10 @@
+
+Authors
+=======
+
+* Ionel Cristian Mărieș - https://blog.ionelmc.ro
+* Alvin Chow - https://github.com/alvinchow86
+* Astrum Kuo - https://github.com/xowenx
+* Erik M. Bray - http://iguananaut.net
+* Ran Benita - https://github.com/bluetech
+* "hugovk" - https://github.com/hugovk
diff --git a/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/INSTALLER b/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/INSTALLER
new file mode 100644
index 0000000000000000000000000000000000000000..a1b589e38a32041e49332e5e81c2d363dc418d68
--- /dev/null
+++ b/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/INSTALLER
@@ -0,0 +1 @@
+pip
diff --git a/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/LICENSE b/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..de39b84808564a6b086d2bbbe60b4411ff03767e
--- /dev/null
+++ b/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/LICENSE
@@ -0,0 +1,21 @@
+BSD 2-Clause License
+
+Copyright (c) 2014-2019, Ionel Cristian Mărieș
+All rights reserved.
+
+Redistribution and use in source and binary forms, with or without modification, are permitted provided that the
+following conditions are met:
+
+1. Redistributions of source code must retain the above copyright notice, this list of conditions and the following
+disclaimer.
+
+2. Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following
+disclaimer in the documentation and/or other materials provided with the distribution.
+
+THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES,
+INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
+DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
+SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
+SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY,
+WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF
+THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
diff --git a/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/METADATA b/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/METADATA
new file mode 100644
index 0000000000000000000000000000000000000000..b0e7326377604fd5f04604df1a13b4839f5450ef
--- /dev/null
+++ b/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/METADATA
@@ -0,0 +1,176 @@
+Metadata-Version: 2.1
+Name: lazy-object-proxy
+Version: 1.5.1
+Summary: A fast and thorough lazy object proxy.
+Home-page: https://github.com/ionelmc/python-lazy-object-proxy
+Author: Ionel Cristian Mărieș
+Author-email: contact@ionelmc.ro
+License: BSD-2-Clause
+Project-URL: Documentation, https://python-lazy-object-proxy.readthedocs.io/
+Project-URL: Changelog, https://python-lazy-object-proxy.readthedocs.io/en/latest/changelog.html
+Project-URL: Issue Tracker, https://github.com/ionelmc/python-lazy-object-proxy/issues
+Platform: UNKNOWN
+Classifier: Development Status :: 5 - Production/Stable
+Classifier: Intended Audience :: Developers
+Classifier: License :: OSI Approved :: BSD License
+Classifier: Operating System :: Unix
+Classifier: Operating System :: POSIX
+Classifier: Operating System :: Microsoft :: Windows
+Classifier: Programming Language :: Python
+Classifier: Programming Language :: Python :: 2.7
+Classifier: Programming Language :: Python :: 3
+Classifier: Programming Language :: Python :: 3.5
+Classifier: Programming Language :: Python :: 3.6
+Classifier: Programming Language :: Python :: 3.7
+Classifier: Programming Language :: Python :: 3.8
+Classifier: Programming Language :: Python :: Implementation :: CPython
+Classifier: Programming Language :: Python :: Implementation :: PyPy
+Classifier: Topic :: Utilities
+Requires-Python: >=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*
+
+========
+Overview
+========
+
+
+
+A fast and thorough lazy object proxy.
+
+* Free software: BSD 2-Clause License
+
+Note that this is based on `wrapt`_'s ObjectProxy with one big change: it calls a function the first time the proxy object is
+used, while `wrapt.ObjectProxy` just forwards the method calls to the target object.
+
+In other words, you use `lazy-object-proxy` when you only have the object way later and you use `wrapt.ObjectProxy` when you
+want to override few methods (by subclassing) and forward everything else to the target object.
+
+Example::
+
+ import lazy_object_proxy
+
+ def expensive_func():
+ from time import sleep
+ print('starting calculation')
+ # just as example for a very slow computation
+ sleep(2)
+ print('finished calculation')
+ # return the result of the calculation
+ return 10
+
+ obj = lazy_object_proxy.Proxy(expensive_func)
+ # function is called only when object is actually used
+ print(obj) # now expensive_func is called
+
+ print(obj) # the result without calling the expensive_func
+
+Installation
+============
+
+::
+
+ pip install lazy-object-proxy
+
+Documentation
+=============
+
+https://python-lazy-object-proxy.readthedocs.io/
+
+Development
+===========
+
+To run the all tests run::
+
+ tox
+
+Acknowledgements
+================
+
+This project is based on some code from `wrapt`_ as you can see in the git history.
+
+.. _wrapt: https://github.com/GrahamDumpleton/wrapt
+
+
+Changelog
+=========
+
+1.5.1 (2020-07-22)
+------------------
+
+* Added ARM64 wheels (manylinux2014).
+
+1.5.0 (2020-06-05)
+------------------
+
+* Added support for ``__fspath__``.
+* Dropped support for Python 3.4.
+
+1.4.3 (2019-10-26)
+------------------
+
+* Added binary wheels for Python 3.8.
+* Fixed license metadata.
+
+1.4.2 (2019-08-22)
+------------------
+
+* Included a ``pyproject.toml`` to allow users install the sdist with old python/setuptools, as the
+ setuptools-scm dep will be fetched by pip instead of setuptools.
+ Fixes `#30 <https://github.com/ionelmc/python-lazy-object-proxy/issues/30>`_.
+
+1.4.1 (2019-05-10)
+------------------
+
+* Fixed wheels being built with ``-coverage`` cflags. No more issues about bogus ``cext.gcda`` files.
+* Removed useless C file from wheels.
+* Changed ``setup.py`` to use setuptools-scm.
+
+1.4.0 (2019-05-05)
+------------------
+
+* Fixed ``__mod__`` for the slots backend. Contributed by Ran Benita in
+ `#28 <https://github.com/ionelmc/python-lazy-object-proxy/pull/28>`_.
+* Dropped support for Python 2.6 and 3.3. Contributed by "hugovk" in
+ `#24 <https://github.com/ionelmc/python-lazy-object-proxy/pull/24>`_.
+
+1.3.1 (2017-05-05)
+------------------
+
+* Fix broken release (``sdist`` had a broken ``MANIFEST.in``).
+
+1.3.0 (2017-05-02)
+------------------
+
+* Speed up arithmetic operations involving ``cext.Proxy`` subclasses.
+
+1.2.2 (2016-04-14)
+------------------
+
+* Added `manylinux <https://www.python.org/dev/peps/pep-0513/>`_ wheels.
+* Minor cleanup in readme.
+
+1.2.1 (2015-08-18)
+------------------
+
+* Fix a memory leak (the wrapped object would get bogus references). Contributed by Astrum Kuo in
+ `#10 <https://github.com/ionelmc/python-lazy-object-proxy/pull/10>`_.
+
+1.2.0 (2015-07-06)
+------------------
+
+* Don't instantiate the object when __repr__ is called. This aids with debugging (allows one to see exactly in
+ what state the proxy is).
+
+1.1.0 (2015-07-05)
+------------------
+
+* Added support for pickling. The pickled value is going to be the wrapped object *without* any Proxy container.
+* Fixed a memory management issue in the C extension (reference cycles weren't garbage collected due to improper
+ handling in the C extension). Contributed by Alvin Chow in
+ `#8 <https://github.com/ionelmc/python-lazy-object-proxy/pull/8>`_.
+
+1.0.2 (2015-04-11)
+-----------------------------------------
+
+* First release on PyPI.
+
+
diff --git a/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/RECORD b/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/RECORD
new file mode 100644
index 0000000000000000000000000000000000000000..d8ae2e01ce41299351be5f03db193bf3272ce321
--- /dev/null
+++ b/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/RECORD
@@ -0,0 +1,21 @@
+lazy_object_proxy-1.5.1.dist-info/AUTHORS.rst,sha256=8CeCjODba0S8UczLyZBPhpO_J6NMZ9Hz_fE1A1uNe9Y,278
+lazy_object_proxy-1.5.1.dist-info/INSTALLER,sha256=zuuue4knoyJ-UwPPXg8fezS7VCrXJQrAP7zeNuwvFQg,4
+lazy_object_proxy-1.5.1.dist-info/LICENSE,sha256=W-1KNkH2bsSNuN7SNqKV8z2H0CkxXzYXZVhUzw1wxUA,1329
+lazy_object_proxy-1.5.1.dist-info/METADATA,sha256=z053kywfZh9ucyFWHpdMAL55fGxvzJBM-cwIzb-cX1c,5235
+lazy_object_proxy-1.5.1.dist-info/RECORD,,
+lazy_object_proxy-1.5.1.dist-info/REQUESTED,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+lazy_object_proxy-1.5.1.dist-info/WHEEL,sha256=z-ezgbNu1Y2ixypRrBmFDHP9mmiBhiGywozViqVfAIc,105
+lazy_object_proxy-1.5.1.dist-info/top_level.txt,sha256=UNH-FQB-j_8bYqPz3gD90kHvaC42TQqY0thHSnbaa0k,18
+lazy_object_proxy/__init__.py,sha256=mlcq2RyFCnUz1FNBaTI1Ow5K1ZHp1VpfBMIYGSILfHc,410
+lazy_object_proxy/__pycache__/__init__.cpython-38.pyc,,
+lazy_object_proxy/__pycache__/_version.cpython-38.pyc,,
+lazy_object_proxy/__pycache__/compat.cpython-38.pyc,,
+lazy_object_proxy/__pycache__/simple.cpython-38.pyc,,
+lazy_object_proxy/__pycache__/slots.cpython-38.pyc,,
+lazy_object_proxy/__pycache__/utils.cpython-38.pyc,,
+lazy_object_proxy/_version.py,sha256=bT8zyTb1DAzMJtJMpir1ZyrfjmU_UitIT0AeNOufA9I,120
+lazy_object_proxy/cext.cp38-win_amd64.pyd,sha256=W2E-nsw3kkOFJl_mlukC1Gfxl8ULtgqo7daRolyyJk8,33280
+lazy_object_proxy/compat.py,sha256=W9iIrb9SWePDvo5tYCyY_VMoFoZ84nUux_tyLoDqonw,286
+lazy_object_proxy/simple.py,sha256=leXvG0RyqfrEmA-AM7eSvjkuhqOSA9Wq3uVu6-4mCMA,8568
+lazy_object_proxy/slots.py,sha256=iLu_hvEn6G6_jhnxicWRDcxfQcnaUt_MdGPGfpXHpgs,11731
+lazy_object_proxy/utils.py,sha256=x4XTrtlp_mDTWO_EOq_ILIOv2Qol8RLMnRm5M8l3OfU,291
diff --git a/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/REQUESTED b/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/REQUESTED
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/WHEEL b/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/WHEEL
new file mode 100644
index 0000000000000000000000000000000000000000..c69d2a37ba9eeded75a791eeaed0ae8f1ed86fca
--- /dev/null
+++ b/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/WHEEL
@@ -0,0 +1,5 @@
+Wheel-Version: 1.0
+Generator: bdist_wheel (0.33.6)
+Root-Is-Purelib: false
+Tag: cp38-cp38-win_amd64
+
diff --git a/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/top_level.txt b/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/top_level.txt
new file mode 100644
index 0000000000000000000000000000000000000000..bdf032e91b831175fac9916edc7a8e460f5877e0
--- /dev/null
+++ b/venv/Lib/site-packages/lazy_object_proxy-1.5.1.dist-info/top_level.txt
@@ -0,0 +1 @@
+lazy_object_proxy
diff --git a/venv/Lib/site-packages/lazy_object_proxy/__init__.py b/venv/Lib/site-packages/lazy_object_proxy/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..2068a3d607724bd32eeeb56c9bd42cafc381b22b
--- /dev/null
+++ b/venv/Lib/site-packages/lazy_object_proxy/__init__.py
@@ -0,0 +1,23 @@
+try:
+ import copy_reg as copyreg
+except ImportError:
+ import copyreg
+
+from .utils import identity
+
+copyreg.constructor(identity)
+
+try:
+ from .cext import Proxy
+ from .cext import identity
+except ImportError:
+ from .slots import Proxy
+else:
+ copyreg.constructor(identity)
+
+try:
+ from ._version import version as __version__
+except ImportError:
+ __version__ = '1.5.1'
+
+__all__ = "Proxy",
diff --git a/venv/Lib/site-packages/lazy_object_proxy/_version.py b/venv/Lib/site-packages/lazy_object_proxy/_version.py
new file mode 100644
index 0000000000000000000000000000000000000000..2136e63ed40de11c90588e40b9baff902973b170
--- /dev/null
+++ b/venv/Lib/site-packages/lazy_object_proxy/_version.py
@@ -0,0 +1,4 @@
+# coding: utf-8
+# file generated by setuptools_scm
+# don't change, don't track in version control
+version = '1.5.1'
diff --git a/venv/Lib/site-packages/lazy_object_proxy/cext.cp38-win_amd64.pyd b/venv/Lib/site-packages/lazy_object_proxy/cext.cp38-win_amd64.pyd
new file mode 100644
index 0000000000000000000000000000000000000000..cfd4158cc4c8e930c52886334a8337a6c36b24a1
Binary files /dev/null and b/venv/Lib/site-packages/lazy_object_proxy/cext.cp38-win_amd64.pyd differ
diff --git a/venv/Lib/site-packages/lazy_object_proxy/compat.py b/venv/Lib/site-packages/lazy_object_proxy/compat.py
new file mode 100644
index 0000000000000000000000000000000000000000..e950fdf663d277d16509b3d982d658744d835ce9
--- /dev/null
+++ b/venv/Lib/site-packages/lazy_object_proxy/compat.py
@@ -0,0 +1,14 @@
+import sys
+
+PY2 = sys.version_info[0] == 2
+PY3 = sys.version_info[0] == 3
+
+if PY3:
+ string_types = str, bytes
+else:
+ string_types = basestring, # noqa: F821
+
+
+def with_metaclass(meta, *bases):
+ """Create a base class with a metaclass."""
+ return meta("NewBase", bases, {})
diff --git a/venv/Lib/site-packages/lazy_object_proxy/simple.py b/venv/Lib/site-packages/lazy_object_proxy/simple.py
new file mode 100644
index 0000000000000000000000000000000000000000..92e355af8540bbb6d07ccb04829c9e88da19f00e
--- /dev/null
+++ b/venv/Lib/site-packages/lazy_object_proxy/simple.py
@@ -0,0 +1,258 @@
+import operator
+
+from .compat import PY2
+from .compat import PY3
+from .compat import string_types
+from .compat import with_metaclass
+from .utils import cached_property
+from .utils import identity
+
+
+def make_proxy_method(code):
+ def proxy_wrapper(self, *args):
+ return code(self.__wrapped__, *args)
+
+ return proxy_wrapper
+
+
+class _ProxyMethods(object):
+ # We use properties to override the values of __module__ and
+ # __doc__. If we add these in ObjectProxy, the derived class
+ # __dict__ will still be setup to have string variants of these
+ # attributes and the rules of descriptors means that they appear to
+ # take precedence over the properties in the base class. To avoid
+ # that, we copy the properties into the derived class type itself
+ # via a meta class. In that way the properties will always take
+ # precedence.
+
+ @property
+ def __module__(self):
+ return self.__wrapped__.__module__
+
+ @__module__.setter
+ def __module__(self, value):
+ self.__wrapped__.__module__ = value
+
+ @property
+ def __doc__(self):
+ return self.__wrapped__.__doc__
+
+ @__doc__.setter
+ def __doc__(self, value):
+ self.__wrapped__.__doc__ = value
+
+ # Need to also propagate the special __weakref__ attribute for case
+ # where decorating classes which will define this. If do not define
+ # it and use a function like inspect.getmembers() on a decorator
+ # class it will fail. This can't be in the derived classes.
+
+ @property
+ def __weakref__(self):
+ return self.__wrapped__.__weakref__
+
+
+class _ProxyMetaType(type):
+ def __new__(cls, name, bases, dictionary):
+ # Copy our special properties into the class so that they
+ # always take precedence over attributes of the same name added
+ # during construction of a derived class. This is to save
+ # duplicating the implementation for them in all derived classes.
+
+ dictionary.update(vars(_ProxyMethods))
+ dictionary.pop('__dict__')
+
+ return type.__new__(cls, name, bases, dictionary)
+
+
+class Proxy(with_metaclass(_ProxyMetaType)):
+ __factory__ = None
+
+ def __init__(self, factory):
+ self.__dict__['__factory__'] = factory
+
+ @cached_property
+ def __wrapped__(self):
+ self = self.__dict__
+ if '__factory__' in self:
+ factory = self['__factory__']
+ return factory()
+ else:
+ raise ValueError("Proxy hasn't been initiated: __factory__ is missing.")
+
+ __name__ = property(make_proxy_method(operator.attrgetter('__name__')))
+ __class__ = property(make_proxy_method(operator.attrgetter('__class__')))
+ __annotations__ = property(make_proxy_method(operator.attrgetter('__anotations__')))
+ __dir__ = make_proxy_method(dir)
+ __str__ = make_proxy_method(str)
+
+ if PY3:
+ __bytes__ = make_proxy_method(bytes)
+
+ def __repr__(self, __getattr__=object.__getattribute__):
+ if '__wrapped__' in self.__dict__:
+ return '<{} at 0x{:x} wrapping {!r} at 0x{:x} with factory {!r}>'.format(
+ type(self).__name__, id(self),
+ self.__wrapped__, id(self.__wrapped__),
+ self.__factory__
+ )
+ else:
+ return '<{} at 0x{:x} with factory {!r}>'.format(
+ type(self).__name__, id(self),
+ self.__factory__
+ )
+
+ def __fspath__(self):
+ wrapped = self.__wrapped__
+ if isinstance(wrapped, string_types):
+ return wrapped
+ else:
+ fspath = getattr(wrapped, '__fspath__', None)
+ if fspath is None:
+ return wrapped
+ else:
+ return fspath()
+
+ __reversed__ = make_proxy_method(reversed)
+
+ if PY3:
+ __round__ = make_proxy_method(round)
+
+ __lt__ = make_proxy_method(operator.lt)
+ __le__ = make_proxy_method(operator.le)
+ __eq__ = make_proxy_method(operator.eq)
+ __ne__ = make_proxy_method(operator.ne)
+ __gt__ = make_proxy_method(operator.gt)
+ __ge__ = make_proxy_method(operator.ge)
+ __hash__ = make_proxy_method(hash)
+ __nonzero__ = make_proxy_method(bool)
+ __bool__ = make_proxy_method(bool)
+
+ def __setattr__(self, name, value):
+ if hasattr(type(self), name):
+ self.__dict__[name] = value
+ else:
+ setattr(self.__wrapped__, name, value)
+
+ def __getattr__(self, name):
+ if name in ('__wrapped__', '__factory__'):
+ raise AttributeError(name)
+ else:
+ return getattr(self.__wrapped__, name)
+
+ def __delattr__(self, name):
+ if hasattr(type(self), name):
+ del self.__dict__[name]
+ else:
+ delattr(self.__wrapped__, name)
+
+ __add__ = make_proxy_method(operator.add)
+ __sub__ = make_proxy_method(operator.sub)
+ __mul__ = make_proxy_method(operator.mul)
+ __div__ = make_proxy_method(operator.div if PY2 else operator.truediv)
+ __truediv__ = make_proxy_method(operator.truediv)
+ __floordiv__ = make_proxy_method(operator.floordiv)
+ __mod__ = make_proxy_method(operator.mod)
+ __divmod__ = make_proxy_method(divmod)
+ __pow__ = make_proxy_method(pow)
+ __lshift__ = make_proxy_method(operator.lshift)
+ __rshift__ = make_proxy_method(operator.rshift)
+ __and__ = make_proxy_method(operator.and_)
+ __xor__ = make_proxy_method(operator.xor)
+ __or__ = make_proxy_method(operator.or_)
+
+ def __radd__(self, other):
+ return other + self.__wrapped__
+
+ def __rsub__(self, other):
+ return other - self.__wrapped__
+
+ def __rmul__(self, other):
+ return other * self.__wrapped__
+
+ def __rdiv__(self, other):
+ return operator.div(other, self.__wrapped__)
+
+ def __rtruediv__(self, other):
+ return operator.truediv(other, self.__wrapped__)
+
+ def __rfloordiv__(self, other):
+ return other // self.__wrapped__
+
+ def __rmod__(self, other):
+ return other % self.__wrapped__
+
+ def __rdivmod__(self, other):
+ return divmod(other, self.__wrapped__)
+
+ def __rpow__(self, other, *args):
+ return pow(other, self.__wrapped__, *args)
+
+ def __rlshift__(self, other):
+ return other << self.__wrapped__
+
+ def __rrshift__(self, other):
+ return other >> self.__wrapped__
+
+ def __rand__(self, other):
+ return other & self.__wrapped__
+
+ def __rxor__(self, other):
+ return other ^ self.__wrapped__
+
+ def __ror__(self, other):
+ return other | self.__wrapped__
+
+ __iadd__ = make_proxy_method(operator.iadd)
+ __isub__ = make_proxy_method(operator.isub)
+ __imul__ = make_proxy_method(operator.imul)
+ __idiv__ = make_proxy_method(operator.idiv if PY2 else operator.itruediv)
+ __itruediv__ = make_proxy_method(operator.itruediv)
+ __ifloordiv__ = make_proxy_method(operator.ifloordiv)
+ __imod__ = make_proxy_method(operator.imod)
+ __ipow__ = make_proxy_method(operator.ipow)
+ __ilshift__ = make_proxy_method(operator.ilshift)
+ __irshift__ = make_proxy_method(operator.irshift)
+ __iand__ = make_proxy_method(operator.iand)
+ __ixor__ = make_proxy_method(operator.ixor)
+ __ior__ = make_proxy_method(operator.ior)
+ __neg__ = make_proxy_method(operator.neg)
+ __pos__ = make_proxy_method(operator.pos)
+ __abs__ = make_proxy_method(operator.abs)
+ __invert__ = make_proxy_method(operator.invert)
+
+ __int__ = make_proxy_method(int)
+
+ if PY2:
+ __long__ = make_proxy_method(long) # noqa
+
+ __float__ = make_proxy_method(float)
+ __oct__ = make_proxy_method(oct)
+ __hex__ = make_proxy_method(hex)
+ __index__ = make_proxy_method(operator.index)
+ __len__ = make_proxy_method(len)
+ __contains__ = make_proxy_method(operator.contains)
+ __getitem__ = make_proxy_method(operator.getitem)
+ __setitem__ = make_proxy_method(operator.setitem)
+ __delitem__ = make_proxy_method(operator.delitem)
+
+ if PY2:
+ __getslice__ = make_proxy_method(operator.getslice)
+ __setslice__ = make_proxy_method(operator.setslice)
+ __delslice__ = make_proxy_method(operator.delslice)
+
+ def __enter__(self):
+ return self.__wrapped__.__enter__()
+
+ def __exit__(self, *args, **kwargs):
+ return self.__wrapped__.__exit__(*args, **kwargs)
+
+ __iter__ = make_proxy_method(iter)
+
+ def __call__(self, *args, **kwargs):
+ return self.__wrapped__(*args, **kwargs)
+
+ def __reduce__(self):
+ return identity, (self.__wrapped__,)
+
+ def __reduce_ex__(self, protocol):
+ return identity, (self.__wrapped__,)
diff --git a/venv/Lib/site-packages/lazy_object_proxy/slots.py b/venv/Lib/site-packages/lazy_object_proxy/slots.py
new file mode 100644
index 0000000000000000000000000000000000000000..38668b8dfc350b777d27826934b3b0fa618c805e
--- /dev/null
+++ b/venv/Lib/site-packages/lazy_object_proxy/slots.py
@@ -0,0 +1,426 @@
+import operator
+
+from .compat import PY2
+from .compat import PY3
+from .compat import string_types
+from .compat import with_metaclass
+from .utils import identity
+
+
+class _ProxyMethods(object):
+ # We use properties to override the values of __module__ and
+ # __doc__. If we add these in ObjectProxy, the derived class
+ # __dict__ will still be setup to have string variants of these
+ # attributes and the rules of descriptors means that they appear to
+ # take precedence over the properties in the base class. To avoid
+ # that, we copy the properties into the derived class type itself
+ # via a meta class. In that way the properties will always take
+ # precedence.
+
+ @property
+ def __module__(self):
+ return self.__wrapped__.__module__
+
+ @__module__.setter
+ def __module__(self, value):
+ self.__wrapped__.__module__ = value
+
+ @property
+ def __doc__(self):
+ return self.__wrapped__.__doc__
+
+ @__doc__.setter
+ def __doc__(self, value):
+ self.__wrapped__.__doc__ = value
+
+ # We similar use a property for __dict__. We need __dict__ to be
+ # explicit to ensure that vars() works as expected.
+
+ @property
+ def __dict__(self):
+ return self.__wrapped__.__dict__
+
+ # Need to also propagate the special __weakref__ attribute for case
+ # where decorating classes which will define this. If do not define
+ # it and use a function like inspect.getmembers() on a decorator
+ # class it will fail. This can't be in the derived classes.
+
+ @property
+ def __weakref__(self):
+ return self.__wrapped__.__weakref__
+
+
+class _ProxyMetaType(type):
+ def __new__(cls, name, bases, dictionary):
+ # Copy our special properties into the class so that they
+ # always take precedence over attributes of the same name added
+ # during construction of a derived class. This is to save
+ # duplicating the implementation for them in all derived classes.
+
+ dictionary.update(vars(_ProxyMethods))
+
+ return type.__new__(cls, name, bases, dictionary)
+
+
+class Proxy(with_metaclass(_ProxyMetaType)):
+ """
+ A proxy implementation in pure Python, using slots. You can subclass this to add
+ local methods or attributes, or enable __dict__.
+
+ The most important internals:
+
+ * ``__factory__`` is the callback that "materializes" the object we proxy to.
+ * ``__target__`` will contain the object we proxy to, once it's "materialized".
+ * ``__wrapped__`` is a property that does either:
+
+ * return ``__target__`` if it's set.
+ * calls ``__factory__``, saves result to ``__target__`` and returns said result.
+ """
+
+ __slots__ = '__target__', '__factory__'
+
+ def __init__(self, factory):
+ object.__setattr__(self, '__factory__', factory)
+
+ @property
+ def __wrapped__(self, __getattr__=object.__getattribute__, __setattr__=object.__setattr__,
+ __delattr__=object.__delattr__):
+ try:
+ return __getattr__(self, '__target__')
+ except AttributeError:
+ try:
+ factory = __getattr__(self, '__factory__')
+ except AttributeError:
+ raise ValueError("Proxy hasn't been initiated: __factory__ is missing.")
+ target = factory()
+ __setattr__(self, '__target__', target)
+ return target
+
+ @__wrapped__.deleter
+ def __wrapped__(self, __delattr__=object.__delattr__):
+ __delattr__(self, '__target__')
+
+ @__wrapped__.setter
+ def __wrapped__(self, target, __setattr__=object.__setattr__):
+ __setattr__(self, '__target__', target)
+
+ @property
+ def __name__(self):
+ return self.__wrapped__.__name__
+
+ @__name__.setter
+ def __name__(self, value):
+ self.__wrapped__.__name__ = value
+
+ @property
+ def __class__(self):
+ return self.__wrapped__.__class__
+
+ @__class__.setter # noqa: F811
+ def __class__(self, value): # noqa: F811
+ self.__wrapped__.__class__ = value
+
+ @property
+ def __annotations__(self):
+ return self.__wrapped__.__anotations__
+
+ @__annotations__.setter
+ def __annotations__(self, value):
+ self.__wrapped__.__annotations__ = value
+
+ def __dir__(self):
+ return dir(self.__wrapped__)
+
+ def __str__(self):
+ return str(self.__wrapped__)
+
+ if PY3:
+ def __bytes__(self):
+ return bytes(self.__wrapped__)
+
+ def __repr__(self, __getattr__=object.__getattribute__):
+ try:
+ target = __getattr__(self, '__target__')
+ except AttributeError:
+ return '<{} at 0x{:x} with factory {!r}>'.format(
+ type(self).__name__, id(self),
+ self.__factory__
+ )
+ else:
+ return '<{} at 0x{:x} wrapping {!r} at 0x{:x} with factory {!r}>'.format(
+ type(self).__name__, id(self),
+ target, id(target),
+ self.__factory__
+ )
+
+ def __fspath__(self):
+ wrapped = self.__wrapped__
+ if isinstance(wrapped, string_types):
+ return wrapped
+ else:
+ fspath = getattr(wrapped, '__fspath__', None)
+ if fspath is None:
+ return wrapped
+ else:
+ return fspath()
+
+ def __reversed__(self):
+ return reversed(self.__wrapped__)
+
+ if PY3:
+ def __round__(self):
+ return round(self.__wrapped__)
+
+ def __lt__(self, other):
+ return self.__wrapped__ < other
+
+ def __le__(self, other):
+ return self.__wrapped__ <= other
+
+ def __eq__(self, other):
+ return self.__wrapped__ == other
+
+ def __ne__(self, other):
+ return self.__wrapped__ != other
+
+ def __gt__(self, other):
+ return self.__wrapped__ > other
+
+ def __ge__(self, other):
+ return self.__wrapped__ >= other
+
+ def __hash__(self):
+ return hash(self.__wrapped__)
+
+ def __nonzero__(self):
+ return bool(self.__wrapped__)
+
+ def __bool__(self):
+ return bool(self.__wrapped__)
+
+ def __setattr__(self, name, value, __setattr__=object.__setattr__):
+ if hasattr(type(self), name):
+ __setattr__(self, name, value)
+ else:
+ setattr(self.__wrapped__, name, value)
+
+ def __getattr__(self, name):
+ if name in ('__wrapped__', '__factory__'):
+ raise AttributeError(name)
+ else:
+ return getattr(self.__wrapped__, name)
+
+ def __delattr__(self, name, __delattr__=object.__delattr__):
+ if hasattr(type(self), name):
+ __delattr__(self, name)
+ else:
+ delattr(self.__wrapped__, name)
+
+ def __add__(self, other):
+ return self.__wrapped__ + other
+
+ def __sub__(self, other):
+ return self.__wrapped__ - other
+
+ def __mul__(self, other):
+ return self.__wrapped__ * other
+
+ def __div__(self, other):
+ return operator.div(self.__wrapped__, other)
+
+ def __truediv__(self, other):
+ return operator.truediv(self.__wrapped__, other)
+
+ def __floordiv__(self, other):
+ return self.__wrapped__ // other
+
+ def __mod__(self, other):
+ return self.__wrapped__ % other
+
+ def __divmod__(self, other):
+ return divmod(self.__wrapped__, other)
+
+ def __pow__(self, other, *args):
+ return pow(self.__wrapped__, other, *args)
+
+ def __lshift__(self, other):
+ return self.__wrapped__ << other
+
+ def __rshift__(self, other):
+ return self.__wrapped__ >> other
+
+ def __and__(self, other):
+ return self.__wrapped__ & other
+
+ def __xor__(self, other):
+ return self.__wrapped__ ^ other
+
+ def __or__(self, other):
+ return self.__wrapped__ | other
+
+ def __radd__(self, other):
+ return other + self.__wrapped__
+
+ def __rsub__(self, other):
+ return other - self.__wrapped__
+
+ def __rmul__(self, other):
+ return other * self.__wrapped__
+
+ def __rdiv__(self, other):
+ return operator.div(other, self.__wrapped__)
+
+ def __rtruediv__(self, other):
+ return operator.truediv(other, self.__wrapped__)
+
+ def __rfloordiv__(self, other):
+ return other // self.__wrapped__
+
+ def __rmod__(self, other):
+ return other % self.__wrapped__
+
+ def __rdivmod__(self, other):
+ return divmod(other, self.__wrapped__)
+
+ def __rpow__(self, other, *args):
+ return pow(other, self.__wrapped__, *args)
+
+ def __rlshift__(self, other):
+ return other << self.__wrapped__
+
+ def __rrshift__(self, other):
+ return other >> self.__wrapped__
+
+ def __rand__(self, other):
+ return other & self.__wrapped__
+
+ def __rxor__(self, other):
+ return other ^ self.__wrapped__
+
+ def __ror__(self, other):
+ return other | self.__wrapped__
+
+ def __iadd__(self, other):
+ self.__wrapped__ += other
+ return self
+
+ def __isub__(self, other):
+ self.__wrapped__ -= other
+ return self
+
+ def __imul__(self, other):
+ self.__wrapped__ *= other
+ return self
+
+ def __idiv__(self, other):
+ self.__wrapped__ = operator.idiv(self.__wrapped__, other)
+ return self
+
+ def __itruediv__(self, other):
+ self.__wrapped__ = operator.itruediv(self.__wrapped__, other)
+ return self
+
+ def __ifloordiv__(self, other):
+ self.__wrapped__ //= other
+ return self
+
+ def __imod__(self, other):
+ self.__wrapped__ %= other
+ return self
+
+ def __ipow__(self, other):
+ self.__wrapped__ **= other
+ return self
+
+ def __ilshift__(self, other):
+ self.__wrapped__ <<= other
+ return self
+
+ def __irshift__(self, other):
+ self.__wrapped__ >>= other
+ return self
+
+ def __iand__(self, other):
+ self.__wrapped__ &= other
+ return self
+
+ def __ixor__(self, other):
+ self.__wrapped__ ^= other
+ return self
+
+ def __ior__(self, other):
+ self.__wrapped__ |= other
+ return self
+
+ def __neg__(self):
+ return -self.__wrapped__
+
+ def __pos__(self):
+ return +self.__wrapped__
+
+ def __abs__(self):
+ return abs(self.__wrapped__)
+
+ def __invert__(self):
+ return ~self.__wrapped__
+
+ def __int__(self):
+ return int(self.__wrapped__)
+
+ if PY2:
+ def __long__(self):
+ return long(self.__wrapped__) # noqa
+
+ def __float__(self):
+ return float(self.__wrapped__)
+
+ def __oct__(self):
+ return oct(self.__wrapped__)
+
+ def __hex__(self):
+ return hex(self.__wrapped__)
+
+ def __index__(self):
+ return operator.index(self.__wrapped__)
+
+ def __len__(self):
+ return len(self.__wrapped__)
+
+ def __contains__(self, value):
+ return value in self.__wrapped__
+
+ def __getitem__(self, key):
+ return self.__wrapped__[key]
+
+ def __setitem__(self, key, value):
+ self.__wrapped__[key] = value
+
+ def __delitem__(self, key):
+ del self.__wrapped__[key]
+
+ def __getslice__(self, i, j):
+ return self.__wrapped__[i:j]
+
+ def __setslice__(self, i, j, value):
+ self.__wrapped__[i:j] = value
+
+ def __delslice__(self, i, j):
+ del self.__wrapped__[i:j]
+
+ def __enter__(self):
+ return self.__wrapped__.__enter__()
+
+ def __exit__(self, *args, **kwargs):
+ return self.__wrapped__.__exit__(*args, **kwargs)
+
+ def __iter__(self):
+ return iter(self.__wrapped__)
+
+ def __call__(self, *args, **kwargs):
+ return self.__wrapped__(*args, **kwargs)
+
+ def __reduce__(self):
+ return identity, (self.__wrapped__,)
+
+ def __reduce_ex__(self, protocol):
+ return identity, (self.__wrapped__,)
diff --git a/venv/Lib/site-packages/lazy_object_proxy/utils.py b/venv/Lib/site-packages/lazy_object_proxy/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..ceb3050f7675c8bba747ef33b0164162085e31c5
--- /dev/null
+++ b/venv/Lib/site-packages/lazy_object_proxy/utils.py
@@ -0,0 +1,13 @@
+def identity(obj):
+ return obj
+
+
+class cached_property(object):
+ def __init__(self, func):
+ self.func = func
+
+ def __get__(self, obj, cls):
+ if obj is None:
+ return self
+ value = obj.__dict__[self.func.__name__] = self.func(obj)
+ return value
diff --git a/venv/Lib/site-packages/six-1.15.0.dist-info/INSTALLER b/venv/Lib/site-packages/six-1.15.0.dist-info/INSTALLER
new file mode 100644
index 0000000000000000000000000000000000000000..a1b589e38a32041e49332e5e81c2d363dc418d68
--- /dev/null
+++ b/venv/Lib/site-packages/six-1.15.0.dist-info/INSTALLER
@@ -0,0 +1 @@
+pip
diff --git a/venv/Lib/site-packages/six-1.15.0.dist-info/LICENSE b/venv/Lib/site-packages/six-1.15.0.dist-info/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..de6633112c1f9951fd688e1fb43457a1ec11d6d8
--- /dev/null
+++ b/venv/Lib/site-packages/six-1.15.0.dist-info/LICENSE
@@ -0,0 +1,18 @@
+Copyright (c) 2010-2020 Benjamin Peterson
+
+Permission is hereby granted, free of charge, to any person obtaining a copy of
+this software and associated documentation files (the "Software"), to deal in
+the Software without restriction, including without limitation the rights to
+use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
+the Software, and to permit persons to whom the Software is furnished to do so,
+subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
+FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
+COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
+IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
+CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
diff --git a/venv/Lib/site-packages/six-1.15.0.dist-info/METADATA b/venv/Lib/site-packages/six-1.15.0.dist-info/METADATA
new file mode 100644
index 0000000000000000000000000000000000000000..869bf25a884325e37cd8f415f5e1f1f37b832039
--- /dev/null
+++ b/venv/Lib/site-packages/six-1.15.0.dist-info/METADATA
@@ -0,0 +1,49 @@
+Metadata-Version: 2.1
+Name: six
+Version: 1.15.0
+Summary: Python 2 and 3 compatibility utilities
+Home-page: https://github.com/benjaminp/six
+Author: Benjamin Peterson
+Author-email: benjamin@python.org
+License: MIT
+Platform: UNKNOWN
+Classifier: Development Status :: 5 - Production/Stable
+Classifier: Programming Language :: Python :: 2
+Classifier: Programming Language :: Python :: 3
+Classifier: Intended Audience :: Developers
+Classifier: License :: OSI Approved :: MIT License
+Classifier: Topic :: Software Development :: Libraries
+Classifier: Topic :: Utilities
+Requires-Python: >=2.7, !=3.0.*, !=3.1.*, !=3.2.*
+
+.. image:: https://img.shields.io/pypi/v/six.svg
+ :target: https://pypi.org/project/six/
+ :alt: six on PyPI
+
+.. image:: https://travis-ci.org/benjaminp/six.svg?branch=master
+ :target: https://travis-ci.org/benjaminp/six
+ :alt: six on TravisCI
+
+.. image:: https://readthedocs.org/projects/six/badge/?version=latest
+ :target: https://six.readthedocs.io/
+ :alt: six's documentation on Read the Docs
+
+.. image:: https://img.shields.io/badge/license-MIT-green.svg
+ :target: https://github.com/benjaminp/six/blob/master/LICENSE
+ :alt: MIT License badge
+
+Six is a Python 2 and 3 compatibility library. It provides utility functions
+for smoothing over the differences between the Python versions with the goal of
+writing Python code that is compatible on both Python versions. See the
+documentation for more information on what is provided.
+
+Six supports Python 2.7 and 3.3+. It is contained in only one Python
+file, so it can be easily copied into your project. (The copyright and license
+notice must be retained.)
+
+Online documentation is at https://six.readthedocs.io/.
+
+Bugs can be reported to https://github.com/benjaminp/six. The code can also
+be found there.
+
+
diff --git a/venv/Lib/site-packages/six-1.15.0.dist-info/RECORD b/venv/Lib/site-packages/six-1.15.0.dist-info/RECORD
new file mode 100644
index 0000000000000000000000000000000000000000..c38259f758ef5b462a91387a6ef0262324d66452
--- /dev/null
+++ b/venv/Lib/site-packages/six-1.15.0.dist-info/RECORD
@@ -0,0 +1,9 @@
+__pycache__/six.cpython-38.pyc,,
+six-1.15.0.dist-info/INSTALLER,sha256=zuuue4knoyJ-UwPPXg8fezS7VCrXJQrAP7zeNuwvFQg,4
+six-1.15.0.dist-info/LICENSE,sha256=i7hQxWWqOJ_cFvOkaWWtI9gq3_YPI5P8J2K2MYXo5sk,1066
+six-1.15.0.dist-info/METADATA,sha256=W6rlyoeMZHXh6srP9NXNsm0rjAf_660re8WdH5TBT8E,1795
+six-1.15.0.dist-info/RECORD,,
+six-1.15.0.dist-info/REQUESTED,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
+six-1.15.0.dist-info/WHEEL,sha256=kGT74LWyRUZrL4VgLh6_g12IeVl_9u9ZVhadrgXZUEY,110
+six-1.15.0.dist-info/top_level.txt,sha256=_iVH_iYEtEXnD8nYGQYpYFUvkUW9sEO1GYbkeKSAais,4
+six.py,sha256=U4Z_yv534W5CNyjY9i8V1OXY2SjAny8y2L5vDLhhThM,34159
diff --git a/venv/Lib/site-packages/six-1.15.0.dist-info/REQUESTED b/venv/Lib/site-packages/six-1.15.0.dist-info/REQUESTED
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/venv/Lib/site-packages/six-1.15.0.dist-info/WHEEL b/venv/Lib/site-packages/six-1.15.0.dist-info/WHEEL
new file mode 100644
index 0000000000000000000000000000000000000000..ef99c6cf3283b50a273ac4c6d009a0aa85597070
--- /dev/null
+++ b/venv/Lib/site-packages/six-1.15.0.dist-info/WHEEL
@@ -0,0 +1,6 @@
+Wheel-Version: 1.0
+Generator: bdist_wheel (0.34.2)
+Root-Is-Purelib: true
+Tag: py2-none-any
+Tag: py3-none-any
+
diff --git a/venv/Lib/site-packages/six-1.15.0.dist-info/top_level.txt b/venv/Lib/site-packages/six-1.15.0.dist-info/top_level.txt
new file mode 100644
index 0000000000000000000000000000000000000000..ffe2fce498955b628014618b28c6bcf152466a4a
--- /dev/null
+++ b/venv/Lib/site-packages/six-1.15.0.dist-info/top_level.txt
@@ -0,0 +1 @@
+six
diff --git a/venv/Lib/site-packages/six.py b/venv/Lib/site-packages/six.py
new file mode 100644
index 0000000000000000000000000000000000000000..83f69783d1a2dcb81e613268bc77afbd517be887
--- /dev/null
+++ b/venv/Lib/site-packages/six.py
@@ -0,0 +1,982 @@
+# Copyright (c) 2010-2020 Benjamin Peterson
+#
+# Permission is hereby granted, free of charge, to any person obtaining a copy
+# of this software and associated documentation files (the "Software"), to deal
+# in the Software without restriction, including without limitation the rights
+# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+# copies of the Software, and to permit persons to whom the Software is
+# furnished to do so, subject to the following conditions:
+#
+# The above copyright notice and this permission notice shall be included in all
+# copies or substantial portions of the Software.
+#
+# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+# SOFTWARE.
+
+"""Utilities for writing code that runs on Python 2 and 3"""
+
+from __future__ import absolute_import
+
+import functools
+import itertools
+import operator
+import sys
+import types
+
+__author__ = "Benjamin Peterson <benjamin@python.org>"
+__version__ = "1.15.0"
+
+
+# Useful for very coarse version differentiation.
+PY2 = sys.version_info[0] == 2
+PY3 = sys.version_info[0] == 3
+PY34 = sys.version_info[0:2] >= (3, 4)
+
+if PY3:
+ string_types = str,
+ integer_types = int,
+ class_types = type,
+ text_type = str
+ binary_type = bytes
+
+ MAXSIZE = sys.maxsize
+else:
+ string_types = basestring,
+ integer_types = (int, long)
+ class_types = (type, types.ClassType)
+ text_type = unicode
+ binary_type = str
+
+ if sys.platform.startswith("java"):
+ # Jython always uses 32 bits.
+ MAXSIZE = int((1 << 31) - 1)
+ else:
+ # It's possible to have sizeof(long) != sizeof(Py_ssize_t).
+ class X(object):
+
+ def __len__(self):
+ return 1 << 31
+ try:
+ len(X())
+ except OverflowError:
+ # 32-bit
+ MAXSIZE = int((1 << 31) - 1)
+ else:
+ # 64-bit
+ MAXSIZE = int((1 << 63) - 1)
+ del X
+
+
+def _add_doc(func, doc):
+ """Add documentation to a function."""
+ func.__doc__ = doc
+
+
+def _import_module(name):
+ """Import module, returning the module after the last dot."""
+ __import__(name)
+ return sys.modules[name]
+
+
+class _LazyDescr(object):
+
+ def __init__(self, name):
+ self.name = name
+
+ def __get__(self, obj, tp):
+ result = self._resolve()
+ setattr(obj, self.name, result) # Invokes __set__.
+ try:
+ # This is a bit ugly, but it avoids running this again by
+ # removing this descriptor.
+ delattr(obj.__class__, self.name)
+ except AttributeError:
+ pass
+ return result
+
+
+class MovedModule(_LazyDescr):
+
+ def __init__(self, name, old, new=None):
+ super(MovedModule, self).__init__(name)
+ if PY3:
+ if new is None:
+ new = name
+ self.mod = new
+ else:
+ self.mod = old
+
+ def _resolve(self):
+ return _import_module(self.mod)
+
+ def __getattr__(self, attr):
+ _module = self._resolve()
+ value = getattr(_module, attr)
+ setattr(self, attr, value)
+ return value
+
+
+class _LazyModule(types.ModuleType):
+
+ def __init__(self, name):
+ super(_LazyModule, self).__init__(name)
+ self.__doc__ = self.__class__.__doc__
+
+ def __dir__(self):
+ attrs = ["__doc__", "__name__"]
+ attrs += [attr.name for attr in self._moved_attributes]
+ return attrs
+
+ # Subclasses should override this
+ _moved_attributes = []
+
+
+class MovedAttribute(_LazyDescr):
+
+ def __init__(self, name, old_mod, new_mod, old_attr=None, new_attr=None):
+ super(MovedAttribute, self).__init__(name)
+ if PY3:
+ if new_mod is None:
+ new_mod = name
+ self.mod = new_mod
+ if new_attr is None:
+ if old_attr is None:
+ new_attr = name
+ else:
+ new_attr = old_attr
+ self.attr = new_attr
+ else:
+ self.mod = old_mod
+ if old_attr is None:
+ old_attr = name
+ self.attr = old_attr
+
+ def _resolve(self):
+ module = _import_module(self.mod)
+ return getattr(module, self.attr)
+
+
+class _SixMetaPathImporter(object):
+
+ """
+ A meta path importer to import six.moves and its submodules.
+
+ This class implements a PEP302 finder and loader. It should be compatible
+ with Python 2.5 and all existing versions of Python3
+ """
+
+ def __init__(self, six_module_name):
+ self.name = six_module_name
+ self.known_modules = {}
+
+ def _add_module(self, mod, *fullnames):
+ for fullname in fullnames:
+ self.known_modules[self.name + "." + fullname] = mod
+
+ def _get_module(self, fullname):
+ return self.known_modules[self.name + "." + fullname]
+
+ def find_module(self, fullname, path=None):
+ if fullname in self.known_modules:
+ return self
+ return None
+
+ def __get_module(self, fullname):
+ try:
+ return self.known_modules[fullname]
+ except KeyError:
+ raise ImportError("This loader does not know module " + fullname)
+
+ def load_module(self, fullname):
+ try:
+ # in case of a reload
+ return sys.modules[fullname]
+ except KeyError:
+ pass
+ mod = self.__get_module(fullname)
+ if isinstance(mod, MovedModule):
+ mod = mod._resolve()
+ else:
+ mod.__loader__ = self
+ sys.modules[fullname] = mod
+ return mod
+
+ def is_package(self, fullname):
+ """
+ Return true, if the named module is a package.
+
+ We need this method to get correct spec objects with
+ Python 3.4 (see PEP451)
+ """
+ return hasattr(self.__get_module(fullname), "__path__")
+
+ def get_code(self, fullname):
+ """Return None
+
+ Required, if is_package is implemented"""
+ self.__get_module(fullname) # eventually raises ImportError
+ return None
+ get_source = get_code # same as get_code
+
+_importer = _SixMetaPathImporter(__name__)
+
+
+class _MovedItems(_LazyModule):
+
+ """Lazy loading of moved objects"""
+ __path__ = [] # mark as package
+
+
+_moved_attributes = [
+ MovedAttribute("cStringIO", "cStringIO", "io", "StringIO"),
+ MovedAttribute("filter", "itertools", "builtins", "ifilter", "filter"),
+ MovedAttribute("filterfalse", "itertools", "itertools", "ifilterfalse", "filterfalse"),
+ MovedAttribute("input", "__builtin__", "builtins", "raw_input", "input"),
+ MovedAttribute("intern", "__builtin__", "sys"),
+ MovedAttribute("map", "itertools", "builtins", "imap", "map"),
+ MovedAttribute("getcwd", "os", "os", "getcwdu", "getcwd"),
+ MovedAttribute("getcwdb", "os", "os", "getcwd", "getcwdb"),
+ MovedAttribute("getoutput", "commands", "subprocess"),
+ MovedAttribute("range", "__builtin__", "builtins", "xrange", "range"),
+ MovedAttribute("reload_module", "__builtin__", "importlib" if PY34 else "imp", "reload"),
+ MovedAttribute("reduce", "__builtin__", "functools"),
+ MovedAttribute("shlex_quote", "pipes", "shlex", "quote"),
+ MovedAttribute("StringIO", "StringIO", "io"),
+ MovedAttribute("UserDict", "UserDict", "collections"),
+ MovedAttribute("UserList", "UserList", "collections"),
+ MovedAttribute("UserString", "UserString", "collections"),
+ MovedAttribute("xrange", "__builtin__", "builtins", "xrange", "range"),
+ MovedAttribute("zip", "itertools", "builtins", "izip", "zip"),
+ MovedAttribute("zip_longest", "itertools", "itertools", "izip_longest", "zip_longest"),
+ MovedModule("builtins", "__builtin__"),
+ MovedModule("configparser", "ConfigParser"),
+ MovedModule("collections_abc", "collections", "collections.abc" if sys.version_info >= (3, 3) else "collections"),
+ MovedModule("copyreg", "copy_reg"),
+ MovedModule("dbm_gnu", "gdbm", "dbm.gnu"),
+ MovedModule("dbm_ndbm", "dbm", "dbm.ndbm"),
+ MovedModule("_dummy_thread", "dummy_thread", "_dummy_thread" if sys.version_info < (3, 9) else "_thread"),
+ MovedModule("http_cookiejar", "cookielib", "http.cookiejar"),
+ MovedModule("http_cookies", "Cookie", "http.cookies"),
+ MovedModule("html_entities", "htmlentitydefs", "html.entities"),
+ MovedModule("html_parser", "HTMLParser", "html.parser"),
+ MovedModule("http_client", "httplib", "http.client"),
+ MovedModule("email_mime_base", "email.MIMEBase", "email.mime.base"),
+ MovedModule("email_mime_image", "email.MIMEImage", "email.mime.image"),
+ MovedModule("email_mime_multipart", "email.MIMEMultipart", "email.mime.multipart"),
+ MovedModule("email_mime_nonmultipart", "email.MIMENonMultipart", "email.mime.nonmultipart"),
+ MovedModule("email_mime_text", "email.MIMEText", "email.mime.text"),
+ MovedModule("BaseHTTPServer", "BaseHTTPServer", "http.server"),
+ MovedModule("CGIHTTPServer", "CGIHTTPServer", "http.server"),
+ MovedModule("SimpleHTTPServer", "SimpleHTTPServer", "http.server"),
+ MovedModule("cPickle", "cPickle", "pickle"),
+ MovedModule("queue", "Queue"),
+ MovedModule("reprlib", "repr"),
+ MovedModule("socketserver", "SocketServer"),
+ MovedModule("_thread", "thread", "_thread"),
+ MovedModule("tkinter", "Tkinter"),
+ MovedModule("tkinter_dialog", "Dialog", "tkinter.dialog"),
+ MovedModule("tkinter_filedialog", "FileDialog", "tkinter.filedialog"),
+ MovedModule("tkinter_scrolledtext", "ScrolledText", "tkinter.scrolledtext"),
+ MovedModule("tkinter_simpledialog", "SimpleDialog", "tkinter.simpledialog"),
+ MovedModule("tkinter_tix", "Tix", "tkinter.tix"),
+ MovedModule("tkinter_ttk", "ttk", "tkinter.ttk"),
+ MovedModule("tkinter_constants", "Tkconstants", "tkinter.constants"),
+ MovedModule("tkinter_dnd", "Tkdnd", "tkinter.dnd"),
+ MovedModule("tkinter_colorchooser", "tkColorChooser",
+ "tkinter.colorchooser"),
+ MovedModule("tkinter_commondialog", "tkCommonDialog",
+ "tkinter.commondialog"),
+ MovedModule("tkinter_tkfiledialog", "tkFileDialog", "tkinter.filedialog"),
+ MovedModule("tkinter_font", "tkFont", "tkinter.font"),
+ MovedModule("tkinter_messagebox", "tkMessageBox", "tkinter.messagebox"),
+ MovedModule("tkinter_tksimpledialog", "tkSimpleDialog",
+ "tkinter.simpledialog"),
+ MovedModule("urllib_parse", __name__ + ".moves.urllib_parse", "urllib.parse"),
+ MovedModule("urllib_error", __name__ + ".moves.urllib_error", "urllib.error"),
+ MovedModule("urllib", __name__ + ".moves.urllib", __name__ + ".moves.urllib"),
+ MovedModule("urllib_robotparser", "robotparser", "urllib.robotparser"),
+ MovedModule("xmlrpc_client", "xmlrpclib", "xmlrpc.client"),
+ MovedModule("xmlrpc_server", "SimpleXMLRPCServer", "xmlrpc.server"),
+]
+# Add windows specific modules.
+if sys.platform == "win32":
+ _moved_attributes += [
+ MovedModule("winreg", "_winreg"),
+ ]
+
+for attr in _moved_attributes:
+ setattr(_MovedItems, attr.name, attr)
+ if isinstance(attr, MovedModule):
+ _importer._add_module(attr, "moves." + attr.name)
+del attr
+
+_MovedItems._moved_attributes = _moved_attributes
+
+moves = _MovedItems(__name__ + ".moves")
+_importer._add_module(moves, "moves")
+
+
+class Module_six_moves_urllib_parse(_LazyModule):
+
+ """Lazy loading of moved objects in six.moves.urllib_parse"""
+
+
+_urllib_parse_moved_attributes = [
+ MovedAttribute("ParseResult", "urlparse", "urllib.parse"),
+ MovedAttribute("SplitResult", "urlparse", "urllib.parse"),
+ MovedAttribute("parse_qs", "urlparse", "urllib.parse"),
+ MovedAttribute("parse_qsl", "urlparse", "urllib.parse"),
+ MovedAttribute("urldefrag", "urlparse", "urllib.parse"),
+ MovedAttribute("urljoin", "urlparse", "urllib.parse"),
+ MovedAttribute("urlparse", "urlparse", "urllib.parse"),
+ MovedAttribute("urlsplit", "urlparse", "urllib.parse"),
+ MovedAttribute("urlunparse", "urlparse", "urllib.parse"),
+ MovedAttribute("urlunsplit", "urlparse", "urllib.parse"),
+ MovedAttribute("quote", "urllib", "urllib.parse"),
+ MovedAttribute("quote_plus", "urllib", "urllib.parse"),
+ MovedAttribute("unquote", "urllib", "urllib.parse"),
+ MovedAttribute("unquote_plus", "urllib", "urllib.parse"),
+ MovedAttribute("unquote_to_bytes", "urllib", "urllib.parse", "unquote", "unquote_to_bytes"),
+ MovedAttribute("urlencode", "urllib", "urllib.parse"),
+ MovedAttribute("splitquery", "urllib", "urllib.parse"),
+ MovedAttribute("splittag", "urllib", "urllib.parse"),
+ MovedAttribute("splituser", "urllib", "urllib.parse"),
+ MovedAttribute("splitvalue", "urllib", "urllib.parse"),
+ MovedAttribute("uses_fragment", "urlparse", "urllib.parse"),
+ MovedAttribute("uses_netloc", "urlparse", "urllib.parse"),
+ MovedAttribute("uses_params", "urlparse", "urllib.parse"),
+ MovedAttribute("uses_query", "urlparse", "urllib.parse"),
+ MovedAttribute("uses_relative", "urlparse", "urllib.parse"),
+]
+for attr in _urllib_parse_moved_attributes:
+ setattr(Module_six_moves_urllib_parse, attr.name, attr)
+del attr
+
+Module_six_moves_urllib_parse._moved_attributes = _urllib_parse_moved_attributes
+
+_importer._add_module(Module_six_moves_urllib_parse(__name__ + ".moves.urllib_parse"),
+ "moves.urllib_parse", "moves.urllib.parse")
+
+
+class Module_six_moves_urllib_error(_LazyModule):
+
+ """Lazy loading of moved objects in six.moves.urllib_error"""
+
+
+_urllib_error_moved_attributes = [
+ MovedAttribute("URLError", "urllib2", "urllib.error"),
+ MovedAttribute("HTTPError", "urllib2", "urllib.error"),
+ MovedAttribute("ContentTooShortError", "urllib", "urllib.error"),
+]
+for attr in _urllib_error_moved_attributes:
+ setattr(Module_six_moves_urllib_error, attr.name, attr)
+del attr
+
+Module_six_moves_urllib_error._moved_attributes = _urllib_error_moved_attributes
+
+_importer._add_module(Module_six_moves_urllib_error(__name__ + ".moves.urllib.error"),
+ "moves.urllib_error", "moves.urllib.error")
+
+
+class Module_six_moves_urllib_request(_LazyModule):
+
+ """Lazy loading of moved objects in six.moves.urllib_request"""
+
+
+_urllib_request_moved_attributes = [
+ MovedAttribute("urlopen", "urllib2", "urllib.request"),
+ MovedAttribute("install_opener", "urllib2", "urllib.request"),
+ MovedAttribute("build_opener", "urllib2", "urllib.request"),
+ MovedAttribute("pathname2url", "urllib", "urllib.request"),
+ MovedAttribute("url2pathname", "urllib", "urllib.request"),
+ MovedAttribute("getproxies", "urllib", "urllib.request"),
+ MovedAttribute("Request", "urllib2", "urllib.request"),
+ MovedAttribute("OpenerDirector", "urllib2", "urllib.request"),
+ MovedAttribute("HTTPDefaultErrorHandler", "urllib2", "urllib.request"),
+ MovedAttribute("HTTPRedirectHandler", "urllib2", "urllib.request"),
+ MovedAttribute("HTTPCookieProcessor", "urllib2", "urllib.request"),
+ MovedAttribute("ProxyHandler", "urllib2", "urllib.request"),
+ MovedAttribute("BaseHandler", "urllib2", "urllib.request"),
+ MovedAttribute("HTTPPasswordMgr", "urllib2", "urllib.request"),
+ MovedAttribute("HTTPPasswordMgrWithDefaultRealm", "urllib2", "urllib.request"),
+ MovedAttribute("AbstractBasicAuthHandler", "urllib2", "urllib.request"),
+ MovedAttribute("HTTPBasicAuthHandler", "urllib2", "urllib.request"),
+ MovedAttribute("ProxyBasicAuthHandler", "urllib2", "urllib.request"),
+ MovedAttribute("AbstractDigestAuthHandler", "urllib2", "urllib.request"),
+ MovedAttribute("HTTPDigestAuthHandler", "urllib2", "urllib.request"),
+ MovedAttribute("ProxyDigestAuthHandler", "urllib2", "urllib.request"),
+ MovedAttribute("HTTPHandler", "urllib2", "urllib.request"),
+ MovedAttribute("HTTPSHandler", "urllib2", "urllib.request"),
+ MovedAttribute("FileHandler", "urllib2", "urllib.request"),
+ MovedAttribute("FTPHandler", "urllib2", "urllib.request"),
+ MovedAttribute("CacheFTPHandler", "urllib2", "urllib.request"),
+ MovedAttribute("UnknownHandler", "urllib2", "urllib.request"),
+ MovedAttribute("HTTPErrorProcessor", "urllib2", "urllib.request"),
+ MovedAttribute("urlretrieve", "urllib", "urllib.request"),
+ MovedAttribute("urlcleanup", "urllib", "urllib.request"),
+ MovedAttribute("URLopener", "urllib", "urllib.request"),
+ MovedAttribute("FancyURLopener", "urllib", "urllib.request"),
+ MovedAttribute("proxy_bypass", "urllib", "urllib.request"),
+ MovedAttribute("parse_http_list", "urllib2", "urllib.request"),
+ MovedAttribute("parse_keqv_list", "urllib2", "urllib.request"),
+]
+for attr in _urllib_request_moved_attributes:
+ setattr(Module_six_moves_urllib_request, attr.name, attr)
+del attr
+
+Module_six_moves_urllib_request._moved_attributes = _urllib_request_moved_attributes
+
+_importer._add_module(Module_six_moves_urllib_request(__name__ + ".moves.urllib.request"),
+ "moves.urllib_request", "moves.urllib.request")
+
+
+class Module_six_moves_urllib_response(_LazyModule):
+
+ """Lazy loading of moved objects in six.moves.urllib_response"""
+
+
+_urllib_response_moved_attributes = [
+ MovedAttribute("addbase", "urllib", "urllib.response"),
+ MovedAttribute("addclosehook", "urllib", "urllib.response"),
+ MovedAttribute("addinfo", "urllib", "urllib.response"),
+ MovedAttribute("addinfourl", "urllib", "urllib.response"),
+]
+for attr in _urllib_response_moved_attributes:
+ setattr(Module_six_moves_urllib_response, attr.name, attr)
+del attr
+
+Module_six_moves_urllib_response._moved_attributes = _urllib_response_moved_attributes
+
+_importer._add_module(Module_six_moves_urllib_response(__name__ + ".moves.urllib.response"),
+ "moves.urllib_response", "moves.urllib.response")
+
+
+class Module_six_moves_urllib_robotparser(_LazyModule):
+
+ """Lazy loading of moved objects in six.moves.urllib_robotparser"""
+
+
+_urllib_robotparser_moved_attributes = [
+ MovedAttribute("RobotFileParser", "robotparser", "urllib.robotparser"),
+]
+for attr in _urllib_robotparser_moved_attributes:
+ setattr(Module_six_moves_urllib_robotparser, attr.name, attr)
+del attr
+
+Module_six_moves_urllib_robotparser._moved_attributes = _urllib_robotparser_moved_attributes
+
+_importer._add_module(Module_six_moves_urllib_robotparser(__name__ + ".moves.urllib.robotparser"),
+ "moves.urllib_robotparser", "moves.urllib.robotparser")
+
+
+class Module_six_moves_urllib(types.ModuleType):
+
+ """Create a six.moves.urllib namespace that resembles the Python 3 namespace"""
+ __path__ = [] # mark as package
+ parse = _importer._get_module("moves.urllib_parse")
+ error = _importer._get_module("moves.urllib_error")
+ request = _importer._get_module("moves.urllib_request")
+ response = _importer._get_module("moves.urllib_response")
+ robotparser = _importer._get_module("moves.urllib_robotparser")
+
+ def __dir__(self):
+ return ['parse', 'error', 'request', 'response', 'robotparser']
+
+_importer._add_module(Module_six_moves_urllib(__name__ + ".moves.urllib"),
+ "moves.urllib")
+
+
+def add_move(move):
+ """Add an item to six.moves."""
+ setattr(_MovedItems, move.name, move)
+
+
+def remove_move(name):
+ """Remove item from six.moves."""
+ try:
+ delattr(_MovedItems, name)
+ except AttributeError:
+ try:
+ del moves.__dict__[name]
+ except KeyError:
+ raise AttributeError("no such move, %r" % (name,))
+
+
+if PY3:
+ _meth_func = "__func__"
+ _meth_self = "__self__"
+
+ _func_closure = "__closure__"
+ _func_code = "__code__"
+ _func_defaults = "__defaults__"
+ _func_globals = "__globals__"
+else:
+ _meth_func = "im_func"
+ _meth_self = "im_self"
+
+ _func_closure = "func_closure"
+ _func_code = "func_code"
+ _func_defaults = "func_defaults"
+ _func_globals = "func_globals"
+
+
+try:
+ advance_iterator = next
+except NameError:
+ def advance_iterator(it):
+ return it.next()
+next = advance_iterator
+
+
+try:
+ callable = callable
+except NameError:
+ def callable(obj):
+ return any("__call__" in klass.__dict__ for klass in type(obj).__mro__)
+
+
+if PY3:
+ def get_unbound_function(unbound):
+ return unbound
+
+ create_bound_method = types.MethodType
+
+ def create_unbound_method(func, cls):
+ return func
+
+ Iterator = object
+else:
+ def get_unbound_function(unbound):
+ return unbound.im_func
+
+ def create_bound_method(func, obj):
+ return types.MethodType(func, obj, obj.__class__)
+
+ def create_unbound_method(func, cls):
+ return types.MethodType(func, None, cls)
+
+ class Iterator(object):
+
+ def next(self):
+ return type(self).__next__(self)
+
+ callable = callable
+_add_doc(get_unbound_function,
+ """Get the function out of a possibly unbound function""")
+
+
+get_method_function = operator.attrgetter(_meth_func)
+get_method_self = operator.attrgetter(_meth_self)
+get_function_closure = operator.attrgetter(_func_closure)
+get_function_code = operator.attrgetter(_func_code)
+get_function_defaults = operator.attrgetter(_func_defaults)
+get_function_globals = operator.attrgetter(_func_globals)
+
+
+if PY3:
+ def iterkeys(d, **kw):
+ return iter(d.keys(**kw))
+
+ def itervalues(d, **kw):
+ return iter(d.values(**kw))
+
+ def iteritems(d, **kw):
+ return iter(d.items(**kw))
+
+ def iterlists(d, **kw):
+ return iter(d.lists(**kw))
+
+ viewkeys = operator.methodcaller("keys")
+
+ viewvalues = operator.methodcaller("values")
+
+ viewitems = operator.methodcaller("items")
+else:
+ def iterkeys(d, **kw):
+ return d.iterkeys(**kw)
+
+ def itervalues(d, **kw):
+ return d.itervalues(**kw)
+
+ def iteritems(d, **kw):
+ return d.iteritems(**kw)
+
+ def iterlists(d, **kw):
+ return d.iterlists(**kw)
+
+ viewkeys = operator.methodcaller("viewkeys")
+
+ viewvalues = operator.methodcaller("viewvalues")
+
+ viewitems = operator.methodcaller("viewitems")
+
+_add_doc(iterkeys, "Return an iterator over the keys of a dictionary.")
+_add_doc(itervalues, "Return an iterator over the values of a dictionary.")
+_add_doc(iteritems,
+ "Return an iterator over the (key, value) pairs of a dictionary.")
+_add_doc(iterlists,
+ "Return an iterator over the (key, [values]) pairs of a dictionary.")
+
+
+if PY3:
+ def b(s):
+ return s.encode("latin-1")
+
+ def u(s):
+ return s
+ unichr = chr
+ import struct
+ int2byte = struct.Struct(">B").pack
+ del struct
+ byte2int = operator.itemgetter(0)
+ indexbytes = operator.getitem
+ iterbytes = iter
+ import io
+ StringIO = io.StringIO
+ BytesIO = io.BytesIO
+ del io
+ _assertCountEqual = "assertCountEqual"
+ if sys.version_info[1] <= 1:
+ _assertRaisesRegex = "assertRaisesRegexp"
+ _assertRegex = "assertRegexpMatches"
+ _assertNotRegex = "assertNotRegexpMatches"
+ else:
+ _assertRaisesRegex = "assertRaisesRegex"
+ _assertRegex = "assertRegex"
+ _assertNotRegex = "assertNotRegex"
+else:
+ def b(s):
+ return s
+ # Workaround for standalone backslash
+
+ def u(s):
+ return unicode(s.replace(r'\\', r'\\\\'), "unicode_escape")
+ unichr = unichr
+ int2byte = chr
+
+ def byte2int(bs):
+ return ord(bs[0])
+
+ def indexbytes(buf, i):
+ return ord(buf[i])
+ iterbytes = functools.partial(itertools.imap, ord)
+ import StringIO
+ StringIO = BytesIO = StringIO.StringIO
+ _assertCountEqual = "assertItemsEqual"
+ _assertRaisesRegex = "assertRaisesRegexp"
+ _assertRegex = "assertRegexpMatches"
+ _assertNotRegex = "assertNotRegexpMatches"
+_add_doc(b, """Byte literal""")
+_add_doc(u, """Text literal""")
+
+
+def assertCountEqual(self, *args, **kwargs):
+ return getattr(self, _assertCountEqual)(*args, **kwargs)
+
+
+def assertRaisesRegex(self, *args, **kwargs):
+ return getattr(self, _assertRaisesRegex)(*args, **kwargs)
+
+
+def assertRegex(self, *args, **kwargs):
+ return getattr(self, _assertRegex)(*args, **kwargs)
+
+
+def assertNotRegex(self, *args, **kwargs):
+ return getattr(self, _assertNotRegex)(*args, **kwargs)
+
+
+if PY3:
+ exec_ = getattr(moves.builtins, "exec")
+
+ def reraise(tp, value, tb=None):
+ try:
+ if value is None:
+ value = tp()
+ if value.__traceback__ is not tb:
+ raise value.with_traceback(tb)
+ raise value
+ finally:
+ value = None
+ tb = None
+
+else:
+ def exec_(_code_, _globs_=None, _locs_=None):
+ """Execute code in a namespace."""
+ if _globs_ is None:
+ frame = sys._getframe(1)
+ _globs_ = frame.f_globals
+ if _locs_ is None:
+ _locs_ = frame.f_locals
+ del frame
+ elif _locs_ is None:
+ _locs_ = _globs_
+ exec("""exec _code_ in _globs_, _locs_""")
+
+ exec_("""def reraise(tp, value, tb=None):
+ try:
+ raise tp, value, tb
+ finally:
+ tb = None
+""")
+
+
+if sys.version_info[:2] > (3,):
+ exec_("""def raise_from(value, from_value):
+ try:
+ raise value from from_value
+ finally:
+ value = None
+""")
+else:
+ def raise_from(value, from_value):
+ raise value
+
+
+print_ = getattr(moves.builtins, "print", None)
+if print_ is None:
+ def print_(*args, **kwargs):
+ """The new-style print function for Python 2.4 and 2.5."""
+ fp = kwargs.pop("file", sys.stdout)
+ if fp is None:
+ return
+
+ def write(data):
+ if not isinstance(data, basestring):
+ data = str(data)
+ # If the file has an encoding, encode unicode with it.
+ if (isinstance(fp, file) and
+ isinstance(data, unicode) and
+ fp.encoding is not None):
+ errors = getattr(fp, "errors", None)
+ if errors is None:
+ errors = "strict"
+ data = data.encode(fp.encoding, errors)
+ fp.write(data)
+ want_unicode = False
+ sep = kwargs.pop("sep", None)
+ if sep is not None:
+ if isinstance(sep, unicode):
+ want_unicode = True
+ elif not isinstance(sep, str):
+ raise TypeError("sep must be None or a string")
+ end = kwargs.pop("end", None)
+ if end is not None:
+ if isinstance(end, unicode):
+ want_unicode = True
+ elif not isinstance(end, str):
+ raise TypeError("end must be None or a string")
+ if kwargs:
+ raise TypeError("invalid keyword arguments to print()")
+ if not want_unicode:
+ for arg in args:
+ if isinstance(arg, unicode):
+ want_unicode = True
+ break
+ if want_unicode:
+ newline = unicode("\n")
+ space = unicode(" ")
+ else:
+ newline = "\n"
+ space = " "
+ if sep is None:
+ sep = space
+ if end is None:
+ end = newline
+ for i, arg in enumerate(args):
+ if i:
+ write(sep)
+ write(arg)
+ write(end)
+if sys.version_info[:2] < (3, 3):
+ _print = print_
+
+ def print_(*args, **kwargs):
+ fp = kwargs.get("file", sys.stdout)
+ flush = kwargs.pop("flush", False)
+ _print(*args, **kwargs)
+ if flush and fp is not None:
+ fp.flush()
+
+_add_doc(reraise, """Reraise an exception.""")
+
+if sys.version_info[0:2] < (3, 4):
+ # This does exactly the same what the :func:`py3:functools.update_wrapper`
+ # function does on Python versions after 3.2. It sets the ``__wrapped__``
+ # attribute on ``wrapper`` object and it doesn't raise an error if any of
+ # the attributes mentioned in ``assigned`` and ``updated`` are missing on
+ # ``wrapped`` object.
+ def _update_wrapper(wrapper, wrapped,
+ assigned=functools.WRAPPER_ASSIGNMENTS,
+ updated=functools.WRAPPER_UPDATES):
+ for attr in assigned:
+ try:
+ value = getattr(wrapped, attr)
+ except AttributeError:
+ continue
+ else:
+ setattr(wrapper, attr, value)
+ for attr in updated:
+ getattr(wrapper, attr).update(getattr(wrapped, attr, {}))
+ wrapper.__wrapped__ = wrapped
+ return wrapper
+ _update_wrapper.__doc__ = functools.update_wrapper.__doc__
+
+ def wraps(wrapped, assigned=functools.WRAPPER_ASSIGNMENTS,
+ updated=functools.WRAPPER_UPDATES):
+ return functools.partial(_update_wrapper, wrapped=wrapped,
+ assigned=assigned, updated=updated)
+ wraps.__doc__ = functools.wraps.__doc__
+
+else:
+ wraps = functools.wraps
+
+
+def with_metaclass(meta, *bases):
+ """Create a base class with a metaclass."""
+ # This requires a bit of explanation: the basic idea is to make a dummy
+ # metaclass for one level of class instantiation that replaces itself with
+ # the actual metaclass.
+ class metaclass(type):
+
+ def __new__(cls, name, this_bases, d):
+ if sys.version_info[:2] >= (3, 7):
+ # This version introduced PEP 560 that requires a bit
+ # of extra care (we mimic what is done by __build_class__).
+ resolved_bases = types.resolve_bases(bases)
+ if resolved_bases is not bases:
+ d['__orig_bases__'] = bases
+ else:
+ resolved_bases = bases
+ return meta(name, resolved_bases, d)
+
+ @classmethod
+ def __prepare__(cls, name, this_bases):
+ return meta.__prepare__(name, bases)
+ return type.__new__(metaclass, 'temporary_class', (), {})
+
+
+def add_metaclass(metaclass):
+ """Class decorator for creating a class with a metaclass."""
+ def wrapper(cls):
+ orig_vars = cls.__dict__.copy()
+ slots = orig_vars.get('__slots__')
+ if slots is not None:
+ if isinstance(slots, str):
+ slots = [slots]
+ for slots_var in slots:
+ orig_vars.pop(slots_var)
+ orig_vars.pop('__dict__', None)
+ orig_vars.pop('__weakref__', None)
+ if hasattr(cls, '__qualname__'):
+ orig_vars['__qualname__'] = cls.__qualname__
+ return metaclass(cls.__name__, cls.__bases__, orig_vars)
+ return wrapper
+
+
+def ensure_binary(s, encoding='utf-8', errors='strict'):
+ """Coerce **s** to six.binary_type.
+
+ For Python 2:
+ - `unicode` -> encoded to `str`
+ - `str` -> `str`
+
+ For Python 3:
+ - `str` -> encoded to `bytes`
+ - `bytes` -> `bytes`
+ """
+ if isinstance(s, binary_type):
+ return s
+ if isinstance(s, text_type):
+ return s.encode(encoding, errors)
+ raise TypeError("not expecting type '%s'" % type(s))
+
+
+def ensure_str(s, encoding='utf-8', errors='strict'):
+ """Coerce *s* to `str`.
+
+ For Python 2:
+ - `unicode` -> encoded to `str`
+ - `str` -> `str`
+
+ For Python 3:
+ - `str` -> `str`
+ - `bytes` -> decoded to `str`
+ """
+ # Optimization: Fast return for the common case.
+ if type(s) is str:
+ return s
+ if PY2 and isinstance(s, text_type):
+ return s.encode(encoding, errors)
+ elif PY3 and isinstance(s, binary_type):
+ return s.decode(encoding, errors)
+ elif not isinstance(s, (text_type, binary_type)):
+ raise TypeError("not expecting type '%s'" % type(s))
+ return s
+
+
+def ensure_text(s, encoding='utf-8', errors='strict'):
+ """Coerce *s* to six.text_type.
+
+ For Python 2:
+ - `unicode` -> `unicode`
+ - `str` -> `unicode`
+
+ For Python 3:
+ - `str` -> `str`
+ - `bytes` -> decoded to `str`
+ """
+ if isinstance(s, binary_type):
+ return s.decode(encoding, errors)
+ elif isinstance(s, text_type):
+ return s
+ else:
+ raise TypeError("not expecting type '%s'" % type(s))
+
+
+def python_2_unicode_compatible(klass):
+ """
+ A class decorator that defines __unicode__ and __str__ methods under Python 2.
+ Under Python 3 it does nothing.
+
+ To support Python 2 and 3 with a single code base, define a __str__ method
+ returning text and apply this decorator to the class.
+ """
+ if PY2:
+ if '__str__' not in klass.__dict__:
+ raise ValueError("@python_2_unicode_compatible cannot be applied "
+ "to %s because it doesn't define __str__()." %
+ klass.__name__)
+ klass.__unicode__ = klass.__str__
+ klass.__str__ = lambda self: self.__unicode__().encode('utf-8')
+ return klass
+
+
+# Complete the moves implementation.
+# This code is at the end of this module to speed up module loading.
+# Turn this module into a package.
+__path__ = [] # required for PEP 302 and PEP 451
+__package__ = __name__ # see PEP 366 @ReservedAssignment
+if globals().get("__spec__") is not None:
+ __spec__.submodule_search_locations = [] # PEP 451 @UndefinedVariable
+# Remove other six meta path importers, since they cause problems. This can
+# happen if six is removed from sys.modules and then reloaded. (Setuptools does
+# this for some reason.)
+if sys.meta_path:
+ for i, importer in enumerate(sys.meta_path):
+ # Here's some real nastiness: Another "instance" of the six module might
+ # be floating around. Therefore, we can't use isinstance() to check for
+ # the six meta path importer, since the other six instance will have
+ # inserted an importer with different class.
+ if (type(importer).__name__ == "_SixMetaPathImporter" and
+ importer.name == __name__):
+ del sys.meta_path[i]
+ break
+ del i, importer
+# Finally, add the importer to the meta path import hook.
+sys.meta_path.append(_importer)
diff --git a/venv/Scripts/isort.exe b/venv/Scripts/isort.exe
new file mode 100644
index 0000000000000000000000000000000000000000..1b3bbc7643c4725afe88359343908f2140aca750
Binary files /dev/null and b/venv/Scripts/isort.exe differ